Р.Клацки
КРАТКОВРЕМЕННАЯ ПАМЯТЬ:
ХРАНЕНИЕ И ПЕРЕРАБОТКА
ИНФОРМАЦИИ*
Структурирование и емкость КП
Мы уже отметили один из основных фактов, касающихся КП: ее емкость ограничена; количество информации, которое может храниться в ней одновременно, не должно превышать известного предела. Данные об этом получены главным образом при определении объема непосредственной памяти, когда испытуемому сначала предъявляют короткий список элементов (например, РАБОТА, МЫШЬ, ПАДЕНИЕ, СОЛЬ, ДИСК, ПЛАТЬЕ, КНИГА), а затем просят припомнить их. При малом числе элементов выполнение этой задачи не составляет труда и испытуемый точно воспроизводит список. Но если число их превышает 7, большинство испытуемых начинает допускать ошибки. Число элементов, которые испытуемый может припомнить, не делая ошибок, называют объемом памяти, и его истолковывали как предельное количество информации, которое может вместить КП. Предполагается, что КП может одновременно удерживать около семи элементов, поэтому именно такое число их испытуемый может воспроизводить без ошибок. При большем числе предъявленных элементов некоторые из них не могут удерживаться в КП и испытуемый не сможет их припомнить, что приведет к ошибкам.
Объем непосредственной памяти можно определить как равный примерно семи словам; но он равен также семи буквам (если эти буквы не образуют слов) или семи бессмысленным слогам. Иначе говоря, объем памяти выражается не в каких-то определенных единицах — словах, буквах или слогах, а равен примерно семи любым предъявленным элементам. Таким образом, испытуемый может запомнить 7 букв, если они не складываются ни в какие определенные структуры (X, П, А, Ф, М, К, И), но способен запомнить гораздо больше букв, если они образуют 7 слов. Это происходит потому, что он может перекодировать последовательность из многих букв в ряд более крупных единиц, если эта последовательность образует осмысленные слова. Такое перекодирование - объединение отдельных стимулов (букв) в более крупные единицы (слова) — называют структурированием (chunking). Соответственно образующиеся при этом единицы называют структурными единицами (chunks). Этот термин был введен Миллером (Miller. 1956), которому принадлежит также ставшая ныне знаменитой фраза о том, что объем
 * Клацки Р. Память человека.Структуры и процессы. М.: Мир, 1978. С. 92-93, 96-97, 133-139, 141-149.
* Клацки Р. Память человека.Структуры и процессы. М.: Мир, 1978. С. 92-93, 96-97, 133-139, 141-149.
памяти, измеренный в структурных единицах, равен "Магическому Числу Семь плюс или минус два".
Миллер обсуждал некоторые другие объемы, соответствующие этому "магическому" диапазону чисел от 5 до 9, однако в связи с нашей темой особенно существенны его представления о КП: объем кратковременной памяти измеряется в единицах, которые могут очень широко варьировать по своей внутренней структуре. Единица емкости КП соответствует одной структурной единице, а структурная единица — вещь довольно изменчивая, она содержит в зависимости от обстоятельств различное количество информации.
Одно из затруднений, связанных с концепцией структурной единицы, заключается в том, что его определение вводит нас в замкнутый круг: с одной стороны, мы определяем структурные единицы как элементы, которых в КП может находиться около семи, а с другой стороны — утверждаем, что объем КП соответствует семи структурным единицам. Иными словами, объем КП равен семи таким единицам, которых в ней помещается семь штук. Смысла в этом мало, и нужно, очевидно, найти способ определить структурную единицу как-то иначе. Конечно, довольно часто есть возможность определить характер структурной единицы по-другому. Допустим, что мы предъявляем испытуемому в виде последовательного ряда буквы, образующие несколько трехбуквенных слов (например, К, О, Т, Б, О, Р, В, А, Л). При этом может оказаться, что испытуемый способен запомнить примерно 21 букву (составляющие 7 слов) и воспроизвести их в пробе на непосредственное припоминание. В таком случае одна структурная единица соответствует одному слову, если принять, что одна единица — это такой элемент, которых испытуемый может запомнить семь. Однако, поскольку нам известны слова, одна структурная единица соответствует также одному слову. Иначе говоря, мы могли бы заранее предсказать, что испытуемый сможет запомнить 21 букву (а не 7), потому что в дан ном случае структурной единицей является слово. Таким образом, два способа определения структурной единицы — на основе объема памяти и на основе наших представлений о том, что соответствует единице, — согласуются между собой. <...>
Процесс структурирования
Как мы убедились, КП - не склад, куда помещают разные вещи и где их просто хранят без разбора, а система, в которой информация может подвергаться различным воздействиям и храниться в разнообразных формах. Очевидно, что при структурировании материала в КП используется информация, хранящаяся в ДП, - например, сведения о правильном написании слов. Информация из ДП позволяет придать некоторую структуру набору внешне не связанных между собой элементов; без этого образование структурных единиц было бы невозмож-
но. Таким образом, структурирование, подобно повторению, связано с опосредованием.
Исходя из такой характеристики процесса структурирования, можно представить себе, какие условия для него требуются. Во-первых, структурирование обычно происходит в то время, когда информация поступает в КП, а это означает, что объединяемый материал должен поступать в КП более или менее одновременно (было бы трудно объединить три буквы в слово, если бы эти буквы были случайно разбросаны в ряду из 21 буквы). Во-вторых, структурирование должно облегчаться, если объединяемые элементы обладают каким-то внутренним сродством, позволяющим им образовать некую единицу. В частности, если группа стимулов имеет структуру, соответствующую какому-то коду в ДП, то можно ожидать, что эти стимулы сложатся в структурную единицу, соответствующую этому коду.
Боуэр (Bower, 1970, 1972, a; Bower a. Springston, 1970), изучал некоторые из этих аспектов структурирования, видоизменяя способы сочетания предъявляемых элементов и степень их соответствия информации, хранящейся в ДП. В некоторых работах он варьировал группировку букв в буквенных последовательностях. Одним из способов такой группировки было временное разделение. Испытуемые выполняли задачу на определение объема памяти при слуховом восприятии букв. Экспериментатор, называя буквы, разделял их короткими паузами, положение и длительность которых он варьировал. Например, он мог читать ряд букв следующим образом: УФО... ОНФР... ГФ... НРЮ. Испытуемые, прослушавшие такую последовательность, запоминали меньше букв, чем те, которым предъявляли те же буквы, но иначе: УФ... ООН...ФРГ...ФНРЮ, хотя число букв, а также число групп из двух, трех и четырех букв было в обоих случаях одинаковым. Боуэр получил примерно такие же результаты при зрительном предъявлении букв с выделением групп цветом (в приведенных ниже рядах заглавные и строчные буквы были разного цвета):
УФОонфрГФнрю или УФоонФРГфнрю
Как показывают эксперименты Боуэра, знакомые сочетания букв, такие, как акронимы (буквенные сокращения), могут служить основой для структурирования, особенно в тех случаях, когда легко заметить соответствие входных сигналов этим сочетаниям. Структурные единицы могут возникать и при предъявлении более сложного материала, чем списки букв, хотя принципы структурирования остаются теми же. <...>
Эксперименты Познера по сравнению букв
Одна группа данных, говорящих о существовании зрительного кодирования в КП, получена с помощью метода, разработанного Познером (Posner, 1969; Posner а. о., 1969; Posner a. Mitchell, 1967). Исследования Познера дают веские основания полагать, что: 1) после воздействия зрительного стимула зрительная информация может сохраняться в ус-
ловиях, несовместимых с иконическим хранением; 2) зрительная информация может также поступать на короткое время из ДП. Основной метод Познера состоит в следующем (рис. 1). Испытуемый участвует в длинном ряде проб, каждая из которых продолжается очень недолго. В каждой пробе испытуемому предъявляют две буквы. Он должен сообщить, имеют ли эти буквы одинаковые названия (например, А и А или Б и б) или разные (например, А и Б); испытуемый делает это, нажимая на одну из находящихся перед ним кнопок.
| Тип пробы
| Что видит испытуемый
| Верный ответ
|
| С полным совпадением С совпадением названий «Отрицательная» проба
| А А А а А б
| «Одинаковые» «Одинаковые» «Разные»
|
|
| <----- Время
| реакции —»
|
Рис. 1. Возможные типы проб в экспериментах Познера по сравнению букв
Совершенно очевидно, что это задание - в отличие от большинства рассмотренных прежде - испытуемый может выполнить без всяких ошибок. Поэтому экспериментатора в данном случае не могут удовлетворить такие данные, как просто процент верных и неверных ответов. Зависимой переменной здесь будет время реакции (ВР) испытуемого - время, необходимое ему для того, чтобы после предъявления букв дать ответ — "одинаковые" или "разные". Точнее, ВР — это время между появлением букв и ответом испытуемого.
Теоретически эта величина показывает, сколько требуется времени для соответствующих внутренних процессов. В задании Познера в ВР входит время, необходимое испытуемому для того, чтобы зрительно воспринять буквы, сопоставить их друг с другом, решить, одинаковые они или разные, и нажать нужную кнопку. ВР будет больше или меньше в зависимости от того, сколько времени понадобится испытуемому для выполнения этих действий. Однако использование ВР в экспериментальной психологии не ограничивается задачами такого типа. Этот показатель имеет давнюю историю. Познер заимствовал его из работы Дондерса (Danders, 1862), который предложил "метод вычитания" для использования ВР при изучении психических процессов. Этот метод очень прост. Допустим, что у нас есть два задания, Хк Y, и что в задание У целиком входит все задание X плюс еще некоторый компонент Q (т. е. Y=X+Q). Тогда, измерив ВР для выполнения заданий X и Y, можно вычесть ВР для X из ВР для Y и получить время, необходимое для выполнения компонента Q. Таким способом можно исследовать природу Q, даже если этот компонент нельзя непосредственно наблюдать в отдельности. В более общей форме: используя время реакции, можно выделять отдельные компоненты заданий и исследовать некоторые свойства психических процессов.
Вернемся к экспериментам Познера. Как видно из рис. 1, существуют две ситуации, в которых испытуемый ответит "одинаковые". Он даст такой ответ, если две предъявленные буквы идентичны (например, А и А); мы будем называть это "полным
| Восприятие и зрительное кодирование букв
|
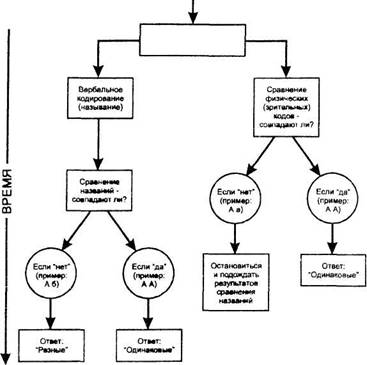 совпадением". И он опять-таки ответит "одинаковые", если буквы не идентичны, но имеют одно и то же название (как А и а); это будет "совпадение названий". В остальных случаях испытуемый будет отвечать "разные". (Ответы "одинаковые" и "разные" называют также положительными и отрицательными соответственно.) Как правило, для этих трех ситуаций — с полным совпадением, с совпадением названий и с разными буквами — величины ВР различны. В случае полного совпадения испытуемый обычно отвечает на 0,1 с быстрее (в экспериментах с ВР это очень большая величина), чем в случае совпадения названий или отрицательного ответа. Это позволяет предполагать, что во внутренних процессах, связанных с выполнением таких задач, есть какие-то различия.
совпадением". И он опять-таки ответит "одинаковые", если буквы не идентичны, но имеют одно и то же название (как А и а); это будет "совпадение названий". В остальных случаях испытуемый будет отвечать "разные". (Ответы "одинаковые" и "разные" называют также положительными и отрицательными соответственно.) Как правило, для этих трех ситуаций — с полным совпадением, с совпадением названий и с разными буквами — величины ВР различны. В случае полного совпадения испытуемый обычно отвечает на 0,1 с быстрее (в экспериментах с ВР это очень большая величина), чем в случае совпадения названий или отрицательного ответа. Это позволяет предполагать, что во внутренних процессах, связанных с выполнением таких задач, есть какие-то различия.
Чтобы выяснить, в чем состоят эти различия, следует разбить выполняемую задачу на отдельные компоненты, каждый из которых занимает часть всего затрачиваемого времени. Таким способом мы пытаемся выделить тот компонент или те компоненты, которые занимают дополнительное время в вариантах, отличных от случая полного совпадения. Мы могли бы предположительно расчленить задачу следующим образом: сначала испытуемый воспринимает буквы (зрительно кодирует их); затем он должен назвать их; после этого он решает, имеют ли они одинаковые или разные названия, и наконец, он дает ответ, нажимая на кнопку. Эти операции занимают все время - от начала предъявления букв до ответа. Нет достаточных оснований предполагать, что время, необходимое для восприятия букв, в разных случаях различно; точно так же вряд ли может варьировать и время, затрачиваемое на нажатие кнопки. Скорее всего различия в ВР зависят от времени, необходимого для процессов называния и сравнения. Когда буквы идентичны, на выполнение этих процессов, вероятно, уходит меньше времени, чем если буквы отличаются друг от друга.
По мнению Познера, различия в ВР обусловлены тем, что в случае двух идентичных букв нет нужды называть их. Он полагает, что идентичность их замечается сразу же при зрительном восприятии их физической формы. Только тогда, когда буквы не идентичны, возникает необходимость дать им названия и сопоставить эти названия. Короче говоря, в случаях полного совпадения (А, А) задача сводится к восприятию и зрительному кодированию, сравнению физических образов и даче ответа; в случае же совпадения названий (А, а) или отрицательного ответа (А, Б) она включает восприятие и зрительное кодирование, вербальное кодирование (называние), сравнение названий и дачу ответа. При совпадении названий ответная реакция - ввиду большего числа входящих в нее компонентов - должна занимать больше времени, что и приводит к наблюдаемым различиям ВР. Короче говоря, сопоставление в случаях полного совпадения основано, по мнению Позне-
Рис. 2. Схема возможных психических процессов при выполнении задачи на сравнение букв
ра, на зрительной информации, а в случаях совпадения названий — на словесных кодах (рис. 2).
Считая, что в случае полного совпадения сопоставляется зрительная информация, мы тем самым подразумеваем наличие этой информации. Последнее не вызывает сомнений, если две буквы предъявляются одновременно и остаются на виду до тех пор, пока испытуемый не даст ответа, - именно такой случай мы и рассматриваем. Нам, однако, нужны доказательства того, что зрительная информация остается в памяти и после исчезновения стимула. Более того, мы хотим показать, что эта информация содержится не в иконическом образе, а за его пределами, т. е, в КП.
Для того чтобы показать наличие в памяти такой зрительной информации, задачу Познера можно видоизменить, предъявляя две буквы не одновременно, а последовательно. Типичная проба будет состоять в следующем: сначала появляется первая буква, примерно на полсекунды, затем следует меж-стимульный интервал, на протяжении которого испытуемый видит пустое поле, после чего появляется вторая буква.
Испытуемый, как и в прежнем варианте, должен указать, "одинаковы" или "различны" две предъявленные ему буквы. Время реакции определяют в этом случае как промежуток между появлением второй буквы и ответом испытуемого.
В этой задаче первая буква должна еще оставаться в памяти испытуемого, когда он сообщает свой ответ, так как она исчезла с экрана перед межсти-мульным интервалом. Для сопоставления двух букв
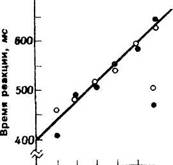
 должна использоваться информация, находящаяся в памяти. Есть ли доказательства того, что при этом используется именно зрительная информация? Иначе говоря, наблюдается ли в этом варианте опыта сокращение ВР при полном совпадении по уравнению со случаем совпадения названий? На это следует ответить утвердительно, по крайней мере для некоторых условий. Если межстимульный интервал меньше 1 с, то сопоставления при полном совпадении занимают меньше времени, но если он приближается к 2 с, различия в ВР исчезают (рис. 3). Рассуждая таким же образом, как и прежде, можно заключить, что если ВР при полном совпадении меньше, чем при совпадении названий, то для установления полной идентичности букв используется зрительная информация. Поскольку, однако, первая буква в момент сопоставления физически отсутствует, соответствующая зрительная информация должна, очевидно, находиться в мозгу. Таким образом, мы имеем доказательство того, что зрительная информация относительно первой буквы сохраняется в течение примерно 2 с после исчезновения этой буквы. Постепенное исчезновение различия во времени реакции по мере удлинения межстимульного интервала можно объяснить постепенным угасанием в памяти зрительного следа первой буквы.
должна использоваться информация, находящаяся в памяти. Есть ли доказательства того, что при этом используется именно зрительная информация? Иначе говоря, наблюдается ли в этом варианте опыта сокращение ВР при полном совпадении по уравнению со случаем совпадения названий? На это следует ответить утвердительно, по крайней мере для некоторых условий. Если межстимульный интервал меньше 1 с, то сопоставления при полном совпадении занимают меньше времени, но если он приближается к 2 с, различия в ВР исчезают (рис. 3). Рассуждая таким же образом, как и прежде, можно заключить, что если ВР при полном совпадении меньше, чем при совпадении названий, то для установления полной идентичности букв используется зрительная информация. Поскольку, однако, первая буква в момент сопоставления физически отсутствует, соответствующая зрительная информация должна, очевидно, находиться в мозгу. Таким образом, мы имеем доказательство того, что зрительная информация относительно первой буквы сохраняется в течение примерно 2 с после исчезновения этой буквы. Постепенное исчезновение различия во времени реакции по мере удлинения межстимульного интервала можно объяснить постепенным угасанием в памяти зрительного следа первой буквы.
s
S Я1 к п ф
а ш
0 1 2
Межстимульный интервал, с
Рис. 3. Влияние межстимульного интервала на время реакции при сравнении последовательно предъявляемых букв (Posner, 1969)
Итак, мы теперь располагаем данными о том, что зрительная информация может некоторое время сохраняться в памяти после исчезновения стимула. Остается, правда, важный вопрос: откуда нам известно, что зрительная информация находится в КП, а не в иконической памяти? Ведь описанные здесь эксперименты не позволяют утверждать, что в сопоставлении двух идентичных букв не используется иконическая информация. Есть, однако, данные, указывающие на то, что используемые при этом следы находятся не в сенсорном регистре и что их скорее следовало бы отнести к "кратковременной" памяти (в соответствии с критериями, которые мы установили в начале главы).
Один из доводов в пользу несенсорной природы этих зрительных следов состоит в том, что они, по-видимому, сохраняются даже после исчезновения иконического образа (Posner а. о., 1969). Предположим, например, что в интервале между двумя буквами предъявляют какое-то маскирующее поле -скажем, произвольный черно-белый узор. Следовало бы ожидать, что этот узор сотрет иконический образ первой буквы. В таком опыте полное совпадение все еще выявляется испытуемым быстрее, чем совпадение названий (хотя в обоих случаях затрачи вается больше времени, чем при "пустом" межсти-мульном интервале). Таким образом, зрительная информация о первой букве, по-видимому, сохраняется даже после предъявления маскирующего поля, а это означает, что она хранится не в сенсорном регистре, а в каком-то ином месте.
Другим указанием на то, что обсуждаемая нами зрительная память не является сенсорной, служат данные о возможности "заимствовать" соответствующий образ из ДП. Опишем результаты одного из таких экспериментов (Posner а. о., 1969). Вместо зрительного предъявления первой буквы испытуемому говорят: "Это заглавное А". Затем следует "пустой" интервал, после чего предъявляется либо заглавное А, либо какая-нибудь другая буква. При таких условиях время реакции для положительных ответов (когда вторая буква соответствует объявленной) сравнимо с ВР для случаев полного совпадения (в обычных условиях, т. е. при зрительном предъявлении обеих букв) при межстимульном интервале порядка 1 с и более. При интервале менее 1 с полное совпадение выявляется испытуемым несколько быстрее. Эти результаты позволяют предполагать, что испытуемый использует вербальное предъявление для того, чтобы создать внутренний зрительный образ объявленной буквы (с помощью правил, описывающих соответствие между звучанием и видом букв). После появления второй буквы он сравнивает с ней этот созданный им внутренний образ. Если испытуемый располагает по меньшей мере одной секундой для построения этого внутреннего образа, то этот образ сравним с тем, что имелось бы при зрительном предъявлении первой буквы. Если же времени слишком мало (меньше 1 с), получается образ "худшего качества", чем след буквы, предъявленной зрительно. Как мы видим; испытуемый, вероятно, может создавать зрительное представление в соответствии с содержащимися в ДП правилами или может удерживать в памяти подобный же образ после фактического предъявления стимула. Это служит веским доводом в пользу того, что зрительный образ, сохраняющийся после исчезновения стимула, не является иконическим следом, поскольку такого рода образ может быть извлечен из ДП, а не только получен непосредственно через органы чувств. <...>
Сканирование памяти и зрительная КП
Свой основной эксперимент Стернберг (Sternberg, 1966) поставил с целью изучить, каким образом происходит извлечение информации из КП: воспри-
|
| рольного стимула в КП испытуемого содержится стандартный набор элементов. Будем считать, что последующая переработка состоит из трех этапов. Сначала испытуемый воспринимает и кодирует контрольный стимул — переводит его в какую-либо внутреннюю форму; затем он сравнивает этот стимул с элементами стандартного набора и, наконец, на основании этих сравнений дает ответ. Суммарное время, затрачиваемое на все эти этапы, представляет собой ВР данного испытуемого.
Стернберга особенно интересовали изменения ВР, связанные с изменением величины стандартного набора, т, е. числа элементов в этом наборе. Из таких изменений ВР можно кое-что заключить относительно процесса сравнения, производимого испытуемым на втором этапе выполнения задачи. Что произойдет, если увеличить стандартный набор на одну цифру? Испытуемому придется произвести больше сравнений, так как он
|
| х
X
Я1
*я ф а
к
«а. ш
■•личина стандартного набора($) Величина стандартного набора (s)
800г-
|
| Отрицательные
Положительные
|
| ответы
12 3 4 5 6 Величина стандартного набора (s)
Рис. 5. Эксперимент Стернберга со сканированием памяти (Stemberg, 1966):
А -зависимость времени реакции от величины стандартного набора, ожидаемая в соответствии с гипотезой параллельного сканирования; Б - то же в соответствии с гипотезой последовательного сканирования; В - подлинные результаты, полученные в задаче со сканированием
|
| Испытуемому
предъявляют
стандартный
набор
|
Испытуемому
предъявляют
контрольный
стимул

| Испытуемый
сохраняет
стандартный
набор в
КП
|
| Испытуемый сравнивает контрольный
стимул со
стандартным
набором
|
Испытуемым воспринимает
и кодирует контрольный
стимул
Рис. 4. Задача Стернберга со сканированием памяти:
А - этапы типичной пробы;
Б - предполагаемые психические процессы, происходящие во время пробы.
ется? Может ли вся информация обследоваться одновременно — с помощью какого-то процесса параллельного сканирования? Или же сканирование производится последовательно, так что каждый элемент или структурная единица прочитывается одна за другой? Для выяснения этого и других вопросов Стернберг разработал следующую задачу. Каждый испытуемый участвовал в ряде проб, и в каждой пробе ему сначала предъявляли "стандартный набор", например, от одной до пяти цифр (примером набора из четырех цифр может служить 2, 4, 7, 3). Число элементов в наборе было меньше объема КП, и испытуемого просили запомнить их. Затем ему предъявляли "контрольный стимул" — одну цифру, которая могла входить или не входить в исходный набор. Испытуемый должен был ответить "да", если контрольный стимул соответствовал одному из элементов стандартного набора, и "нет", если он не соответствовал ни одному из них. Так же как и в экспериментах Познера, испытуемые могли выполнять это задание с очень небольшим числом ошибок, поэтому измеряемой переменной было время реакции (ВР). В данном случае ВР определялось как промежуток времени между предъявлением контрольного стимула и ответом испытуемого (обычно состоявшем в нажатии на кнопку, рис. 4-, Л).
Какого рода переработка информации происходит в этот короткий период? Задачу можно предположительно расчленить на отдельные компоненты того же типа, что и в экспериментах Познера (рис. 4, Б). Мы исходим из того, что при пояапении конт-
должен сравнивать контрольный стимул с каждым элементом стандартного набора. Изменение ВР при добавлении одной цифры должно быть различным в зависимости оттого, каким способом испытуемый выполняет задание; поэтому, выяснив, как изменяется ВР, мы сможем судить о том, как он перерабатывает предъявленную информацию.
Допустим, например, что у нас имеется простая гипотеза о параллельном процессе сравнения в КП — о том, что испытуемый обладает неограниченными возможностями переработки информации и может обследовать сразу все, что содержится в КП, затрачивая на это не больше усилий, чем было бы нужно для просмотра лишь некоторой части содержимого КП. Эта гипотеза позволяет нам сделать определенные предсказания относительно изменений ВР. В частности, мы можем ожидать, что добавление одной цифры к стандартному набору не окажет на ВР никакого влияния. Содержит ли память 2, 3 или 4 элемента — ВР для данного задания варьировать не будет, так как испытуемый затрачивает на сравнение нескольких элементов с контрольным стимулом не больше времени, чем на сравнение одного элемента.
Согласно другой возможной гипотезе, задача решается путем последовательного сканирования -испытуемый может сравнивать стимул одновременно лишь с одним из элементов стандартного набора. В этом случае каждый элемент, добавляемый к набору, будет удлинять время, необходимое для выполнения задачи. Соответственно будет увеличиваться ВР, причем степень этого увеличения будет зависеть от того, сколько времени требуется для сравнения еще одной цифры с контрольным стимулом. Следует ожидать, что при этом получится график, подобный представленному на рис. 5.
Рассмотрим эту гипотезу последовательного сканирования более подробно. Мы предположили, что процесс выполнения испытуемым задания состоит из трех этапов, каждый из которых занимает какую-то часть всего затрачиваемого времени. Допустим, что испытуемый затрачивает е миллисекунд на то, чтобы закодировать контрольный стимул, с миллисекунд на сравнение одного элемента стандартного набора с этим стимулом и г миллисекунд на третий этап (дачу ответа). Если стандартный набор состоит только из одного элемента, испытуемый сможет выполнить задание за е+c+r миллисекунд — это и будет его ВР. Допустим теперь, что в стандартном наборе 5 элементов и ни один из них не соответствует контрольному стимулу. Испытуемый даст в этом случае отрицательный ответ, и его ВР составит е+c+c+c+c+c+r миллисекунд. В общем случае время, затрачиваемое испытуемым на то, чтобы дать в аналогичной ситуации отрицательный ответ, будет равно e+s -c+r, где s — число элементов в стандартном наборе. Если построить график зависимости ВР от.v, получится прямая линия. Ее можно описать уравнением BP=(e+r)+(s с). Таким образом, наклон этой линии будет равен с. Иными словами, если бы какой-нибудь испытуемый выполнял это задание и мы построили бы график зависимости его ВР при отрицательных ответах от величины стандартного набора, то получилась бы прямая линия. Наклон этой прямой теоретически будет соответствовать тому времени (с), которое испытуемый затрачивает на одно срав-
нение. ВР при 5 = 0- это время, необходимое для того, чтобы закодировать стимул (е) и дать ответ (г). Читателю может показаться странным, что мы сосредоточили все внимание на отрицательных ответах. Это связано с тем, что отрицательный ответ может быть дан лишь после того, как испытуемый сопоставит с контрольным стимулом все элементы стандартного набора; иначе как бы он мог выяснить, что контрольного стимула в этом наборе не было? В случае же положительных ответов картина осложняется, так как испытуемый может прекратить сравнение, обнаружив соответствие одного из элементов стандартного набора контрольному элементу. Он не обязательно произведет все возможные сравнения. Это так называемая гипотеза "самопрекращения": в ней предполагается, что испытуемый прекращает сканирование, как только он найдет элемент, соответствующий контрольному стимулу. Можно выдвинуть и другое предположение, называемое гипотезой "полного просмотра". Согласно этой гипотезе, испытуемый независимо от того, обнаружил он соответствующий элемент или нет, "просматривает" на стадии сравнения весь стандартный набор. Он не прекращает сопоставление, а доводит его до конца. Эта последняя гипотеза интуитивно кажется необоснованной, но тем не менее ее следует проверить.
Решающим критерием при выборе между гипотезами "самопрекращения" и "полного просмотра" служит угол наклона функции ВР (графика зависимости ВР от величины стандартного набора) для положительных ответов. Когда испытуемый обнаруживает соответствие между контрольным стимулом и одним из элементов стандартного набора, в среднем это происходит после просмотра половины набора. В соответствии с гипотезой самопрекращения это означало бы, что в тех случаях, когда ответ положительный, испытуемый прекратит сканирование, дойдя (в среднем) до середины набора, а в случае отрицательного ответа будет доводить этот процесс до конца. Если испытуемый сам прекращает сканирование, то при положительном ответе он производит в среднем (s+\)/2 сравнений. Его ВР при положительных ответах составит е+г+[(.$+1)/2]-с. Если преобразовать эту формулу так, чтобы представить ВР как функцию s (при этом получим BP=(e+r+c/2)+[(c/2)s]), то окажется, что наклон графика для положительных ответов вдвое меньше, чем для отрицательных (с/2 для положительных и с — для отрицательных). В отличие от этого гипотеза полного просмотра утверждает, что этап сравнения при положительных и отрицательных ответах одинаков — в обоих случаях производятся все возможные сравнения - и поэтому такого различия в наклоне графика не должно быть (в обоих случаях наклоны будут равны с).
Теперь у нас имеются три гипотезы. Одна из них - это гипотеза параллельного сканирования, которая предсказывает, что зависимость ВР от s будет выражаться горизонтальной прямой как для положительных, так и для отрицательных ответов (рис. 5, А). Две другие гипотезы — это варианты гипотезы последовательного сканирования, согласно которой сравнения производятся по одному, а ВР возрастает с увеличением числа элементов в стандартном наборе (рис. 5, Б). В одном из вариантов предполагается, что сканирование — процесс самопрекращаю-
щийся. В этом случае наклон фафика для положительных ответов будет вдвое меньше, чем для отрицательных. Согласно другому варианту, сканирование носит исчерпывающий характер и никакого различия между графиками для положительных и отрицательных ответов быть не должно.
Для того чтобы установить, насколько обоснованны эти гипотезы, мы должны провести эксперимент. Нужно собрать данные о величине ВР для нескольких испытуемых, каждый из которых проделал по многу проб. Среди проб должны быть как положительные, так и отрицательные, и проводиться они должны при нескольких различных размерах стандартного набора. Затем следует вывести среднее время реакции для проб каждого типа - положительных и отрицательных - и для каждого из стандартных наборов. После этого нужно построить графики зависимости ВР от.?. Именно это проделал Стернберг и полученные результаты представлены на рис 5, В. Из всего сказанного выше следует, что его данные говорят в пользу гипотезы последовательного исчерпывающего сканирования.
То обстоятельство, что результаты Стернберга подтверждают эту гипотезу, представляет особый интерес, поскольку, как мы заметили, гипотеза полного просмотра противоречит нашим интуитивным ожиданиям. Напомним, что, согласно этой гипотезе, испытуемый независимо от того, обнаружил ли он соответствие одного из элементов стандартного набора контрольному стимулу или нет, всегда сравнивает с этим стимулом все элементы стандартного набора. Он не прекращает сравнений, если обнаружит соответствие. А это, казалось бы, означает, что в случае положительного ответа, т. е. при нахождении соответствия, испытуемый производит много ненужных сравнений.
Тем не менее исчерпывающему сканированию можно найти объяснение. Для этого прежде всего разделим происходящий при сканировании процесс сравнения на два компонента. Один из них - это акт сравнения как таковой, другой — принятые решения относительно результатов сравнения. Если при сравнении обнаружилось соответствие между одним из элементов стандартного набора и контрольным стимулом, то решение будет положительным, ведущим к положительному ответу. В противном случае ответ будет отрицательным.
Посмотрим теперь, что произойдет, если время, которым располагает испытуемый для сравнения контрольного стимула с элементами стандартного набора, будет очень коротким, а время, в течение которого он должен решить, привело ли это сравнение к положительному результату, — относительно более долгим. В случае самопрекращающегося процесса его продвижение по стандартному набору можно было бы представить следующим образом: сравни, решай, сравни, решай и т.д. до тех пор, пока не будет обнаружено соответствие (принято решение "да") или пока не будет исчерпан стандартный набор. Исчерпывающий же процесс будет иметь вид: сравни, сравни, сравни и т.д., а затем — когда стандартный набор будет исчерпан — решай. Если принятие решения занимает намного больше времени, чем сравнение, то нетрудно понять, что исчерпывающее сканирование может оказаться более вы-
годным: оно требует только однократного принятия решения. Таким образом, исчерпывающее сканирование будет более эффективным в том случае, если испытуемый может производить сравнения очень быстро — так быстро, что ему было бы трудно останавливаться для того, чтобы принимать решения. Вместо этого испытуемый "проносится пулей" по всему набору и только после этого принимает решение и дает ответ.
Если такое объяснение исчерпывающего сканирования верно, то сравнение должно занимать очень мало времени. Это можно проверить по данным о ВР, вычислив наклон графика зависимости ВР от величины стандартного набора; теоретически этот наклон соответствует времени, которое нужно затратить на сравнение контрольного стимула с одним элементом стандартного набора. Подсчет показывает, что фактические данные подтверждают предположение об очень быстром сравнении. Из данных,











