Благодаря тому, что ОС берёт на себя всё взаимодействие с микроконтроллером, простейшее возможное приложение в общем-то ничуть не сложнее, чем традиционный «Hello world» на большом ПК:
#include <stdio.h>
int main(void)
{
puts("Hello World!");
printf("You are running RIOT on a(n) %s board.\n", RIOT_BOARD);
printf("This board features a(n) %s MCU.\n", RIOT_MCU);
return 0;
}
В структуре нашей ОС это приложение располагается в папке example/hello-world в файле main.c (оно там уже есть).
Однако, очевидно, чтобы его скомпилировать, необходимо сначала настроить среду сборки. Это делается по-разному в разных ОС.
1. Windows 8 и старее. К сожалению, придётся использовать среду MinGW, медленную и неудобную. Процедура установки нужных компонентов достаточно подробно описана здесь. Отмечу, что для работы с Git/GitHub придётся также отдельно поставить Git for Windows, который притащит свою урезанную версию MinGW. При желании всё это можно свести в один терминал MinGW, но проблем с очень низкой скоростью работы MinGW и общим его неудобством это не решит.
В целом, Windows 7 и Windows 8, как можно понять, являются не самым удачным выбором для разработки.
2. Windows 10. Откройте магазин Microsoft Store, найдите в нём Ubuntu и установите. Если при первом запуске Ubuntu будет ругаться на выключенный компонент Windows, откройте системное приложение «Включение или отключение компонентов Windows», найдите там «Поддержка Windows для Linux» и включите.
Вся дальнейшая работа происходит в среде Ubuntu, значительно более комфортной и быстрой, нежели MinGW.
Скачайте компилятор и сопровождающие его утилиты отсюда (внимание: вам нужна 64-битная версия для Linux!), откройте Ubuntu, распакуйте архив и укажите системе пути к нему:
cd /opt
sudo tar xf /mnt/c/Users/vasya/Downloads/gcc-arm-none-eabi-7-2017-q4-major-linux.tar.bz2
export PATH=/opt/gcc-arm-none-eabi-7-2017-q4-major/bin/:$PATH
export PATH=/opt/gcc-arm-none-eabi-7-2017-q4-major/arm-none-eabi/bin/:$PATH
echo "export PATH=/opt/gcc-arm-none-eabi-7-2017-q4-major/bin/:\$PATH" >> ~/.bashrc
echo "export PATH=/opt/gcc-arm-none-eabi-7-2017-q4-major/arm-none-eabi/bin/:\$PATH" >> ~/.bashrc
Последние две команды пропишут установку путей к компилятору и утилитам в файл.bashrc, так что вам не придётся вручную их устанавливать при каждом запуске Ubuntu. Обратите внимание на обратную дробь перед $ и двойную стрелку >> в конце — без первого путь будет записан некорректно, без второго (с одиночной стрелкой) вы сотрёте всё предыдущее содержимое.bashrc.
После этого выполнение в консоли команды arm-none-eabi-gcc --version должно сообщать, что такой компилятор есть, а его версия — 7.2.1 (на текущий момент).
Для работы с Git вам потребуется сгенерировать пару из приватного и публичного ключей командой ssh-keygen, после чего скопировать публичный ключ (в Ubuntu под Windows это можно сделать командой cat ~/.ssh/id_rsa.pub, потом выделить выведенное мышкой и нажать Enter — оно скопируется в буфер обмена) и добавить его в ваш аккаунт GitHub. После этого можно будет работать с GitHub из командной строки командой git.
NB: если вы ранее не работали в командной строке Linux, то обратите внимание на два полезных момента: курсорные стрелки вверх и вниз позволяют листать историю введённых команд, а клавиша Tab дополняет набранный вами путь к файлу или папке до конца (то есть cd /opt/gcc- превратится в строку cd /opt/gcc-arm-none-eabi-7-2017-q4-major). Последнее служит также хорошей проверкой, правильно ли вы набираете путь — если неправильно, дополнен он по очевидной причине не будет. Если возможных вариантов дополнения несколько, то двойное нажатие Tab выведет их все.
NB: в Windows вам будет удобнее работать, если сами исходные коды ОС размещаются в папке, напрямую доступной из Windows, например Documents/git/RIOT. Из-под MinGW она будет доступна по пути /c/Users/vasya/Documents/git/RIOT, из-под Ubuntu — /mnt/c/Users/vasya/Documents/git/RIOT. В этом случае вы сможете свободно пользоваться для работы с кодом, например, текстовыми редакторами, написанными для Windows, такими как Notepad++.
3. Linux. Установка среды сборки ничем не отличается от инструкции для Windows 10, кроме того, что Microsoft Store вам не потребуется. Также не ищите gcc-arm-none-eabi в репозитории вашего дистрибутива — скачайте наиболее свежую версию с его официального сайта.
После установки среды сборки откройте консоль, перейдите в папку с RIOT и в подпапку examples/hello-world, после чего запустите команду make.
Скорее всего, она быстро прервётся ошибкой и сообщением, что у вас не хватает unzip (под Windows 10 по умолчанию он не устанавливается), make или других утилит. В Windows 10 их можно установить командой (перечень недостающего даётся простым списком через пробел):
sudo apt-get install unzip make
После установки попробуйте ещё раз запустить make — точнее, оптимальным вариантом является вызов команды «make clean && make»: первая очищает мусор, оставшийся от предыдущей попытки. Без ней компилятор может ошибочно решить, что какой-то из уже собранных модулей не менялся, и не пересобирать его — в результате вы получите прошивку, собранную из кусков старого и нового кода.
NB: в оригинальном RIOT приложение hello-world собирается для архитектуры native, то есть, в нашем случае ноутбука или десктопа, x86. Однако в нашем коде в параметрах сборки проекта уже указана плата unwd-range-l1-r3, использующая контроллер stm32, поэтому в начале процедуры вы должны увидеть строку
Building application "mirea" for "unwd-range-l1-r3" with MCU "stm32l1".
В случае успеха за ней вы увидите десяток-два строчек, начинающихся с команды make — это сборка отдельных компонентов операционной системы. Закончится всё сообщением об успешном создании файла прошивки mirea.elf с указанием размеров различных типов данных (объёмов используемой флэш-памяти и ОЗУ).
Как-то вот так: 
Итак, мы немного разобрались с тем, как выглядит микроконтроллер, скачали исходные коды нашей ОС, настроили среду сборки и убедились, что она работает.
Контрольные вопросы
1. Что такое Arduino IDE, для чего используется?
2. Что такое Proteus 8 Pro, для чего используется?
3. Для чего необходима симуляция электрической цепи?
4. Как выполнить компилирование скетча для Arduino Uno?
5. Как написать скетч для Arduino Uno?
6. Как настроить Bluetooth на ПК?
Тестовые задания
1. Акустическая модель описывает:
1) плотность распределения вероятностей акустических классов;
2) вероятность перехода между состояниями трифона;
3) вероятность перехода между состояниями фонемы.
2. Языковая модель описывает вероятность:
1) появления фонемы в окружении других фонем;
2) появления трифона в окружении других фонем;
3) появления слова в контексте других слов.
3. Языковая модель является
10) статистической моделью;
11) математической моделью;
12) скрытой марковской моделью;
13) гауссовой смесью.
4. Форма представления 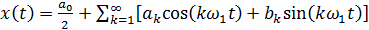 функции x (t) в виде ряда Фурье является:
функции x (t) в виде ряда Фурье является:
5) синусно-косинусной;
6) амплитудно-фазовой;
7) комплексной.
5. Форма представления 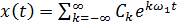 , где
, где 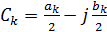 , функции x (t) в виде ряда Фурье является:
, функции x (t) в виде ряда Фурье является:
1) синусно-косинусной;
2) амплитудно-фазовой;
3) комплексной.
6. Сумма 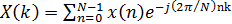 ,
, 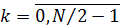 , является:
, является:
8) быстрым преобразованием Фурье дискретного сигнала длины N;
9) прямым дискретным преобразованием Фурье дискретного сигнала длины N;
10) обратным дискретным преобразованием Фурье дискретного сигнала длины N;
11) прямым непрерывным преобразованием Фурье дискретного сигнала длины N;
12) обратным непрерывным преобразованием Фурье дискретного сигнала длины N.
7. В спектрограмме сигнала разрешение по частоте f и по времени t ограничиваются неравенством:
8) Δ t / Δ f ≤1/4 π;
9) Δ t Δ f ≤1/4 π;
10) Δ t Δ f ≤1/4 π;
11) Δ t Δ f ≤1/2 π;
12) Δ f / Δ t ≤1/4 π;
13) Δ f / Δ t ≤1/2 π.
8. Пусть: N 1 = 512 –длина окна анализа сигнала; Fs = 22050 – частота дискретизации сигнала; x – массив отсчетов исходного сигнала размером 24001, тогда:
18) длительность сигнала составит 1.5 с; диапазон анализируемых частот [0, 10005] Гц; разрешающая способность по частоте составляет 52 Гц;
19) длительность сигнала составит 3.05 с; диапазон анализируемых частот [0, 11025] Гц; разрешающая способность по частоте составляет 34 Гц;
20) длительность сигнала составит 1.088 с; диапазон анализируемых частот [0, 11025] Гц; разрешающая способность по частоте составляет 44 Гц.
9. Чтобы функция ψ (t) была вейвлетом необходимо и достаточно:
1) функция ψ (t) локализована, т.е. ψ (t) Î L 2(R);
2) функция ψ (t) локализована и имеет нулевое среднее;
3) функция ψ (t) локализована первые её m моментов равны нулю
10. Представление сигнала f в виде
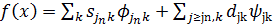 ,
,
где ψ – базисный вейвлет, φ – масштабная, функция является:
4) дискретным вейвлет-преобразованием;
5) непрерывным вейвлет-преобразованием;
6) вейвлет-преобразованием Добеши;
7) быстрым вейвлет-преобразованием.
11. Кепстр – это:
5) обратное дискретное косинусное преобразование логарифмированной энергии;
6) обратное Фурье-преобразование логарифма мощности сигнала;
7) обратное дискретное косинусное преобразование свертки сигнала с оконной функцией;
12. Какое из утверждений правильное:
7) в пределах одной критической полосы порог восприятия незначительно меняется;
8) на субъективный взгляд слушателя частота гармонического сигнала в пределах одной критической полосы в два раза выше или ниже по сравнению с соседней полосой.
13. Линейный предсказатель с коэффициентами α k определяется как система, на выходе которой выполняется равенство
1) 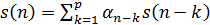 ;
;
2) 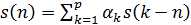 ;
;
3) 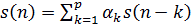 ;
;
4) 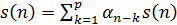 .
.
14. Какие из следующих утверждений верны:
1) модель гауссовых смесей не игнорирует временную информацию об акустической наблюдаемой последовательности;
2) модель гауссовых смесей игнорирует временную информацию об акустической наблюдаемой последовательности;
3) модель гауссовых смесей является параметрической вероятностной функцией, представляющей собой взвешенную сумму функций гауссовых распределений;
4) модель гауссовых смесей не используется в качестве модели функции распределения акустических характеристик лишь в случае пофонемного распознавания;
15. Процесс называется марковским, если для каждого момента времени вероятность любого состояния системы в следующий момент зависит:
1) только от состояния системы в настоящий момент;
2) от того, каким образом система пришла в это состояние;
3) от n предыдущих состояний.
16. С помощью марковских моделей можно описать:
1) только акустическую модель, но не модель языка;
2) только модель языка, но не акустическую модель;
3) и акустическую модель, и модель языка.
17. Цель векторного квантования:
1) переход от вектора признаков к одному числу в определенном диапазоне;
2) переход от непрерывного вектора признаков к дискретному вектору путем квантования каждой компоненты;
3) кластеризация множества эталонов слов.
18. Задача распознавания при использовании скрытых марковских моделей решается с помощью алгоритма:
1) Витерби;
2) только «Вперёд»;
3) только «Назад»;
4) «Вперёд-назад»;
5) Баума-Уэлша.
19. Задача обучения скрытой марковской модели решается с помощью алгоритма:
1) «Вперёд-назад»;
2) только «Вперёд»;
3) Витерби;
4) только «Назад»;
5) Баума-Уэлша.
20. Чему равна вероятность наблюдать последовательность x 1, x 2,…, xt для модели λ ={ A, B, π } и оказаться в состоянии si в момент времени t = 1:
1) πiBi (x 1);
2) 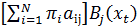 ;
;
3)  .
.
21. Чему равна вероятность наблюдать последовательность x t +1, x t +2,…, x T (T – конечный момент времени) для модели λ ={ A, B, π } и оказаться в состоянии si в момент времени t = Т:
1) 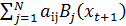 ;
;
2) 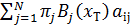 ;
;
3) 1;
4)  .
.
22. Алгоритм DTW используют преимущественно для:
1) распознавания изолированных слов;
2) пофонемного распознавания;
3) распознавания трифонов.
23. Какая из метрик позволяет учесть корреляцию и вариативность признаков:
1) Евклидова метрика;
2) метрика Махаланобиса;
3) квартально-блочная метрика;
4) метрика Итакуро-Саито.
ЗАКЛЮЧЕНИЕ
Речь является наиболее естественным для человека средством коммуникации. Важнейшей составляющей человеко-машинного интерфейса являются системы автоматического распознавания речи, они в основном используются для моделирования привычного для человека общения с машиной.
Автоматическое распознавание речи является динамично развивающимся направлением в области искусственного интеллекта. За последние полвека в данной области достигнуты значительные успехи – имеется множество коммерческих приложений, которые делают вложения в данную область оправданными и выгодными.
Стоит отметить, что на сегодняшний день в сфере распознавания речи успехи достигнуты только в пределах ограниченного словарного запаса. Это обусловлено трудностями, возникающими при разработке систем автоматического распознавания речи: речь, характеризуется отсутствием заранее подготовленной формы и содержания устного сообщения, фраза обладает высокой вариативностью на всех уровнях обработки речи, усложняет задачу распознавания, присутствующий в речи фоновый шум. Поэтому поиск робастных акустических характеристик речевого сигнала является актуальной задачей.
В ходе выполнения лабораторных работ студенты изучают способы параметризации речевого сигнала, строят различные наборы признаков для пофонемного распознавания речи, анализируют их эффективность на вероятностных и нейросетевых классификаторах. Кроме того, используя методы динамического программирования, студенты учатся строить распознаватель речевых команд малого словаря. В результате чего у студентов формируется понимание теоретической базы компьютерного анализа речи, умение применять стандартные методы и модели к решению задач распознавания и обработки речевых сигналов, навыки и опыт работы с основными принципами и методами обработки речевых данных, навыками применения речевых технологий и программ для анализа звука на ЭВМ.
ЛИТЕРАТУРА
1. Кипяткова И.С. Автоматическая обработка разговорной русской речи / И.С.Кипяткова, А.Л.Ронжин, А.А.Карпов. – СПб.: ГУАП, 2013. – 314 с.
2. Тампель И.Б. Автоматическое распознавание речи. Учебное пособие / И.Б.Тампель, А.А.Карпов. − СПб: Университет ИТМО, 2016. – 138 с.
3. Малла С. Вэйвлеты в обработке сигналов: Пер. с англ. / С.Малла. – М.: Мир, 2005. – 672 с.
4. Оппенгейм А. Цифровая обработка сигналов. Пер. с англ. / А.Оппенгейм, Р.Шафер. – М.: Техносфера, 2006. – 858 с.
5. Рабинер Л.Р. Цифровая обработка речевых сигналов: пер. с англ. / Л.Р. Рабинер, Р.В. Шафер. – М.: «Радио и связь», 1981. – 782 с.
6. Маркел Дж.Д., Грэй А.X. Линейное предсказание речи: Пер. с английского / Под редакцией Ю.Н. Прохорова и В.С. Звездина. – Москва: Издательство «Связь», 1980. – 308 с.
7. АЧИЛОВ Р. SSL-сертификаты сайтов. Назначение и использование //Системный администратор. – 2010. – №. 3. – С. 64-68.
8. Lee J., Ware B. Open Source Web Development with LAMP: Using Linux, Apache, MySQL, Perl, and PHP. – Addison-Wesley Professional, 2003.
9. Дронов В. А. JavaScript в Web-дизайне. – БХВ-Петербург, 2005.
10. Робин Н. Создаем динамические веб-сайты с помощью PHP, MySQL, JavaScript, CSS и HTML5. 4-е изд. – " Издательский дом"" Питер""", 2016.
11. Clifton I. G. Android user interface design: implementing material design for developers. – Addison-Wesley Professional, 2015.
12.
Маруга М.М.
лабораторные работы по ИНТЕРНЕТ-ТЕХНОЛОГИЯМ:
учебно-методическое пособие по дисциплине «Интернет технологии»
для студентов по направлению подготовки
09.04.01 «Информатика и вычислительная техника»
(для всех форм обучения)





