Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы обеспечить пользователю удобный интерфейс при работе с данными, хранящимися на диске, и обеспечить совместное использование файлов несколькими пользователями и процессами.
В широком смысле понятие "файловая система" включает:
- совокупность всех файлов на диске,
- наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске,
- комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами.
Файлы
Файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Файлы хранятся в памяти, не зависящей от энергопитания, обычно — на магнитных дисках.
Типы файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых, как правило, входят обычные файлы, файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и другие.
Обычные файлы, или просто файлы, содержат информацию произвольного характера, которую заносит в них пользователь или которая образуется в результате работы системных и пользовательских программ.
Каталоги — это особый тип файлов, которые содержат системную справочную информацию о наборе файлов, сгруппированных пользователями по какому-либо неформальному признаку (например, в одну группу объединяются файлы, содержащие документы одного договора, или файлы, составляющие один программный пакет).
Специальные файлы — это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к файлам и внешним устройствам. Специальные файлы позволяют пользователю выполнять операции ввода-вывода посредством обычных команд записи в файл или чтения из файла. Эти команды обрабатываются сначала программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются операционной системой в команды управления соответствующим устройством.
Современные файловые системы поддерживают и другие типы файлов, такие как символьные связи, именованные конвейеры, отображаемые в память файлы.
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некую логическую структуру. Эта структура является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть либо целиком возложено на приложение, либо в той или иной степени эту работу может взять на себя файловая система.
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла целиком относятся к ведению приложения, файл представляется ФС неструктурированной последовательностью данных. При этом формат файла, в котором хранится объектный модуль, известен только этим программам.
Другая модель файла, которая применялась в ОС OS/360, DEC RSX и VMS, а в настоящее время используется достаточно редко, — это структурированный файл. В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. Приложение может обращаться к ФС с запросами на ввод-вывод на уровне записей, например «считать запись 25 из файла FILE.DOC». ФС должна обладать информацией о структуре файла, достаточной для того, чтобы выделить любую запись. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением. Развитием этого подхода стали системы управления базами данных (СУБД), которые поддерживают не только сложную структуру данных, но и взаимосвязи между ними.
Логическая запись является наименьшим элементом данных, которым может оперировать программист при организации обмена с внешним устройством. Даже если физический обмен с устройством осуществляется большими единицами, операционная система должна обеспечивать программисту доступ к отдельной логической записи.
Файловая система может использовать два способа доступа к логическим записям: читать или записывать логические записи последовательно (последовательный доступ) или позиционировать файл на запись с указанным номером (прямой доступ).
Очевидно, что ОС не может поддерживать все возможные способы структурирования данных в файле, поэтому в тех ОС, в которых вообще существует поддержка логической структуризации файлов, она существует для небольшого числа широко распространенных схем логической организации файла.
К числу таких способов структуризации относится представление данных в виде записей, длина которых фиксирована в пределах файла (рис. 7.7, а). В таком случае доступ к n-й записи осуществляется либо путем последовательного чтения (n-1) предшествующих записей, либо прямо по адресу, вычисленному по ее порядковому номеру. Например, если L — длина записи, то начальный адрес n-й записи равен L*n. Заметим, что при такой логической организации размер записи фиксирован в пределах файла, а записи в различных файлах, принадлежащих одной и той же файловой системе, могут иметь различный размер.
Другой способ структуризации состоит в представлении данных в виде последовательности записей, размер которых изменяется в пределах одного файла. Если расположить значения длин записей так, как это показано на рис. 7.7, б, то для поиска нужной записи система должна последовательно считать все предшествующие записи. Вычислить адрес нужной записи по ее номеру при такой логической организации файла невозможно, а следовательно, не может быть применен более эффективный метод прямого доступа.
Файлы, доступ к записям которых осуществляется последовательно, по номерам позиций, называются неиндексированными, или последовательными.

Другим типом файлов являются индексированные файлы, они допускают более быстрый прямой доступ к отдельной логической записи. В индексированном файле (рис. 7.7, в) записи имеют одно или более ключевых (индексных) полей и могут адресоваться путем указания значений этих полей. Для быстрого поиска данных в индексированном файле предусматривается специальная индексная таблица, в которой значениям ключевых полей ставится в соответствие адрес внешней памяти. Этот адрес может указывать либо непосредственно на искомую запись, либо на некоторую область внешней памяти, занимаемую несколькими записями, в число которых входит искомая запись. В последнем случае говорят, что файл имеет индексно-последовательную организацию, так как поиск включает два этапа: прямой доступ по индексу к указанной области диска, а затем последовательный просмотр записей в указанной области. Ведение индексных таблиц берет на себя файловая система. Понятно, что записи в индексированных файлах могут иметь произвольную длину.
Все вышесказанное в большей степени относится к обычным файлам, которые могут быть как структурированными, так и неструктурированными. Что же касается других типов файлов, то они обладают определенной структурой, известной файловой системе. Например, файловая система должна понимать структуру данных, хранящихся в файле-каталоге или файле типа «символьная связь».
Физическая организация и адресация файла
Важным компонентом физической организации файловой системы является физическая организация файла, то есть способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Непрерывное размещение — простейший вариант физической организации (рис. 7.11, а), при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти. Основным достоинством этого метода является высокая скорость доступа, так как затраты на поиск и считывание кластеров файла минимальны. Также минимален объем адресной информации — достаточно хранить только номер первого кластера и объем файла. Данная физическая организация максимально возможный размер файла не ограничивает. Однако этот вариант имеет существенные недостатки, которые затрудняют его применимость на практике, несмотря на всю его логическую простоту. При более пристальном рассмотрении оказывается, что реализовать эту схему не так уж просто. Действительно, какого размера должна быть непрерывная область, выделяемая файлу, если файл при каждой модификации может увеличить свой размер? Еще более серьезной проблемой является фрагментация. Спустя некоторое время после создания файловой системы в результате выполнения многочисленных операций создания и удаления файлов пространство диска неминуемо превращается в «лоскутное одеяло», включающее большое число свободных областей небольшого размера. Как всегда бывает при фрагментации, суммарный объем свободной памяти может быть очень большим, а выбрать место для размещения файла целиком невозможно. Поэтому на практике используются методы, в которых файл размещается в нескольких, в общем случае несмежных областях диска.

Следующий способ физической организации — размещение файла в виде связанного списка кластеров дисковой памяти (рис. 7.11, б). При таком способе в начале каждого кластера содержится указатель на следующий кластер. В этом случае адресная информация минимальна: расположение файла может быть задано одним числом — номером первого кластера. В отличие от предыдущего способа каждый кластер может быть присоединен к цепочке кластеров какого-либо файла, следовательно, фрагментация на уровне кластеров отсутствует. Файл может изменять свой размер во время своего существования, наращивая число кластеров. Недостатком является сложность реализации доступа к произвольно заданному месту файла — чтобы прочитать пятый по порядку кластер файла, необходимо последовательно прочитать четыре первых кластера, прослеживая цепочку номеров кластеров. Кроме того, при этом способе количество данных файла, содержащихся в одном кластере, не равно степени двойки (одно слово израсходовано на номер следующего кластера), а многие программы читают данные кластерами, размер которых равен степени двойки.
Популярным способом, применяемым, например, в файловой системе FAT, является использование связанного списка индексов (рис. 7.11, в). Этот способ является некоторой модификацией предыдущего. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связывается некоторый элемент — индекс. Индексы располагаются в отдельной области диска — в MS-DOS это таблица FAT (File Allocation Table), занимающая один кластер. Когда память свободна, все индексы имеют нулевое значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого кластера становится равным либо номеру М следующего кластера данного файла, либо принимает специальное значение, являющееся признаком того, что этот кластер является для файла последним. Индекс же предыдущего кластера файла принимает значение N, указывая на вновь назначенный кластер.
При такой физической организации сохраняются все достоинства предыдущего способа: минимальность адресной информации, отсутствие фрагментации, отсутствие проблем при изменении размера. Кроме того, данный способ обладает дополнительными преимуществами. Во-первых, для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов, отсчитать нужное количество кластеров файла по цепочке и определить номер нужного кластера. Во-вторых, данные файла заполняют кластер целиком, а значит, имеют объем, равный степени двойки.
Еще один способ задания физического расположения файла заключается в простом перечислении номеров кластеров, занимаемых этим файлом (рис. 7.11, г). Этот перечень и служит адресом файла. Недостаток данного способа очевиден: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Достоинством же является высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла. Фрагментация на уровне кластеров в этом способе также отсутствует.
Последний подход с некоторыми модификациями используется в традиционных файловых системах ОС UNIX s5 и ufs1. Для сокращения объема адресной информации прямой способ адресации сочетается с косвенным.
В стандартной на сегодняшний день для UNIX файловой системе ufs используется следующая схема адресации кластеров файла. Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт (рис. 7.12). Если размер файла меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если кластер имеет размер 8 Кбайт (максимальный размер кластера, поддерживаемого в ufs), то таким образом можно адресовать файл размером до 8192x12 *» 98 304 байт.
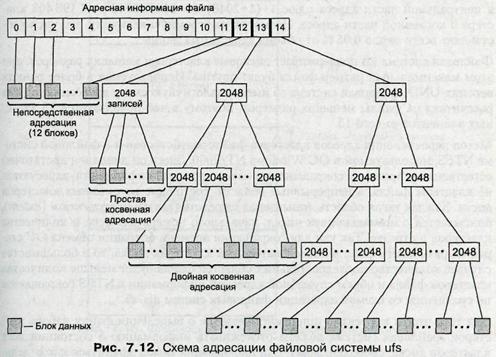
Если размер файла превышает 12 кластеров, то следующее 13-е поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров файла. Таким образом, 13-й элемент адреса используется для косвенной адресации. При размере в 8 Кбайт кластер, на который указывает 13-й элемент, может содержать 2048 номеров следующих кластеров данных файла и размер файла может возрасти до 8192х(12+2048)=16 875 520 байт.
Если размер файла превышает 12+2048 = 2060 кластеров, то используется 14-е поле, в котором находится номер кластера, содержащего 2048 номеров кластеров, каждый из которых хранят 2048 номеров кластеров данных файла. Здесь применяется уже двойная косвенная адресация. С ее помощью можно адресовать кластеры в файлах, содержащих до 8 192х(12+2048+20482) = 3,43766x10*° байт.
И наконец, если файл включает более 12+2048+20482 = 4 196 364 кластеров, то используется последнее 15-е поле для тройной косвенной адресации, что позволяет задать адрес файла, имеющего следующий максимальный размер:
8192х(12+2048+20482+20483)=7,0403х1013байт.
Таким образом, файловая система ufs при размере кластера в 8 Кбайт поддерживает файлы, состоящие максимум из 70 триллионов байт данных, хранящихся в 8 миллиардах кластеров. Как видно на рис. 7.12, для задания адресной информации о максимально большом файле требуется: 15 элементов по 4 байта (60 байт) в центральной части адреса плюс 1+(1+2048)+(1+2048+20482) - 4 198 403 кластера в косвенной части адреса. Несмотря на огромную величину, это число составляет всего около 0,05 % от объема адресуемых данных.
Файловая система ufs поддерживает дисковые кластеры и меньших размеров, при этом максимальный размер файла будет другим. Используемая в более ранних версиях UNIX файловая система s5 имеет аналогичную схему адресации, но она рассчитана на файлы меньших размеров, поэтому в ней используется 13 адресных элементов вместо 15.
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS, используемой в ОС Windows NT/2000. Здесь он дополнен достаточно естественным приемом, сокращающим объем адресной информации: адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область, называемая отрезком (run), или экстентом (extent), описывается с помощью двух чисел: начального номера кластера и количества кластеров в отрезке. Так как для сокращения времени операции обмена ОС старается разместить файл в последовательных кластерах диска, то в большинстве случаев количество последовательных областей файла будет меньше количества кластеров файла и объем служебной адресной информации в NTFS сокращается по сравнению со схемой адресации файловых систем ufs/s5.
Для того чтобы корректно принимать решение о выделении файлу набора кластеров, файловая система должна отслеживать информацию о состоянии всех кластеров диска: свободен/занят. Эта информация может храниться как отдельно от адресной информации файлов, так и вместе с ней.
Организация
Функционирование любой файловой системы можно представить многоуровневой моделью (рисунок 2.36), в которой каждый уровень предоставляет некоторый интерфейс (набор функций) вышележащему уровню, а сам, в свою очередь, для выполнения своей работы использует интерфейс (обращается с набором запросов) нижележащего уровня.

Рис. 2.36. Общая модель файловой системы
Задачей символьного уровня является определение по символьному имени файла его уникального имени. В файловых системах, в которых каждый файл может иметь только одно символьное имя (например, MS-DOS), этот уровень отсутствует, так как символьное имя, присвоенное файлу пользователем, является одновременно уникальным и может быть использовано операционной системой. В других файловых системах, в которых один и тот же файл может иметь несколько символьных имен, на данном уровне просматривается цепочка каталогов для определения уникального имени файла. В файловой системе UNIX, например, уникальным именем является номер индексного дескриптора файла (i-node).
На следующем, базовом уровне по уникальному имени файла определяются его характеристики: права доступа, адрес, размер и другие. Характеристики файла могут входить в состав каталога или храниться в отдельных таблицах. При открытии файла его характеристики перемещаются с диска в оперативную память, чтобы уменьшить среднее время доступа к файлу. В некоторых файловых системах (например, HPFS) при открытии файла вместе с его характеристиками в оперативную память перемещаются несколько первых блоков файла, содержащих данные.
Следующим этапом реализации запроса к файлу является проверка прав доступа к нему. Для этого сравниваются полномочия пользователя или процесса, выдавших запрос, со списком разрешенных видов доступа к данному файлу. Если запрашиваемый вид доступа разрешен, то выполнение запроса продолжается, если нет, то выдается сообщение о нарушении прав доступа.
На логическом уровне определяются координаты запрашиваемой логической записи в файле, то есть требуется определить, на каком расстоянии (в байтах) от начала файла находится требуемая логическая запись. При этом абстрагируются от физического расположения файла, он представляется в виде непрерывной последовательности байт. Алгоритм работы данного уровня зависит от логической организации файла. Например, если файл организован как последовательность логических записей фиксированной длины l, то n-ая логическая запись имеет смещение l(n-1) байт. Для определения координат логической записи в файле с индексно-последовательной организацией выполняется чтение таблицы индексов (ключей), в которой непосредственно указывается адрес логической записи.

Рис. 2.37. Функции физического уровня файловой системы
Исходные данные:
V - размер блока
N - номер первого блока файла
S - смещение логической записи в файле
Требуется определить на физическом уровне:
n - номер блока, содержащего требуемую логическую запись
s - смещение логической записи в пределах блока
n = N + [S/V], где [S/V] - целая часть числа S/V
s = R [S/V] - дробная часть числа S/V
На физическом уровне файловая система определяет номер физического блока, который содержит требуемую логическую запись, и смещение логической записи в физическом блоке. Для решения этой задачи используются результаты работы логического уровня - смещение логической записи в файле, адрес файла на внешнем устройстве, а также сведения о физической организации файла, включая размер блока. Рисунок 2.37 иллюстрирует работу физического уровня для простейшей физической организации файла в виде непрерывной последовательности блоков. Подчеркнем, что задача физического уровня решается независимо от того, как был логически организован файл.
После определения номера физического блока, файловая система обращается к системе ввода-вывода для выполнения операции обмена с внешним устройством. В ответ на этот запрос в буфер файловой системы будет передан нужный блок, в котором на основании полученного при работе физического уровня смещения выбирается требуемая логическая запись.
Разновидности
FAT – Файловая система MS DOS, предположительно разработана лично Биллом Гейтсом. В основе системы FAT лежит таблица размещения файлов (также называемая FAT). FAT представляет собой таблицу элементов, каждый из которых соответствует одному кластер, два экземпляра FAT (основной и резервный) хранятся в начале диска, сразу после загрузочного сектора) Имеются системы FAT12, FAT16 и FAT32 в зависимости от числа бит, отводимых на элемент FAT.
В загрузочном секторе тома FAT хранится код загрузчика, метка диска и различная информация, в том числе размер кластера и т. п.
Имена файлов хранятся в виде записей в каталогах. Каталог занимает один или более кластеров. Структура записи в каталоге (FAT32):
Если файл занимает несколько кластеров, он необязательно хранится в смежных кластерах. Элемент каталога указывает на первый кластер, а в элементе FAT, соответствующием этому кластеру, записан номер следующего кластера (или FF – признак конца файла). Некоторые кластеры могут быть помечены в FAT как плохие, в случае если они содержат поврежденные сектора диска.
Общее число кластеров на диске определяется размерностью элемента FAT, размер кластера – соотношением общего числа и раздела диска. Увеличение размера элемента приводит к более эффективному использованию дискового пространства больших дисков, так как увеличивается число кластеров, хотя размер самой FAT увеличивается. При числе секторов в кластере 64 максимальный размер тома FAT16 2Гб
В Windows 95 к файловой системе FAT добавлена возможность использования длинных имен файлов и использования ранее запрещенных символов в именах. Для файлов с длинными именами в каталоге создаются специальные элементы каталога.
NTFS – файловая система Windows NT, имеет повышенную надежность за счет журналирования файловых операций и встроенную поддержку контроля доступа.
Первые 12% дискового пространства NTFS отводится под MFT (master file table), которая представляет собой таблицу записей о всех файлах тома (под файлом понимается любой объект, записываемый на диск, в том числе сама MFT и различные области метаданных). В начале MFT содержатся записи о 16 метафайлах: самой MFT, копия первых 16 записей MFT в середине тома, размещенная посередине тома, файл журналирования, общая информация (о метке тома и т. п.), список стандартных атрибутов файлов (в смысле NTFS), корневой каталог, карта свободного места, загрузочный сектор, файл дисковых квот (Windows 2000, NTFS 5.0), таблица соответствия больших и малых букв.
Каждый файл идентифицируется номером записи в MFT. Запись MFT имеет размер от 1К и содержит всю информацию о файле, а также сам файл, если его размер не велик. Кроме записи с файлом может быть связаны один или несколько атрибутов.
HPFS – файловая система OS/2
Файловые системы UNIX – Существует много разновидностей файловых систем UNIX, но основные принципы во всех системах одни и те же (это все inode-файловые системы).
Примерами ФС этого семейства являются s5fs (System V UNIX, в настоящее вермя устарела), ffs (FreeBSD), minix и extfs – файловые системы первых версий Linux, ext2fs – основная файловая система LINUX, ReiserFS и ext3fs – системы для Linux c поддержкой журанлирования.
Большинство современных UNIX поддерживают несколько файловых систем, в том числе FAT и NTFS благодаря мощной системе управления файлами, называемой «виртуальной файловой системой» (VFS). В отличии от Windows в UNIX на файловую систему возлагаются функции интерфейса с драйверами и ядром ОС.








