

Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Навигация:
Главная Случайная страница Обратная связь ТОП Интересно знать Избранные Новые материалы
Топ:
Установка замедленного коксования: Чем выше температура и ниже давление, тем место разрыва углеродной цепи всё больше смещается к её концу и значительно возрастает...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Процедура выполнения команд. Рабочий цикл процессора: Функционирование процессора в основном состоит из повторяющихся рабочих циклов, каждый из которых соответствует...
Интересное:
Влияние предпринимательской среды на эффективное функционирование предприятия: Предпринимательская среда – это совокупность внешних и внутренних факторов, оказывающих влияние на функционирование фирмы...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является...
Дисциплины:
|
из
5.00
|
Заказать работу |
Содержание книги
Поиск на нашем сайте
|
|
|
|
ФАЙЛЫ
Основные понятия, связанные с организацией файлов
Современные ЭВМ имеют в своём составе внешние запоминающие устройства, способные хранить огромные массивы информации в течение сколь угодно длительного времени. Наиболее удобным местом хранения является дисковая память, которой оснащены все персональные компьютеры (ПК). Дисковая память – это место хранения данных, не используемых в данный момент для алгоритмической обработки. На диске хранятся как программы, системные и пользовательские, так и данные различного назначения.
Любая информация, хранимая во внешней памяти ЭВМ, независимо от назначения этой информации, организуется как файл.
Файлы называют внешними структурами данных в отличие от всех остальных структур данных, хранимых в основной памяти только на время работы программы и называемых оперативными.
В общем смысле под файлом понимают любое внешнее устройство, способное хранить (или создавать) информацию в форме, воспринимаемой ЭВМ: клавиатура дисплея, экран дисплея, магнитная лента, перфолента, печатающее устройство, магнитные диски и т.п.
С точки зрения хранения информации на дисках файл – это поименованная область памяти на диске, в которой хранится логически однородная информация.
В дальнейшем изложении будем ориентироваться на дисковую память ПК.
СТРУКТУРА ФАЙЛА
Методы организации и обработки файлов как данных, располагаемых во внешней памяти, имеют ряд особенностей по сравнению со способами организации и обработки оперативных структур данных.
Напомним, что алгоритмическая обработка выполняется только над данными, размещёнными в основной памяти.
Поэтому данные, находящиеся во внешней памяти и подлежащие обработке, должны быть сначала перемещены в основную память. Как правило, это перемещение данных из внешней памяти в основную и в обратном направлении осуществляется небольшими порциями (файл не может полностью уместиться в основной памяти). Следовательно, файл должен быть определённым образом структурирован.
Наиболее всеобщей формой структурирования информации является последовательность. Последовательность имеет удобную и эффективную реализацию на всех запоминающих устройствах.
Файл представляет собой последовательность компонент одного типа.
В последовательности определяется некоторый естественный порядок компонент. В любой момент непосредственно доступна только одна компонента. Её можно либо «просматривать», либо «формировать»; одновременно делать то и другое невозможно. К остальным компонентам можно «прийти», лишь двигаясь шаг за шагом вдоль файла. Файл формируется путём последовательных добавлений в его конец новых компонент. Поэтому определение файлового типа не задаёт число компонент.
ПОНЯТИЕ МЕТОДА ДОСТУПА
Вся деятельность СУФ базируется на фундаментальном понятии метода доступа. Метод доступа – совокупность программного способа доступа к данным и метода организации данных.
В основе современных методов организации файлов лежит последовательный метод, принятый в системе Турбо Паскаль. На рис.3 показана схема последовательного файла с иллюстрацией соответствующей терминологии.
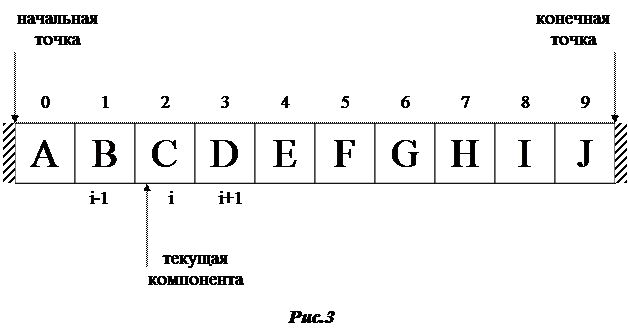 В дальнейшем будем рассматривать логический файл, т.к. на него ориентирована алгоритмическая обработка.
В дальнейшем будем рассматривать логический файл, т.к. на него ориентирована алгоритмическая обработка.
Объявление файловой переменной в программе связано с выделением в оперативной памяти специальной, скрытой от нас переменной, значение которой равно номеру логической компоненты файла, «видимой» операционной системе в данный момент времени обработки файла. Эта переменная называется указателем текущей компоненты. На рисунках указатель изображается стрелкой. СУФ автоматически нумерует все компоненты, начиная с нуля.
Компонента, номер которой хранит указатель, называется текущей. Если указатель показывает на компоненту i, то компонента с номером i-1 называется предыдущей, а с номером i+1 – последующей по отношению к текущей компоненте.
Последовательная организация файла предусматривает запись компонент в файл, начиная с нулевой компоненты; затем записывается первая, затем вторая и т.д. компоненты.
Последовательный доступ к файлу предусматривает обработку записей файла по правилу, соответствующему упорядочению: после обработки компоненты с номером i, автоматически становится доступной компонента с номером i+1. Обработка начинается с нулевой компоненты.
Магнитные диски позволяют организовать, наряду с последовательным, прямой доступ к любой логической компоненте. Всякий раз, когда необходимо обратиться к некоторой компоненте, программа сообщает конкретный номер этой компоненты (т.е. устанавливает указатель на соответствующую компоненту, независимо от того, какая компонента до этого была обработана). СУФ имеет специальные процедуры прямого доступа, к которым обращается программа.
Таким образом, Турбо Паскаль предусматривает последовательную организацию информации в файле с последовательным и прямым доступом к компоненте файла.
ОТКРЫТИЕ И ЗАКРЫТИЕ ФАЙЛА.
Устройство внешней памяти хранит большое количество файлов. Естественно, программа должна сообщить СУФ, с каким конкретным файлом (файлами) она будет работать. Для этого в СУФ предусмотрена процедура открытия файлов. Открытие файла предусматривает указание начальной метки файла и направление обмена информацией: если файл формируется, он открывается для записи; если файловая информация используется в алгоритме или файл модифицируется, он открывается для чтения. При открытии файла СУФ автоматически нумерует записи файла, создаёт указатель текущей записи, устанавливает его на нулевую компоненту, выделяет буфер.
Если обработка файла закончена, необходимо его закрыть. Закрыть файл – это, прежде всего, высвободить буфер. Если файл только что сформирован, при закрытии ставится метка номера файла. СУФ имеет специальную процедуру «закрыть файл». После закрытия файл «исчезает» из области видимости СУФ.
ФОРМИРОВАНИЕ ФАЙЛА
Формирование файла связано с алгоритмом создания логической компоненты файла и записью (перемещением) этой информации на диск.
Очевидно, что в программе должна быть объявлена некоторая переменная оперативной памяти, тип которой идентичен (совпадает) с типом файловой компоненты. В соответствии с постановкой задачи в программе определяется значение этой переменной. Для перемещения информации в файл используется знакомая нам операция
WRITE (<имя файл. перем.>, <имя логич. комп.>);
Напоминаем, что файл должен быть предварительно открыт для записи.
Например, если компоненты файла – целые числа, то объявим логическую компоненту как переменную целого типа:
Program LES(h);
Var
h: file of integer;
a: integer; { логическая компонента }
……………
begin {LES}
assign(h,’E:\CTL\hd.dat’);
rewrite(h);
a:=5;
write(h,a); {запись компоненты в файл}
……………
Так как все компоненты файла имеют одинаковый тип, очевидно, что формирование файла необходимо вести в цикле. Но логический файл не имеет конечной длины. Как правило, наиболее общим алгоритмом формирования файла является цикл-пока. Условием окончания цикла является задание некоторого значения-сигнала. Это значение не записывается в файл и никогда в файле не встречается. Оно задаётся константой того же типа, что и тип компоненты.
Структура алгоритма создания файла показана рис.4. S – некоторое сигнальное значение.

Например, необходимо записать в файл информацию о студентах по следующим спецификациям:
фамилия, номер зачётной книжки, номер группы. Студенты не «рассортированы» по группам. Соответствующая программа приведена на рис.5.
Program STD(h);
TYPE SR=RECORD { структура }
name : string[30]; { логической }
numbz : integer; { компоненты }
numbG : integer
end;
VAR h: file of SR;
a: SR; { логич. компонента }
begin
assign(h,’E:TL\h1.dat’);
rewrite(h);
writeln(‘введите номер группы очередного студента’);
writeln(‘0 – признак окончания ввода’);
{4} readln(a.numbG);
{формирование файла в цикле - пока управляющее поле a. numbG не получит значение 0}
while a.numbG<>0 do
begin
writeln(‘Фамилия?’);
{1} readln(a.name);
writeln(‘Номер зачётки?’);
{2} readln(a.nambz);
{3} writeln(h,a); {запись комп. в файл}
writeln(‘введите номер группы очередного студента’);
{4} readln(a.numbG);
end; {while}
writeln(‘Запись файла окончена’);
close(h)
{5} end.
Рис.5
В этой программе роль сигнальной переменной играет константа целого типа нуль, записанная в условие проверки при входе в цикл while. Такое значение выбрано из соображения, что, как правило, не бывает номера группы нуль.
В строках 1, 2, 4 набираются значения полей структурированной логической компоненты a. Тип её объявлен одинаковым с типом компоненты файла h. Как только значение номера группы введётся нулевым, цикл формирования файла заканчивается. Процедура закрытия файла в конце формирования создаёт метку конца файла на диске.
ЧТЕНИЕ И МОДИФИКАЦИЯ ФАЙЛА
Файл читается, прежде всего, для проверки созданной информации, а также для алгоритмической обработки в соответствии с условием задачи. Чтение возможно только для сформированного файла!
После чтения последней компоненты указатель текущей записи переместится на метку конца файла. Попытка читать файл в таком состоянии приведёт к аварии в программе. Для слежения за ситуацией «наступил конец файла» СУФ имеет логическую функцию
EOF(<имя файлов. перем.>).
Значение этой функции есть FALSE, если указатель стоит на любой существующей компоненте файла, и TRUE, если указатель переместился на метку конца файла.
Чтение очередной компоненты файла выполняется с помощью обращения к процедуре
READ (<имя файл. перем.>,<имя логич. комп.>)
Второй параметр процедуры чтения имеет тот же смысл, что и п.2.3.
Наиболее общий алгоритм чтения и обработки информации из файла изображён на рис.6. Это алгоритм последовательного доступа.

Шаг «обработать компоненту» может быть алгоритмически простым (например, печать компоненты), а может представляться сложным алгоритмом в соответствии с условием задачи.
В качестве примера продолжим программу на рис.5 фрагментом программы распечатки созданного файла. Для этого строку {5} отодвинем в конец модифицированной программы. Продолжение программы приведено на рис.7.
……………
close(h); {файл после формирования был закрыт}
reset(h); {открыть файл для чтения}
while not EOF(h) do
begin
read(h,a); {читать с диска в оперативную память}
write(a.numbG:5,a.name:30, a.numbz:4);
writeln
end;
close(h)
end.
Рис.7
Примеры решения задач на обработку файлов
Пример 1.
Создать файл, состоящий из последовательности чисел целого типа. Вычислить среднее арифметическое квадратов нечётных компонент файла. Исходный файл распечатать.
Тестовый пример:
Созданный файл:

S:=32+52+72+12=84; S – сумма квадратов нечётных компонент в файле f.
K=4; K – количество нечётных компонент в файле f.
 ; SR – среднее арифметическое нечётных компонент.
; SR – среднее арифметическое нечётных компонент.
Блок-схема алгоритма приведена на рис.8.

Шаги основного проекта алгоритма пояснены в предыдущих параграфах и не требуют детализации в виде блок-схемы.
Программа на языке Турбо Паскаль приведена на рис.9.
Program Pr1(f);
{Формирование файла из целых чисел и вычисление ср. арифметического нечётных компонент}
TYPE FAL=file of integer;
VAR f: FAL; {имя файловой переменной}
K: integer; {счётчик нечётных компонент}
S, a: integer; { S – сумма квадратов нечётных компонент,
а – компонента логического файла}
SR: real; { SR - среднее арифметическое нечётных компонент файла}
name: string[20]; { метка файла }
Begin
writeln(‘Введите имя файла: ‘);
readln(name);
ASSIGN(f,name);
{ писать в файл }
REWRITE(f);
writeln(‘Признак конца ввода – 999’);
writeln(‘Вводите очередное целое число’);
read(a);
while a<>999 do
begin
write(f,a);
Writeln(‘Вводите очередное целое число’);
read(a);
end;
CLOSE(f); { Файл сформирован }
writeln(‘Сформирован файл’);
{ Просмотр созданного файла }
RESET(f);
while not EOF(f) do
begin
read(f,a);
write(‘ ‘,a);
end;
CLOSE(f); { Просмотр завершён }
{Вычислено ср. ар. нечётных компонент файла f }
RESET(f); {Открыть файл для обработки}
S:=0;
K:=0;
while not EOF(f) do
begin
read(f,a);
if (a mod 2)<>0 then
begin
S:=S+SQR(a);
K:=K+1;
end;
end;
CLOSE(f);
SR:=S/K;
writeln(‘ср. ар. = ’,SR:6:2)
end. {Pr1}
Рис.9
Пример 2.
 Даны символьные файлы f1 и f2. Переписать с сохранением порядка следования компоненты файла f1 в файл f2, а компоненты файла f2 - в файл f1. Вспомогательный файл не использовать. Блок-схема основного проекта приведена на рис.10.
Даны символьные файлы f1 и f2. Переписать с сохранением порядка следования компоненты файла f1 в файл f2, а компоненты файла f2 - в файл f1. Вспомогательный файл не использовать. Блок-схема основного проекта приведена на рис.10.
Программа алгоритма обмена содержимым символьных файлов f1 и f2 приведена на рис.11.
Program Pr2(f1,f2);
{Программа создаёт два символьных файла и выполняет обмен их содержимым}
Var
n1,n2: integer; {соответственно кол-во компонент в файле f 1 и
в файле f2}
f1,f2: file of char;
a,b: char {компоненты логического файла}
Begin
ASSIGN(f1,’e:\Cat\d1.dat’);
ASSIGN(f2,’e:\Cat\d2.dat’);
Rewrite(f1); {файл f 1 открыт для записи}
write(‘Пиши в файл f1 символы’);
writeln(‘Признак конца ввода - *’);
readln; {очистить буфер перед вводом первого символа}
read(a);
while a<>’*’ do
begin
write(f1,a);
read(a);
end;
CLOSE(f1);
Rewrite(f2); {файл f 2 открыт для записи}
write(‘Пиши в файл f2 цепочку символов’);
writeln(‘Признак конца ввода - *’);
readln;
read(a);
while a<>’*’ do
begin
write(f2,a);
read(a);
end;
CLOSE(f2);
writeln(‘Файлы: f1, f2 созданы’);
{обмен компонентами, пока файлы f1 и f2 не кончились}
Reset(f1);
Reset(f2);
while(not eof(f1)) and (not eof(f2)) do
Begin
read(f1,a);
read(f2,b);
{после чтения компоненты указатель переместился за
компоненту }
seek(f1,filepos(f1)-1);
seek(f2,filepos(f2)-1);
{Перед обменом компонентами файлов f1 и f2 указатель необходимо вернуть назад на одну компоненту, иначе компоненты будут записаны на место последующих компонент}
write(f1,b);
write(f2,a);
end;
n1:=filesize(f1);
n2:=filesize(f2);
{Дописать остаток более длинного файла}
if n1>n2 then
{ файл f1 длиннее файла f2}
begin
while not eof(f1) do
begin
read(f1,a);
write(f2,a);
end;
{усечение «хвоста» более длинного файла f 1}
seek(f1,n2); truncate(f1);
end
else
{файл f 2 длиннее файла f 1}
begin
while not eof(f2) do
begin
read(f2,a);
write(f1,a);
end;
{усечение «хвоста» более длинного файла f 2}
seek(f2,n1);
truncate(f2);
end;
{ распечатать файл f1}
writeln(‘Файл f1 после обмена’);
seek(f1,0);
while not eof(f1) do
begin
read(f1,a);
write(a);
end;
writeln(‘Файл f2 после обмена’);
seek(f2,0);
while not eof(f1) do
begin
read(f2,a);
write(a);
end;
Close(f1);
Close(f2);
end. {Pr2}
Рис.11
Пример 3.
В заданной целой матрице A(m,n) строки, не содержащие ни одного нуля, переписать последовательно в файл f. Если файл не сформирован, сделать сообщение. Начальная строка при обработке матрицы – первая.
Тестовый пример:


В тестовой матрице вторая строка должна быть переписана в файл f. Очевидно, файл не будет сформирован, если в каждой строке матрицы встретится хотя бы один нуль.
Блок-схема основного проекта приведена на рис.12.
 |
На рис.13 показана последовательная обработка строк:
kF – переменная-флажок, сигнализирующая, что хотя бы одна строка в файл будет записана (kF=1);
i – номер обрабатываемой очередной строки;
j – текущий номер элемента в строке;
ki – переменная-флажок: ki=0, если нет ни одного нулевого элемента в строке; ki=1, если есть хотя бы один нуль в строке.
N – количество столбцов матрицы, M – количество строк матрицы.

Остальные шаги на рис.12 не требуют детализации. Программа алгоритма задачи приведена на рис.14.
Program PR3(f);
{формирование файла из элементов строк матрицы A (M, N), не содержащих нулевых элементов}
Const M1=50;
N1=70;
Var
A: array [1..M1,1..N1] of integer;
f: file of integer;
h: integer; {логическая компонента файла}
kF,ki,i,j,M,N: integer;
Begin
ASSIGN(f,’E:\ARTM\fil.dat’);
{ формируем матрицу }
writeln(‘Введите M – кол. строк матр., N – кол. столбцов’);
write(‘M=’); readln(M);
write(‘N=’); readln(N);
writeln(‘Введите матрицу строками’);
for i:=1 to M do
for j=1 to N do
read(A[i,j]);
{ открываем файл для записи }
rewrite(f);
{выполняем просмотр строк матрицы: строки,
не содержащие нулей, записываем в файл f }
kF:=0; {флаг формирования файла}
for i:=1 to M do
begin(i)
ki:=0; {флаг наличия нуля в строке}
j:=1;
{ начало просмотра очередной строки }
REPEAT
IF A[i,j]=0 then
begin
ki:=1; {в строке есть нуль}
j:=n {необходимо закончить просмотр строки}
end;
j:=j+1
until j>n; {конец просмотра очередной строки}
{есть нуль в строке i?}
IF ki=0 then
{в строке нет нуля, пишем её в файл}
begin
kF:=1; { файл сформирован }
for j:=1 to N do
begin
b:=A[i,j];
write(f,b)
end;
end; {i} close(f);
{ файл сформирован?}
IF kF=1 then
{ файл сформирован, распечатать его }
begin
reset (f); {открываем файл для чтения}
while not EOF (f) do
begin
read(f,b);
write(‘ ‘, b)
end;
close (f)
end
else
writeln(‘файл не сформирован’);
end. { Pr 3}
Рис.14
ФАЙЛЫ
Основные понятия, связанные с организацией файлов
Современные ЭВМ имеют в своём составе внешние запоминающие устройства, способные хранить огромные массивы информации в течение сколь угодно длительного времени. Наиболее удобным местом хранения является дисковая память, которой оснащены все персональные компьютеры (ПК). Дисковая память – это место хранения данных, не используемых в данный момент для алгоритмической обработки. На диске хранятся как программы, системные и пользовательские, так и данные различного назначения.
Любая информация, хранимая во внешней памяти ЭВМ, независимо от назначения этой информации, организуется как файл.
Файлы называют внешними структурами данных в отличие от всех остальных структур данных, хранимых в основной памяти только на время работы программы и называемых оперативными.
В общем смысле под файлом понимают любое внешнее устройство, способное хранить (или создавать) информацию в форме, воспринимаемой ЭВМ: клавиатура дисплея, экран дисплея, магнитная лента, перфолента, печатающее устройство, магнитные диски и т.п.
С точки зрения хранения информации на дисках файл – это поименованная область памяти на диске, в которой хранится логически однородная информация.
В дальнейшем изложении будем ориентироваться на дисковую память ПК.
СТРУКТУРА ФАЙЛА
Методы организации и обработки файлов как данных, располагаемых во внешней памяти, имеют ряд особенностей по сравнению со способами организации и обработки оперативных структур данных.
Напомним, что алгоритмическая обработка выполняется только над данными, размещёнными в основной памяти.
Поэтому данные, находящиеся во внешней памяти и подлежащие обработке, должны быть сначала перемещены в основную память. Как правило, это перемещение данных из внешней памяти в основную и в обратном направлении осуществляется небольшими порциями (файл не может полностью уместиться в основной памяти). Следовательно, файл должен быть определённым образом структурирован.
Наиболее всеобщей формой структурирования информации является последовательность. Последовательность имеет удобную и эффективную реализацию на всех запоминающих устройствах.
Файл представляет собой последовательность компонент одного типа.
В последовательности определяется некоторый естественный порядок компонент. В любой момент непосредственно доступна только одна компонента. Её можно либо «просматривать», либо «формировать»; одновременно делать то и другое невозможно. К остальным компонентам можно «прийти», лишь двигаясь шаг за шагом вдоль файла. Файл формируется путём последовательных добавлений в его конец новых компонент. Поэтому определение файлового типа не задаёт число компонент.
ФИЗИЧЕСКИЙ И ЛОГИЧЕСКИЙ ФАЙЛЫ
Особенности устройств внешней памяти, на которых хранится файл, и основной памяти, где файл создаётся, а затем обрабатывается, заставляют рассматривать файл с двух позиций: как логическую, т.е. абстрактную (программную) структуру данных, и как реальную, физическую структуру данных, размещённую на конкретном носителе. В соответствии с указанными точками зрения существуют понятия «логический файл» и «физический файл».
Переменную, объявленную в программе как файл с определённой структурой компонент, соответствующей структуре любого оперативного типа данных (примитивы, массивы, записи и т.п.), называют логическим файлом. Логическая организация файла определяется пользователем на основе требований задачи.
Поименованные данные, хранимые на устройстве внешней памяти в виде последовательности физических групп информации (блоков информации), участвующих в операциях пересылки между основной и внешней памятью, называют физическим файлом.
Соответствие между физическим и логическим файлами реализуется системными программами, составляющими систему управления файлами (СУФ). Всякое действие, определяемое программой пользователя (алгоритмом), интерпретируется СУФ некоторой совокупностью действий на физическом уровне.
На рис.1 показано соответствие между физическим и логическим файлами.4

Представление физического файла тесно связано с характеристиками конкретного устройства внешней памяти. На магнитном диске физический файл представляет собой цепочку бит, рассоложенных по концентрическим дорожкам (трекам) на магнитной поверхности. Места расположения треков получаются при специальной подготовке диска (форматировании). Цепочки бит разделяются на подцепочки, называемые физическими записями (физическими компонентами), или блоками. Каждый блок физического файла содержит определённое число компонент логического файла. Это число называется коэффициентом блокирования и устанавливается СУФ либо по умолчанию (стандартно), либо по указанию пользователя.
На рис.1а физические записи разделены свободными от информации промежутками (заштрихованные промежутки), величина которых зависит от точности работы аппаратуры управления процессом считывания и записи информации. Заштрихованные области в начале и конце схемы физического файла называются метками файла. По начальной метке файл отыскивается среди множества всех файлов на диске. Конечная метка позволяет СУФ определять последний блок в данном файле.
Из рис. 1а, 1б видим, что коэффициент блокирования для рассматриваемого файла равен двум. На рис.1в показан один из возможных вариантов структуры компоненты логического файла. Например, если рассматривается файл с информацией о книгах, хранимых в некоторой библиотеке, структура компоненты соответствующего логического файла может быть, например, такой:
название (строка символов);
автор (строка символов);
издатель (строка символов);
год (целое число);
стоимость (вещественное число).
В любом случае методы логической организации файлов (представление данных, реализация функций доступа) являются прямым применением оперативных структур данных: примитивов, массивов, записей RECORD, списков и т.п.
|
|
|

Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим...

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...

Архитектура электронного правительства: Единая архитектура – это методологический подход при создании системы управления государства, который строится...
© cyberpedia.su 2017-2025 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!

