В большинстве случаев основой для построения ЯМ является аппарат статистических методов. Качество статистических ЯМ оценивается с помощью коэффициента неопределенности (perplexitycoefficient)[BahlL.R. 1977]. Коэффициентнеопределенности может быть интерпретирован как (геометрическое) среднее ветвление в данной модели[GibbonD., MooreR., WinskiR., 1998]. Для N-граммной модели коэффициент неопределенности рассчитывается по формуле:

|
(1.6)
|
wi1, wi2,…,wiN– естественный язык, заданный некоторым корпусом текстов.
Коэффициент неопределенности является функцией от построенной языковой модели и естественно языка (текстового корпуса). При фиксированном языке он позволяет сравнивать различные языковые модели, а при фиксированном типе модели – оценивать сложность самих естественных языков.
4.2.5. Способы определения произнесения слов не из словарясистемы
Звуковой сигнал, поступающий на вход системы распознавания речи, зачастую содержит различного рода помехи: шумы, неречевые звуки (смех, кашель, дыхание), речь посторонних лиц, различные нарушения речевого потока (оговорки, «эканья»), а также слова, которые не входят в словарь системы. Влияние этих факторов приводит к ошибкам распознавания. Одной из ключевых задач системы распознавания речи является определение и отсеивание перечисленных помех.
Существует два основных подхода к решению названной задачи: вычисление оценок правдоподобия (или просто подобия) и манипуляции со словарем и грамматикой системы.
Метод вычисления оценок подобия заключается в расчете для каждого распознанного слова числовой характеристики, соответствующей уровню уверенности его корректного распознавания. Полученная характеристика сравнивается с порогом и, если значение характеристики выше порога, принимается решение о правильном распознавании. В противном случае слово считается распознанным неверно.
Оценки подобия можно разделить на три группы: простые характеристики, апостериорная вероятность и отношения правдоподобия.
Манипуляции со словарем и грамматикой заключаются в добавлении в словарь и грамматику системы специальных акустических моделей, отождествляемых с помехами. Соответственно, если распознается специальная модель, принимается решение об ошибочном распознавании и наоборот. Особенность подхода состоит в том, что определение СНИС выполняется непосредственно в процессе распознавания и не требует применения дополнительных вычислительных алгоритмов. Два основных направления манипуляций: оптимизация словаря и модели заполнения.
Для оптимизации словарь необходимо дополнить "словами" двух типов: модели-шумы и слова-антимодели. Первые отсеивают ошибочно выделенные детектором речевой активности звуки, вторые – «вытесняют» мало- похожие на звук слова из списка результатов распознавания.
Модели-шумы весьма эффективны в отсеивании различных щелчков, стуков, скрипов, жужжаний и даже дыхания. Однако, для борьбы с более сложными шумами они оказываются малопригодными.
Модели-шумы хорошо отсеивают "артефакты", возникающие из-за ложных срабатываний детектора речевой активности, поэтому с увеличением точности алгоритмов VAD их актуальность сокращается. Кроме того, ресурсоемкость Моделей-шумов на порядок выше ресурсоемкости VAD.
Слова-антимодели могут формироваться по двум основным принципам. В первом случае для каждого СИС строится слово-антимодель, во втором – строится несколько слов-антимоделей на весь словарь.
Первый вариант требует значительных вычислительных ресурсов, т.к. рабочий словарь системы фактически удваивается. Эксперименты показали, что использование небольшого статического набора слов-антимоделей не дает желаемого результата, а увеличение их количества приводит к падению производительности системы.
За счет оптимизации словаря обычно не удается достичь удовлетворительного процента отсеивания СНИС при допустимом падении процента распознавания СИС и производительности.
Этапы синтеза речи
Основными направлениями современных исследований в области автоматического синтеза речи являются аудиовизуальный синтез, синтез экспрессивной и эмоциональной речи, а также объединение двух подходов к синтезу речи третьего поколения: селективного синтеза и синтеза на основе скрытых Марковских моделей – так называемый гибридный синтез. Наиболее часто в гибридном синтезе от селективного синтеза берётся та часть, которая отвечает за подбор и соединение элементов конкатенации из речевой базы, поскольку соединяются элементы естественной речи–тем самым и синтезированная речь звучит более естественно. Значения физических параметров (длительности, энергии и ЧОТ звука), необходимые для оптимального селективного подбора элементов конкатенации, определяются не по созданным вручную правилам, а порождаются автоматически моделями, обученными на той же речевой базе, что позволяет быстро настроить просодическое оформление речи на нового диктора.
В настоящее время системы, основанные на так называемой технологии unit selection или, иными словами, технологии селективного синтеза речи, обеспечивают получение наиболее естественной синтезированной речи.
Алгоритм Unit selection
Селективный синтез речи является разновидностью конкатенативного синтеза, то есть при генерации речевого сигнала используются заранее полученные звукозаписи естественной речи. Вотличие от более раннихаллофонных или дифонных синтезаторов речи,порождающих итоговый речевой сигнал из отдельных и специально подготовленных звуковых единиц, выделенных из небольшого и тщательно подобранного набора озвученных слов, при селективном синтезе для каждой целевой единицы синтеза производится выбор наиболее подходящего кандидата из множества вариантов, взятых из озвученных диктором предложений естественного языка. Для этого записываются специальные речевые базы, размер которых можетдостигать нескольких десятков часов звучания[Black 2002].В процессеакустического синтеза алгоритм селекции (выбора) строит оптимальную последовательность звуковых единиц, выбранных из речевой базы, (рис. 1.9), учитывая одновременно и то, насколько кандидат подходит под описание необходимых характеристик целевого звука (стоимость замены), и то, насколько хорошо выбранные элементы будут конкатенироваться с соседними (стоимость связи). При этом с учетом указанных стоимостей из базы в качестве оптимальныхмогут быть выбраны не отдельные звук и, а их цепочки или даже целые предложения. Такой подход позволяет минимизировать необходимость модификаций речевого сигнала (или даже полностью от них отказаться), что повышает естественность синтезируемой речи.

Рисунок 1.9 - Выбор целевой звуковой последовательности при селективном синтезе речи
В то же время именно из -за тенденции к минимизации акустических модификаций одной из особенностей селективного синтеза является возможность частичного или даже полного несоответствия характеристик выбираемых единиц - кандидатов целевым характеристикам, необходимым для синтеза. Поэтому при тестировании селективного синтеза особенно важным является раздельное тестирование лингвистической обработки текста в целях его дальнейшего озвучивания и собственно акустического модуля синтеза выходного речевого сигнала.
При селективном синтезе происходит выбор групп наиболее подходящих звуковых элементов из базы синтезатора на основе значений акустических характеристик, вычисленных для каждого аллофона[Clark et al. 2007].Для того чтобы определить, насколько тот или иной элемент базы подходит для синтеза целевой звуковой единицы, вводятся понятия стоимости замены (target cost) и стоимости связи (join/concatenation cost).
Стоимость замены для элемента из базы ui по отношению к целевому элементу ti вычисляется по формуле:
 , (1.7)
, (1.7)
где:
 — расстояние между k -ыми характеристиками элементов (способ его вычисления зависит от конкретной характеристики)
— расстояние между k -ыми характеристиками элементов (способ его вычисления зависит от конкретной характеристики)
 — вес k-ой характеристики (может подбираться опытным путём или настраиваться автоматически).
— вес k-ой характеристики (может подбираться опытным путём или настраиваться автоматически).
Иными словами, стоимость замены равна взвешенной сумме различий в признаках между целевым элементом и конкретным элементом речевой базы. В качестве признаков могут выступать любые просодические и лингвистические характеристики элементов. Как правило, используется следующая информация: частота основного тона (ЧОТ), длительность, контекст, позиция элемента в слоге, слове, количество ударных слогов во фразе и др.
Выбранные из базы элементы должны не только мало отличаться от целевых, но и хорошо соединяться (конкатенироваться) друг с другом. Функция стоимости связи двух элементов в цепочке может быть определена как взвешенная сумма различий в признаках между двумя последовательно выбранными кандидатами:
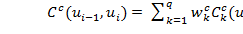 , (1.8)
, (1.8)
где:
 — расстояние между k-ми характеристиками элементов,
— расстояние между k-ми характеристиками элементов,  — вес для k-ой характеристики.
— вес для k-ой характеристики.
Общая стоимость связи для целой последовательности из n элементов равна сумме введенных выше стоимостей:
 , (1.9)
, (1.9)
Задача алгоритмаunitselection состоит в том, чтобы выбрать такоемножество элементов  , которое бы минимизировало общую стоимость полученной цепочки согласно формуле (1.9).различных селективных синтезаторах могут варьировать ся минимальные звуковые элементы базы: это могут быть аллофоны, дифоны, полуфоны, слогит. д. Также в разных селективных синтезаторах может использоваться различный набор характеристик, по которым подбираются эти элементы, способы и алгоритмы настройки весов для них[Vepa 2004; Vepa, King 2004].
, которое бы минимизировало общую стоимость полученной цепочки согласно формуле (1.9).различных селективных синтезаторах могут варьировать ся минимальные звуковые элементы базы: это могут быть аллофоны, дифоны, полуфоны, слогит. д. Также в разных селективных синтезаторах может использоваться различный набор характеристик, по которым подбираются эти элементы, способы и алгоритмы настройки весов для них[Vepa 2004; Vepa, King 2004].
На заключительном этапе синтеза происходит объединение выбранной последовательности элементов в звуковой поток, представляющий собой синтезированную речь.






