В основе законов распределения случайных величин, событий, основных теорем теории вероятностей лежит эксперимент, т.е. каждое исследование случайных явлений, выполняемое методами теории вероятностей, прямо или косвенно опирается на экспериментальные данные. Поэтому математическая статистика занимается разработкой методов сбора, описания и анализа экспериментальных данных, получаемых в результате наблюдений массовых случайных явлений. При этом можно выделить три этапа, присутствующие в любом приложении статистических методов:
1) сбор данных;
2) обработка данных;
3) статистические выводы - прогнозы и решения.
Выборочные статистики
Статистические распределения. Исходным материалом математического исследования является статистическая совокупность, которая образует выборку. Если X - изучаемая случайная величина, то возможное множество значений случайной величины 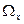 составляют генеральную совокупность, а наблюдаемые значения случайной величины
составляют генеральную совокупность, а наблюдаемые значения случайной величины 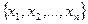 – выборку.
– выборку.
Распределение выборки, задаваемое интервальным статистическим рядом (табл. 1.1) или таблицей относительных частот (табл. 1.2), называется эмпирическим распределением случайной величины X.
Таблица 1.1
Интервалы наблюденных значений непрерывной случайной величины 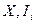
|
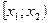
|
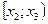
|
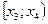
|
…
|
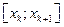
|
Относительные частоты
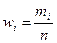
|

|
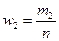
|
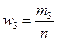
|
…
|
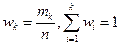
|
Интервальный статистический ряд распределения представленный графически, называется гистограммой (рис. 1.1):
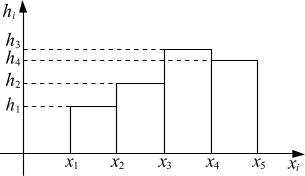
Рис. 1.1
Площадь каждого прямоугольника равна соответствующей относительной частоте. А площадь всей гистограммы равна единице.
Таблица 1.2
| Наблюденные значения дискретной случайной величины, xi
|
x1
|
x2
|
x3
|
…
|
xk
|
| Относительные частоты,
|
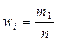
|
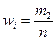
|
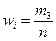
|
…
|
|
|
|
Ломаная линия с вершинами в точках 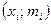 или точках
или точках 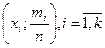 , называется частотным многоугольником (полигоном частот) или полигоном относительных частот (рис.1.2):
, называется частотным многоугольником (полигоном частот) или полигоном относительных частот (рис.1.2):
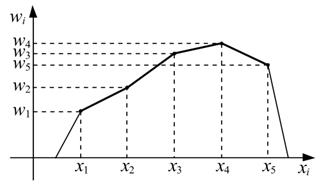
Рис 1.2
Эмпирической функцией распределения называется относительная частота события {X< 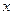 } в данной выборке значений случайной величины X, т.е.
} в данной выборке значений случайной величины X, т.е.
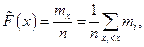
где mx – число значений xi, меньших x, n – объем выборки. Значения эмпирической функции распределения принадлежат отрезку 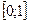 , т.е.
, т.е. 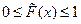 .
.
Эмпирическая функция распределения удовлетворяет следующим свойствам:
1. 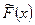 – неубывающая функция;
– неубывающая функция;
2. – кусочно-постоянная непрерывная слева функция;
3. Если x < x1 то 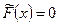 и если x > xk, то
и если x > xk, то 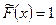 .
.
Эмпирическая функция распределения сходится по вероятности к функции распределения 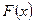 генеральной совокупности, т.е.
генеральной совокупности, т.е. 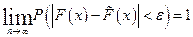 , где
, где 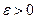 .
.
Основные числовые характеристики эмпирического распределения. Среднее арифметическое:
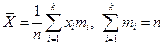 (1.1)
(1.1)
Медиана:
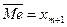 , или
, или 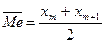 где
где 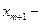 средняя варианта, если число вариант нечетно;
средняя варианта, если число вариант нечетно; 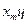 средние варианты, если число вариант четно, или
средние варианты, если число вариант четно, или 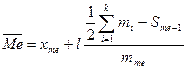 ,
,  , (1.2)
, (1.2)
где  – нижняя граница интервала, в котором лежит медиана; l – длина интервала;
– нижняя граница интервала, в котором лежит медиана; l – длина интервала; 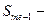 сумма частот во всех интервалах, предшествующих медианному;
сумма частот во всех интервалах, предшествующих медианному;  - частота медианного интервала.
- частота медианного интервала.
Мода:
 , где варианта xk имеет наибольшую частоту;
, где варианта xk имеет наибольшую частоту;
или 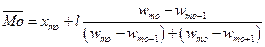 , (1.3)
, (1.3)
где 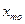 - нижняя граница интервала, в котором лежит мода; l –длина интервала;
- нижняя граница интервала, в котором лежит мода; l –длина интервала; 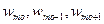 - относительные частоты, соответствующие модальному, предшествующему и последующему интервалам.
- относительные частоты, соответствующие модальному, предшествующему и последующему интервалам.
Статистическая дисперсия:
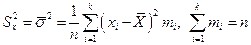 ; (1.4)
; (1.4)
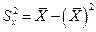 ;
;
Среднее статистическое квадратическое отклонение (стандартная ошибка):
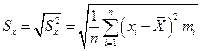 ;
; 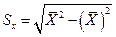 . (1.5)
. (1.5)
Вариационный размах: 
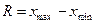 . (1.6)
. (1.6)
Среднее абсолютное (линейное) отклонение:
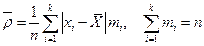 . (1.7)
. (1.7)
Коэффициенты вариации:
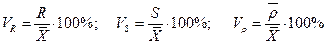 . (1.8)
. (1.8)
Начальный момент k -го порядка:
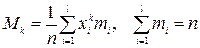 . (1.9)
. (1.9)
Центральный момент k -го порядка:
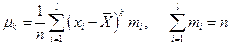 . (1,10)
. (1,10)
Асимметрия:
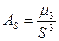 . (1.11)
. (1.11)
Эксцесс:
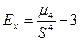 . (1.12)
. (1.12)
Задачи
1.1. Для статистической совокупности данных, характеризующих затраты на 1 денежную единицу продукции (работ, услуг) за год по 100 предприятиям г. Минска:
| 61,55
| 61,59
| 62,09
| 63,08
| 63,97
| 64,74
| 65,07
|
| 67,12
| 68,10
| 69,38
| 70,21
| 70,21
| 70,36
| 71,25
|
| 71,86
| 72,00
| 72,39
| 72,41
| 72,46
| 72,50
| 72,80
|
| 72,84
| 73,44
| 74,93
| 75,46
| 75,65
| 77,13
| 77,37
|
| 77,64
| 77,86
| 90,93
| 78,03
| 78,28
| 78,74
| 78,97
|
| 79,07
| 79,10
| 79,34
| 79,34
| 19,39
| 79,40
| 79,49
|
| 79,70
| 80,02
| 80,26
| 80,56
| 80,65
| 80,69
| 81,13
|
| 81,32
| 81,40
| 81,54
| 81,85
| 82,27
| 82,71
| 82,74
|
| 82,78
| 83,03
| 83,05
| 83,59
| 83,68
| 83,74
| 83,78
|
| 83,96
| 84,98
| 85,18
| 85,32
| 85,64
| 85,71
| 85,64
|
| 86,01
| 86,03
| 86,11
| 86,11
| 86,48
| 86,94
| 86,98
|
| 87,38
| 87,47
| 87,59
| 87,89
| 88,03
| 88,04
| 88,11
|
| 88,24
| 88,89
| 90,34
| 90,40
| 90,58
| 90,73
| 90,76
|
| 92,51
| 92,72
| 92,94
| 94,58
| 95,06
| 95,73
| 96,11
|
| 96,34
| 96,55
|
|
|
|
|
|
построить эмпирическое распределение, эмпирическую функцию распределения. Вычислить числовые характеристики.
Решение. Составим ряд распределения, характеризующий затраты в денежных единицах на 1 ден. ед. продукции (работ, услуг) по 100 предприятиям.
Каждое индивидуальное измерение затрат представлено отдельно, поэтому эти данные называют несгруппированными дискретными данными. Следовательно, исследуемая случайная величина X является дискретной случайной величиной. Дискретные данные также могут быть подвергнуты группировке. В результате группировки данных облегчается их интерпретация, хотя при этом частично теряется точность.
Определим длину интервала по формуле:
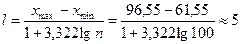 .
.
Вычислим частоты mi и относительные частоты wi вариант, принадлежащих каждому интервалу. Результат сведем в таблицу 1.3
Таблица 1.3
| Затраты на 1 ден. ед. продукции, ден. ед.
| Количество предприятий, mi
| Относительная частота, wi
| Накопленная частота, 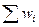
|
| [61,55-66,55)
|
| 0,07
| 0,07
|
| [66,55-71,55)
|
| 0,07
| 0,14
|
| [71,55-76,55)
|
| 0,12
| 0,26
|
| [76,55-81,55)
|
| 0,26
| 0,52
|
| [81,55-86,55)
|
| 0,23
| 0,75
|
| [86,55-91,55)
|
| 0,16
| 0,91
|
| [91,55-96,55]
|
| 0,09
| 1,00
|
Затраты по предприятиям, составляющие интервальный ряд распределения, представим графически. Построим гистограмму и полигон (рис 1.3, 1.4 соответственно).
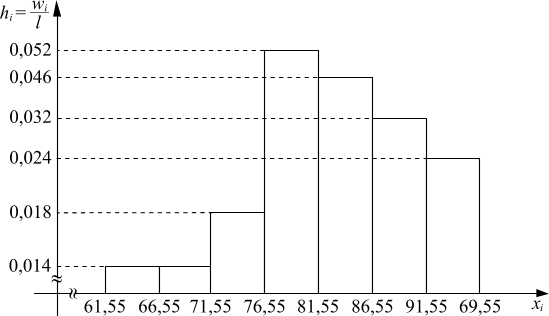
Рис. 1.3
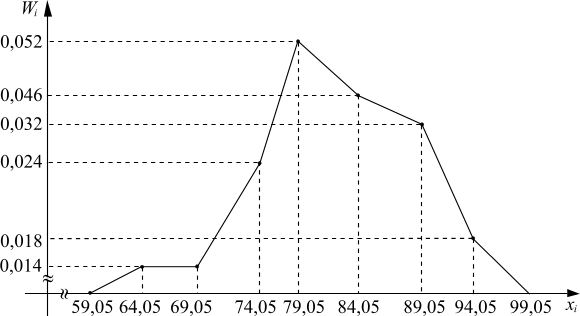
Рис. 1.4
Используя накопленные относительные частоты, составляем кумулянту (эмпирическую функцию распределения):
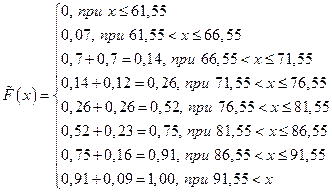
График эмпирической функции распределения показан на рис 1.5.
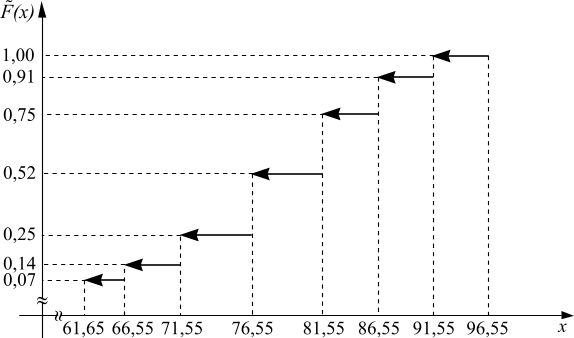

Рис 1.5
Вычислим числовые характеристики затрат (в денежных единицах) на 1 ден. ед. продукции (работ, услуг) по данным 100 предприятий г. Минска.
Среднее арифметическое для несгруппированных данных
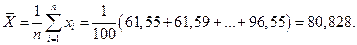
Если данные представлены в виде интервального статистического ряда распределения, то среднюю точку 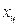 каждого интервала выбирают в качестве представителя всех вариант, входящих в состав интервала. Значение средней точки каждого интервала умножают на частоту интервала, суммируют эти произведения и делят на объем выборки:
каждого интервала выбирают в качестве представителя всех вариант, входящих в состав интервала. Значение средней точки каждого интервала умножают на частоту интервала, суммируют эти произведения и делят на объем выборки:
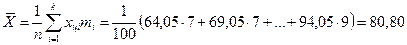
Как уже отмечалось, группировка всегда сопровождается потерей точности, что и подтверждает вычисление среднего арифметического. Поэтому остальные числовые характеристики вычислим по не сгруппированным данным.
Не сгруппированные данные образуют дискретный вариационный ряд, содержащий четное число вариант, поэтому медиана равна полусумме средних вариант:
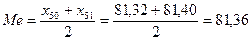 .
.
Такие исходные не сгруппированные данные не имеют моды.
Но если рассмотреть интервальный статистический ряд распределения (таблица 1.3), то модальным интервалом будет интервал (76,55;81,55), имеющий наибольшую частоту и тогда моду вычислим по формуле (1.3):
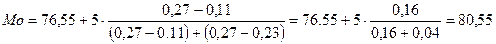 .
.
С теоретической точки зрения наиболее подходящей мерой колеблемости ряда распределения служит статистическая дисперсия:
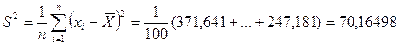 .
.
Среднее статистическое квадратичное отклонение - величина абсолютная, она выражается в тех же единицах, что и сами затраты:
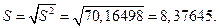
Пределы изменения затрат характеризует размах:
R=96,55-61,55=35,0.
Вычисляем безразмерные показатели вариации - коэффициенты вариации:
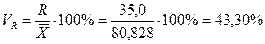 ;
;
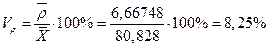 ;
;
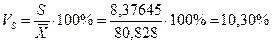 .
.
Значение коэффициента вариации Vs показывает, что совокупность исходных данных однородна.
Выяснение общего характера распределения предполагает вычисление показателей асимметрии и эксцесса. Асимметрия:
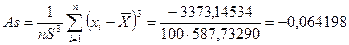
отрицательна, следовательно, распределение характеризуется незначительной левосторонней асимметрией.
Эксцесс:
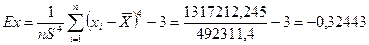
отрицательный, следовательно, распределение затрат более плосковершинное по сравнению с нормальным.
Ошибки асимметрии и эксцесса SAs =0,23774, SEx =0,45475 удовлетворяют неравенствам:
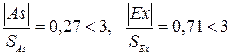 ,
,
откуда следует, что асимметрия и эксцесс незначительны в распределении затрат.
В задачах 1.2 – 1.4 построить эмпирическое распределение, его графическое представление, эмпирическую функцию распределения и вычислить числовые характеристики выборки: среднее арифметическое, моду, медиану, статистическую дисперсию, среднее статистическое квадратическое отклонение, вариационный размах, среднее абсолютное (линейное) отклонение, коэффициенты вариации, асимметрию и эксцесс.
1.2. Число построенных квартир (тысяч) различными организациями приводятся в таблице 1.4
Таблица 1.4
| Государственными
предприятиями и
организациями
| Жилищно-строительными
кооперативами
| Индивидуальными застройщиками
| Колхозами
| Кооперативными,
арендными, общественными организациями
и другими организациями
|
| 50,4
| 8,0
| 28,2
| 2,9
| 0,2
|
| 52,5
| 8,2
| 21,9
| 2,9
| 0,4
|
| 51,3
| 9,1
| 21,6
| 3,3
| 0,4
|
| 58,8
| 8,5
| 21,8
| 3,5
| 0,4
|
| 53,2
| 7,5
| 20,4
| 4,2
| 0,3
|
| 53,7
| 6,4
| 18,7
| 5,0
| 0,4
|
| 50,1
| 6,5
| 15,2
| 4,1
| 0,3
|
| 53,7
| 6,5
| 13,1
| 4,6
| 0,5
|
| 54,8
| 7,0
| 11,6
| 5,0
| 0,3
|
| 54,6
| 6,1
| 11,0
| 6,0
| 0,2
|
| 58,3
| 6,5
| 8,9
| 6,2
| 0,5
|
| 59,7
| 8,1
| 8,0
| 7,0
| 0,3
|
| 59,4
| 7,4
| 7,6
| 7,5
| 0,2
|
| 59,4
| 9,6
| 6,9
| 7,3
| 0,3
|
| 61,0
| 10,2
| 6,4
| 8,9
| 0,3
|
| 61,1
| 11,1
| 5,8
| 9,9
| 0,6
|
| 61,7
| 11,8
| 6,3
| 11,8
| 0,5
|
| 71,0
| 13,8
| 5,7
| 8,9
| 0,3
|
| 67,5
| 11,4
| 5,7
| 7,9
| 0,2
|
| 69,7
| 12,0
| 5,9
| 6,5
| 0,3
|
| 63,3
| 10,8
| 8,3
| 5,4
| 1,3
|
| 66,2
| 7,3
| 4,4
| 3,9
| 2,1
|
| 52,7
| 7,0
| 3,9
| 3,3
| 4,1
|
| 36,0
| 11,2
| 4,2
| 3,0
| 4,7
|
| 30,8
| 8,3
| 5,3
| 1,6
| 4,9
|
| 15,8
| 3,5
| 4,7
| 0,9
| 2,4
|
| 13,4
| 15,1
| 5,9
| 0,6
| 3,2
|
1.3. Поезда метро идут строго по расписанию с интервалом в 5 минут. В результате измерения получена выборка времени (в секундах) ожидания поезда для 15 студентов, каждый из которых выходит на перрон в случайный момент времени:
38; 61; 60; 42; 52; 51; 34; 65; 72; 80; 92; 90; 104; 102; 79.
1.4. Число автомобилей, подъезжающих на заправку в течении часа в различное время суток характеризуется выборкой:
6-7; 7-8; 8-9; 9-10; 10-11; 11-12; 12-13; 13-14; 14-15; 15-16; 16-17; 17-18;
12 20 40 37 28 15 21 17 18 11 8 25
18-19; 19-20; 20-21; 21-22; 22-23.
30 20 11 10 10
В задачах 1.5-1.14 построить интервальный статистический ряд распределения (если он не задан), гистограмму, полигон относительных частот, эмпирическую функцию распределения, вычислить числовые характеристики выборки: среднее арифметическое, медиану, моду, статистическую дисперсию и среднее квадратическое отклонение, вариационный размах, среднее абсолютное (линейное) отклонение, коэффициенты вариации.
1.5. Интервальный ряд распределения:
Таблица 1.5
Границы
интервалов,
|
10-20
|
20-30
|
30-40
|
40-50
|
50-60
|
60-70
|
70-80
|
| Частоты, mi
|
|
|
|
|
|
|
|
1.6. Интервальный ряд распределения:
Таблица 1.6
| Границы
интервалов,
| 18-20
| 20-22
| 22-24
| 24-26
| 26-28
| 28-30
| 30-32
| 32-34
|
| Частоты, mi
|
|
|
|
|
|
|
|
|
1.7. Результаты измерения емкости затвор – сток у 96 полевых транзисторов:
| 1,9
| 3,1
| 1,3
| 0,7
| 3,2
| 1,1
| 2,9
| 2,7
| 2,7
| 4,0
| 3,1
| 3,9
|
| 1,7
| 3,2
| 0,9
| 0,8
| 3,1
| 1,2
| 2,6
| 1,9
| 2,3
| 3,2
| 1,3
| 2,8
|
| 4,1
| 1,3
| 2,4
| 4,5
| 2,5
| 0,9
| 1,4
| 1,6
| 2,2
| 3,1
| 2,1
| 2,5
|
| 1,5
| 1,1
| 2,3
| 4,3
| 2,1
| 0,7
| 1,2
| 1,5
| 1,8
| 2,9
| 2,5
| 2,1
|
| 0,8
| 0,9
| 1,7
| 4,1
| 4,3
| 2,6
| 0,9
| 0,8
| 1,2
| 2,1
| 1,8
| 3,1
|
| 3,2
| 2,9
| 1,1
| 3,2
| 4,5
| 2,1
| 3,1
| 5,1
| 1,1
| 1,9
| 1,3
| 2,6
|
| 0,9
| 3,1
| 0,9
| 3,1
| 3,3
| 2,8
| 2,5
| 4,0
| 4,3
| 1,1
| 2,5
| 3,5
|
| 2,1
| 3,8
| 4,6
| 3,8
| 2,3
| 3,9
| 2,4
| 4,1
| 4,2
| 0,9
| 3,7
| 3,9
|
1.8. Распределение скорости автомобилей на одном из участков автомагистрали:
1.9. Распределение общего времени (в минутах) на ожидание и обслуживание автомобилей на заправочной станции:
1.10. Как изменятся числовые характеристики выборки, если результаты наблюдения увеличить или уменьшить одновременно в m раз?
1.11. Распределение времени наработки на отказ приборов некоторого типа:
| 1,31
| 0,48
| 0,76
| 1,71
| 1,20
| 0,54
| 0,20
| 0,67
|
| 0,62
| 0,15
| 0,05
| 0,78
| 0,24
| 0,29
| 1,47
| 1,11
|
| 0,67
| 0,99
| 1,02
| 0,51
| 0,65
| 1,56
| 0,16
| 0,49
|
1.12. Производство кожаной обуви в Республике Беларусь (в млн. пар):
Таблица 1.7
| t, годы
| Yi, млн. пар
| t, годы
| Yi, млн. пар
|
|
|
|
| 45,3
|
|
| 41,8
|
| 46,8
|
|
| 41,2
|
| 45,3
|
|
| 41,5
|
| 37,2
|
|
| 41,3
|
| 33,4
|
|
|
|
| 26,4
|
|
| 42,2
|
|
|
|
| 43,1
|
| 11,4
|
|
| 44,2
|
| 15,6
|
|
| 44,8
|
| 16,2
|
|
| 45,3
|
| 16,5
|
|
| 46,9
|
|
|
1.13. Динамический ряд, характеризующий изменение значения денежных агрегатов (в условных денежных единицах):
Таблица 1.8
| год
| Y
| Год
| Y
|
| 01.01.97
| 5109,5
| 01.08.98
| 26459,0
|
| 01.02.97
| 5261,7
| 01.09.98
| 27803,3
|
| 01.03.97
| 7553,0
| 01.10.98
| 28563,3
|
| 01.04.97
| 9223,8
| 01.11.98
| 26603,3
|
| 01.05.97
| 10031,4
| 01.12.98
| 29837,7
|
| 01.06.97
| 12360,4
| 01.01.99
| 31483,2
|
| 01.07.97
| 13032,5
| 01.02.99
| 39381,0
|
| 01.08.97
| 12676,1
| 01.03.99
| 39995,3
|
| 01.09.97
| 12981,8
| 01.04.99
| 40343,7
|
| 01.10.97
| 13351,2
| 01.05.99
| 47337,7
|
| 01.11.97
| 12054,2
| 01.06.99
| 48812,8
|
| 01.12.97
| 131,86
| 01.07.99
| 60232,4
|
| 01.01.98
| 14454.8
| 01.08.99
| 65328,2
|
| 01.02.98
| 15610,4
| 01.09.99
| 67134,1
|
| 01.03.98
| 16883,2
| 01.10.99
| 72487,2
|
| 01.04.98
| 19887,1
| 01.11.99
| 66044,1
|
| 01.05.98
| 20484.1
| 01.12.99
| 73073,0
|
| 01.06.98
| 24988,2
| 01.01.00
| 74311,1
|
| 01.07.98
| 27196,9
|
|
|
1.14. Динамические ряды, характеризующие урожайность зерна (таблица 1.9) и валовой сбор зерна (таблица 1.10) в Республике Беларусь:
Таблица 1.9
| Год
| Урожайность зерна в РБ (центнеров с 1 гектара)
| Год
| Урожайность зерна в РБ (центнеров с 1 гектара)
|
|
| 26,6
|
| 23,6
|
|
| 24,2
|
| 18,3
|
|
| 26,8
|
| 14,5
|
|
| 27,7
|
| 19,1
|
|
| 22,4
|
| 19,9
|
|
| 20,4
|
| 24,7
|
|
| 21,7
|
| 24,2
|
Таблица 1.10
| год
| Валовой сбор зерна в РБ (тыс. тонн)
| Год
| Валовой сбор зерна в РБ (тыс. тонн)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5448,8
|
Статистическое оценивание.
Основной задачей математической статистики является задача определения закона распределения наблюдаемой случайной величины Х по данным выборки.
Числовые характеристики выборки 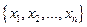 называются статистическими и являются величинами случайными. Они имеют законы распределения, зависящие от законов распределения случайной величины Х в генеральной совокупности.
называются статистическими и являются величинами случайными. Они имеют законы распределения, зависящие от законов распределения случайной величины Х в генеральной совокупности.
Выборочная числовая характеристика, применяемая для получения оценки неизвестного параметра a генеральной совокупности, называется точечной оценкой 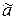 . Оценка - это значение некоторой функции элементов выборки, то есть
. Оценка - это значение некоторой функции элементов выборки, то есть 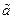 =
= 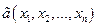 .
.
Наилучшую точечную оценку определяют при помощи условий: несмещеннсти, эффективности и состоятельности.
Оценка называется несмещенной оценкой параметра 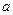 , если ее математическое ожидание равно оцениваемому параметру, то есть
, если ее математическое ожидание равно оцениваемому параметру, то есть 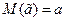 . Разность
. Разность 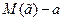 называется смещением.
называется смещением.
Несмещенной оценкой математического ожидания генеральной совокупности служит среднее арифметическое выборки: 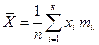
где 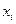 – варианта выборки,
– варианта выборки, 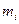 – частота варианты
– частота варианты 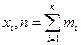 - объем выборки.
- объем выборки.
Для оценки параметра a может быть предложено несколько несмещенных оценок. Мерой точности несмещенной оценки считают ее дисперсию D(). Если 1 и 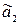 – две различные несмещенные оценки параметра a и D( 1)< D (), то оценка 1 более эффективна, чем оценка ;
– две различные несмещенные оценки параметра a и D( 1)< D (), то оценка 1 более эффективна, чем оценка ;
Несмещенная оценка параметра a, дисперсия которой достигает своего наименьшего возможного значения 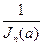 , называется эффективной:
, называется эффективной: 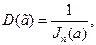
где 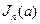 - информация Фишера, содержащаяся в выборке объема
- информация Фишера, содержащаяся в выборке объема 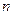 относительно неизвестного параметра . Для непрерывной случайной величины
относительно неизвестного параметра . Для непрерывной случайной величины 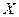 с плотностью распределения
с плотностью распределения 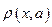 информация Фишера равна:
информация Фишера равна:
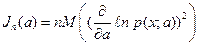 . (2.1)
. (2.1)






