Матрица попарных расстояний между объектами. Схожие объекты чаще лежат в одном классе, чем в разных.
Алгоритмы:
• метод ближайших соседей;
• метод парзеновского окна;
• метод потенциальных функций;
• метод радиальных базисных функций;
• отбор эталонных объектов;
· метод комитетов.
Метод потенциальных функций
Теорема: для любой обучающей выборки можно построить потенциальную функцию с качеством распознавания 100%.
Пусть даны попарно не пересекающихся множеств из пространства. Свяжем с каждой точкой из этих множеств некоторую функцию, аналогичную по форме электрическому потенциалу, т. е. максимальную в этой точке и убывающую по всем направлениям от нее (точка, таким образом, окажется как бы источником потенциала). Такой функцией может быть, например, функция 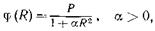
где P — коэффициент, называемый весом точки; R — расстояние между точкой-источником и точкой, в которой вычисляется потенциал. Величину в каждой точке пространства можно считать мерой близости этой точки к точке-источнику.
Пусть источниками служат точки 1-го образа. Тогда создаваемый в данной точке пространства всеми точками средний потенциал, т. е. суммарный потенциал, деленный на число источников (называемый потенциалом 1-го образа), будет характеризовать близость данной точки ко всему образу в целом.
Аналогично определим в этой же точке пространства потенциалы 2-го,.., k -го образов. Естественно будет отнести точку к тому образу, чей потенциал в этой точке является наибольшим.
Будем распознавать точки из обучающего множества. Если возникает такая ситуация, что некоторые точки из множества неправильно распознаются, т. е. будут отнесены не к своему образу, то увеличением весов этих точек можно достигнуть правильного распознавания всех точек множества. Таким образом, процесс обучения сводится к подбору весовых коэффициентов точек обучающего множества.
Метод комитетов
Отыскиваемая разделяющая поверхность(решающее правило) имеет две стороны – «положительную» и «отрицательную», причем образ М находится по положительную сторону от разделяющей поверхности, а образ N – по отрицательную сторону. При этом при выделении образов используется процедура типа «голосование». Окончательное разделение множества на два образа принимается «большинством голосов». Затем, для каждого из выделенных множеств М и N вычислительная процедура последовательно повторяется по этому же алгоритму. Процесс вычисления завершается при достижении заданного уровня близости характеристик точек (объектов) в каждом образе.
Можно использовать след. определение:
Комитетом поверхностей данного класса, разделяющим регионы М и N, называется такая конечная совокупность { T 1, Т 2,..., Т q} поверхностей этого класса (с указанием положительной и отрицательной сторон), что регион М находится по положительную сторону более чем половины поверхностей T 1, Т 2,..., Т q, а регион N – по отрицательную сторону более чем половины этих же поверхностей.
Теоремы.
Теорема Новикова: для любой обучающей непротиворечивой непересекающейся выборки(A* Ụ B*) можно построить линейную функцию(решающее правило) за конечное время с качеством распознавания 100%. A* и B* - выпуклые непустые множества, A* принадлежит A, B* принадлежит B.
Теорема Мазурова: для любой обучающей непротиворечивой выборки(A* Ụ B*) можно построить однородный комитет за конечное время, ρ об=ρ0 заданное. A* и B* - непустые множества, A* принадлежит A, B* принадлежит B.
Теорема Лациса:
Любую практическую задачу можно решить 1 алгоритмом из 4 классов:
1)Метод потенциальных функций
2)Метод комитетов
3)Метод логических функций
4)Метод статистических функций
Любые 2 алгоритма класса будут распознавать с одинаковой вероятностью. Для решения достаточно 4 любых алгоритма из существующих классов, из них взять лучший.
11. Основные принципы и задачи анализа изображений.
Определение изображения, отличие изображения от вектора объекта в распознавании образов. Архитектура пакета Анализа изображений. Современное состояние анализа изображений.
Основные задачи
Предварительная обработка изображения: сегментация, построение гистограмм яркости, бинаризация, удаление шумов, выделение контура, описание информативных признаков объектов, анализ данных, распознавание, краткое описание объектов.
Основные принципы анализа изображений:
1. захват и улучшение изображения(преобразование в электрический сигнал, пригодный для оцифровки и хранения в памяти компьютера)
2. сегментация (бинаризация - преобразование в чёрно-белое изображение)
3. обнаружение объектов (идентификация - выделение какого-либо индивидуального признака для каждого объекта),
4. измерение
Определение изображения.
Изображение(растровый экран) – множество пикселей, функция от x,y.Характеризуется яркостью и координатами. Много лишней информации(фон).
Пиксель – точка изображения.
Отличие изображения от вектора объекта в распознавании образов.
Совокупность признаков, относящихся к одному объекту, называется вектором признаков.
Любое изображение можно представить в виде вектора, а значит и в виде точки некоторого пространства признаков. Значит изображение можно отнести к какому-либо образу, как и объект.
Архитектура пакета анализа изображений:
Изображение => Предварительная обработка => Описание объектов(Сущ. признаки) =>Распознавание = Вектор
Современное состояние анализа изображений.
• новое интерактивное приложение для просмотра в системе MATLAB видео или последовательностей изображений;
• новое программируемое приложение GUI для интерактивного перемещения и манипуляции областью интереса;
• Image Tool включает интерактивные операции масштабирования и контрастирования;
• поддержка считывания изображения с большим динамическим диапазоном яркостей.
12. Предварительная обработка изображений. Какие задачи и как решаются предварительной обработкой изображений? Что такое эвристика? Пиксель.
На настоящее время существуют общепризнанные два класса алгоритмов:
1. класс выделения границ, анализ формы контуров;
2. класс анализа внутренних свойств объекта, текстура.
Задачи:
1)Сегментация — это процесс выделения объектов и границ на изображениях.
2)Гистограмма интенсивности – соотношение между количеством пикселей и интенсивностью для каждого объекта изображения и фона.
3)Пороговая функция. С помощью пороговой функции делаем цветное изображение черно- белым. Пороговая функция выбирается обычно I> Iфон.

4)Бинаризация – перевод изображения в чёрно-белое.
5)Избавление от шума, резкость границ.(Пороговые и медианные фильтры).
6)Выделение контуров с помощью пороговой функции(Толщина линии 3-5 px).Алгоритм жук.
7)Сглаживание.
8)Компактное описание геометрических признаков контура.
Эвристика – отличный от алгоритмического метод решения сложных задач, основанный на неформальных правилах опытных специалистов. Это алгоритм, который хорошо решает задачу в определённой области, но область математически не прописана, и не известно, насколько хорошо алгоритм будет работать для другой задачи.
Пи́ксель — наименьший логический элемент двумерного цифрового изображения в растровой графике, точка изображения. Пиксели расположены в изображении по строкам и столбцам.
13. Отличие звука и изображения. Цифровая обработка сигналов. Теорема Котельникова. Частота, необходимая для устойчивого распознавания речи. Фурье преобразование звукового сигнала. Кодовая книга. Алгоритм распознавания речи. Примеры фильтров (эвристик).
Цифрова́я обрабо́тка сигна́лов — преобразование сигналов, представленных в цифровой форме.
Любой непрерывный (аналоговый) сигнал

может быть подвергнут дискретизации по времени и квантованию по уровню (оцифровке), то есть представлен в цифровой форме. При помощи математических алгоритмов

преобразуется в некоторый другой сигнал

, имеющий требуемые свойства. Процесс преобразования сигналов называется фильтрацией(извлечение информации и подавление шумов).
Даже оцифрованный сигнал занимает много места, и следующий шаг обработки заключается в сжатии сигнала.
Теорема Котельникова.
На входе аналоговый сигнал, превращается в дискретный, информация сохраняется, чтобы можно было вернуться назад.
Если сигнал таков, что его спектр ограничен частотой F сверху, то после дискретизации сигнала с частотой не менее 2F можно восстановить исходный непрерывный сигнал по полученному цифровому сигналу без потери точности.
Преобразование Фурье
Эквивалентность частотно-временных преобразований однозначно определяется через преобразование Фурье.
Преобразование Фурье рассматривается как обратимый переход от временно́го пространства в частотное пространство.
Если исходный сигнал задан функцией  , заданной на всей вещественной оси, то его преобразование Фурье задается формулой
, заданной на всей вещественной оси, то его преобразование Фурье задается формулой
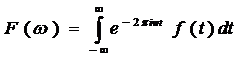

Функция  или ее модуль трактуется как интенсивность исходного сигнала на частоте
или ее модуль трактуется как интенсивность исходного сигнала на частоте  .
.
Выбор частоты преобразования
Так как звуки человеческой речи лежать в диапазоне частот 300-4000 Гц, то минимально необходимая частота преобразования составляет 8000 Гц. Однако многие компьютерные программы распознавания речи используют стандартную для обычных звуковых адаптеров частоту преобразования 44 000 Гц. С одной стороны, такая частота преобразования не приводит к чрезмерному увеличению потока цифровых данных, а другой — обеспечивает оцифровку речи с достаточным качеством.
Кодовая книга 
Записываются эталонные речевые фрагменты, разбиваются на элементарные составляющие (отрезки речи, в течении которых можно считать параметры речевого сигнала постоянными) и для каждого из них вычисляются значения характерных признаков. Они кластеризуются и записываются в кодовую книгу.
Алгоритм распознавания речи
· Алгоритмы динамического программирования.
Сравниваются эталонный элемент E и описание распознаваемого слова X. Задача сводится к поиску оптимальной траектории на плоскости, минимизирующей различие E и X.
Скрытая Марковская модель (СММ) — статистическая модель, задачей ставится разгадывание неизвестных параметров на основе наблюдаемых.
Алгоритм «прямого-обратного» хода —алгоритм, вычисляющий вероятность специфической последовательности наблюдений.
Алгоритм включает три шага:
o вычисление прямых вероятностей
o вычисление обратных вероятностей
o вычисление сглаженных значений
Сначала алгоритм продвигается, начиная с первого наблюдения в последовательности и идя в последнее, и затем возвращается назад к первому. При каждом наблюдении вычисляются вероятности последовательности, которые будут использоваться для вычислений при следующем наблюдении. Во время обратного прохода алгоритм одновременно выполняет шаг сглаживания. Сглаживание позволяет алгоритму принимать во внимание все прошлые наблюдения для того, чтобы вычислить более точные результаты.
14. База анализа изображений. По каким принципам она устроена?

В блоке предварительной обработки происходит бинаризация изображения, построение гистограмм и пороговых функций, фильтрация шумов, выделение границ, формирование линий, контуров объектов, выделение существенных признаков границ.
Описание объектов: список граничных пикселей, список линий, компактное описание контуров объектов, существенные признаки объектов.
Распознавание объектов на основе их существенных признаков с помощью базы знаний.
15. История и перспективы нейронных сетей. Персептрон. Нейрон. Следствие из теоремы Колмогорова. Принципы и алгоритмы построения нейронной сети.
В 1943 Мак-Каллок и Питтс разработали компьютерную модель нейронной сети на основе математических алгоритмов.
В 1957 Ф.Розенблатт разработал персептрон — математическую и компьютерную модель восприятия информации мозгом, на основе двухслойной обучающей компьютерной сети, использующей действия сложения и вычитания.
С 2006 было предложено несколько неконтролируемых процедур обучения нейронных сетей с одним или несколькими слоями с использованием так называемых алгоритмов глубокого обучения.
В последнее время предпринимаются активные попытки объединения искусственных нейронных сетей и экспертных систем. Нейросетевые прикладные пакеты, разрабатываемые рядом компаний, позволяют пользователям работать с разными видами нейронных сетей и с различными способами их обучения.
Области применения нейронных сетей весьма разнообразны — это распознавание текста и речи, семантический поиск, экспертные системы и системы поддержки принятия решений, предсказание курсов акций, системы безопасности, анализ текстов.
Эпоха настоящих параллельных нейровычислений начнется с появлением на рынке большого числа аппаратных реализаций.
Нейронная сеть – взвешенный орграф с входом и выходом.Серый ящик, определяющий класс функций.
 Нейрон представляет собой единицу обработки информации в нейронной сети. Это линейная функция от суммы, вес в графе(нейронной сети).
Нейрон представляет собой единицу обработки информации в нейронной сети. Это линейная функция от суммы, вес в графе(нейронной сети).
В этой модели нейрона можно выделить три основных элемента:
• синапсы, каждый из которых характеризуется своим весом или силой.
• сумматор, аналог тела клетки нейрона.
• функция активации, определяет окончательный выходной уровень нейрона.
персептрон — математическая и компьютерная модель восприятия информации мозгом, на основе двухслойной обучающей компьютерной сети, использующей действия сложения и вычитания.
Теорема Колмогорова:
Если рассматривать n-мерный куб и непрерывная функция заданая на вершинах, то любая точка внутри куба аппроксимируется его вершинами.
Следствие: любую функцию можно представить в виде нейронный сетей => любую задачу можно решить с помощью нейронных сетей.
Принципы нейронных сетей:
o Принцип коннекционизма означает, что каждый нейрон нейросети, как правило, связан со всеми нейронами предыдущего слоя обработки данных
o Нелинейность выходной функции активации
o Локальность и параллелизм вычислений
o Обучение, основанное на данных
o Универсальность обучающих алгоритмов
Для обучения нейронных сетей применяются алгоритмы двух типов: управляемое ("обучение с учителем") и не управляемое ("без учителя").
Общая схема обучения с учителем выглядит так:
1. Перед началом обучения весовые коэффициенты НС устанавливаются некоторым образом, на пример - случайно.
2. На первом этапе на вход НС в определенном порядке подаются учебные примеры. На каждой итерации вычисляется ошибка для учебного примера  (ошибка обучения) и по определенному алгоритму производится коррекция весов НС. Целью процедуры коррекции весов есть минимизация ошибки
(ошибка обучения) и по определенному алгоритму производится коррекция весов НС. Целью процедуры коррекции весов есть минимизация ошибки  .
.
3. На втором этапе обучения производится проверка правильности работы НС. На вход НС в определенном порядке подаются контрольные примеры. На каждой итерации вычисляется ошибка для контрольного примера  (ошибка обобщения). Если результат неудовлетворительный то, производится модификация множества учебных примеров и повторение цикла обучения НС.
(ошибка обобщения). Если результат неудовлетворительный то, производится модификация множества учебных примеров и повторение цикла обучения НС.
В алгоритме обратного распространения вычисляется вектор градиента поверхности ошибок. Алгоритм линейного поиска выбирает направление и ищет на ней миниум, затем повторяет действие. Алгоритм сопряжённых градиентов поскольку мы нашли точку минимума вдоль некоторой прямой, производная по этому направлению равна нулю. Сопряженное направление выбирается таким образом, чтобы эта производная и дальше оставалась нулевой.
Неуправляемое обучение. (Алгоритм Кохонена)
Алгоритм Кохонена дает возможность строить нейронную сеть для разделения векторов входных сигналов на подгруппы. Используется при заранее определённом количестве кластеров.
Шаг 1. Инициализация сети: весовым коэффициентам сети присваиваются малые случайные значения.
Шаг 2. Предъявление сети нового входного сигнала.
Шаг 3. Вычисление расстояния d до всех нейронов сети.
Шаг 4. Выбор нейрона с наименьшим расстоянием.
Шаг 5. Настройка весов нейрона j* и его соседей.
Шаг 6. Возвращение к шагу 2.
16. Основные подходы к построению нейронных сетей. Какие задачи необходимо решить при построении НС. Современные оболочки для моделирования нейронных сетей (МАТЛАБ).
Подходы:
Логический подход.
Основой служит Булева алгебра. Практически каждая система ИИ, построенная на логическом принципе, представляет собой машину доказательства теорем.
Под структурным подходом подразумеваются попытки построения ИИ путем моделирования структуры человеческого мозга.
Довольно большое распространение получил эволюционный подход. При построении систем ИИ по данному подходу основное внимание уделяется построению начальной модели, и правилам, по которым она может изменяться (эволюционировать).
Еще один широко используемый подход к построению систем ИИ — имитационный. Данный подход является классическим для кибернетики с одним из ее базовых понятий - "черным ящиком" (ЧЯ). Объект, поведение которого имитируется, представляет собой такой "черный ящик".
Задачи(этапы):
• Сбор данных для обучения;
• Подготовка и нормализация данных;
• Выбор топологии сети;
• Экспериментальный подбор характеристик сети;
• Экспериментальный подбор параметров обучения;
• Собственно обучение;
• Проверка адекватности обучения;
• Корректировка параметров, окончательное обучение;
• Вербализация сети с целью дальнейшего использования









