Задачи работы
Задачами данной лабораторной работы являются:
1. Закрепление полученных знаний о контейнерах.
2. Развитие навыков программирования на языке C++.
3. Развитие навыков программной реализации концепций алгоритмов и программных объектов.
Задание на лабораторную работу
Разработать класс контейнера и демонстрационную программу, иллюстрирующую его использование:
1. Реализовать класс списка с операциями добавления элемента, удаления элемента, доступа к первому элементу, доступа к следующему за данным [5, разд. 10.2].
2. Реализовать класс бинарного дерева с операциями поиска, добавления и удаления элемента [5, гл. 12].
3. Реализовать класс ассоциативного массива. [5, гл. 12]
4. Разработать класс АВЛ-дерева [5, гл.13] (задача 13-3).
5. Разработать класс красно-черного дерева [5, гл. 13].
6. Реализовать класс массива элементов, значение которых может быть 0 или 1, с выделением 1 бита на каждый элемент (т.е. если мы храним 32 элемента – внутри должна лежать одна переменная типа int).
7. Реализовать класс стека [5, разд. 10.1].
8. Реализовать класс очереди [5, разд. 10.1].
9. Реализовать класс очереди с приоритетами на базе пирамиды [5, разд. 6.5].
Достаточна разработка консольного приложения. Разработка Windows-приложения будет большим преимуществом выполнения работы, если студент достаточно подготовлен для создания Windows-приложений, иллюстрирующих работу системы.
Требования к отчетности по лабораторной работе
В качестве отчета по лабораторной работе студент предоставляет в электронном виде программу на C++, содержащую реализацию класса и пример его использования.
Предлагаемые этапы выполнения работы
1. Изучение рассматриваемого контейнера.
2. Проектирование класса контейнера – определение его public методов.
3. Реализация демонстрационной программы, иллюстрирующей работу класса. Предпочтительно выполнять ее до реализации самого класса, чтобы использовать ее для тестирования возможностей класса и убедиться в удобстве интерфейса класса до его реализации.
4. Реализация класса-контейнера.
5. Отладка программы.
Теоретический материал, необходимый для выполнения лабораторной работы
Основные типы контейнеров
Списки
Для того, чтобы устранить проблемы работы с массивами (долгая вставка элемента в середину, потребность в большом непрерывном блоке памяти), необходимо снять требование непрерывного размещения данных в памяти. Для этого элементы контейнера должны хранить информацию о расположении других элементов. Простейший пример такого контейнера – список [5, разд. 10.2].
Список может быть однонаправленным (в этом случае хранится адрес первого элемента, а каждый элемент помнит адрес следующего) и двунаправленным (хранятся адреса первого и последнего элементов, каждый элемент помнит адрес следующего и предыдущего).
Преимуществом списка является быстрая вставка элемента и быстрое его удаление. Действительно, и вставка, и удаление могут быть выполнены за время O(1). Эти операции затрагивают только добавляемый/удаляемый элемент и его непосредственных соседей, которым нужно обновить свои указатели на предыдущий/следующий элемент. Код на C++ для добавления элемента может иметь вид:
class TListItem
{
TListItem* Next;
Type Value;
};
void Include(TListItem* ptr_before, T val)
{
TListItem* ptr_new = new TListItem;
ptr_new->val = val;
ptr_new->next = ptr_before->next;
ptr_before->next = ptr_new;
}
В функции Include мы получаем указатель на элемент списка, после которого должен быть добавлен новый элемент, и значение, которое должно храниться в новом элементе. Мы создаем этот новый элемент с помощью new и сохраняем в нем требуемое значение. Следующим за ним элементом будет тот, который раньше был следующим за элементом ptr_before. Следующим за элементом, на который указывает ptr_before, будет новый элемент.
Работа функции Include иллюстрируется на рис. 5.

Рис. 5. Добавление элемента в список.
Аналогично может быть реализовано и удаление.
void Delete(TListItem* ptr_before)
{
TListItem* ptr_for_delete = ptr_before->next;
ptr_before->next = ptr_for_delete->next;
delete ptr_for_delete;
}
В функцию Delete передается указатель на элемент, следующий за которым необходимо удалить. Прежде всего мы определяем подлежащий удалению элемент (ptr_for_delete). Следующим за ptr_before теперь будет тот элемент, который следовал за ptr_for_delete. После того, как элемент таким образом исключен из списка, остается только освободить память.
Работа функции Delete иллюстрируется на рис. 6.

Рис. 6. Удаление элемента из списка
Бинарные деревья поиска
Бинарным деревом поиска [5, гл. 12] называется бинарное дерево [5, пр. B] со следующими свойствами:
1. С каждым узлом ассоциировано значение, тип данных которого допускает применение операции <.
2. Левый потомок каждого узла и все поддерево, корнем которого он является (левое поддерево), содержит меньшие значения, чем значение данного узла.
3. Правый потомок каждого узла и все поддерево, корнем которого он является (правое поддерево), содержит большие значения, чем значение данного узла.
Примеры бинарного дерева поиска приведены на рис. 7.
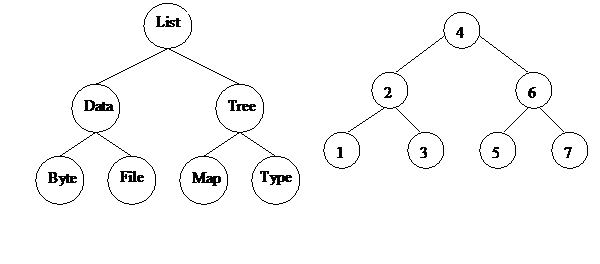
Рис. 7. Примеры бинарного дерева поиска.
Бинарное дерево поиска может рассматриваться как контейнер. В нем можно определить операции добавления, удаления и поиска элементов. Как правило, операции добавления, удаления и поиска определяются следующим образом:
Поиск
Работа поиска иллюстрируется на рис. 8.
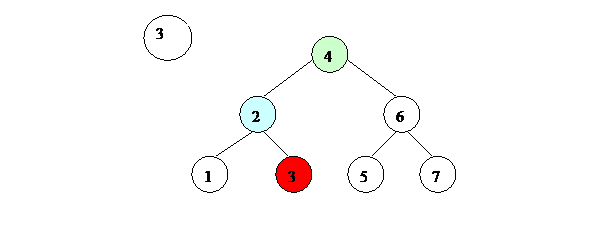
Рис. 8. Поиск в бинарном дереве поиска.
1. При поиске элемента мы сравниваем значение, которое ищем, со значением корня. Если оно совпало – мы нашли элемент.
2. Если значение, которое мы ищем, меньше – следует искать в левом поддереве.
3. Если значение, которое мы ищем, больше – следует искать в правом поддереве.
4. Далее продолжаем действовать по тому же алгоритму, пока не найдем элемент или пока поддерево, в котором следует искать, не окажется пустым (в этом случае мы можем сказать, что такого элемента в дереве нет).
Время поиска пропорционально высоте дерева.
Добавление элемента
1. Добавление элемента реализуется аналогично поиску. Поскольку такого элемента еще нет (считаем, что в бинарном дереве поиска не может быть двух элементов с одинаковыми значениями), то в итоге поиска мы найдем пустое поддерево, где этот элемент должен быть.
2. На месте этого пустого поддерева размещаем элемент.

Рис. 9. Добавление элемента в бинарное дерево поиска.
Время добавления пропорционально высоте дерева.
Удаление элемента
1. Если удаляемый элемент не имеет потомков, мы можем просто удалить его. См. рис. 10.
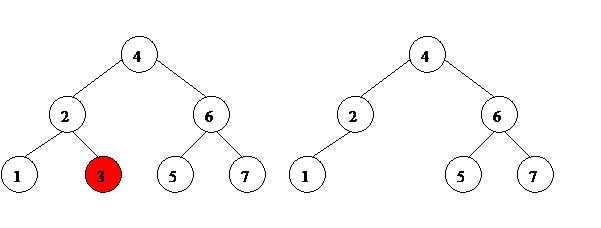
Рис. 10. Удаление элемента из бинарного дерева поиска.
2. Если удаляемый элемент имеет одного потомка – поднимаем этого потомка на имя удаляемого элемента. См. рис. 11.
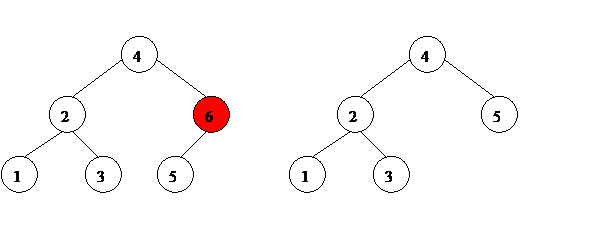
Рис. 11. Удаление элемента из бинарного дерева поиска.
3. Если удаляемый элемент имеет двух потомков, нам нужно найти в правом поддереве минимальный элемент. Найти в поддереве минимальный элемент просто.
a. Если корень не имеет левого потомка – он и есть минимальный.
b. Иначе минимальный элемент следует искать в левом поддереве. Вернемся к пункту a, но высота нашего дерева стала на единицу меньше.
c. Таким образом, мы найдем минимальный элемент в поддереве за время, пропорциональное высоте поддерева.
d. На рис. 12-14 минимальные элементы поддерева выделены голубым цветом.
Найдя минимальный элемент правого поддерева, мы ставим его на место удаляемого элемента. Левого потомка у этого элемента по определению нет (если бы был, был бы еще меньше, и данный элемент не был бы минимальным элементом поддерева). Если нет и правого потомка – элемент можно просто удалить. Если правый потомок есть – ставим этого правого потомка на его место.
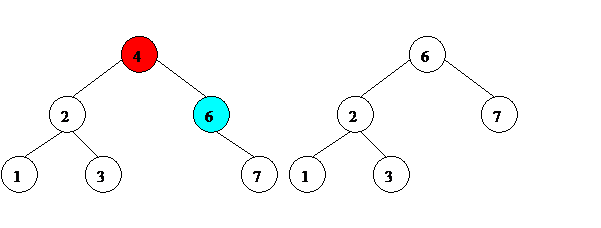
Рис. 12. Удаление элемента из бинарного дерева поиска.
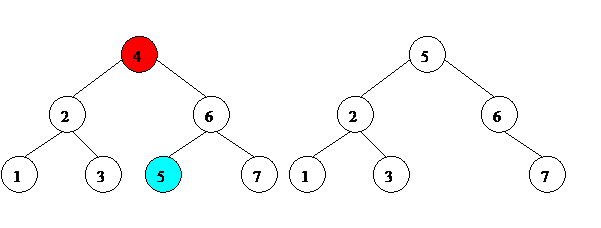
Рис. 13. Удаление элемента из бинарного дерева поиска.
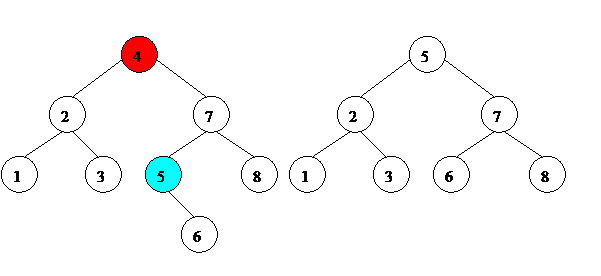
Рис. 14. Удаление элемента из бинарного дерева поиска.






