Метод SADT (Structured Analysis and Design Technique) считается классическим методом процессного подхода к управлению. Основной принцип процессного подхода заключается в структурировании деятельности организации в соответствии с ее бизнес-процессами, а не организационно-штатной структурой.
В соответствии с этим принципом бизнес-модель должна выглядеть следующим образом:
1. Верхний уровень модели должен отражать только контекст системы — взаимодействие предприятия с внешним миром.
2. На втором уровне модели должны быть отражены основные виды деятельности (тематически сгруппированные бизнес-процессы) предприятия и их взаимосвязи.
3. Дальнейшая детализация осуществляется посредством бизнес-функций — совокупностей операций, сгруппированных по определенным признакам. Бизнес-функции детализируются с помощью элементарных бизнес-операций.
4. Описание элементарной бизнес-операции осуществляется посредством задания алгоритма ее выполнения.
Метод SADT разработан Дугласом Россом (SoftTech, Inc.) в 1969 г. для моделирования искусственных систем средней сложности. Данный метод успешно использовался в военных, промышленных и коммерческих организациях США для решения широкого круга задач. В первую очередь построения модели работы целого предприятия. Метод SADT поддерживается Министерством обороны США, которое было инициатором разработки семейства стандартов IDEF (Icam DEFinition), являющегося основной частью программы ICAM (интегрированная компьютеризация производства), проводимой по инициативе ВВС США. Метод SADT реализован в одном из стандартов этого семейства — IDEF0, который был утвержден в качестве федерального стандарта США в 1993 г., его подробные спецификации можно найти на сайте http://www.idef.com. Существует также российская версия данного стандарта [Методология функционального моделирования IDEF0. Руководящий документ РД IDEF0 – 2000. – М.: Госстандарт России, 2000].
IDEF0 представляет собой совокупность правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области. Она отображает функциональную структуру объекта, т.е. производимые им действия и связи между этими действиями. Основные элементы этого метода основываются на следующих концепциях:
· Графическое представление – блочное моделирование. Диаграмма отображает функцию в виде блока, а интерфейсы и взаимодействие блоков друг с другом описывается посредством интерфейсных дуг, которые определяют когда и каким образом функции выполняются и управляются.
· Строгость и точность. Выполнение правил SADT требует достаточной строгости и точности, не накладывая в то же время чрезмерных ограничений на действия аналитика. Правила SADT включают: ограничение количества блоков на каждом уровне декомпозиции (правило 3-8 блоков — ограничение мощности краткосрочной памяти человека), связность диаграмм (номера блоков), уникальность меток и наименований (отсутствие повторяющихся имен), синтаксические правила для графики (блоков и дуг), разделение входов и управлений (правило определения роли данных).
· Отделение организации от функции, т.е. исключение влияния административной структуры организации на функциональную модель.
При создании рекомендуется:
· Размещать на каждой диаграмме от 3 до 6-7 блоков.
· Не загромождать диаграммы несущественными на данном уровне деталями.
· Выбирать ясные, отражающие суть дела имена процессов и потоков, при этом стараться не использовать аббревиатуры.
Функциональна модель IDEF0 — методология и графическая нотация, предназначенная для формализации и описания бизнес-процессов. Отличительной особенностью IDEF0 является её акцент на соподчинённость объектов. В IDEF0 рассматривается логические отношения между работами, а не их временна́я последовательность (WorkFlow).
Результатом применения метода SADT является модель, которая состоит из диаграмм, фрагментов текстов и глоссария, имеющих ссылки друг на друга.
Диаграммы — главные компоненты модели, все функции организации и интерфейсы на них представлены как функциональные блоки (Activity Boxизображается в виде прямоугольника)и интерфейсной дуги (Arrow)соответственно. По требованиям стандарта название каждого функционального блока должно быть сформулировано в глагольном наклонении (например, “производить услуги”, а не “производство услуг”).Каждый функциональный блок в рамках единой рассматриваемой системы должен иметь свой уникальный идентификационный номер.
Интерфейсные дуги часто называют потоками или стрелками. Интерфейсная дуга отображает элемент системы, который обрабатывается функциональным блоком или оказывает иное влияние на функцию. Графическим отображением интерфейсной дуги является однонаправленная стрелка. Каждая интерфейсная дуга должна иметь свое уникальное наименование. По требованию стандарта, наименование должно быть оборотом существительного. С помощью интерфейсных дуг отображают различные объекты, в той или иной степени определяющие процессы, происходящие в системе. Такими объектами могут быть элементы реального мира (детали, вагоны, сотрудники и т.д.) или потоки данных и информации (документы, данные, файлы, результаты расчётов и т.д.). В зависимости от того, к какой из сторон подходит данная интерфейсная дуга, она носит название “входящей”, “исходящей” или “управляющей”. Кроме того, “источником” (началом) и “приемником” (концом) каждой функциональной дуги могут быть только функциональные блоки, при этом “источником” может быть только выходная сторона блока, а “приемником” любая из трех оставшихся.
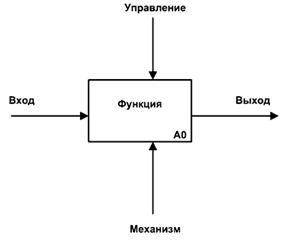
Рисунок 1. Функциональный блок и интерфейсные дуги
Сторона блока, к которой подсоединена дуга, определяет тип интерфейса:
· управляющая информация (алгоритм функционирования, ГОСТы, методические указания, инструкции, нормативы, критерии оценки, накладываемые ограничения и т.д.) входит в блок сверху;
· входная информация (параметры функции, данные вводимые пользователем, документы, файлы, рабочие материалы, результаты прошлых операций и др. информация, обработкой которой будет заниматься блок) показана с левой стороны блока;
· результаты (выход, тоже разного рода данные) показаны с правой стороны;
· механизм работы (человек, автоматизированная система, ЭВМ, инструментальные среды, прочие исполнители и другие технические средства), который осуществляет операцию, представляется дугой, входящей в блок снизу (Рис. 1).
Соотношение сторон не стандартизируется, главное сама форма блока в виде прямоугольника и чтобы стрелки подходили к нужной стороне блока.
Блоки да диаграмме обычно размещаются по ступенчатой схеме в соответствии с последовательностью их работы или доминированием, которое понимается как влияние, оказываемое одним блоком на другие. Но этот принцип не означает, что на схеме обязательно будет главный блок, который запускает технологическую цепочку и затем на базе его выходных данных будут работать остальные.
Можно выделить 6 типов влияния блоков друг на друга:
а) передача обработанных данных дальше – выход блока подаётся на вход блока с меньшим доминированием, т.е. следующий.
б) управление – выход блока используется как управляющий элемент для блока с меньшим доминированием.
в) обратная связь по входу – выход блока подаётся на вход блока с большим доминированием (предыдущего)
г) обратная связь по управлению – выход блока используется как управляющая информация для блока с большим доминированием.
д) выбор исполнителя – выход блока используется как механизм для другого блока, например, если блок определяет, кто из исполнителей будет работать в связанном с ним блоке (когда в системе есть несколько пользователей – админ, юзер и др.).
е) независимость – блоки не имеют связей напрямую, в работе пользователь может выбрать одну из предлагаемых функций независимо от другой.

Рисунок – Типы влияния блоков
Дуги могут разветвляться и соединяться вместе различными способами. Разветвление означает, что часть или вся информация может использоваться в каждом ответвлении дуги. Дуга всегда помечается до ветвления, чтобы идентифицировать передаваемый набор данных. Если ветвь дуги после ветвления не помечена, то она содержит весь набор данных. На каждой ветке допустимо производить уточнение, что именно она содержит.

Рисунок – Пример обозначения дуг при ветвлении
Одной из наиболее важных особенностей метода SADT является постепенное введение все больших уровней детализации: диаграммы каждого следующего уровня уточняют структуру родительского блока.
Построение модели начинают с единственного блока, для которого определяют исходные данные, результаты, управление и механизм. Диаграмма, содержащая этот единственный блок, называется контекстной диаграммой системы. Затем этот единственный блок постепенно детализируется методом пошаговой детализации. Во всех случаях каждая подфункция (диаграмма) может использовать или производить только те элементы данных, которые использованы или производятся родительской функцией, причём никакие элементы не могут быть опущены, т.е., как уже отмечалось, родительский блок и его интерфейсы обеспечивают контекст. К нему нельзя ничего добавить, и из него не может быть ничего удалено на уровень ниже. Это условие определяет непротиворечивость построенной модели. Поэтому если нужно что-то добавить или удалить из предка сделайте это сначала в родителе.
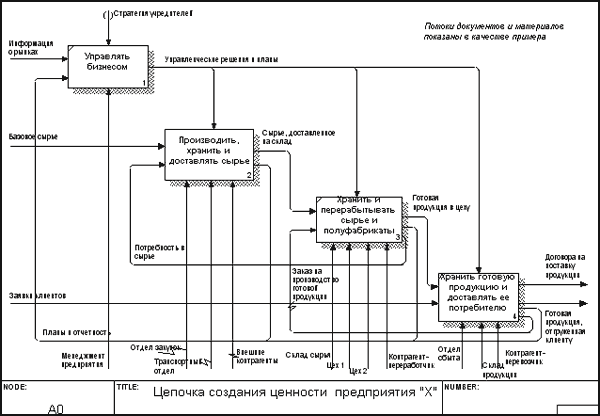
На Рис. 2, где приведены три диаграммы и их взаимосвязи, показана структура SADT-модели. Каждый компонент модели может быть декомпозирован на другую диаграмму. Каждая диаграмма иллюстрирует «внутреннее строение» блока на родительской диаграмме, т.е. диаграмме на уровень выше.

Рисунок 2. Структура SADT-модели. Декомпозиция диаграмм
Данная декомпозиция выявляет полный набор подфункций, каждая из которых показана как блок. Каждая из этих подфункций может быть декомпозирована подобным образом в целях большей детализации и так далее.На каждом шаге декомпозиции диаграмма предыдущего уровня называется родительской для более детальной диаграммы.Общее число уровней в модели (включая контекстный) не должно превышать 5-6. Практика показывает, что этого вполне достаточно для построения полной функциональной модели современного предприятия любой отрасли.
Пример декомпозиции блока нулевого уровня:
При построении иерархии диаграмм используются следующие стратегии декомпозиции:
• Функциональная декомпозиция — декомпозиция в соответствии с функциями, которые выполняют люди или организация.
• Декомпозиция в соответствии с известными стабильными подсистемами — приводит к созданию набора моделей, по одной модели на каждую подсистему или важный компонент.
• Декомпозиция по физическому процессу — выделение функциональных стадий, этапов завершения или шагов выполнения. Эта стратегия рекомендуется только если целью модели является описание физического процесса как такового или только в крайнем случае, когда неясно, как действовать.
Для лучшего ориентирования по диаграммам используется иерархическая нумерация блоков, начинающаяся с латинской буквы А с последующей цифрой. Первый уровень – А0, второй А1, А2, А3 и т.д., третий – А11, А12, А23 и т.д., где первая цифра номер родительского блока, а последняя номер конкретного субблока.
Если диаграммы получаются запутанными из-за большого количества текста, то можно вводить условные обозначения и соответственно словарь, где определяют структуры и элементы данных. Символ обозначает тип связи: I-входная, C – управлявшая, M-механизм, R-результат. Число – номер связи по соответствующей стороне родительского блока, считая сверху вниз и слева направо.
Детализацию завершают после получения функций, назначение которых хорошо понятно как заказчику, так и разработчику. Эти функции описывают, используя естественный язык или псевдокоды. Вместо этого можно построить схему алгоритма функционирования блока.
Таким образом,в результате получают спецификацию, которая состоит из иерархии функциональных диаграмм, спецификаций функций нижнего уровня и словаря, имеющих ссылки друг на друга.
Рассмотрим ещё один пример диаграммы 1го уровня для приложения, строящего таблицы/графики функций одной переменной. Для неё определён следующий словарь данных:
I1 – функция;
I2 – отрезок;
I3 – шаг;
C1 – вид график/таблица;
R1 – график функции на отрезке;
R2 – таблица значений функции на отрезке.

Основные преимущества SADT заключаются в следующем:
· полнота описания бизнес-процесса;
· комплексность декомпозиции;
· возможность агрегирования и детализации потоков данных;
· наличие жестких требований, обеспечивающих получение стандарта;
· простота документирования процессов;
· соответствие подхода к описанию процессов стандарту ISO 9000:2000.
В то же время метод SADT обладает рядом недостатков:
· сложность восприятия (большое количество дуг на диаграммах);
· не однозначность нумерации блоков, например А11, может восприниматься как 11й блок на 1м уровне детализации или это блок 1 на 2м уровне детализации для блока 1 из 1го уровня.
· большое количество уровней декомпозиции;
· трудность увязки нескольких процессов, представленных в различных моделях одной и той же организации;
· нельзя отразить структуру передаваемых данных;
· не отражаются явно последовательность действий и время.
Диаграммы структур данных
Структурой данных называют совокупность правил и ограничений, которые отражают связи, существующие между отдельными частями (элементами) данных.
Различают абстрактные структуры данных, используемые для уточнения связей между элементами, и конкретные структуры, используемые для представления данных в программах.
Все абстрактные структуры данных можно разделить на три группы: структуры, элементы которых не связаны между собой, структуры с неявными связями элементов - таблицы и структуры, связь элементов которых указывается явно - графы (рис. 4.18).
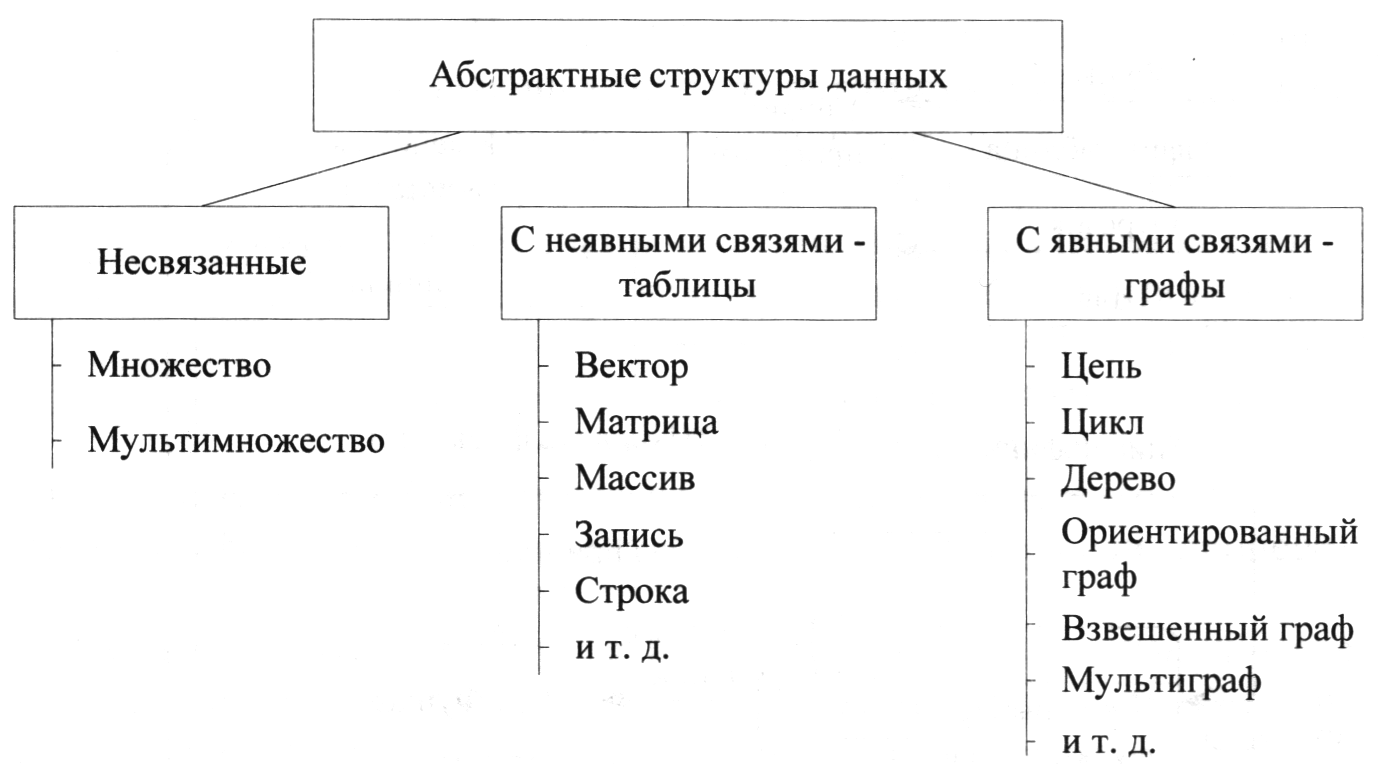
Рис. 4.18.Классификация абстрактных структур данных
В первую группу входят множества (рис. 4.19, а) и мультимножества (множества, допускающее включение одного и того же элемента по нескольку раз) (рис. 4.19, б). Наиболее существенная характеристика элемента данных в этих структурах - его принадлежность некоторому набору, т. е. отношение вхождения. Данные абстрактные структуры используют, если никакие другие отношения элементов не являются существенными для описываемых объектов.

Рис. 4.19. Множество (а) и мультимножество (б)
Ко второй группе относят векторы, матрицы, массивы (многомерные), записи, строки, а также таблицы, включающие перечисленные структуры в качестве частей. Использование этих абстрактных типов может означать, что существенным является не только вхождение элемента данных в некоторую структуру, но и их порядок, а также отношения иерархии структур, т. е. вхождение структуры в структуру более высокой степени общности (рис. 4.20).
В тех случаях, когда существенны связи элементов данных между собой, в качестве модели структур данных используют графы. На рис. 4.21 показаны различные варианты графовых моделей.
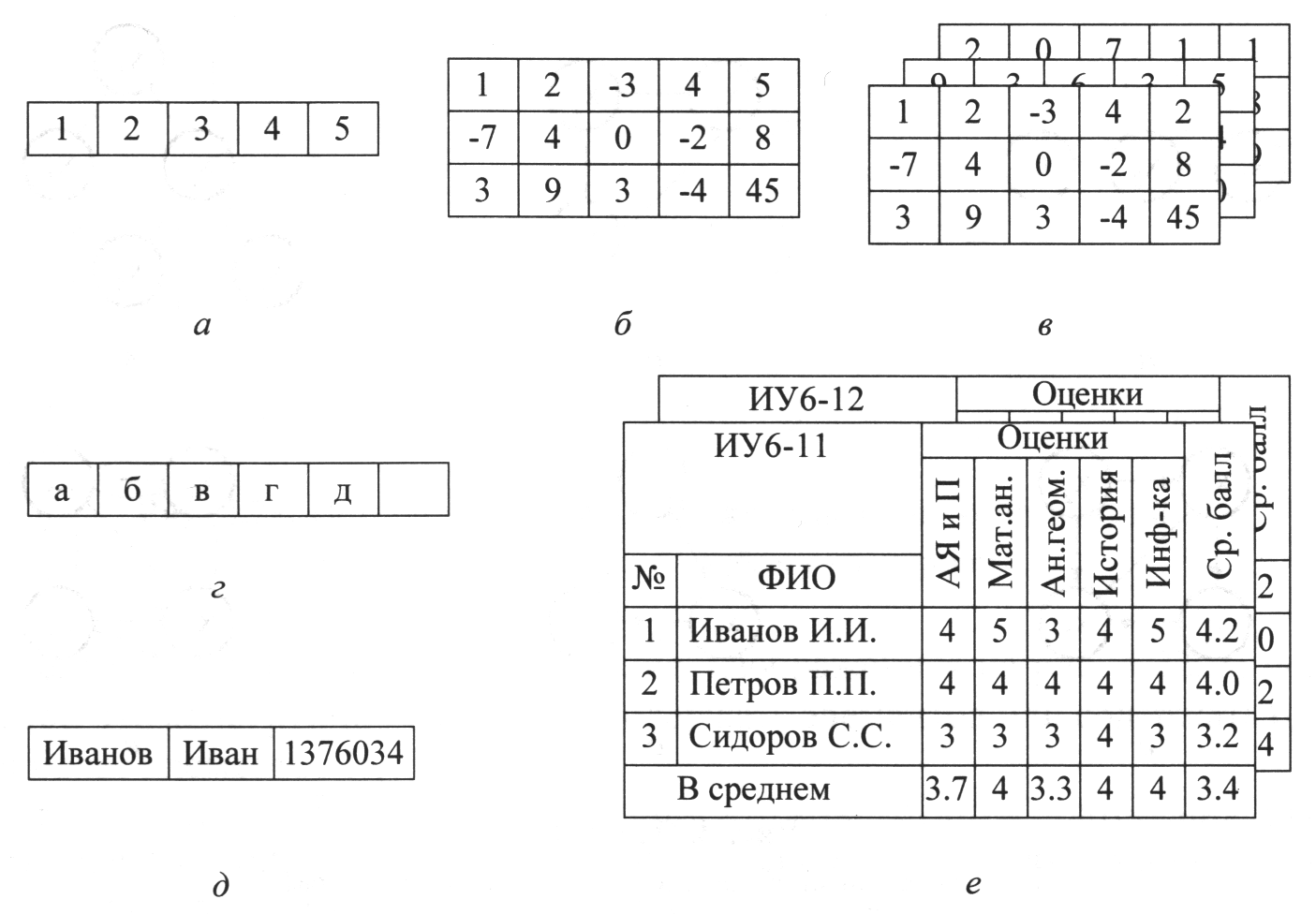
Рис. 4.20. Таблицы:
а - числовой вектор; 6 - матрица; в - трехмерный массив; г - строка; д - запись; е - массив однотипных таблиц с вложенными структурами

Рис. 4.21. Графы:
а - цепь; б - цикл; в - дерево; г - ориентированный граф; д - взвешенный смешанный граф; е - мультиграф
Очень существенно, что в реальности возможно вложение структур данных, в том числе и разных типов, а потому для их описания могут потребоваться специальные модели. В зависимости от описываемых типов отношений модели структур данных принято делить на иерархические и сетевые.
Иерархические модели позволяют описывать упорядоченные или неупорядоченные отношения вхождения элементов данных в компонент более высокого уровня, т. е. множества, таблицы и их комбинации. К иерархическим моделям относят модель Джексона-Орра, для графического представления которой можно использовать:
• диаграммы Джексона, предложенные в составе методики проектирования программного обеспечения того же автора в 1975 г.;
• скобочные диаграммы Орра, предложенные в составе методики проектирования программного обеспечения Варнье-Орра (1974).
Сетевые модели основаны на графах, а потому позволяют описывать связность элементов данных независимо от вида отношения, в том числе комбинации множеств, таблиц и графов. К сетевым моделям, например, относят модель «сущность-связь» (ER - Entity-Relationship), обычно используемую при разработке баз данных.
Диаграммы Джексона. В основе диаграмм Джексона лежит предположение о том, что структуры данных так же, как и программ, можно строить из элементов с использованием всего трех основных конструкций: последовательности, выбора и повторения.
Каждая конструкция представляется в виде двухуровневой иерархии, на верхнем уровне которой расположен блок конструкции, а на нижнем - блоки элементов. Нотации конструкций различаются специальными символами в правом верхнем углу блоков элементов. В изображении последовательности дополнительный символ отсутствует. В изображении выбора ставится символ «о» (латинское) - сокращение английского «или» (or). Конструкции последовательности и выбора должны содержать по два или более элементов второго уровня. В изображении повторения в блоке единственного (повторяющегося) элемента ставится символ «*».
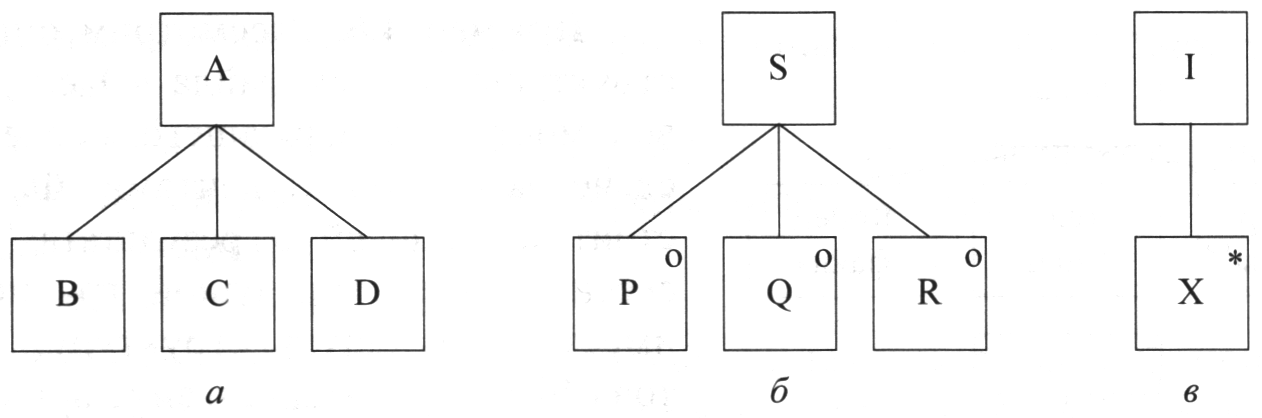
Рис. 4.22. Нотация Джексона для представления конструкций:
а - последовательность; 6 - выбор; в - повторение
Так схема, показанная на рис. 4.22, а, означает, что конструкция А состоит из элементов В, С и D, следующих в указанном порядке. Схема на рис. 4.22, б означает, что конструкция S состоит либо из элемента Р, либо из элемента Q, либо из элемента R. Схема, изображенная на рис. 4.22, в, показывает, что конструкция I может не содержать элементов или содержать один или более элементов X. В случае, если необходимо показать, что конструкция повторения должна включать один или более элементов, используют комбинацию из двух структур последовательности и повторения (рис. 4.23).

Рис. 4.23. Пример описания конструкции, в которой повторение встречается один или более раз
Скобочные диаграммы Орра. Диаграмма Орра базируется на том же предположении о сходстве структур программ и данных, что и диаграмма Джексона. Отличие состоит лишь в нотации. Автор предлагает для представления конструкций данных использовать фигурные скобки (рис. 4.24).
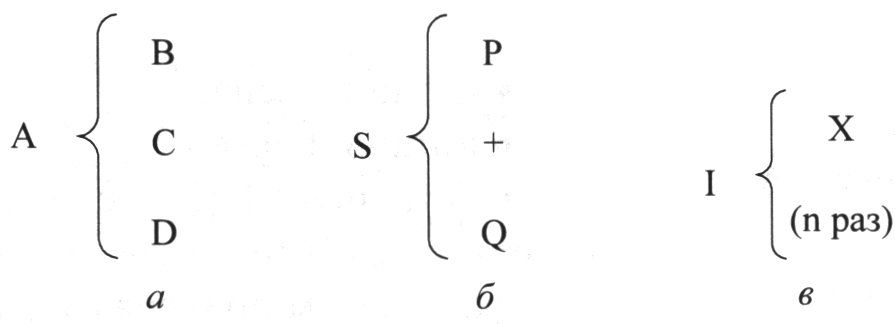
Рис. 4.24. Скобочная нотация для представления структур данных Орра:
а - последовательность; б - выбор; в - повторение
Пример 4.6. Рассмотрим описание структуры данных файла «Электронная ведомость», содержащего сведения о сдаче экзаменов студентами. Файл состоит из записей о результатах сдачи сессии студентами одной группы. Он имеет следующую структуру: номер группы, записи об успеваемости студентов (ФИО студента, название предмета и оценка, полученная студентом, в завершении записи специальный символ «конец записи») и специальный символ «конец файла». На рис. 4.25 показано, как выглядит описание данной структуры с использованием диаграммы Джексона, а на рис. 4.26 - с использованием скобок Орра.

Рис. 4.25. Описание структуры файла «Электронная ведомость» в виде диаграммы Джексона

Рис. 4.26. Описание структуры файла «Электронная ведомость» в виде диаграммы Орра
Сетевая модель данных. Сетевые модели данных используют в тех случаях, если отношение между компонентами данных не исчерпываются включением. Для графического представления разновидностей этой модели используют несколько нотаций. Наиболее известны из них следующие:
• нотация П. Чена;
• нотация Р. Баркера;
• нотация IDEF1 (более современный вариант этой нотации - IDEF1X используется в CASE-системах, например, в системе ERWin).
Диаграмма потоков данных (DFD)
Диаграммы потоков данных(Data Flow Diagrams — DFD) представляют собой иерархию функциональных компонентов (процессов), связанных потоками данных. Цель такого представления — продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Первая диаграмма, отражающая обмен данными датируется 20ми годами прошлого века. Для построения DFD в современном представлении используются две различные нотации, соответствующие методам,предложенным независимо Йордоном-ДеМарко (предложена в 1975г) и Гейном-Сэрсоном (1979). Эти нотации незначительно отличаются друг от друга графическим изображением символов (далее в примерах используется нотация Гейна-Сэрсона). Та же модель используется в методологии структурного анализа и проектирования SSADM, принятой в Великобритании в качестве национального стандарта разработки информационных систем.
В соответствии с данным методом модель системы определяется как иерархия диаграмм потоков данных, описывающих асинхронный процесс преобразования информации от ее ввода в систему до выдачи потребителю. Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Они в свою очередь, преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям — потребителям информации.
Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока не будет достигнут уровень декомпозиции, на котором детализировать процессы далее не имеет смысла, т.е. смысл такой же, как и в IDEF0. Дополнительно появляются внешние сущности по отношению к рассматриваемой системе, которые являются источниками или потребителями информации, а также накопители информации.
Соотношение сторон не стандартизируется, главное сама форма блоков.
Основными компонентами диаграмм потоков данных являются:
• внешние сущности;
• системы и подсистемы;
• процессы;
• накопители данных;
• потоки данных.
Внешняя сущность представляет собой материальный объект или физическое лицо, являющиеся источником или приемником информации, например, заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что она находится за пределами границ анализируемой системы (не входит внутрь программы). В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой системы, если это необходимо, или, наоборот, часть процессов может быть вынесена за пределы диаграммы и представлена как внешняя сущность.
Внешняя сущность обозначается квадратом (Рис. 1), расположенным над диаграммой и бросающим на нее тень для того, чтобы можно было выделить этот символ среди других обозначений.

Рисунок 1. Графическое изображение внешней сущности
Накопитель данных — это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми.
Накопитель данных может быть реализован физически в виде ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т.д. Накопитель данных на диаграмме потоков данных изображается, как показано на рис. 2.
Накопитель данных идентифицируется буквой «D» и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика.Накопитель данных в общем случае является прообразом будущей базы данных, и описание хранящихся в нем данных должно соответствовать модели данных.

Рисунок 2. Графическое изображение накопителя данных
Процесс представляет собой преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Физически процесс может быть реализован различными способами: это может быть подразделение организации (отдел), выполняющее обработку входных документов и выпуск отчетов, программа, аппаратно реализованное логическое устройство и т.д.
Процесс на диаграмме потоков данных изображается, как показано на Рис. 3.
Номер процесса служит для его идентификации. В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, например: «Ввести сведения о налогоплательщиках», «Выдать информацию о текущих расходах», «Проверить поступление денег». Дополнительно может присутствовать поле физической реализации, где указывается подразделение организации, программа, программный модуль, аппаратное устройство и т.д. Два основных отличия от IDEF0: стороны прямоугольника не имеют ярко выраженных функций (направление передачи информации в блок ли из него определяется направлением стрелки отношения), механизм работы записывается в соответствующем разделе (если такое предусмотрено в CASE-средстве, например в BPWinтакого нет), а не заходит стрелкой снизу блока.

Рисунок 3. Графическое изображение процесса в BPwin

Рисунок 4. Графическое изображение процесса в OpenModelSphere
Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой и т.д.
Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (рис. 4). Каждый поток данных имеет имя, отражающее его содержание.
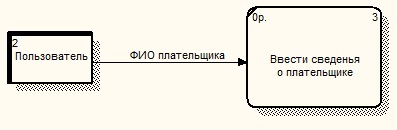
Рисунок 4. Поток данных








