ВВЕДЕНИЕ
Тематика научно-исследовательской работы определяется темой магистерской диссертации студента. Работа проводится в научно-исследовательских организациях, научно-исследовательских подразделениях производственных предприятий и фирм, специализированных лабораториях университета, на базе научно-образовательных и инновационных центров.
Научно-исследовательская работа магистрантов представляет собой комплекс мероприятий, направленных на освоение студентами в процессе обучения по учебным планам и сверх них методов, приемов и навыков выполнения исследований и анализа, развитие способностей к научному и техническому творчеству, самостоятельности и инициативы.
Научно-исследовательская работа осуществляется в соответствии с рабочим учебным планом магистерской образовательной программой направления 09.04.02 - "Информационные системы и технологии" и индивидуальным планом подготовки магистранта. Работа проходит под контролем научного руководителя магистранта и руководителя научно- исследовательского подразделения.
Цели и задачи
Цели научно-исследовательской практики
Основная цель научно-исследовательской работы – подготовить студента-магистранта к самостоятельной научно-исследовательской работе, основным результатом которой является написание и успешная защита магистерской диссертации.
Задачи научно-исследовательской практики
В процессе выполнения научно-исследовательской работы стоят следующие задачи:
1. вести библиографическую работу с привлечением современных информационных технологий;
2. формулировать и разрешать проблемы (вопросы), возникающие в ходе выполнения научно-исследовательской работы;
3. выбирать необходимые методы исследования (модифицировать существующие, разрабатывать новые методы), исходя из задач конкретного исследования;
4. применять современные информационные технологии при проведении научных исследований;
5. обрабатывать полученные результаты, анализировать и осмысливать их (при подготовке отчета по научно-исследовательской работе, тезисов докладов, научных статей, ВКР);
6. получить другие навыки и умения, необходимые студенту-магистранту данного направления, обучающемуся по конкретной магистерской программе.
Задание для научно-исследовательской практики
Задание на научно-исследовательскую практику включает следующие задачи:
1. Проанализировать перспективные направления развитиятехнологий распознавания и синтеза русской речи.
2. Определить и проанализировать программное обеспечение, ориентированное на реализацию технологий распознавания и синтеза русской речи.
3. Сформировать план проведения исследований технологий распознавания и синтеза русской речи.
Увеличение спроса на услуги голосовой биометрии
Изначально, слово «биометрия» встречалось только в медицинской теории. Тем не менее, стали возрастать потребности в безопасности с использованием биометрических технологий среди предприятий и российских государственных учреждений. Использование биометрических технологий – один из ключевых факторов на мировом рынке распознавания речи. Распознавание голоса используется проверки подлинности человека, так как голос каждого человека индивидуален. Это обеспечит высокий уровень точности и безопасности. Распознавание голоса имеет большое значение в финансовых институтах, таких как банк, а также на предприятиях в сфере здравоохранения. В настоящее время сегмент распознавания речи составляет 3,5% от доли технологий биометрии на мировом рынке, но это доля имеет постоянный рост. Также низкая стоимость биометрических устройств увеличивает спрос со стороны малого и среднего бизнеса.
VoiceNavigator Web
Навигация по веб-ресурсам при помощи голоса. Разработка компании «Центр речевых технологий», позволяет управлять навигацией сайта при помощи речевых команд. Характеристики данной системы распознавания идентичны характеристикам VoiceNavigator.
ViaVoice (компания «IBM»)
ViaVoice представляет собой программное ядро для аппаратных реализаций. Компания ProVox Technologies на основе этого ядра создала систему для диктовки отчетов врачей-радиологов VoxReports.
Характеристики:
· точность распознавания достигает 95-98%;
· дикторонезависимость;
· словарь системы ограничен набором специфических терминов.
Рассмотрев сравнительные характеристики современных систем распознавания речи, можно сделать следующие выводы:
· наиболее перспективными разработками на российском рынке являются продукты компании «Центр речевых технологий» (ЦРТ);
· большинство популярных на сегодняшний день систем распознавания работаютс изолированными словами;
· разработчики достигли высокой точности в командных системах (речевые интерфейсы, голосовое управление);
· в наиболее распространенных современных приложениях точность распознавания составляет в среднем 95-99%;
· задача распознавания слитной речи в достаточной степени не решена.
Результаты сравнительного анализа систем распознавания речи представлены в таблице 1.
Таблица 1 - Результаты сравнительного анализа систем распознавания речи
| Название системы
| Назначение
| Структурная
единица
| Обучение
| Поддержка русского языка
| Дикторонезависимость
| Коэфф. расп.
|
| VoiceNavigator,
VoiceNavigator Web
| Командная
система, речевой интерфейс,
распознавание речи
| Слово, фраза
| Да
| Да
| Да
| 97%
|
| Speereo Speech Recognition
| Голосовое
управление
| Слово
| Нет
| Да
| Да
| 95%
|
| Sakrament ASR Engine
(Сакрамент)
| Речевой
| -
| Нет
| Да
| Да
| 95%
|
| интерфейс
|
| Google Voice Search
| Голосовой поиск
| Слово, фраза
| Нет
| Да
| Да
| -
|
| Dragon NaturallySpeaking
| Голосовое
управление,
распознавание речи
| -
| Нет
| Нет
| Нет
| 98%
|
| ViaVoice, VoxReports
| Голосовое
управление,
распознавание речи
| -
| Нет
| Нет
| Да
| 95%
|
Этапы распознавания речи
В общем случае распознавание разделяется на пять основных этапов: членение речевого потока, вычисление акустических признаков, сравнение признаков со звуковыми моделями (распознавание слов), определение произнесения слов не из словаря системы, языковое моделирование. Для каждого этапа распознавание характерно применение определенного набора методов, моделей и алгоритмов обработки речевого потока.
На рисунке 1 представлено соответствие между этапами распознавания и основными методами алгоритмами, применяемыми на них. Рассмотрим подробнее, перечисленные методы и алгоритмы.

Рисунок 1.1 - Соответствие этапов распознавания методам и алгоритмам обработки речи
Членение речевого потока
Одним из условий надежного распознавания речевых фрагментов является точное определение их границ. При высоких значениях соотношения сигнал/шум (30 дБ и более) выделение не представляет технических трудностей и может выполняться пороговым старт-стоповым методом. Однако, в большинстве реальных задач соотношение сигнал/шум значительно ниже и требуется применение специальных методов определения речевой активности.
Обычно используются известные алгоритмы определения речевой активности (VAD), подробно описанные в рекомендациях ITUT [G.729, G.723] и их модификации. Дополнительно могут применяться алгоритмы фильтрации выбросов VAD [Гусев 2008].
Дальнейшее членение выделенных речевых фрагментов на аллофоны (слова, синтагмы или фразы) представляется весьма затруднительным и неоднозначным. Это объясняется отсутствием явных физических границ между элементами речевого потока. Детальная сегментация может быть выполнена при участии более высоких уровней системы распознавания речи.
Эвристический подход
Метрика – это способ определения расстояния между параметрами входящего звукового потока и параметрами моделей звуков. Чем меньше расстояние, тем более похожими являются речевой сигнал и модель звука. От выбора метрики во многом зависит эффективность и точность распознавания.
Нормализация темпа речи
Одной из задач в распознавании речи является нейтрализация изменчивости темпа речи в процессе сравнения входящего речевого потока с моделями звуков. При сравнении необходимо совмещать соответствующие участки звуков, и только потом определять расстояния. В результате многочисленных экспериментов по нормализации темпа речи был сделан вывод о нелинейном характере деформаций темпа речи.
В рамках эвристического подхода нормализация темпа речи осуществляется с использованием таких методов и алгоритмов, как динамическое программирование, градиентный спуск. Рассмотрим их подробнее.
Метод градиентного спуска
Метод градиентного спуска – это метод оптимизации функции многих переменных[Косарев 1986, Туркин 1984]. Метод основан на том, что градиент функции в каждой точке направлен в сторону ее наискорейшего локального возрастания. Для поиска минимума функции необходимо спускаться в противоположном направлении. Таким образом, все последующие приближения функции получаются из предыдущего смещения в направлении, противоположенном градиенту.
При сравнении модели и реализации звука оптимальную траекторию представляют последовательностью шагов, каждый из которых делается в направлении минимизации функционала. В качестве функционала используется метрика.
При сравнении методом градиентного спуска может использоваться следующее уравнение:

|
(1.3)
|
соответствующее максимально возможному двукратному искажению времени.
В уравнении (1.3) NG определяет пару приращений индексов i и j. Процесс построения траектории сходства показан на рисунке 1.3. Видно, что количество шагов не превышает длин модели и реализации:

Рисунок 1.3 - Определение расстояния между реализацией и моделью звука методом градиентного спуска
Метод градиентного спуска требует меньшего (по сравнению с динамическим программированием) количества вычислительных ресурсов, однако он не гарантирует выявления оптимальной траектории. Кроме того, существует проблема конца траектории, т.к. в общем случае траектория заканчивается не в точке (I, J), а упирается либо в правую, либо в верхние границы. Это означает, что в результате применения алгоритма выполнено частичное сравнения модели и реализации. Для завершения сравнения может использоваться, например, метод штрафных функций при разрешении движения вдоль границ. Также за результат может приниматься взвешенное значение частичногосравнения.
Из-за своих недостатков метод градиентного спуска не получил широкого применения в системах распознавания речи. Основная область его применения – встраиваемые системы реального времени.
Нейронные сети
Нейронная сеть – это сеть с конечным числом слоев из однотипных элементов – аналогов нейронов с различными типами связей между слоями[Уоссерман 1990].Искусственные нейронные сети возникли на основе знаний о функционировании мозга живых существ. Они представляют собой попытку использования моделей биологических процессов в мозге для выработки новых технологических решений.
Наиболее распространенной является модель нейрона МакКаллока- Питса (рисунок 1.4), предложенная в 1943 г[McCulloch W.S. 1943]. Искусственный нейрон имитирует свойства биологического нейрона (рисунок 1.4). Он имеет группу синапсов – однонаправленных входных связей, соединенных с выходами других нейронов, а также аксон – выходную связь, с которой сигнал поступает на синапсы следующих нейронов.

Рисунок 1.4 - Искусственный нейрон
Сигналы синапсов умножаются на весовые коэффициенты, соответствующие синоптической силе. Все произведения суммируются, определяя уровень активации нейрона:

|
(1.4)
|
Выход нейрона есть функция его состояния. Функция называется активационной. МакКаллок и Питтс [Kohonen 1989, McCulloch W.S. 1943] предложили использовать пороговую активационную функцию, возвращающую 1, если уровень активации нейрона выше порога, и 0 – в противном случае. Они доказали, что совокупность параллельно функционирующих нейронов способна выполнять универсальные вычисления, при правильно подобранных весах.
На практике часто используется логическая (сигмоидальная) функция вида:

|
(1.5)
|
α – параметр, определяющий форму функции активации, задаваемый пользователем.
Нейронная сеть может рассматриваться как граф с взвешенными связями, в котором нейроны являются узлами. Но не всякое соединение нейронов работоспособно и целесообразно. Существует несколько работающих и реализованных программно архитектур нейронных сетей (рисунок 1.5). По архитектуре связей нейронные сети могут быть разделены на два класса: сети прямого распространения и рекуррентные сети. Графы сетей прямого распространения не содержат петель, соответственно, рекуррентные сети – это сети с обратными связями.

Рисунок 1.5 - Наиболее распространенные архитектуры нейронных сетей
Сети прямого распространения подразделяются на однослойные и многослойные персептроны, а также на сети радиальных базисныхфункций. Нейронная сеть состоит из входного слоя и выходного слоя. Дополнительно в сети могут присутствовать так называемые скрытые слои. Нейроны скрытых слоев не имеют непосредственных входов исходных данных, их выходы связаны только с входами нейронов выходного и скрытых слоев. Скрытые слои выполняют дополнительное преобразование информации, увеличивая нелинейностьмодели.
В персептронах каждый нейрон использует пороговую или сигмоидальную функцию активации. Доказано, что многослойный персептрон может формировать сколь угодно сложные границы принятия решения и реализовывать произвольные булевы функции [Mitnsky 1969].
Сети, использующие радиальные базисные функции, являются частным случаем двухслойной сети прямого распространения. Каждый элемент скрытого слоя использует в качестве активационной функции радиальную базисную функцию типа гауссовой. Скрытые элементы формируют совокупность функций, которые образуют базисную систему для представления входных примеров в построенном на ней пространстве.
Рекуррентные сети организованы так, что каждый нейрон может получать входную информацию от других нейронов, самого себя и окружающей среды. Такие сети позволяют моделировать нелинейные динамические системы. Среди рекуррентных сетей можно выделить сети Хопфилда, Кохонена и модели теории адаптивного резонанса.
Сети Кохонена обладают свойством сохранения топологии, воспроизводящим важный аспект карт признаков в коре головного мозга животных. Близкие входные данные возбуждают близкие выходные элементы.
Сети Кохонена [Kohonen 1989]могут использоваться для проектирования многомерных данных, аппроксимации плотности и кластеризации. Они также успешно применялись для распознавания речи, обработки изображений, в робототехнике и в задачах управления[Hertz J 1991].
Модели теории адаптивного резонанса — это попытка разрешения противоречия между стабильностью и пластичностью сети. Карпентер и Гроссберг разработали модели теории адаптивного резонанса[Carpenter 1991]. Сеть имеет достаточное число выходных элементов, но они не используются до тех пор, пока не возникнет в этом необходимость. Обучающий алгоритм корректирует имеющийся прототип категории, только если входной вектор в достаточной степени ему подобен. Когда входной вектор недостаточно подобен ни одному существующему прототипу сети, создается новая категория, и с ней связывается нераспределенный элемент с входным вектором в качестве начального значения прототипа. Если не находится нераспределенного элемента, то новый вектор не вызывает реакции сети.
Модель теории адаптивного резонанса может создавать новые категории и отбрасывать входные примеры, когда сеть исчерпала свою емкость. Однако число обнаруженных сетью категорий чувствительно к параметру сходства.
В основе построения сетей Хопфилда лежит функция энергии[Hopfield J.J. 1982]. Основное свойство энергетической функции состоит в том, что в процессе эволюции сети она убывает и достигает локального минимума. Основная область применения сетей Хопфилда – ассоциативная память и комбинаторные задачи оптимизации, которые могут быть сформулированы как задачи оптимизации энергии.
Нейронные сети нашли широкое применение в системах распознавания речи в качестве вспомогательных алгоритмов. Так, нейронные сети успешно используются при расчете локальных метрик[Lippman R.P. 1991]. Способность многослойных персептронов к аппроксимации апостериорной вероятности классов используется в гибридных подходах к распознаванию, основанному на скрытых Марковских моделях, в которых нейронные сети служат для вычисления правдоподобия состояний[Бовбель, Bourlard H. 1990, Morgan N. 1995].
При использовании нейронных сетей для распознавания отдельных фонем, слогов, изолированных команд, не удается получить значительного повышения точности по сравнению с обычными классификаторами. Это объясняется чувствительностью нейронных сетей к нелинейным деформациям темпа речевого сигнала.
Для борьбы с деформациями темпа речи разработаны специальные днамические нейросетевые классификаторы, содержащие линии задержки и узлы, выполняющие временное интегрирование. Считается, что такие классификаторы мало чувствительны к небольшим временным искажениям.
Эксперименты показали эффективность применения динамических нейронных сетей при распознавании акустически схожих слов, согласных и гласных звуков[Бовбель]. Однако, это справедливо только для задач с малым словарём.
Динамическая нейронная сеть с временными задержками представляет собой многослойный персептрон с модифицированными узлами (рисунок 1.6).

Рисунок 1.6 - Узел динамической нейронной сети с временными задержками
Каждый из J входов имеет линию задержки на N значений. Узел суммирует значения, поступающие с входов, и значения, содержащиеся в линиях задержек с учетом весовых коэффициентов, вычисляет порог и нелинейную активационную функцию.
Архитектура трехслойной динамической нейронной сети с временными задержками представлена на рисунке 1.7. Показаны только связи для одного выходного узла.

Рисунок 1.7 - Пример архитектуры динамической нейронной сети с временными задержками
В приведенном примере обработка сетью входной последовательности векторов признаков эквивалентна прохождению окон временных задержек над образами узлов нижнего уровня. Узлы скрытых слоев сети представляют собой движущиеся детекторы признаков, способные обнаруживать требуемые образы в любом месте входной последовательности. Равенство весов связей входных узлов со вторым слоем обеспечивает инвариантность сети к временным сдвигам обучающих и контрольныхвыборок.
Несмотря на разнообразие структур нейронных сетей, самой известной и наиболее распространенной моделью является многослойный персептрон, структурная схема которого представлена на рисунке 1.8.
Нейроны многослойного персептрона разделены на несколько слоев, и не взаимодействуют между собой внутри одного слоя. Каждый нейрон сети (кроме нейронов входного слоя), получает входной сигнал от каждого нейрона предыдущего слоя и выходной сигнал нейрона (кроме последнего слоя) поступает на вход нейронов последующего слоя. Многослойный персептрон является моделью со связями, обеспечивающими распространение сигнала только вперед – от входа к выходу сети. Нейроны обычно функционируют в соответствии с моделью МакКаллока-Питса, в качестве функции активации выбирается сигмоидальная функция (1.16).

Рисунок 1.8 - Пример многослойного персептрона
Существует три способа обучения нейронных сетей: обучение «с учителем», обучение «без учителя» и смешанное обучение. Множество алгоритмов обучения делится на два класса: детерминистских и стохастических. В первых подстройка весов задается жесткой последовательностью действий, во-вторых – производится на основе случайныхпроцессов.
Основным алгоритмом обучения многослойного персептрона является алгоритм обратного распространения ошибки (Back Propagation Error, BP- алгоритм).[Rosenblatt F. 1959]
Скрытые Марковские модели
Основные понятия
Инструментарий для построения Скрытых Марковских Моделей (СММ Hidden Markov Model HMM) может использоваться для моделирования любого временного ряда. Одно из возможных его применений – построение средств обработки речи, в частности, систем распознаванияречи.
Можно выделить две основных стадии обработки речи:
· оценка параметров множества HMM, с использованием обучающих образцов произнесения и соответствующих им транскрипций;
· определение транскрипций, соответствующих неизвестным образцам произнесения.
Речевой сигнал – это некоторое сообщение, кодируемое с помощью последовательности одного или нескольких символов. Для выполнения обратной процедуры по распознаванию последовательности символов речевой сигнал преобразуется в последовательность векторов дискретных параметров. Задача системы распознавания заключается в установлении соответствия между последовательностями векторов параметров и символов.
Языковые модели
Для распознавания речи требуется создавать языковые модели (ЯМ), позволяющие для каждого нового поступившего на вход слова определять вероятность принадлежности получившейся цепочки слов к языку. Для многих языков разработаны ЯМ, принципиально улучшающие распознавание слитной речи. Рассмотрим подробнее некоторые способы построения языковых моделей.
N-граммы
В основе N-граммных ЯМ лежит предположение о том, что вероятность появления очередного слова в предложении зависит только от предыдущих N – 1 слов. Практическое применение находят модели со значениями N от 1 до 4. Для английского языка оптимальной считается модель с N = 3 – триграммная модель. Большинство коммерческих систем распознавания слитной речи используют N-граммные модели в той или иной форме.
Основным достоинством N-граммных ЯМ является высокая скорость работы и простота расчета вероятностей (вероятность предложения вычисляется как произведение вероятностей, входящих в него N-грамм). Основной недостаток – заведомо неверное предположение о независимости вероятности слова от всей предыстории, что не позволяет моделировать глубокие языковые связи.
Кроме того, для качественного обучения N-грамм требуются огромные объёмы обучающих данных (по оценкам[Бабин 2004]требуется порядка 1 терабайта текстов для обучения биграмм) и использование специальных техник сглаживания[GibbonD., MooreR., WinskiR., 1998]. Для сокращения объема модели также используют кластеризацию словаря.
Этапы синтеза речи
Основными направлениями современных исследований в области автоматического синтеза речи являются аудиовизуальный синтез, синтез экспрессивной и эмоциональной речи, а также объединение двух подходов к синтезу речи третьего поколения: селективного синтеза и синтеза на основе скрытых Марковских моделей – так называемый гибридный синтез. Наиболее часто в гибридном синтезе от селективного синтеза берётся та часть, которая отвечает за подбор и соединение элементов конкатенации из речевой базы, поскольку соединяются элементы естественной речи–тем самым и синтезированная речь звучит более естественно. Значения физических параметров (длительности, энергии и ЧОТ звука), необходимые для оптимального селективного подбора элементов конкатенации, определяются не по созданным вручную правилам, а порождаются автоматически моделями, обученными на той же речевой базе, что позволяет быстро настроить просодическое оформление речи на нового диктора.
В настоящее время системы, основанные на так называемой технологии unit selection или, иными словами, технологии селективного синтеза речи, обеспечивают получение наиболее естественной синтезированной речи.
Алгоритм Unit selection
Селективный синтез речи является разновидностью конкатенативного синтеза, то есть при генерации речевого сигнала используются заранее полученные звукозаписи естественной речи. Вотличие от более раннихаллофонных или дифонных синтезаторов речи,порождающих итоговый речевой сигнал из отдельных и специально подготовленных звуковых единиц, выделенных из небольшого и тщательно подобранного набора озвученных слов, при селективном синтезе для каждой целевой единицы синтеза производится выбор наиболее подходящего кандидата из множества вариантов, взятых из озвученных диктором предложений естественного языка. Для этого записываются специальные речевые базы, размер которых можетдостигать нескольких десятков часов звучания[Black 2002].В процессеакустического синтеза алгоритм селекции (выбора) строит оптимальную последовательность звуковых единиц, выбранных из речевой базы, (рис. 1.9), учитывая одновременно и то, насколько кандидат подходит под описание необходимых характеристик целевого звука (стоимость замены), и то, насколько хорошо выбранные элементы будут конкатенироваться с соседними (стоимость связи). При этом с учетом указанных стоимостей из базы в качестве оптимальныхмогут быть выбраны не отдельные звук и, а их цепочки или даже целые предложения. Такой подход позволяет минимизировать необходимость модификаций речевого сигнала (или даже полностью от них отказаться), что повышает естественность синтезируемой речи.

Рисунок 1.9 - Выбор целевой звуковой последовательности при селективном синтезе речи
В то же время именно из -за тенденции к минимизации акустических модификаций одной из особенностей селективного синтеза является возможность частичного или даже полного несоответствия характеристик выбираемых единиц - кандидатов целевым характеристикам, необходимым для синтеза. Поэтому при тестировании селективного синтеза особенно важным является раздельное тестирование лингвистической обработки текста в целях его дальнейшего озвучивания и собственно акустического модуля синтеза выходного речевого сигнала.
При селективном синтезе происходит выбор групп наиболее подходящих звуковых элементов из базы синтезатора на основе значений акустических характеристик, вычисленных для каждого аллофона[Clark et al. 2007].Для того чтобы определить, насколько тот или иной элемент базы подходит для синтеза целевой звуковой единицы, вводятся понятия стоимости замены (target cost) и стоимости связи (join/concatenation cost).
Стоимость замены для элемента из базы ui по отношению к целевому элементу ti вычисляется по формуле:
 , (1.7)
, (1.7)
где:
 — расстояние между k -ыми характеристиками элементов (способ его вычисления зависит от конкретной характеристики)
— расстояние между k -ыми характеристиками элементов (способ его вычисления зависит от конкретной характеристики)
 — вес k-ой характеристики (может подбираться опытным путём или настраиваться автоматически).
— вес k-ой характеристики (может подбираться опытным путём или настраиваться автоматически).
Иными словами, стоимость замены равна взвешенной сумме различий в признаках между целевым элементом и конкретным элементом речевой базы. В качестве признаков могут выступать любые просодические и лингвистические характеристики элементов. Как правило, используется следующая информация: частота основного тона (ЧОТ), длительность, контекст, позиция элемента в слоге, слове, количество ударных слогов во фразе и др.
Выбранные из базы элементы должны не только мало отличаться от целевых, но и хорошо соединяться (конкатенироваться) друг с другом. Функция стоимости связи двух элементов в цепочке может быть определена как взвешенная сумма различий в признаках между двумя последовательно выбранными кандидатами:
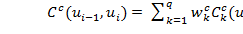 , (1.8)
, (1.8)
где:
 — расстояние между k-ми характеристиками элементов,
— расстояние между k-ми характеристиками элементов,  — вес для k-ой характеристики.
— вес для k-ой характеристики.
Общая стоимость связи для целой последовательности из n элементов равна сумме введенных выше стоимостей:
 , (1.9)
, (1.9)
Задача алгоритмаunitselection состоит в том, чтобы выбрать такоемножество элементов  , которое бы минимизировало общую стоимость полученной цепочки согласно формуле (1.9).различных селективных синтезаторах могут варьировать ся минимальные звуковые элементы базы: это могут быть аллофоны, дифоны, полуфоны, слогит. д. Также в разных селективных синтезаторах может использоваться различный набор характеристик, по которым подбираются эти элементы, способы и алгоритмы настройки весов для них[Vepa 2004; Vepa, King 2004].
, которое бы минимизировало общую стоимость полученной цепочки согласно формуле (1.9).различных селективных синтезаторах могут варьировать ся минимальные звуковые элементы базы: это могут быть аллофоны, дифоны, полуфоны, слогит. д. Также в разных селективных синтезаторах может использоваться различный набор характеристик, по которым подбираются эти элементы, способы и алгоритмы настройки весов для них[Vepa 2004; Vepa, King 2004].
На заключительном этапе синтеза происходит объединение выбранной последовательности элементов в звуковой поток, представляющий собой синтезированную речь.
Расстановка ударений
Для выбора места словесного ударения в русских словах используется словарь. Выбор места ударения для не словарных слов может осуществляться при помощи набора правил или статистических методов.
Одной из основных проблем на данном этапе является выбор места ударения омонимах, различающиеся произношением (омографах). Такие слова могут различаться местом ударения и/или наличием букв «ё»/«е», подробно проблема ё -омографов описана в статье [Лобанов 2009].
Омографы могут иметь одинаковые грамматические признаки («замОк» - «зАмок») либо различаться грамматическими характеристиками, ср.:
· Омонимичные формы внутри одной парадигмы (например, род. п. ед. ч. – им. п. мн. ч.: «облакА» – «Облака», «странЫ» – «стрАны» и т. п.).
· Омонимичные формы разных парадигм (например, существительное инфинитив: «вестИ» – «вЕсти», «пропАсть» – «прОпасть»).
· Омографы могут существенно различаться по частотности («ухА» – «Уха», сорокА – сорОка, кредИт – крЕдит, моЮ – мОю и т. п.), что важно учитывать при выборе нужного варианта.
В общем случае разрешение омонимии требует более глубокого анализа контекста. Он может производиться как на уровне индивидуальных слов (анализ слов, стоящих непосредственно рядом с текущим: «скрыто за семью замками»; поиск ключевых слов в том же предложении: «Дверь была заперта на необычный замок»), так и на уровне классов словоформ – при помощи анализа грамматического окружения и поиска согласованных слов в предложении. При этом могут использоваться грамматические правила, увеличивающие вес словоформы в зависимости от ее окружения.
Блок акустической обработки
На этом этапе выполняется выбор элементов из речевой базы синтезатора (Unit selection) и, при необходимости, модификация полученного речевого сигнала
ВЫВОД
Вопросы синтеза и распознавания речи человека компьютером становятся все более актуальными.
Проанализирован ряд наиболее доступных современных систем распознавания речи, а также их сравнительны их характеристики.
Выделены основные элементы систем распознавания и проведен анализ методов, моделей и алгоритмов, используемых в распознавании речи.
Создание модели длительности звуков речи может обеспечить повышение точности описания речевого сигнала.
Выявлена необходимость построения структур моделей, учитывающих строение звуковой волны, всех звуков русской речи для повышения эффективности распознавания реального речевого сигнала. В настоящее время используется всего одна структура моделей для всех звуков русской речи.
Рассмотрены классификационные признаки систем распознавания речи и предложена классификация, позволившая упростить выбор архитектуры разрабатываемой системы распознавания речи.
В настоящее время имеется довольно большое количество разнообразных русскоязычных селективных синтезаторов. При проведении их сравнительных оценок следует учитывать как особенности технологии селективного синтеза речи, так и общую структуру селективных синтезаторов, и качество решения задач, выполняемых на каждом этапе преобразования «Текст–Речь».
ЗАКЛЮЧЕНИЕ
По итогу проделанной научно-исследовательской работы в рамках подготовки магистров по направлению 09.04.02 - "Информационные системы и технологии" был пройден комплекс мероприятий, направленных на освоение методов, приемов и навыков выполнения исследований и анализа, развитие способностей к научному и техническому творчеству, самостоятельности и инициативы.
Были выполнены анализ, систематизация и обобщение научно-технической информации по теме исследований; теоретическое исследование в рамках поставленных задач, включая математический (имитационный) эксперимент.
Были приобретены навыки: формулирования целей и задач научного исследования; выбора и обоснования методики исследования; работы с прикладными научными пакетами и редакторскими программами, используемыми при проведении научных исследований и разработок; оформления результатов научных исследований.
ВВЕДЕНИЕ
Тематика научно-исследовательской работы определяется темой магистерской диссертации студента. Работа проводится в научно-исследовательских организациях, научно-исследовательских подразделениях производственных предприятий и фирм, специализированных лабораториях университета, на базе научно-образовательных и инновационных центров.
Научно-исследовательская работа магистрантов представляет собой комплекс мероприятий, направленных на освоение студентами в процессе обучения по учебным планам и сверх них методов, приемов и навыков выполнения исследований и анализа, развитие способностей к научному и техническому творчеству, самостоятельности и инициативы.
Научно-исследовательская работа осуществляется в соответствии с рабочим учебным планом магистерской образовательной программой направления 09.04.02 - "Информационные системы и технологии" и индивидуальным планом подготовки магистранта. Работа проходит под контролем научного руководителя магистранта и руководителя научно- исследовательского подразделения.
Цели и задачи
Цели научно-исследовательской практики
Основная цель научно-исследовательской работы – подготовить студента-магистранта к самостоятельной научно-исследовательской работе, основным результатом которой является написание и успешная защита магистерской диссертации.






