Полное построение алгоритма
Algorithm - однозначно трактуемая процедура решения задач.
Процедура - конечная последовательность точно определенных шагов или операций, для выполнения каждой из которых требуется конечный объем ОП и времени, кроме того, алгоритм должен работать конечн. время при любых входных данных.
Алгоритм – процедура, которая может быть реализована на данном ПК при помощи данного языка.
Алгоритм имеется только тогда, когда можно написать программу для ЭВМ.
Уровень:

Шаг используется для определения функции

1. Допущения
N (городов)- 20 городов
Вояжер должен проехать по оптимальному пути

2. Построение модели
При разработки модели возникает два вопроса:
1) какие математические структуры больше всего подходят для задачи
2) существуют ли решенные аналогичные задачи

3. Разработка алгоритма
Algorithm EIS

4. Проверка правильности алгоритма
Правильно не значит эффективно. Алгоритмы редко хороши во всех отношениях.
5. Реализация алгоритма (программа)
При реализации алгоритма задаются следующие вопросы: какие структуры данных, каких они типов, сколько массивов, их размерность, какой язык.
6. Анализ алгоритма и его сложности
Существует количественный критерий.
Если А-алгоритм, n- размерность, 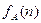 - рабочая функция, дающая верхнюю границу для максимального числа основных операций, которые выполняет алгоритм А для решения задач в размерности n.
- рабочая функция, дающая верхнюю границу для максимального числа основных операций, которые выполняет алгоритм А для решения задач в размерности n.
А- полиноминален, если рабочая функция растет не быстрее, чем полином от n, в противном случае А- экспоненциален.
7. Проверка программы (аналитически и экспериментально)
8. Документация
Некоторые основные приемы алгоритмизации
Некоторые структуры данных
В гл.1 мы высказали утверждение о том, что выбор структур данных может существенно
Повлиять на скорость и эффективность реализованного алгоритма. В этом разделе мы введём несколько структур данных (связанные списки, стеки и очереди) и процедуры для работы с ними, которые часто оказываются полезными.
Рассмотрим преимущества и недостатки использования массивов.
Среди преимуществ отметим следующие:
Массивы помогают объединять множества данных в осмысленные группы.
Имена массивов с индексами минимизируют потребность в слежении за многими элементами
Данных с различными именами.
Использование индексов обеспечивает непосредственный и автоматический доступ к любому
элементу в массиве
Связанные списки
На рис. 2,а массив CS100 преобразован из одномерного в двумерный мссив CS100L. В столбце 1 массива CS100L по – прежнему содержатся фамилии студентов, зачисленных на курс CS100,хотя, как явствует из рис. 2,б, теперь уже не требуется, чтобы эти фамилии были упорядочены по алфавиту. В столбце 2 массива CS100L содержатся неотрицательные целые числа, называемые связями или указателями, значениями которых являются номера строк массива, содержащих фамилию следующего студента (в алфавитном порядке) в текущем

списке. Звездочкой (*) мы отметили те указатели, значения которых изменились в связи с удалением фамилий ГРИДИН и СИДОРОВ и добавлением ДРОЗДОВ. Заметим, что на рис. 2,б
АДАМОВ указывает на БЕЛЯЕВ {CS100L (1, 2)=2 и CS100L(2,1)= БЕЛЯЕВ}.
БЕЛЯЕВ указывает на ЖАРИКОВ {CS100L(2, 2) =4 и CS100L (4, 1)= ЖАРИКОВ}
КУЗНЕЦОВ указывает на ДРОЗДОВ.
ДРОЗДОВ указывает на ЛИПАТОВ и т.д.
Массив CS100L(I,J) размера N×2 работает как линейный связанный список. Линейный связанный список – это конечный набор пар, каждая из которых состоит из информационной части INFO (ИНФО) и указующей части LINK (СВЯЗЬ). Каждая пара называется ячейкой. Если мы хотим расположить ячейки в порядке Ci1, Ci2,... , Cin,то СВЯЗЬ (ij)=ij+1 для j=1,...,n-1,а СВЯЗЬ (in)=0 и указывает на конец списка.
На рис. 3,а, приведена стандартная диаграмма линейного связанного списка;на рис 3,б,приведена диаграмма связанного списка с рис.2,б.Заметим, что ГРИДИН и СИДОРОВ отсутствуют в списке на рис 3,б., хотя они присутствуют на рис 2,б., как затемненные элементы. При реализации связанных списков участвует переменная FIRST(ПЕРВЫЙ) или HEAD (ГОЛОВА), значение которой есть адрес первой ячейки списка (рис 3,а.).
Как было указано выше, одно из главных преимуществ связанных списков заключается в том, что можно легко удалять и добавлять элементы списка. Далее мы пиводим два алгоритма, которые можно использовать при выполнении модификаций, требуемых для преобразования рис. 2,а, а в 2,б.

Первый алгоритм будет удалять заданный элемент из связанного списка. Этот процесс иллюстрируется на рис. 4,где мы ищем ячейку С i, у которой ИНФО (i)=ТРИ, передвигая указатели PREV и PTR до тех пор, пока такая ячейка не найдена. Затем мы заменяем значение СВЯЗЬ в ячейке, на которую указывает PREV, на значение СВЯЗЬ в ячейке, на которую указывает PTR. Далее следуют блок-схема (рис. 5), формальное описание и реализация этого алгоритма.
Algorithm DELETE (УДАЛЕНИЕ). Удаляется ячейка Сi, у которой INFO(i)=VALUE из связанного списка, первая ячейка которого задается переменной FIRST.
Шаг 1. [Выбор первой ячейки] Set PTR ←FIRST; PREV← 0/
Шаг 2. [Ячейка пуста?] While PTR ≠0 do шаг 3 od.
Шаг 3. [Это она?] If INFO (PTR)=VALUE
then [Это первая ячейка?]
if PREV=0 then [удалить спереди]
set FIRST←LINK (PRT); and STOP
else [удалить изнутри]
set LINK (PREV)←LINK(PTR);
and STOP fi
else [Выбор следующей ячейки]
set PREV←PTR; PTR←LINK(PTR) fi.
Шаг 4. [Не в списке ] НАПЕЧАТАТЬ «ЗНАЧЕНИЕ НЕ В СПИСКЕ»;
and STOP.
Следующий алгоритм будет вносить в связанный список новую ячейку. Предположим, что в списке ячейки упорядочены в порядке возрастания содержимого поля ИНФО(INFO).Этот алгоритм аналогичен алгоритму DELETE(УДАЛЕНИЕ) в том отношении, что при выполнении операции внесения используются указатели PREV и PTR.
На рис.6 Проиллюстрирован процесс внесения, причем мы предполагаем, что
ОДИН<ДВА<ТРИ<ЧЕТЫРЕ
На рис 7. и 8. приведены блок-схема и реализация следующего алгоритма:
Algorithm INSERT (ВНЕСЕНИЕ). Внести новую ячейку ROW(РЯД), где INFO(ROW)=VALUE,в упорядоченной связанный список, первая ячейка которого задаётся в FIRST(ПЕРВЫЙ).
Шаг 1. [Выбор первой ячейки] Set PTR ← FIRST; PREV ←0
Шаг 2 [Ячейка пуста?] While PTR ≠ do шаг 3 od.

Шаг 3. [Предшествует ли новая ячейка выбранной?] If VALUE≤ INFO (PTR)
then [вносится спереди?]
if PREV=0 then [внести новую ячейку спереди]
set FIRST←ROW;
LINK (ROW)←PTR;
and STOP
else [внести новую ячейку внутрь]
set LINK(PREV)←ROW;LINK (ROW)←PTR; and STOP fi
else [Выбрать очередную ячейку]
set PREV← PTR;PTR←LINK(PTR) fi.
Шаг 4. [Список пуст?] If PREV=0
then [внести новую ячейку как единственную ячейку в списке ]
set FIRST← ROW;LINK (ROW)←0; and STOP
else [внести новую ячейку в конец списка]
set LINK(PREV)←ROW; LINK (ROW)←0; and STOP fi.


Стековые списки и стеки
Мы увидели, что (линейные) связанные списки – это эффективная структура данных для моделирования ситуаций, в которых подвергаются изменениям упорядоченные массивы элементов данных. В частности. это справедливо для случая, когда модификациями являются главным образом внесение элементов в середину массивов или удаление элементов из середины массива. Когда модификации касаются лишь начала и конца, необходимость в связанных списках исчезает, и стонавятся достаточными простые линейные (одномерные) массивы.
В качестве примера рассмртрим следующую задачу. Во всех компиляторах с языков программирования требуется узнавать, является ли произвольное выражение правильно построенным. в частности, нужно определять, правильно ли расставлены в выражении скобки. Например, последовательность
() (() ())
представляет правильную последовательность скобок, а
() ((() ())
неправильную (есть лишние левые скобки).В более широком математическом контексте в арифметическом выражении обычно встречаются также квадратные скобки [ ] и фигурные скобки { }.
Предположим, что вас попросили разработать алгоритм определения того, что произвольная последовательность круглых, квадратных и фигурных скобок является правильно построенной.Что мы понимаем под правильно построенной последовательностью? Обычное определение состоит в следующем:
1. Последовательности (), [ ] и { } являются правильно построенными.
2. Если последовательность х правильно построенная,то правильно построены и последовательности (х),[ x ] и{ x }.
3. если последовательности x и y правильно построенные, то такова же и последовательность xy.
4. Правильно построенными являются лишь те последовательности, правильность которых следует из конечной последовательности применений правил 1,2 и,3.
Это определение определяет правильно построенные последовательности конструктивно. Например, следующие последовательности являются правильно построенными:
| | | | | | |
| | | | Образована с помощью
правил
| |
| | | | |
| |
_____________________________________________________________________________________

Обычно,чтобы установить, являются ли выражения такого типа правильно построенными, используют стековую память (или просто стек), которая представляет собой бесконечную в одну сторону последовательность слов памяти, как изображено на рис. 8
 Для запоминания элементов данных в стеке элемент заносят в верхнее слово ТОР (ВЕРШИНА), сдвигая тем самым вниз (по одному слову) все другие слова, хранящиеся в стеке (совершенно аналогично тому,как в столовой складывают подносы в стопку). Выбор элементов данных из стека возможен лишь считыванием по одному за раз из слова ТОР, причем все остальные элементы данных сдвигаются вверх.
Для запоминания элементов данных в стеке элемент заносят в верхнее слово ТОР (ВЕРШИНА), сдвигая тем самым вниз (по одному слову) все другие слова, хранящиеся в стеке (совершенно аналогично тому,как в столовой складывают подносы в стопку). Выбор элементов данных из стека возможен лишь считыванием по одному за раз из слова ТОР, причем все остальные элементы данных сдвигаются вверх.
Мы не имеем права выбирать элементы данных внутри стека. (В столовой мы обычно не выбираем двадцатый поднос из стопки подносов.) Иногда термин «стек» обозначает стековую память, когда нам разрешено считывать элементы, находящиеся ниже слова ТОР, но не разрешается изменять их значения или добавлять новые элементы ниже слова ТОР.
| |
| | | . Диаграмма стековой памяти
| |
Покажем на примере,как стековая память помогает нам легко определить, является ли такая последовательность, как g={[ ]({[()]}{ })}, правильно построенной. Элементы g будем обозначать х1,х 2,…, х n, где x i есть одна из скобок {, }, (,), [ или ]. Элементы {, (и [ назовем ЛЕВЫМИ символами; скажем, что xi—левый партнер хj, если xi= [ и хj =], или xi =(и xj =), или x i ={ и xj =}/
Algorithm WELLFORMED (ПРАВИЛЬНО ПОСТРОЕННАЯ). Определяет, является ли произвольная последовательность символов xix2...xn, где каждый xi —одна из скобок {, }, (,), [, или ],авильно построенной.
Шаг 0. [Инициализация ] Set TOP ←0; I←1.
Шаг 1. [ Читается последовательность слева направо]
While I≤ N do through шаг 3 od/
Шаг 2. [Записывается в стек ЛЕВЫЙ символ]
If х i ЛЕВЫЙ символ then [ записывается xi ]
else [выбирается символ из стека ]
if TOP левый партнер хi
then выбирать элемент ТОР из памяти
else НАПЕЧАТАТЬ «НЕПРАВИЛЬНО ПОСТРОЕННАЯ»; and STOP fi fi
Шаг 3. [Прочесть следующий символ ] Set I ←I +1.
Шаг 4. [Память пуста?] If TOP=0 then PRINT «ПРАВИЛЬНО ПОСТРОЕННАЯ»;
else PRINT «НЕПРАВИЛЬНО ПОСТРОЕННАЯ» FI; and STOP.
Применим теперь алгоритм ПРАВИЛЬНО ПОСТРОЕННАЯ к последовательности
g={ [ ] ({ [ () ] } { }) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14
На рис. 9. Приведено содержимое стека, соответствующее операциям 0чтения элементов из g слева направо. Целое значение над I- й конфигурацией стека указывает на то, что в данный момент читается xi- й символ.
Для реализации стека на Фортране мы возьмем одномерный массив STORE[ описанный как STORE (M)] и целую переменную с именем ТОР. Всегда, когда нам нужно поместить на вершину стека элемент Х(I), мы выполняем следующие простые команды:
TOP = TOP +1
IF (TOP. GT.M) GO TO 100
STORE (TOP)=X(I)
GO TO 200
100 PRINT «ПЕРЕПОЛНЕНИЕ СТЕКА»
200 CONTINUE
Далее для выбора элемента выполняются следующие команды:
IF (TOP. EQ.0) GO TO 300
X (I) =STORE (TOP)
TOP=TOP-1
GO TO 400
300 PRINT «СТЕК ПУСТ»
400 CONTINUE

Очереди
В стековой памяти для внесения и удаления элементов можно пользоваться только словом ТОР.В очереди элементы добавляются с одного конца, а выбираются с другого. Эти элементы обычно называются началом (FRONT) и концом (REAR) очереди. Термин «очередь» выбран потому,что эти структуры данных часто используются для моделирования обслуживающих линий, например люди в очереди к парикмахеру, автомобили у светофора, очередь заданий операционной системы.
Для моделирования очереди,как правило, используют линейный массив [например, QUEUE(500)] и две целые переменные FRONT и REAR, которые указывают на первые и последние элементы очереди соответственно. Вначале REAR≥FRONTреди добавится свыше 500 элементов, то, по-видимому,некоторые записи будут удалены из начала очереди. Если это так, то, чтобы не допустить переполнения массива, мы присваиваем REAR=1 и продолжаем заполнять очередь с начала массива. Впрочем,REAR никогда не должен перегонять FRONT.
На рис.10. показано то, что называется ситуацией одна очередь-одно обслуживание. В этом примере емкость очереди 5, конкретные клиенты помечены метками от А до Н, первый ожидающий в очереди клиент обслуживается за три единицы времени, после чего он покидает очередь. В момент Т=0 очередь пуста, и значения FRONT (F) и REAR(F) равны нулю. В момент Т=1 прибывает А,ждет 3 единицы времени и покидает очередь в момент Т=4. Клиенты B,C,D,E,G и H прибывают в моменты времени 2,3,4,7,8 и 9 соответственно.С ждет 4 единицы, прежде чем продвинуться в начало очереди, и покидает ее в момент Т=10. Когда прибывает G,в момент Т-8, конец очереди находится в массиве в положении 5.Здесь мы помещаем G в положение 1 очереди и присваиваем R=1. Когда в момент Т=9 прибываем Н, в Rзасылается 2, в этот момент очередь полностью заполнена. Теперь конец очереди сравнялся с ее началом, и, пока С не покинет очередь, в нее становится нельзя.
ПодпрограммаQADD(рис. 11) добавляет элемент VALUE к очереди. Предполагается, что, когда очередь пуста, FRONT=REAR=0.Процесс удаления элемента из очереди аналогичен. Подпрограмма QDELET(рис.12) выполняет эту работу; при удалении из очереди последнего элемента программа присваивает величинам FRONT и REAR значения, равные 0.

Деревья
Линейные массивы можно также использовать для компактного представления деревьев определенного вида.Пусть Т-дерево с М вершинами, в котором вершины помечены целыми числами 1,2,..., М. Говорят,что дерево Т рекурсивно помечено( или рекурсивное), если каждая вершина с меткой больше 1 смежа ровно с одной вершиной, у которого метка имеет меньшее зна чение. На рис. 13. Приведены примеры рекурсивного дерева Т1 и нерекурсивного дерева Т2

На примере линейного массива ДЕРЕВО показано,как комактно можно представить рекурсивное дерево Т1; ДЕРЕВО (I)=J обозначает, что вершина I смежна вершине J.
Метод частных целей
Метод частных целей основан на сведении трудной задачи к последовательности простых задач. Но и как большинство других методов его не всегда легко перенести на конкретную задачу.
Осмысленный выбор более простых задач: дело искусства, а не интуиции.
Более того, не существует общего набора правил для определения класса задач, которые можно решить с помощью такого подхода.
Метод подъема
Алгоритм начинается с принятия начального предположения или вычисления начального значения задачи. Затем переходим от начального значения к лучшему. Когда алгоритм достигает точки из которой нельзя перейти, он останавливается.
Метод отработки назад
Метод обработки назад начинается с цели (решения) и движемся обратно к начальной постановки задачи. Затем, если действия обратимы, движемся обратно от постановки к решению.
Пример:

Подойдем к задаче с помощью метода отрабатывания назад. На основании этого метода мы задаемся целью (вопросом): с какого расстояния мы можем пересечь пустыню имея запас горючего точно для k баков.
k=1,2,3…n пока не найдем такое целое n, что позволяет пройти весь путь 1000км.
Мы поставим частную цель, так как не смогли сразу решить исходную задачу. Мы не задаем вопрос: сколько топлива на всю дистанцию? Вместо этого, мы задаемся вопросом: какое расстояние можно проехать на заданном топливе.
На первый вопрос ответить можно лишь тогда, когда ответ на второй вопрос будет не меньше 1000л.

Эвристики (гипотезы)
Эврист алгоритм определяющийся, как алгоритм со следующими свойствами:
1) обычно находит хорошие, но не обязательно оптимальные решения
2) его можно быстрее и проще реализовать, чем любой известный точный алгоритм
3) не существует задачи, которой нельзя описать эвристическим алгоритмом.
(многие основаны на методе частных целей и методе подъема)
Общий подход к построению эвристического алгоритма заключается в перечислении требований к общему решению и разделяется на два класса:
1) легко удовлетворять
2) не так легко удовлетворять
1) должны быть удовлетворены
2) те, по отношению к которым можно пойти на компромисс
Цель: Создать алгоритм, удовлетворяющий первые требования, но не обязательно вторые.
Пример:
13- оптимальных проходов 14-оптимальных проходов


В этом алгоритме реализована идея подъема, однако задача сведена к набору частных целей: найти на каждом шаге самый «дешевый» город.
Оптимальное решение имеет два свойства:
1) состоит из множества ребер, вместе представляющих тур (5 ребер)
(его гарантируем)
2) Стоимость никакого Другова не будет меньше заданного (идем на компромисс)
Рекурсия
В математике и программировании это метод определения или выражения функции или процедуры для решения задачи посредством той же функции или процедуры.

Рекуррентные соотношения - это соотношения, которые выражают значение функции при помощи других значений, вычисленных для меньших аргументов.

Для вычисления  нужно произвести рекурсивное обращение и вычислить
нужно произвести рекурсивное обращение и вычислить  , сделать N- рекурсивных обращений.
, сделать N- рекурсивных обращений.
Принято говорить, что глубина рекурсии, требуемая для вычисления 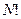 , равна N.
, равна N.
В машинных программах глубина рекурсии соответствует самой длинной последовательности обращений к процедуре требуемой для вычисления функции. Поэтому, глубина рекурсии – мера вычислительной сложности, рекурсивно определенной функции.
Глубина рекурсии ряда Фибоначчи равна (N-3)

Функция может быть дважды рекурсивна, если сама функция и один из ее аргументов определены через самих себя.
Пример: функция Аккермана.
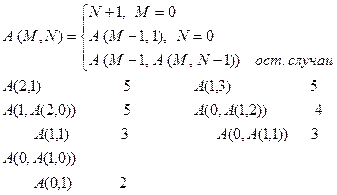
Массив:
int a [10] char char a [10] [10]


Сортировка
Сортировка стала важным предметом вычислительной математики в основном потому, что она отнимает значительную часть времени работы ЭВМ. Осознание того, что 25% всего времени вычислений расходуется на сортировку данных, придает особое значение эффективным алгоритмам сортировки.
К сожалению,нет алгоритма сортировки, который был бы наилучшим в любом случае. Трудно даже решить, какой алгоритм будет лучшим в данной ситуации, так как эффективность алгоритма сортировки может зависеть от множества факторов, например от того,(1) каково число сортируемых элементов; (2) все ли элементы могут быть помещены в доступную оперативную память;(3) до какой степени элементы уже отсортированы; (4) каковы диапазон и распределение значений сортируемых элементов; (5) записаны ли элементы на диске, магнитной ленте или перфокартах; (6) каковы длина, сложность и требования к памяти алгоритма сортировки; (7) предполагается ли, что элементы будут периодически исключаться или добавляться;(8) можно ли элементы сравнивать параллельно.
Очевидно, что с отсортированными данными работать легче, чем с произвольно расположенными. Когда элементы отсортированы, их проще найти (как в телефонном справочнике), обновить, исключить, включить и слить воедино. На отсортированных данных легче определить, имеются ли пропущенные элементы (как в колоде игральных карт), и удостовериться, что все элементы были проверены. Легче также найти общие элементы двух множеств, если они оба отсортированы. Сортировка применяется при трансляции программ, когда составляются таблицы символов; она также является важным средством для ускорения работы практически любого алгоритма, в котором часто нужно обращаться к определенным элементам.
Обычно сортируемые элементы представляют собой записи данных определенного вида. Каждая запись имеет поле ключа и поле информации. Поле ключа содержит положительное число,обычно целое, и записи упорядочиваются по значению ключа.
В этом разделе мы рассматриваем два из наиболее эффективных алгоритмов сортировки, быстрой сортировки и сортировки пирамидой (QUICKSORT и HEAPSORT), и устанавливаем теоретически неулучшаемые границы для всех алгоритмов сортировки с помощью сравнений. В других разделах обсуждаются еще два алгоритма сортировки: сортировка простыми включениями (SIS) и параллельная сортировка (PARSORT).
Поиск
Теперь обратимся к исследованию некоторых основных проблем, относящихся к поиску информации на стуктурах данных. Как и в предыдущем разделе, посвященному сортировки, будем предполагать, что вся информация хранится в записях, которые можно идентифицировать значениями ключей, т.е. записи Ri соответствует значение ключа,обозначаемое Ki.
Предположим,что в файле расположены случайным образом N записей в виде линейного массива. Очевидным методом поиска заданной записи будет последовательный просмотр ключей. Если найден нужный ключ, поиск оканчивается успешно; в противном случае будут просмотрены все ключи, а поиск окажется безуспешным.Если все возможные порядки расположения ключей равновероятны, то такой алгоритм требует O(N) основных операций как в худшем, так и в среднем случаях. Время поиска можно заметно уменьшить, если предварительно упорядочить файл по ключам. Эта предварительная работа имеет смысл, если файл достаточно велик и к нему обращаются часто.
Далее будем предполагать, что у нас есть N записей, уже упорядоченных по ключам так, что К1<К2<…<КN. Пусть дан ключ К и нужно найти соответствующую запись в файле (безуспешный поиск).
Предположим, что мы обратились к середине файла и обнаружили там ключ Ki. Сравним К и Кi. Если К=Кi, то нужная запись найдена. Если К<Кi,то ключ К должен находиться в части файла, предшествующей Кi (если запись с ключом К вообще существует). Аналогично, если Кi<К, то дальнейший поиск следует вести в части файла, следующей за Кi. Если повторять эту процедуру проверки ключа Кi из середины непросмотренной части файла, тогда каждое безуспешное сравнение К с Кi будет исключать из рассмотрения приблизительно половину непросмотренной части.
Блок-схема этой процедуры, известной под названием двоичный поиск, приведена на рис.16
Algorithm BSEARCH (Binary search- двоичный поиск) поиска записи с ключом К в файле с N≥2 записями, ключи которых упорядочены по возрастанию К1<К2…<КN.
Шаг 0. [Инициализация] Set FIRST←1; LAST← N. (FIRST и LAST- указатели первого и последнего ключей в еще не просмотренной части файла.)
Шаг 1. [Основной цикл ] While LAST≥FIRST do through шаг 4 od.
Шаг 2. [Получение центрального ключа] Set I←|_(FIRST + LAST)/2_|.(Кi- ключ, расположенный в середине или слева от середины еще не просмотренной части файла.)
Шаг 3. [Проверка на успешное завершение ] If К=КI then PRINT «Успешное окончание, ключ равен КI»; and STOP fi.
Шаг 4. [ Сравнение] If K < KI then set LAST←I-1 else set FIRST←I+1 fi.
Шаг 5. [ Безуспешный поиск] PRINT «безуспешно»; and STOP.
Алгоритм BSEARCH используется для отыскания К=42 на рис.17.
Метод двоичного поиска можно также применить для того, чтобы представить упорядоченный файл в виде двоичного дерева. Значение ключа, найденное при первом выполнении шага 2 (К(8)=53), является корнем дерева. Интервалы ключей слева (1,7) и справа (9,16) от этого значения помещаются на стек. Верхний интервал снимается со стека и с помощью шага 2 в нем отыскивается средний элемент (или элемент слева от середины). Этот ключ (К(4)=33) становится следующим после корня элементом влево, если его значение меньше значения корня, и следующим вправо в противном случае. Подынтервалы этого интервала справа и слева от вновь добавленного ключа [(1,3), (5,7)] помещаются теперь на стек.Эта процедура повторяется до тех пор, пока стек не окажется пустым. На рис.18 показано двоичное дерево, которое было бы построено для 16 упорядоченных ключей с рис.17.
Двоичный поиск можно теперь интерпретировать как прохождение этого дерева от корня до искомой записи. Если достигнута конечная вершина, а заданный ключ не найден, искомая запись в данном файле отсутствует. Заметим, что число вершин на единственном пути от корня к заданному ключу К равно числу сравнений, выполняемых алгоритмом BSEARCH при попытке отыскания К.



Полное построение алгоритма
Algorithm - однозначно трактуемая процедура решения задач.
Процедура - конечная последовательность точно определенных шагов или операций, для выполнения каждой из которых требуется конечный объем ОП и времени, кроме того, алгоритм должен работать конечн. время при любых входных данных.
Алгоритм – процедура, которая может быть реализована на данном ПК при помощи данного языка.
Алгоритм имеется только тогда, когда можно написать программу для ЭВМ.
Уровень:
Шаг используется для определения функции
1. Допущения
N (городов)- 20 городов
Вояжер должен проехать по оптимальному пути
2. Построение модели
При разработки модели возникает два вопроса:
1) какие математические структуры больше всего подходят для задачи
2) существуют ли решенные аналогичные задачи
3. Разработка алгоритма
Algorithm EIS
4. Проверка правильности алгоритма
Правильно не значит эффективно. Алгоритмы редко хороши во всех отношениях.
5. Реализация алгоритма (программа)
При реализации алгоритма задаются следующие вопросы: какие структуры данных, каких они типов, сколько массивов, их размерность, какой язык.
6. Анализ алгоритма и его сложности
Существует количественный критерий.
Если А-алгоритм, n- размерность, - рабочая функция, дающая верхнюю границу для максимального числа основных операций, которые выполняет алгоритм А для решения задач в размерности n.
А- полиноминален, если рабочая функция растет не быстрее, чем полином от n, в противном случае А- экспоненциален.
7. Проверка программы (аналитически и экспериментально)
8. Документация
Некоторые основные приемы алгоритмизации







