Машинное обучение
Методические указания к выполнению лабораторных работ для студентов магистратуры, обучающихся по направлению подготовки 09.04.01 – «Информатика и вычислительная техника»
Донецк – 2016
Лабораторная робота №1
Тема: построение регрессионной модели с помощью метода ближайших соседей.
Цель: практическая реализация простейших метрических алгоритмов классификации, приобретение навыков анализа эффективности работы классификаторов.
Задача на лабораторную работу
В самолете за каждый лишний сантиметр, выходящий за габариты необходимо заплатить 3$, а за каждый лишний килограмм веса - 4$. Всего у пассажира – 30$. Функция классификации пассажиру неизвестна, поэтому он интуитивно пытается сформировать свой багаж и каждый раз проходит процедуру контроля. Пример обучающей выборки представлен в таблице 1. будет выглядеть примерно так (10 примеров):
Таблица 1. Обучающая выборка для задачи контроля багажа
| №
| ΔS
| Δm
| Класс [0,1]
|
|
|
|
| 1 – контроль пройден
|
|
|
|
| 0 – контроль не пройден
|
| …
| …
| …
| …
|
|
|
|
|
|
Порядок выполнения работы
1. Составить обучающую последовательность из 10 экспериментов и 10 «контрольных» значений (в виде таблицы 1).
2. Реализовать метод сравнения с эталоном различными метриками (направляющие косинусы, евклидово расстояние, расстояние Танимото). В качестве эталона использовать среднее значения признаков из обучающей выборки.
3. Реализовать алгоритм KNN - k ближайших соседей с различными метриками. Подобрать оптимальные параметры алгоритма k от 2 до 5, используя критерий скользящего контроля с исключением объектов по одному и одну из трех реализованных метрик.
4. Реализация алгоритмов должна предусматривать графические отображения обучающей и контрольной выборок, эталонов и результатов классификации.
5. Оценить распознающую способность (классификация образов из обучающей выборки) и обобщающую способность (классификацию «контрольных» образов) классификаторов. В качестве функции потерь использовать индикатор несовпадения с правильным ответом.
6. Оформить отчет по лабораторной работе.
Метод эталонных образов
В основу метода положена идея, которая заключается в том, что некоторая совокупность объектов, объединенных в отдельный класс, может быть представлена одним или несколькими эталонными объектами. Эти эталонные объекты являются наиболее типичными представителями класса. Типичность эталонного объекта означает, что он в среднем максимально похож на все объекты класса. Поскольку сходство двух объектов может трактоваться как величина, противоположная расстоянию между ними в пространстве описаний (образов), то эталон – это объект, для которого минимально среднее расстояние до других объектов.
Пусть в обучающей выборке первому классу соответствует M 1 элементов x 1, i , а второму классу – M 2 элементов x 2, i . Тогда эталонные образы для каждого из классов могут быть определены как оценки математических ожиданий (средние):
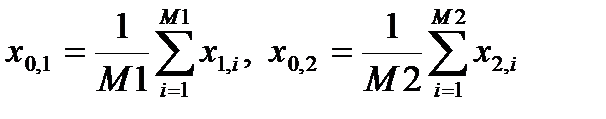 .
.
Классы, однако, могут обладать разными свойствами. Простейшим свойством является компактность класса в пространстве признаков (рис. 1). Этот параметр может быть оценен через среднеквадратичное отклонение (СКО):
 .
.
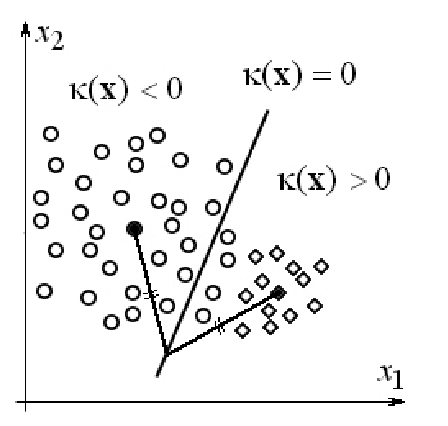
Рис. 1. Пример двух классов разных размеров, для которых критерий евклидового расстояния до эталонных образов не является корректным
Тогда для классификации нового образа x используется следующая решающая функция:
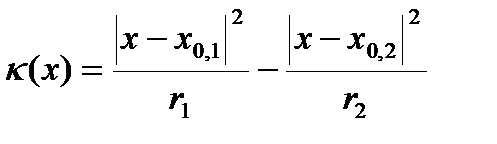 .
.
Если значение этой функции отрицательное, то образ относится к первому классу, в противном случае – ко второму. Разделяющая поверхность для двух классов задается уравнением κ (x)=0.
Метод ближайших соседей
Алгоритм ближайшего соседа (nearest neighbor, NN) относит классифицируемый объект u ∈ Xℓ к тому классу, которому принадлежит ближайший обучающий объект: w(i,u) = [i = 1]; a(u;Xℓ) = y(1)u.
Этот алгоритм является, по всей видимости, самым простым классификатором. Обучение NN сводится к запоминанию выборки Xℓ. Единственное достоинство этого алгоритма — простота реализации. Недостатков гораздо больше:
• Неустойчивость к погрешностям. Если среди обучающих объектов есть выброс — объект, находящийся в окружении объектов чужого класса, то не только он сам будет классифицирован неверно, но и те окружающие его объекты, для которых он окажется ближайшим.
• Отсутствие параметров, которые можно было бы настраивать по выборке. Алгоритм полностью зависит от того, насколько удачно выбрана метрика ρ.
• В результате — низкое качество классификации.
Некоторые метрики
Скалярное умножение векторов:

где p - размерность признакового пространства.
Абсолютное значение вектора (норма):
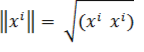
Направляющие косинусы:

Расстояние Танимото:

Содержание отчета
Отчет должен содержать:
1. Постановку задачи.
2. Таблицу 1 с обучающей и контрольной выборкой, графическое отображение выборок и эталонных значений.
3. Таблицу с результатами классификации реализованными алгоритмами (эталона и kNN) с использованием всех метрик обучающей и контрольной выборок и для различных k. Результаты классификации также отобразить графически.
4. Оценки обобщающей и распознающей способностей классификаторов.
5. Выводы. В выводах необходимо проанализировать, при использовании какой из метрик результаты классификации точнее и почему (как это связано с пространством информативных признаков), оценить компактность расположения точек на графике, оценить влияние компактности точек на работу методов.
6. Листинг программы.
Лабораторная робота №2
Тема: исследование классификатора на основе опорных векторов. Выбор ядра.
Цель: научиться использовать библиотеки для построения классификатора на основе опорных векторов, приобретение навыков анализа эффективности работы классификатора с использованием различных ядер.
Порядок выполнения работы
1. Скачать библиотеку LIBSVM со страницы http://www.csie.ntu. edu.tw/~cjlin/libsvm.
2. Разработать программу, реализующую SVM-классификацию с возможностью выбора ядра (одного из стандартных, предоставляемых библиотекой LIBSVM). Предусмотреть визуализацию обучающих данных и классификации по двум признакам.
3. Обучите SVM-классификатор, используя различные ядра и отобразите сгруппированные данные.
4. Протестировать и отладить работу программы на различных обучающих данных. Для чего необходимо выполнить следующее:
a. загрузите данные со страницы http://archive.ics.uci.edu/ml/datasets/Iris для классической задачи классификации ирисов Фишера (БД содержит 150 примеров с 5 признаками);
b. создайте двумерный массив, в котором в первом столбце хранятся измерения sepal length, во втором – sepal width для 150 ирисов;
c. Из вектора species, создайте новый вектор-столбец groups, чтобы классифицировать данные в две группы: Setosa и non-Setosa;
d. Наугад выберите обучающее и тестовое множества.
5. Оформить отчет по лабораторной работе.
Метод опорных векторов
Основы метода опорных векторов были заложены в начале 70-х годов прошлого века. Популярность же метода, которой он начал пользоваться в 1990-х годах после выхода ряда работ, вызвана открытием интересной возможности его расширения на случай нелинейных разделяющих границ (этот способ обобщения метода несколько отличен от тех, которые применялись для других линейных методов).
Смысл критерия качества, привлекающегося в методе опорных векторов, заключается в следующем. Пусть есть некоторая разделяющая гиперплоскость. Ее можно перемещать параллельным переносом (меняя параметр wN +1) в некоторых пределах так, что она все еще будет разделять классы. Совокупность таких параллельных гиперплоскостей образует полосу определенной ширины. В зависимости от ориентации, определяемой параметрами w 1, w 2,…, wN, ширина полосы будет различной.
К примеру, на рис. 1 представлены два класса, которые могут быть разделены различными линейными решающими функциями. При фиксированной ориентации разделяющие поверхности заметают полосу некоторой ширины. На рисунке представлены две такие полосы, обладающие разными ширинами: s 1 и s 2.

Рис. 1. Два линейно разделимых класса образов, для которых представлены две разделяющие полосы с разными ширинами
Линейные решающие функции составляют важное параметрическое семейство. Поиск линейных решающих функций проще как с теоретической, так и с практической точки зрения, а классификаторы, построенные на их основе, являются также и наиболее эффективными в смысле требуемых вычислительных ресурсов. Линейные решающие функции задаются следующим образом:
κ (x, w)= w 1 x 1+ w 2 x 2+…+ wN xN + wN + wN +1= w x ′
где x ′ =(x 1, x 2,…, xN,1) T – пополненный вектор признаков, а w =(w 1, w 2,…, wN +1) – вектор весов, который требуется определить по обучающей выборке, исходя из условий:
wx′i > 0, если x′i Î y 1,
wx′i < 0, если x′i Î y 2.
Разделяющая поверхность, задаваемая уравнением wx′i =0, в данном случае будет гиперплоскостью.
Чтобы представить эти условия единообразно, обычно пользуются следующим приемом. Пусть zi =1, если x′i Î y 1, и zi =−1, если x′i Î y 2, тогда ограничения на вектор параметров будут следующие:
(∀i) zi x′iw > 0. (1)
Полагается, что чем шире полоса, тем лучше соответствующая поверхность разделяет классы. С каждой полосой соприкасается, по крайней мере, по одному вектору из каждого класса. Эти векторы называются опорными (на рисунке представлены заполненными кружками и треугольниками). Опорные векторы могут меняться в зависимости от ориентации полосы.
Ширина полосы и является критерием качества, в соответствии с которым из множества возможных разделяющих поверхностей выбирается лучшая. Идея ширины полосы как критерия качества является наглядной и интуитивно привлекательной.
Среди всех гиперплоскостей, принадлежащих наиболее широкой полосе, выбирается та, расстояние до которой от опорных векторов одинаково (то есть расположенная посередине полосы). Заметим, что положение лучшей гиперплоскости определяется лишь опорными векторами; расположение других векторов обучающей выборки никак не учитывается. Эти условия позволяют определить лучшую гиперплоскость единственным образом (за исключением некоторых вырожденных случаев расположения векторов обучающей выборки).
Чтобы вычислить ширину полосы, прибегают к следующему приему. Если неравенства (1) справедливы, то всегда можно найти такую положительную константу, после умножения вектора w на которую будут верны следующие неравенства:
(∀ i) zix′iw ≥ 1, (2)
причем хотя бы для одного вектора xi равенство будет точным. Стоит отметить, что умножение всех компонентов вектора w на одно и то же число не меняет положения разделяющей гиперплоскости.
Гиперплоскость находится в центре соответствующей ей полосы, если расстояния от опорных векторов до нее равны. Расстояние от точки до плоскости вычисляется по формуле:
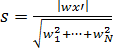 .
.
Наименьшее расстояние достигается на опорных векторах, для которых | wx′ |=1 (знак выражения wx′ будет разным для опорных векторов разных классов). Поскольку искомая плоскость отделена таким расстоянием от обоих классов, ширина соответствующей полосы составит:
 .
.
Вместо максимизации расстояния s0 удобнее минимизировать обратную величину при системе ограничений (2). Эта задача решается методом неопределенных множителей Лагранжа, для чего составляется лагранжиан:
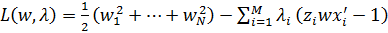 ,
,
который минимизируется при следующих ограничениях: λi ≥0, i =1,…, M и 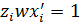 для каких-либо опорных векторов. Здесь λi – неопределенные множители Лагранжа.
для каких-либо опорных векторов. Здесь λi – неопределенные множители Лагранжа.
Условный экстремум лагранжиана ищется путем его дифференцирования по wi и λi и приравнивания всех производных нулю. Полное решение этой задачи не слишком сложное, но достаточно громоздкое, и оно может быть найдено в справочной литературе, поэтому здесь мы его разбирать не будем. Приведем лишь результат:
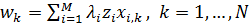 ,
,
а wN +1 просто получается из соотношения 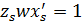 , записанного для произвольного опорного вектора. Следует также заметить, что множители λi отличны от нуля, только для опорных векторов. Сами же величины λi находятся путем минимизации квадратичной функции, получаемой путем подстановки полученных
, записанного для произвольного опорного вектора. Следует также заметить, что множители λi отличны от нуля, только для опорных векторов. Сами же величины λi находятся путем минимизации квадратичной функции, получаемой путем подстановки полученных 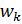 в лагранжиан, при указанных выше ограничениях на значения λi (задача поиска экстремума квадратичной функции при ограничениях на значения параметров относится к области квадратичного программирования).
в лагранжиан, при указанных выше ограничениях на значения λi (задача поиска экстремума квадратичной функции при ограничениях на значения параметров относится к области квадратичного программирования).
Интересной особенностью данного метода является то, что коэффициенты оптимизируемой функции зависят только от произведений 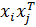 , а не от самих векторов. Более того, подставив найденные параметры wi в уравнение решающей функции κ (x, w), можно убедиться, что и для вычисления решающей функции достаточно знать только произведения , а не сами векторы. Это будет иметь значение при обсуждении обобщенных решающих функций, к рассмотрению которых мы и перейдем.
, а не от самих векторов. Более того, подставив найденные параметры wi в уравнение решающей функции κ (x, w), можно убедиться, что и для вычисления решающей функции достаточно знать только произведения , а не сами векторы. Это будет иметь значение при обсуждении обобщенных решающих функций, к рассмотрению которых мы и перейдем.
Библиотека LIBSVM
Скачать библиотеку LIBSVM можно со страницы http://www.csie.ntu. edu.tw/~cjlin/libsvm.
Она написана на языке C++, но имеется также версия на Java. В дистрибутив входит обертка svm.py для вызова из программ на Python. Чтобы ею воспользоваться, необходима версия LIBSVM, откомпилированная под вашу платформу. Для Windows в дистрибутиве имеется готовая DLL – svmc.dll. (Для версии Python 2.5 этот файл нужно переименовать в svmc.pyd, так как она не умеет импортировать библиотеки с расширением DLL.) В документации, поставляемой вместе с LIBSVM, описывается, как откомпилировать ее на других платформах.
Пример сеанса для Python
Поместите откомпилированную версию LIBSVM и пакет svm.py в свою рабочую папку или в папку, где интерпретатор Python ищет библиотеки. Теперь можно импортировать ее и использовать.
>>> from svm import *
Первым делом создадим простой набор данных. LIBSVM читает данные из кортежа, содержащего два списка. Первый список содержит классы, второй – исходные данные. Попробуем создать набор данных всего с двумя классами:
>>> prob = svm_problem([1,-1],[[1,0,1],[-1,0,-1]])
Еще нужно с помощью функции svm_parameter задать ядро, которым вы собираетесь пользоваться:
>>> param = svm_parameter(kernel_type = LINEAR, C = 10) Далее следует обучить модель: >>> m = svm_model(prob, param)
optimization finished, #iter = 1 nu = 0.025000
ob] = -0.250000, rho = 0.000000 nSV = 2, nBSV = 0 Total nSV = 2
И наконец воспользуемся ею для прогнозирования принадлежности классам:
>>> m.predict([1, 1, 1])
1.0
Это вся функциональность LIBSVM, которая вам нужна для создания модели по обучающим данным и последующей классификации.
У библиотеки LIBSVM есть еще одна полезная особенность – возможность сохранять и загружать обученные модели:
>>> m.save(test.model) >>> m=svm_model(test.model)
Содержание отчета
Отчет должен содержать:
1. Постановку задачи.
2. Графическое отображение выборки.
3. Таблицу с результатами классификации с использованием различных ядер. Результаты классификации отобразить графически.
4. Оценки обобщающей способности классификатора.
5. Выводы. В выводах необходимо проанализировать, при использовании какого из ядер результаты классификации точнее и почему (как это связано с пространством информативных признаков), оценить компактность расположения точек на графике, возможность их линейной разделимости, оценить влияние этой возможности на работу классификатора с различными ядрами.
6. Приложение к отчету.
В приложении к Отчету необходимо дать описание требований к комплектации ЭВМ и шагов, необходимых для установки и запуска программы, а также листинг программы.
Отчет должен быть подготовлен в печатном виде и содержать иллюстрации работы программы.
В электронном виде нужно представить:
1. Электронную версию отчета по лабораторной работе.
2. Результирующую программу (exe-файл), необходимые для ее работы рабочие материалы (базу данных наблюдений).
3. Файл READ ME (описание шагов, необходимых для установки и запуска программы на компьютере).
Работающая программа (exe-файл) должна запускаться на компьютере со стандартным программным обеспечением и не требовать специальных усилий для своей работы (установки на компьютере специального языка программирования, размещения компонентов программы на сервере, прописывания пути к БЗ в командных строках и т.д.).
Лабораторная робота №3
Тема: построение наивного байесовкого классификатора.
Цель: научиться строить модель наивного байесовского классификатора и осуществлять оценку ее параметров методом максимального правдоподобия. Построение классификатора по вероятностной модели, приобрести практические навыки использования наивного байесовского классификатора для задач классификации.
Порядок выполнения работы
1. Разработать программу, реализующую байесовскую классификацию.
2. Протестировать и отладить работу программы на различных обучающих данных. Для чего необходимо выполнить следующее:
a. зайти на страницу с массивами баз данных для отладки алгоритмов машинного обучения https://archive.ics.uci.edu/ml/machine-learning-databases/?C=N;O=D;
b. выбрать любую базу и ознакомиться с ее описательной частью для формирования классов и вектора признаков;
c. используя выбранную базу, сформировать обучающую и контрольную выборки.
3. Оформить отчет по лабораторной работе.
Содержание отчета
Отчет должен содержать:
1. Постановку задачи.
2. Оценки обобщающей способности классификатора.
3. Выводы.
4. Приложение к отчету.
В приложении к Отчету необходимо дать описание требований к комплектации ЭВМ и шагов, необходимых для установки и запуска программы, а также листинг программы.
Отчет должен быть подготовлен в печатном виде и содержать иллюстрации работы программы.
В электронном виде нужно представить:
1. Электронную версию отчета по лабораторной работе.
2. Результирующую программу (exe-файл), необходимые для ее работы рабочие материалы (базу данных наблюдений).
3. Файл READ ME (описание шагов, необходимых для установки и запуска программы на компьютере).
Работающая программа (exe-файл) должна запускаться на компьютере со стандартным программным обеспечением и не требовать специальных усилий для своей работы (установки на компьютере специального языка программирования, размещения компонентов программы на сервере, прописывания пути к БЗ в командных строках и т.д.).
Лабораторная робота №4
Тема: исследование алгоритмов обучения нейронных сетей.
Цель: приобрести практические навыки построения нейросетей различной архитектуры средствами пакета Neural Network Toolbox, оценить эффективность работы каждой из них.
Порядок выполнения работы
1. Установить MATLAB и пакет Neural Network Toolbox.
2. Выбрать для обучения нейросети любую базу данных из источника с массивами баз данных для отладки алгоритмов машинного обучения https://archive.ics.uci.edu/ml/machine-learning-databases/?C=N;O=D.
3. Разбить выборку на обучающую и контрольную.
4. Средствами Neural Network Toolbox построить сети: многослойные, RBF. При построении многослойных сетей исследовать их работу на различных функциях активации и числе нейронов скрытого слоя.
5. Сохранить результат обучения в файле формата mat для дальнейшего использования.
6. Проверить эффективность работы каждой из построенных сетей на контрольной выборке.
7. Оформить отчет по лабораторной работе.
Содержание отчета
Отчет должен содержать:
1. Описание данных для классификации.
2. Краткое описание действий по пунктам.
3. Графики по всем пунктам программы.
4. Таблицу с результатами классификации всех нейросетей.
5. Расчеты и выводы по работе.
6. Приложение к отчету – mat-файлы с результатами обучения нейросетей.
Лабораторная робота №5
Тема: прогнозирование временных рядов с помощью нейросетей.
Цель: изучение способа прогнозирования временных ряда с помощью нейросетей с помощью пакета Neural Network Toolbox.
Порядок выполнения работы
1. Установить MATLAB и пакет Neural Network Toolbox.
2. Выбрать для обучения нейросети любую базу данных из источника с массивами баз данных для отладки алгоритмов машинного обучения https://archive.ics.uci.edu/ml/machine-learning-databases/?C=N;O=D.
3. Разбить выборку на обучающую и контрольную.
4. Средствами Neural Network Toolbox построить сети: многослойные, RBF. При построении многослойных сетей исследовать их работу на различных функциях активации и числе нейронов скрытого слоя.
5. Сохранить результат обучения в файле формата mat для дальнейшего использования.
6. Проверить эффективность работы каждой из построенных сетей на контрольной выборке.
7. Оформить отчет по лабораторной работе.
Машинное обучение
Методические указания к выполнению лабораторных работ для студентов магистратуры, обучающихся по направлению подготовки 09.04.01 – «Информатика и вычислительная техника»
Донецк – 2016
Лабораторная робота №1
Тема: построение регрессионной модели с помощью метода ближайших соседей.
Цель: практическая реализация простейших метрических алгоритмов классификации, приобретение навыков анализа эффективности работы классификаторов.
Задача на лабораторную работу
В самолете за каждый лишний сантиметр, выходящий за габариты необходимо заплатить 3$, а за каждый лишний килограмм веса - 4$. Всего у пассажира – 30$. Функция классификации пассажиру неизвестна, поэтому он интуитивно пытается сформировать свой багаж и каждый раз проходит процедуру контроля. Пример обучающей выборки представлен в таблице 1. будет выглядеть примерно так (10 примеров):
Таблица 1. Обучающая выборка для задачи контроля багажа
| №
| ΔS
| Δm
| Класс [0,1]
|
|
|
|
| 1 – контроль пройден
|
|
|
|
| 0 – контроль не пройден
|
| …
| …
| …
| …
|
|
|
|
|
|
Порядок выполнения работы
1. Составить обучающую последовательность из 10 экспериментов и 10 «контрольных» значений (в виде таблицы 1).
2. Реализовать метод сравнения с эталоном различными метриками (направляющие косинусы, евклидово расстояние, расстояние Танимото). В качестве эталона использовать среднее значения признаков из обучающей выборки.
3. Реализовать алгоритм KNN - k ближайших соседей с различными метриками. Подобрать оптимальные параметры алгоритма k от 2 до 5, используя критерий скользящего контроля с исключением объектов по одному и одну из трех реализованных метрик.
4. Реализация алгоритмов должна предусматривать графические отображения обучающей и контрольной выборок, эталонов и результатов классификации.
5. Оценить распознающую способность (классификация образов из обучающей выборки) и обобщающую способность (классификацию «контрольных» образов) классификаторов. В качестве функции потерь использовать индикатор несовпадения с правильным ответом.
6. Оформить отчет по лабораторной работе.








