Объект, освещенный под разными углами или представленный с разных сторон от точки фиксации взгляда, проецирует на сетчатку отличные друг от друга изображения. Эта изменчивость существенно усложняет задачу для нейронных сетей, отвечающих за категории, с помощью которых мы идентифицируем мир. Допустим, нам нужно идентифицировать некий объект. Не имеет значения, расположен он близко или далеко от нас, слева или справа, вертикально или горизонтально, на свету или в тени. Мы можем легко распознать его независимо от освещения, наклона, расстояния и местонахождения. В ходе эволюции мозг, несомненно, подвергся интенсивному избирательному давлению, которое вынудило его прийти к устойчивому восприятию мира. Сегодня мы знаем, что инвариантность – важнейшая характеристика нижней височной доли. Обезьяны с повреждениями вентральной височной области не способны распознавать объекты таким образом. В отличие от здоровых особей, они не могут распространять результаты научения на новые условия и перестают узнавать усвоенную фигуру при изменении освещения, ее размера или пространственного расположения[216]. Эксперименты на животных показывают, что нижняя височная кора имеет ключевое значение в сборе стабильной зрительной информации. Эта врожденная компетенция, судя по всему, тесно связана с нашей способностью определять, что «РАДИО», «радио» и даже «РаДиО» – одно и то же слово.
Не так давно технология регистрации отдельных нейронов позволила установить точный нейронный код для зрительных объектов у макак. Еще в конце 1960‑х годов Дэвид Хьюбел и Торстен Визель записали активность нейронов в первичной зрительной коре кошки и обнаружили, что клетки срабатывают в ответ на полосы света. В 1982 году их работа была удостоена Нобелевской премии. В 70–80‑х годах сразу несколько выдающихся нейробиологов (Роберт Дисаймон, Чарлз Гросс, Дэвид Перретт, Кэйдзи Танака) последовали их примеру и вживили электроды в передние отделы мозга макаки[217]. Простых линий оказалось недостаточно, чтобы вызвать реакцию нейронов нижневисочной коры: требовались более сложные стимулы. В итоге ученые собрали самые разные образы, фигуры, лица и предметы и предъявляли их зрительно, по одному зараз.
Избирательность нейронных разрядов была очевидна сразу. Зачастую нейрон реагировал только на одно лицо или один конкретный объект, игнорируя десятки других (рис. 3.2). Эта избирательность была тем более примечательна, что сопровождалась выраженным постоянством отклика при масштабных изменениях в деталях исходного изображения. В первичной зрительной коре реакция нейронов обусловлена очень узким окном ввода на сетчатке – так называемым рецептивным полем. Нейроны в нижневисочной коре совсем другие. Их рецептивные поля обширны, а потому они могут реагировать на объекты, появляющиеся почти в любом месте поля зрения. Однако в любой заданной точке этой огромной зоны восприятия каждый нейрон демонстрирует предпочтение объектов определенной категории. Такая предвзятость сохраняется даже тогда, когда изображение смещается на несколько градусов, увеличивается или уменьшается в два раза[218], либо попадает под другое освещение, в результате чего меняется игра света и тени[219].

Рис. 3.2. Нейроны нижневисочной коры обезьяны могут обладать выраженной избирательной чувствительностью по отношению к определенным объектам, лицам или зрительным сценам. Из 100 изображений, последовательно предъявленных одному конкретному нейрону, только вид стула вызвал значительное усиление его активности (по материалам статьи Tamura & Tanaka, 2001). Использовано с разрешения Oxford University Press и Cerebral Cortex.
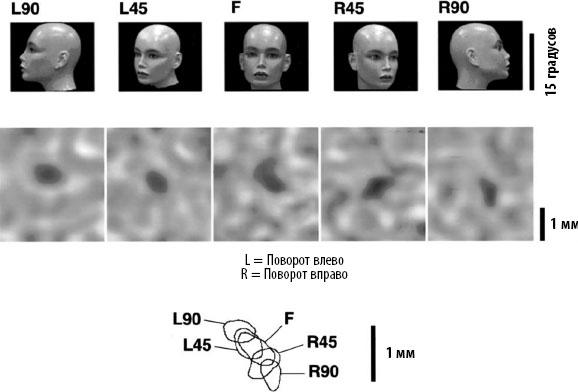
Рис. 3.3. Небольшие участки нижневисочной коры обезьяны реагируют на лица. Вид лица активирует корковую колонку шириной около 500 мкм, которая выглядит как темное пятно на поверхности коры. Когда лицо вращается, последовательные его изображения активируют соседние и частично перекрывающиеся секторы, тем самым содействуя уточнению нейронного кода, неизменного относительно вращения (по материалам статьи Tanaka, Tomonaga, & Matsuzawa, 2003). Использовано с разрешения Cerebral Cortex.
Что происходит, когда объект поворачивается вокруг своей оси? Инвариантность относительно вращения – настоящая проблема для нашей зрительной системы. На самых ранних стадиях визуального распознавания последовательные положения вращающегося лица не кодируются одними и теми же нейронами. Вид справа, спереди и слева активируют соседние участки коры, которые частично перекрывают друг друга (рис. 3.3)[220]. Если объект вращается на сетчатке, большинство нейронов нижневисочной коры срабатывают только в тот момент, когда он оказывается повернут под определенным углом. При отклонении от этого предпочтительного угла более чем на 40 градусов они перестают реагировать вообще. Впрочем, некоторые нейроны более абстрактны и «откликаются» на объект независимо от его положения в пространстве (рис. 3.4)[221]. Проще говоря, эти инвариантные нейроны, судя по всему, собирают входные данные от множества других клеток, каждая из которых отвечает за конкретный угол обзора. Так, они обнаруживают присутствие объекта, объединяя все возможные точки обзора, с которых его можно увидеть.
Итак, проблема зрительной инвариантности, по всей видимости, решается за счет целой серии последовательных стадий обработки, реализуемых в пределах нижневисочной коры. На высшем уровне этой зрительной иерархии активность нейронных ансамблей остается постоянной даже тогда, когда объект движется, отдаляется, поворачивается или отбрасывает новые тени. Этот механизм возник за миллионы лет до изобретения чтения, но его существование играет ключевую роль в нашей способности распознавать слова любого размера, напечатанные любым шрифтом и в любом месте на странице.

Рис. 3.4. Некоторые нейроны нижневисочной коры реагируют на формы избирательно и инвариантно. Этот нейрон энергично срабатывает в ответ на предъявление кольца и (в меньшей степени) на предъявление «треноги» (внизу слева). Реакция в основном не зависит от ориентации объекта в пространстве (по материалам статьи Booth & Rolls, 1998). Использовано с разрешения Cerebral Cortex.
«Бабушкины» клетки
Только представьте: один нейрон реагирует только на одно изображение из тысячи. Это физиологическое наблюдение ошеломляет. Неужели наша кора в самом деле покрыта миллионами ультраспециализированных клеток? Физиолог Гораций Барлоу однажды в шутку заметил, что мозг содержит «бабушкины клетки» – нейроны, реагирующие только на вашу бабушку. Хотя утверждение Барлоу было не лишено иронии, он оказался прав или, по крайней мере, близок к истине. Мозг обезьяны, как и человека, содержит нейроны, которые настолько узкоспециализированы, что в буквальном смысле посвящены одному‑единственному человеку, образу или понятию. Например, в переднем отделе височной доли пациента с эпилепсией однажды обнаружили нейрон, который реагировал исключительно на голливудскую суперзвезду Дженнифер Энистон[222]. Характер исходного изображения значения не имел: это могла быть цветная фотография, лицо крупным планом, карикатура или даже написанное имя – нейрон срабатывал только при виде или упоминании Дженнифер!
Концепция «бабушкиного нейрона» вполне может оказаться истинной, но с рядом оговорок. Даже когда такая удивительная избирательность обнаруживается в одном нейроне, она должна быть результатом вычислений гораздо более крупной сети. Эксперименты, на которые я ссылаюсь, предполагали вживление электродов в участки зрительной системы, выбранные наугад. Если можно найти специализированный нейрон таким бессистемным способом, то, без сомнения, миллионы других ждут своего открытия. Кроме того, их специфичность неизбежно вытекает из коллективной работы многих клеток. В сущности, избирательная реакция одной клетки подобна верхушке айсберга: мы можем видеть ее только благодаря массе нейронов, создающих целую иерархию детекторов. Насколько нам известно, отдельный нейрон сам по себе может выполнять лишь относительно элементарные вычисления на входе. Кроме того, на выходе он не имеет большого влияния: только коалиция из нескольких сотен клеток способна влиять на другие группы клеток. Следовательно, каждое зрительное событие или лицо, которое мы распознаем, должно кодироваться несколькими кластерами избирательных нейронов (так называемое разреженное кодирование).
Представить себе всю цепочку – от миллионов фоторецепторов в сетчатке, которые реагируют на пятна света, до нейронов, что обнаруживают присутствие Дженнифер Энистон, – это неимоверно сложная задача. Мы только начинаем понимать детальную нейронную организацию зрительного распознавания. Мы знаем, что анатомически нижневисочная кора макаки похожа на пирамиду. Зрительный образ входит в ее основание, после чего множество последовательных связей передают его из первичной зрительной коры, расположенной в задней части головы, к переднему краю височного полюса (рис. 3.5)[223]. По мере продвижения вперед сложность образов, возбуждающих нейроны, возрастает. На каждом этапе рекомбинация откликов нейронов предыдущего уровня позволяет клеткам следующего уровня реагировать на более крупные фрагменты изображений. Иначе говоря, наша зрительная система идеально приспособлена для повторной сборки гигантского пазла, который создает сетчатка, раскладывая входящие изображения на миллионы пикселей.[224]
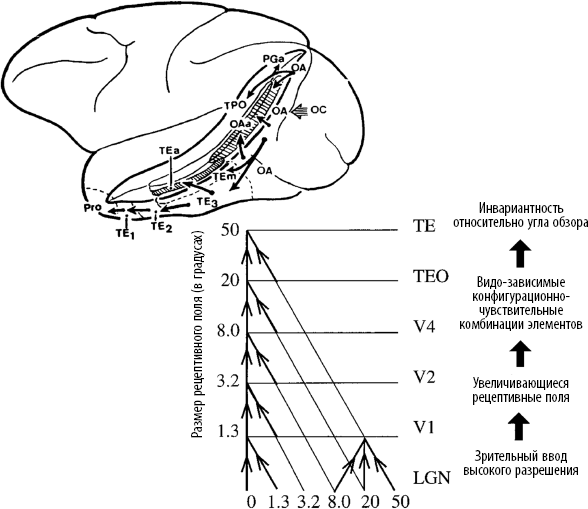
Рис. 3.5. Затылочная и нижневисочная области организованы в виде иерархии возрастающей инвариантности и последовательно соединены друг с другом в соответствии с «синаптической пирамидой». На каждой стадии размер рецептивного поля – области сетчатки, на которую реагируют нейроны, – увеличивается в два‑три раза. Параллельно возрастает сложность и инвариантность их зрительных предпочтений (по материалам статьи Rolls, 2000). Использовано с разрешения Neuron.
Если бы мы могли подняться по нейронной пирамиде шаг за шагом, синапс за синапсом, и записать активность отдельных нейронов, попавшихся нам по пути от первичной зрительной коры до нижней височной доли, мы бы обнаружили три типа изменений:
• Во‑первых, предпочитаемые образы, на которые реагирует нейрон, должны постепенно усложняться. Чтобы вызвать активность в первичной зрительной коре, достаточно маленькой диагональной черты. Для срабатывания нейронов на более высоких уровнях требуются сложные кривые, фигуры, фрагменты объектов и даже целые объекты или лица.
• Во‑вторых, нейроны более высоких уровней реагируют на более обширные участки сетчатки. Каждая клетка определяется сквозь призму своего рецептивного поля – то есть места на сетчатке, которое вызывает ее активность. На каждом уровне рецептивные поля расширяются в два‑три раза. Это означает, что диаметр ретинального участка, на который должен попасть предпочитаемый объект, чтобы нейрон сработал, тоже увеличивается вдвое или втрое.
• В‑третьих, чем выше уровень, тем выше степень инвариантности. Нейроны низших уровней чувствительны к изменениям местоположения, размера и освещения входящей картинки. В областях более высокого уровня нейроны допускают бо́льшие сдвиги и искажения кодируемых объектов.
Функциональная визуализация мозга показывает, что иерархическая организация и возрастающая инвариантность присущи и нашей зрительной коре[225]. У человека, как и у других приматов, концепция нейронной иерархии обеспечивает простое, хотя и гипотетическое решение проблемы зрительной инвариантности. Чтобы опознать объект, наша кора должна усвоить, как он выглядит с разных сторон. Механизмы научения закрепляют за каждым видом отдельный набор нейронов, после чего соединяют «картинки» так, чтобы они сообща возбуждали те же самые нейроны на следующем уровне иерархической пирамиды. Результат – инвариантная нейронная цепь, допускающая значительные изменения угла обзора. Эта простая идея может быть легко воспроизведена на каждом этапе. Нейроны, отвечающие за распознавание профиля Дженнифер Энистон, собирают информацию от клеток более низких уровней, которые идентифицируют фрагменты ее лица. Эти нейроны способны распознать глаз или нос, потому что предыдущий уровень уже обнаружил паттерны света и тени, совместимые с присутствием этих элементов в конкретном месте на сетчатке.
Понятия иерархии и параллельного функционирования – вот главные ключи к зрительной системе приматов. Мысленный образ, разложенный сетчаткой на множество «пикселей», постепенно собирается заново пирамидой нейронов, работающих одновременно. На первый взгляд такой подход может показаться неэффективным: в таком случае каждому из возможных фрагментов, составляющих зрительную сцену, должны быть посвящены миллионы нейронов. Нагрузка на нервную систему, однако, относительно невелика: все, что мы видим, распределяется по гигантской сети простых параллельных процессоров. Подобно тому, как колония муравьев обладает более высоким интеллектом, нежели один муравей, коллективная работа миллионов нейронов позволяет выполнять операции гораздо более сложные, чем те, на которые способна одна клетка. В действительности огромное количество вычислительных блоков приводит к значительной экономии времени обработки. Одиночные нейроны работают медленно. Они получают и передают информацию примерно за 10 миллисекунд, что в миллион раз медленнее скорости электронного микропроцессора. Однако, объединяя активность миллионов нервных клеток, наша зрительная система становится самым эффективным компьютером в мире: ей требуется всего одна шестая доля секунды, чтобы заметить лицо независимо от его внешних особенностей и пространственного расположения[226].
Архитектура мозга вдохновила многих программистов. В настоящее время доступны несколько компьютерных моделей зрительной иерархии, которые я описал[227]. Лучшие из них близки к человеческой как по скорости, так и по степени искажения изображения, которую они допускают. Благодаря этим искусственным нейросетям автоматическое распознавание лиц больше не воспринимается как что‑то из области научной фантастики. Это часть реальной жизни – самая простая цифровая камера сегодня может распознавать лица и улыбки.
Алфавит в мозге обезьяны
Пирамидальная модель предполагает, что нейронный код для любого зрительного объекта состоит из иерархии нервных клеток, каждая из которых обнаруживает наличие некоего фрагмента этого объекта в получаемом изображении. Большинство таких нейронов, вероятно, реагируют на упрощенные и ограниченные виды объектов или их частей. Используя эту гипотезу в качестве отправной точки, японский нейробиолог Кэйдзи Танака сделал любопытное открытие: мозг обезьяны содержит мозаику нейронов, посвященных фрагментам формы. В совокупности эти примитивные очертания образуют своего рода «нейронный алфавит», комбинации которого могут описать любую сложную форму.
Для изучения нейронного кода объектов Танака и его коллеги разработали специальный алгоритм, постепенно упрощавший сложные сцены (рис. 3.6). Они брали образ, который провоцировал энергичные разряды нейрона, а затем сводили его к самой простой возможной форме, которая по‑прежнему вызывала возбуждение. Рассмотрим нейрон, изначально реагировавший на вид кошки. Танака обнаружил, что эта клетка так же активно срабатывала при виде двух соприкасающихся дисков. Другому нейрону «нравилась» форма яблока, но он так же хорошо откликался на черный кружок с «хвостиком». Третий нейрон, который срабатывал при виде куба, в действительности обнаруживал только Y‑образное пересечение его центральных граней. Иными словами, большинство клеток в нижневисочной коре разряжались независимо от кардинальных упрощений изображения[228].
Записав активность сотен нейронов, Танака смог реконструировать приблизительную мозаику объектных клеток на поверхности коры обезьяны. Предпочтения отдельных нейронов менялись плавно: как правило, соседние клетки кодировали схожие формы (рис. 3.6). Например, один сектор отвечал за варианты Y и T. Другие участки специализировались на формах, напоминавших звезды, упрощенный профиль лица или цифру 8. Танака фактически обнаружил целый корковый каталог элементарных форм. В любом заданном месте коры все нейроны внутри вертикальной корковой колонки «интересовались» более или менее похожими фигурами. При этом каждый из них был чувствителен к мельчайшим метрическим отклонениям от базового прототипа.
В совокупности эти клетки обеспечивают алфавит форм, который позволяет классифицировать любое изображение (лицо это или нет?) и выделить его детали, ответив на вопросы: Это лицо Дженнифер Энистон? Сколько ей лет? Она счастлива? Объединяя отклики миллионов таких детекторов, мозг кодирует каждую из миллиардов картинок, которые мы можем увидеть в природе.
Один из учеников Танаки, Манабу Танифудзи, продолжил исследования в этом направлении и выяснил, как множественные колонки нейронов кодируют произвольные объекты. В своих экспериментах он использовал оптическую запись, которая позволила увидеть большую часть коркового кода, связанного со зрительным объектом[229]. Всякий раз, когда мозг активируется, количество света, которое он отражает, уменьшается (механизм этого явления до конца не изучен). Танифудзи измерял нейронную активность всей области мозга с помощью чувствительной видеокамеры, фиксирующей крошечные изменения в отражении света на поверхности коры. С помощью мощного зум‑объектива камера отслеживает активные структуры, расположенные на расстоянии всего нескольких десятых миллиметра друг от друга – примерно такого же размера были колонки Танаки, кодировавшие формы.
В одном эксперименте Танифудзи показывал обезьяне изображение огнетушителя. Идея состояла в том, чтобы стимулировать кору предметами, в распознавании которых эволюция не могла сыграть никакой роли. Корковая мозаика, кодировавшая этот объект, проявилась в виде разреженного массива темных пятен – зон выраженной нейронной активности. Эта «корковая опись» огнетушителя возникала всякий раз, когда Танифудзи показывал его обезьяне. Затем ученый убрал рукоятку и шланг. При виде только красного баллона некоторые пятна исчезли, зато другие остались такими же активными. Что еще удивительнее, в этом случае «вспыхнули» новые пятна. Другими словами, как только менялся внешний вид объекта, каждому новому изображению немедленно приписывался уникальный нейронный код.

Рис. 3.6. Упрощение изображения позволяет выявить микротопографию височной коры. Сложный стимул, активирующий нейрон, постепенно упрощается, пока не будет найден наиболее простой образ, по‑прежнему вызывающий сильную реакцию (вверху). Некоторые из минимальных форм напоминают буквы (O, T, Y, E и так далее). Реагирующие на них нейроны организованы в вертикальные колонки, перпендикулярные коре головного мозга. В этом положении предпочитаемые формы непрерывно варьируются, образуя локальные секторы «избранной» фигуры (по материалам статьи Tanaka, 2003). Использовано с разрешения Cerebral Cortex.
Регистрируя активность отдельных нейронов в каждом из пятен, Танифудзи смог пролить свет на лежащий в основе комбинаторный код. В одном месте нейроны реагировали на вид одной только рукоятки, а также на любую V‑образную форму, похожую на очертания руки или кошачьих ушей. В другом месте они тоже откликались на рукоятку, но прямые линии не воспринимались: этим клеткам больше нравилась изогнутая, как буква «J», форма. Нейроны из третьей группы реагировали на сам баллон, а также на любую другую удлиненную и несколько прямоугольную форму, но переставали это делать, когда к предмету добавлялись такие элементы, как рукоятка или шланг.
Эксперименты Танифудзи внесли существенный вклад в понимание того, как наша височная кора кодирует зрительные образы – даже те, которые мы видим впервые. Секрет заключается в алфавите элементарных форм, каждая из которых кодируется определенными популяциями нейронов и миллионами их потенциальных комбинаций. Различные клетки реагируют не только на разные части объекта; их интересует, как составляющие предмета расположены в пространстве. Подобный комбинаторный код существует на каждом иерархическом уровне зрительной системы. При движении от низших уровней к высшим масштаб и степень сложности предпочитаемых форм возрастают. Первичная зрительная область (V1) главным образом отвечает за обнаружение тонких линий и контуров объектов. Во вторичной зрительной области (V2) нейроны уже чувствительны к сочетаниям линий с четко выраженными наклонами или кривыми[230]. Еще выше, в задней части нижневисочной коры (в так называемой области TEO) клетки реагируют на простые комбинации кривых[231]. Избирательная реакция нейронов – скажем, на букву F – может быть сведена к обнаружению простого сочетания элементарных кривых, каждая из которых расположена в относительно фиксированном месте: верхняя полоса, верхний левый угол, средняя полоса и так далее. Аналогичная схема, по‑видимому, повторяется на каждом уровне: нейронная избирательность есть результат объединения элементов, кодируемых нейронами предыдущих ярусов.
Протобуквы
Возможно, самая поразительная особенность нейронов нижневисочной коры заключается в следующем: многие из предпочитаемых ими форм очень напоминают наши буквы, символы или элементарные китайские иероглифы (рис. 3.4 и 3.6). Одни клетки реагируют на два соприкасающихся круга, образующих восьмерку, другие – на пересечение двух черточек, образующих букву Т, третьи же предпочитают астериск, круг, букву «J», букву «Y»… По этой причине мне нравится называть их протобуквами. То, что эти формы столь глубоко встроены в предпочтения нейронов макак, удивительно. По какому необычайному стечению обстоятельств этот корковый «алфавит» так похож на тот, который мы унаследовали от евреев, греков и римлян? Парадокс чтения поистине достигает своего апогея в этом таинственном сходстве между двумя мирами, которые мы считали дискретными: глубинами коры головного мозга обезьяны и поверхностью глины, тростника и пергамента, на которые первые писцы наносили свои письмена.
Некоторое представление о происхождении этих обезьяньих протобукв можно получить, изучив причину их появления в зрительном поле. Наиболее правдоподобная гипотеза состоит в том, что эти фигуры были отобраны либо в ходе эволюции, либо в результате зрительного научения как составляющие общего «алфавита» форм, необходимых для анализа зрительной сцены. Форма Т, например, чрезвычайно часто встречается в естественных сценах. Всякий раз, когда один объект маскирует другой, их контуры образуют Т‑образное соединение. Значит, нейроны, выполняющие функцию «Т‑детекторов», помогают определить, какой объект находится перед каким.

Другие распространенные конфигурации, такие как формы Y и F, обнаруживаются в точках схождения нескольких граней – они характеризуют острые углы и их ориентацию. Формы J и 8 присущи объектам с кривыми и отверстиями. Все эти фрагменты фигур относятся к так называемым неслучайным свойствам зрительных сцен, поскольку они вряд ли могут возникнуть произвольно в отсутствие какого‑либо объекта вообще. Если вы бросите на пол горсть спичек, маловероятно, что две из них образуют Т‑образное пересечение, и еще менее вероятно, что три из них дадут конфигурацию в виде буквы Y. Следовательно, когда одна из этих форм появляется на сетчатке, мозг может быть уверен, что она соответствует контуру некоего объекта во внешнем мире.
Если кора считает нужным кодировать неслучайные свойства, то это, несомненно, потому, что их комбинации крайне стабильны относительно изменений размера, освещения и угла обзора. Если взять кофейную чашку и повертеть ее в руке, края чашки образуют два противоположных F‑пересечения. Даже с одним закрытым глазом практически невозможно найти положение, под которым край и боковые стороны чашки находятся под прямым углом: как только исчезает две F наверху, тут же появляются две F внизу.

Во многих случаях перечень фигур, образуемых пересечением ребер, представляет собой инвариант, ограничивающий возможность идентификации объекта независимо от угла представления. По всей вероятности, наша нервная система приматов обнаружила это инвариантное свойство и использовала его для кодирования форм. Зрительные сцены обладают и многими другими неслучайными качествами. Одно из них – параллелизм: маловероятно, что изображение будет содержать два параллельных сегмента, если только они не являются гранями трехмерного объекта. Другие инварианты связаны с пространственной организацией: если объект содержит отверстие, то его проекция на сетчатку, вероятно, будет включать замкнутую О‑образную кривую. Зрительные инварианты, подобные этим, настолько узнаваемы, что прочно внедрены в нашу нервную систему. Согласно калифорнийскому психологу Ирвингу Бидерману, наша память вовсе не хранит детализированные визуальные образы объектов. Она просто извлекает схему их неслучайных свойств, организации и пространственных отношений[232]. Это позволяет нам сначала воссоздать элементарные части, составляющие трехмерную структуру объекта (поверхности, конусы, палочки), а затем собрать их в единую репрезентацию его формы. Главное преимущество такого кода – стабильность и постоянство при вращении, окклюзии[233] и присутствии других факторов, ухудшающих качество изображения.
Чтобы подтвердить свою гипотезу, Бидерман собрал доказательства того, что человеческое восприятие объекта в большей степени зависит от неслучайных свойств, нежели от других аспектов изображения. Например, если взять линейный снимок объекта, а затем удалить половину контуров, то его восприятие будет зависеть от того, сохранились ли неслучайные свойства:
• Если удалить сегменты линий, связывающие две вершины, и оставить нетронутыми неслучайные пересечения, распознавание объекта не вызывает сложностей.
• Если удалить все неслучайные свойства, распознавание становится практически невозможным (рис. 3.7)[234].
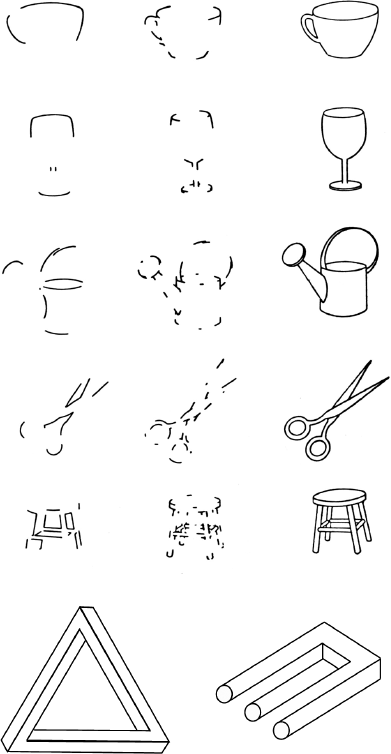
Рис. 3.7. Сложные объекты распознаются по расположению их контуров. В точках пересечения контуры образуют воспроизводимые конфигурации в виде букв T, L, Y или F. Их удаление существенно усложняет распознавание изображения (левый столбик). Удаление эквивалентного количества контуров, не затрагивающих такие соединения, не приводит к выраженным трудностям (средний столбик) (по материалам статьи Biederman, 1987). Любой организованный набор контуров, даже если он не образует единого целого, наша зрительная система автоматически воспринимает как трехмерный объект (внизу).
То же самое происходит, когда нам нужно определить идентичность двух любых объектов. Различия очевидны, если они касаются неслучайных свойств (например, «О» и цифра 8); но почти незаметны, если касаются только метрических характеристик, таких как размер (например, «О» и «о»)[235]. Бидерман, сотрудничая с нейрофизиологом Руфином Фогельсом, показал, что многие нейроны нижневисочной коры макаки игнорируют метрические искажения изображения при условии, что они не затрагивают неслучайные свойства[236].
Таким образом, нейроны нижневисочной коры предпочитают формы, напоминающие латинские буквы T, F, Y или O, по одной простой причине: в совокупности они обеспечивают оптимальный код, который характеризуется инвариантностью относительно трансформаций изображения и позволяет представлять бесконечное множество объектов. Вполне вероятно, что позже к этому алфавиту были добавлены и другие биологически значимые формы. Например, Танака заметил, что некоторые нейроны кодируют черную точку на белом фоне – глазной детектор, очень полезное устройство для такого социального вида, как наш. Другие клетки чувствительны к очертаниям руки или пальца. В первую очередь, однако, нижневисочная кора полагается на набор геометрических фигур и простых математических инвариантов. Большую часть букв мы вовсе не изобретали: они дремали в нашем мозгу миллионы лет и просто были открыты заново, когда человек придумал письмо и алфавит.
Распознавание форм
Но откуда именно берется корковый алфавит примитивных протобукв: он вписан в наши гены или возникает заново у каждого ребенка в результате процесса научения? Пока мы не знаем точного ответа на этот вопрос. Некоторые формы настолько облегчают процесс восприятия, что, вероятно, были заранее встроены в нашу зрительную систему в ходе эволюции. Уже в первые месяцы жизни младенцы чувствительны к лицам и окклюзии предметов. Следовательно, лица, глаза и Т‑образные соединения действительно могут быть частью «врожденного» лексикона форм. С эволюционной точки зрения это дало бы приматам большое преимущество, особенно в раннем взаимодействии с другими представителями своего вида и окружающей средой.
Однако трудно представить, каким образом человеческий геном, включающий максимум 30 000 генов, может содержать подробные инструкции, необходимые для программирования нейронных детекторов множества базовых форм, вплоть до профилей лица и огнетушителей! Кроме того, пластичность нижневисочной коры делает это маловероятным. Даже если мы допустим первоначальную генетическую предрасположенность, вероятно, большинство нейронов, участвующих в распознавании объектов, становятся избирательными в процессе взаимодействия со структурированной визуальной средой. Нас постоянно бомбардируют миллионы изображений, которые поставляют первичные данные для статистического алгоритма обучения мозга. В процессе развития, а возможно, и в течение всей жизни, синаптические контакты в нашей зрительной системе постоянно меняются. Эти трансформации обеспечивают оптимальное кодирование наиболее подходящих фрагментов изображений. Мы начинаем учить ребенка читать в очень раннем возрасте, когда пластичность коры находится на максимуме. Конечно, это не случайно. Погружая детей в искусственную среду букв и слов, мы, вероятно, переориентируем многие из нижневисочных нейронов на кодирование письменной речи.
Многие эксперименты показали, что нейроны постепенно настраиваются на объекты, которые учится различать обезьяна. Это происходит даже в том случае, если предметы, используемые для обучения, представляют собой бессмысленные проволочные фигуры или фракталы, формы которых очень далеки от тех, с какими животное может столкнуться в естественной среде обитания[237]. Очевидно, нейроны формируют свои предпочтения, учась обнаруживать характерные пересечения базовых элементов. Недавний эксперимент Криса Бейкера, Марлин Берманн и Карла Олсона подтверждает это предположение[238]. Исследователи научили обезьян распознавать палочки с разными фигурами на концах – например, с квадратом на одной стороне и трезубцем на другой. После тренировки несколько нейронов стали чувствительны к их точным комбинациям. Когда обезьяне показывали только один конец предмета, они реагировали слабо. Вкратце, нейронная активность при предъявлении всей картинки была больше, чем сумма реакций отдельных нейронов на каждую ее часть. Это прямое доказательство того, что клетки учатся реагировать на новые зрительные комбинации. В рамках огромного каталога возможных форм некоторые нейроны начинают срабатывать исключительно на комбинации, которые часто встречаются. В нашем нейронном инвентаре существуют и другие конфигурации, но только потенциально. Пока обезьяна им не научится, они не будут кодироваться клетками более высокого уровня.
Инстинкт учиться
На сегодняшний день найдено столько доказательств пластичности мозга, что иногда ее считают очевидным свойством коры. В действительности способность учиться – это результат сложного эволюционного процесса. Во многих случаях обучение нежелательно – малыш, которому придется учиться дышать или кушать, долго не проживет. С другой стороны, мы рождаемся в сложном мире, который невозможно предсказать заранее, а потому все устройство нашего мозга нельзя запрограммировать предварительно. Для таких случаев эволюция придумала маленькую хитрость: способность к научению. В определенные периоды развития часть нервной системы приспосабливается к внешним ограничениям. Естественно, сам механизм научения является врожденным и в итоге управляется сложными генетическими алгоритмами. Таким образом, нет никакого противоречия в том, чтобы говорить о жестких механизмах обучения или даже об «инстинкте учиться», как однажды выразился Питер Марлер[239]. Старое противоречие между природой (наследственностью) и средой – это миф: все научение основывается на врожденных принципах, не поддающихся модификации.
Наиболее яркий пример пределов пластичности мозга – бинокулярное зрение, при котором информация, полученная от двух глаз, сливается воедино. Краткий период пластичности, длящийся несколько недель у кошек, несколько месяцев у приматов и несколько лет у людей, позволяет отрегулировать связи в первичной зрительной области. В этом случае пластичность используется для согласования зрительных карт: нейроны учатся объединять сигналы, поступающие от обоих глаз. В конце этого критического периода цепь фиксируется и впоследствии уже не меняется. У детей, страдающих косоглазием в раннем возрасте, нарушения зрения сохраняются на всю жизнь – они теряют способность воспринимать глубину из‑за небольшого расхождения между двумя изображениями (стереозрение). В этом случае природа оставила лишь очень короткий промежуток времени для развития.
Пластичность нижневисочной коры, благодаря которой мы учимся распознавать новые объекты, принципиально ничем не отличается. На всех уровнях зрительной системы наша кора заранее запрограммирована на поиск взаимосвязей в поступающих сенсорных данных и хранение полученных конфигураций. Идентичность объекта сохраняется в виде многочисленных комбинаций связей, возникающих в строго определенной совокупности нервных клеток. Вид огнетушителя, например, активирует несколько групп нейронов, которые кодируют тело, рукоятку, шланг, стандартный красный цвет и, вероятно, ряд других примитивных форм. Эта воспроизводимая комбинация активных нейронов затем сохраняется и фиксируется за счет увеличения силы синапсов, связывающих их в стабильную систему. В свою очередь, каждый из таких примитивов должен быть предварительно усвоен как совокупность элементарных признаков на более низком уровне. Таким образом, наша способность распознавать объекты в конечном счете основывается на пирамиде нейронов и иерархической схеме научения.
На вершине пирамиды возникает новая проблема. На этом уровне некоторые нейроны реагируют на несколько видов одного и того же объекта – например, на профиль лица, вид спереди или даже на имя человека (Дженнифер Энистон). Непонятно, как именно приобретается такая утонченная разновидность инвариантности. Научение на базе случайных совпадений больше не работает. Мы не можем просто взять и связать вместе нейроны, которые активны в данный конкретный момент, потому что никогда не видим все лицо и профиль одновременно (за исключением картин Пикассо).
В естественной среде различные виды одного объекта часто наблюдаются последовательно. Как один нейрон узнает, что все они соответствуют определенному объекту? Ясуси Миясита из Токийского университета описал вероятный нейронный механизм, который вполне м





