Анализ проводится по разработанной методике, приведенной выше.
1.Сформулировать цель анализа
Цель: проанализировать зависимость климатологических катастроф от факторов с помощью модели ADL.
2. Выбрать эндогенные и экзогенные параметры модели.
Эндогенные
Y1t- Климатологические катастрофы (экономический ущерб), Climatological Disasters, USD million
Экзогенные показатели:
Y1t-k- Климатологические катастрофы (экономический ущерб), Climatological Disasters, USD million
 - GDP, World, US$ Per Capita,
- GDP, World, US$ Per Capita,
 - Employed Population, World, 000 Unit,
- Employed Population, World, 000 Unit,
 - Economically Active Population, World, 000 Unit,
- Economically Active Population, World, 000 Unit,
 - Exports (fob) by Commodity + Imports (cif) by Commodity, World, USD million,
- Exports (fob) by Commodity + Imports (cif) by Commodity, World, USD million,
3. Рассчитать эндогенные и экзогенные параметры модели
Расчетные эндогенные и экзогенные параметры модели представляют собой среднегеометрическое показателей стран мира в год t. Расчет осуществляется в программе Excel.
4. Отобразить эндогенные и экзогенные параметры модели в таблицах
Эндогенные и экзогенные переменные представлены в таблице 1.1.1.
Таблица 1.1.1 – Параметры модели
|
| Y1
| X1-1
| X1-2
| X1-3
| X1-4
|
|
| 10 603,2
| 10 122,3
| 3 058 444,4
| 3 292 921,8
| 16 152 292,3
|
|
| 11 414,0
| 10 865,3
| 3 029 900,9
| 3 257 927,7
| 18 588 136,0
|
|
| 2 159,4
| 10 781,4
| 2 992 384,9
| 3 224 968,7
| 18 449 616,4
|
|
| 26 480,0
| 10 624,0
| 2 958 518,7
| 3 188 823,0
| 18 120 946,7
|
|
| 11 279,0
| 10 520,9
| 2 925 443,6
| 3 158 928,4
| 18 060 527,3
|
|
| 5 954,7
| 9 576,8
| 2 874 297,6
| 3 120 953,4
| 15 085 082,5
|
|
| 5 143,7
| 8 878,8
| 2 839 435,9
| 3 077 667,9
| 12 365 710,3
|
|
| 2 766,0
| 9 480,4
| 2 830 683,4
| 3 041 706,5
| 15 938 328,5
|
|
| 5 303,5
| 8 758,6
| 2 797 544,7
| 3 005 259,9
| 13 788 270,7
|
|
| 3 974,6
| 7 870,7
| 2 756 196,8
| 2 969 265,9
| 11 946 665,9
|
|
| 4 312,1
| 7 358,5
| 2 692 722,7
| 2 911 259,7
| 11 414 334,4
|
|
| 2 994,3
| 6 879,8
| 2 617 204,5
| 2 863 002,2
| 10 905 723,1
|
|
| 6 786,0
| 6 186,2
| 2 571 975,4
| 2 812 393,3
| 10 419 775,0
|
|
| 8 233,6
| 5 583,4
| 2 524 756,0
| 2 761 457,9
| 9 955 480,2
|
|
| 126,4
| 5 437,5
| 2 510 557,7
| 2 738 430,5
| 9 511 874,0
|
|
| 6 214,1
| 5 542,7
| 2 451 398,2
| 2 676 672,3
| 9 088 034,4
|
|
| 9 837,6
| 5 449,2
| 2 357 201,1
| 2 631 782,2
| 8 683 080,7
|
|
| 3 129,4
| 5 328,0
| 2 292 453,8
| 2 524 296,8
| 8 296 171,3
|
|
| 9 824,3
| 5 424,7
| 2 262 234,0
| 2 484 722,1
| 7 926 502,2
|
5. Осуществить проверку временных рядов на стационарность, используя тест Дики-Фуллера. В том случае, если ряд нестационарный, привести его к стационарному виду путем вычисления разностей.
Тест Дики-Фуллера представляет собой авторегрессионное уравнение вида:

где  — временной ряд, а
— временной ряд, а  — ошибка.
— ошибка.
Если  , то ряд стационарный. Если a=1, то процесс имеет единичный корень, в этом случае ряд не стационарен, является интегрированным временным рядом первого порядка.
, то ряд стационарный. Если a=1, то процесс имеет единичный корень, в этом случае ряд не стационарен, является интегрированным временным рядом первого порядка.
Тест Дики-Фуллера осуществляется решением авторегрессионного уравнения первого порядка в программе Excel. Ниже приведены результаты теста.
Таблица 1.1.2. – Исходные данные для теста Дики-Фуллера эндогенной переменной
|
| Y1
| Y1
|
|
| 10 603,2
| 11 414,0
|
|
| 11 414,0
| 2 159,4
|
|
| 2 159,4
| 26 480,0
|
|
| 26 480,0
| 11 279,0
|
|
| 11 279,0
| 5 954,7
|
|
| 5 954,7
| 5 143,7
|
|
| 5 143,7
| 2 766,0
|
|
| 2 766,0
| 5 303,5
|
|
| 5 303,5
| 3 974,6
|
|
| 3 974,6
| 4 312,1
|
|
| 4 312,1
| 2 994,3
|
|
| 2 994,3
| 6 786,0
|
|
| 6 786,0
| 8 233,6
|
|
| 8 233,6
| 126,4
|
|
| 126,4
| 6 214,1
|
|
| 6 214,1
| 9 837,6
|
|
| 9 837,6
| 3 129,4
|
|
| 3 129,4
| 0,0
|
Таблица 1.1.3 – Регрессионная статистика
| Множественный R
| 0,68176177
|
| R-квадрат
| 0,46479911
|
| Нормированный R-квадрат
| 0,42362981
|
| Стандартная ошибка
| 1,04245136
|
| Наблюдения
|
|
Таблица 1.1.4 – Дисперсионный анализ
|
| df
| SS
| MS
| F
| Значимость F
|
| Регрессия
|
| 15,7374176
| 15,7374176
| 13,8953163
| 0,00412078
|
| Остаток
|
| 14,1271628
| 0,88294767
|
|
|
| Итого
|
| 26,396
|
|
|
|
Таблица 1.1.5 – Коэффициенты регрессии
|
| Коэффициенты
| Стандартная ошибка
| t-статистика
| P-Значение
| Нижние 95%
| Верхние 95%
| Нижние 95,0%
| Верхние 95,0%
|
| Y-пересечение
| 8,57921245
| 7,46925748
| 1,14860312
| 0,27141568
| -7,55713729
| 24,7155622
| -7,5571373
| 24,7155622
|
| Переменная X 1
| 0,73926471
| 0,2200159
| 3,36005126
| 0,00512078
| 0,26394925
| 1,21458018
| 0,26394925
| 1,21458018
|
Согласно результатам, временной ряд является стационарным.
Таблица 1.1.6. – Исходные данные для теста Дики-Фуллера экзогенной переменной
|
| X1-1
| X1-1
|
|
| 10 122,3
| 10 865,3
|
|
| 10 865,3
| 10 781,4
|
|
| 10 781,4
| 10 624,0
|
|
| 10 624,0
| 10 520,9
|
|
| 10 520,9
| 9 576,8
|
|
| 9 576,8
| 8 878,8
|
|
| 8 878,8
| 9 480,4
|
|
| 9 480,4
| 8 758,6
|
|
| 8 758,6
| 7 870,7
|
|
| 7 870,7
| 7 358,5
|
|
| 7 358,5
| 6 879,8
|
|
| 6 879,8
| 6 186,2
|
|
| 6 186,2
| 5 583,4
|
|
| 5 583,4
| 5 437,5
|
|
| 5 437,5
| 5 542,7
|
|
| 5 542,7
| 5 449,2
|
|
| 5 449,2
| 5 328,0
|
|
| 5 328,0
| 0,0
|
Таблица 1.1.7 – Регрессионная статистика
| Множественный R
| 0,81811412
|
| R-квадрат
| 0,66931071
|
| Нормированный R-квадрат
| 0,60974206
|
| Стандартная ошибка
| 1,25094163
|
| Наблюдения
|
|
Таблица 1.1.8 – Дисперсионный анализ
|
| df
| SS
| MS
| F
| Значимость F
|
| Регрессия
|
| 30,56408646
| 30,56408646
| 32,3837869
| 0,00176816
|
| Остаток
|
| 16,95259536
| 1,05953721
|
|
|
| Итого
|
| 26,396
|
|
|
|
Таблица 1.1.9 – Коэффициенты регрессии
|
| Коэффициенты
| Стандартная ошибка
| t-статистика
| P-Значение
| Нижние 95%
| Верхние 95%
| Нижние 95,0%
| Верхние 95,0%
|
| Y-пересечение
| 10,2950549
| 8,963108973
| 1,378323745
| 0,32569882
| -9,0685648
| 29,65867463
| -9,068564751
| 29,6586746
|
| Переменная X 1
| 0,88711766
| 0,264019084
| 4,032061514
| 0,00176816
| 0,3167391
| 1,457496212
| 0,316739103
| 1,45749621
|
Согласно результатам, временной ряд является стационарным.
Таблица 1.1.10 – Исходные данные для теста Дики-Фуллера экзогенной переменной
|
| X1-2
| X1-2
|
|
| 3 058 444,4
| 3 029 900,9
|
|
| 3 029 900,9
| 2 992 384,9
|
|
| 2 992 384,9
| 2 958 518,7
|
|
| 2 958 518,7
| 2 925 443,6
|
|
| 2 925 443,6
| 2 874 297,6
|
|
| 2 874 297,6
| 2 839 435,9
|
|
| 2 839 435,9
| 2 830 683,4
|
|
| 2 830 683,4
| 2 797 544,7
|
|
| 2 797 544,7
| 2 756 196,8
|
|
| 2 756 196,8
| 2 692 722,7
|
|
| 2 692 722,7
| 2 617 204,5
|
|
| 2 617 204,5
| 2 571 975,4
|
|
| 2 571 975,4
| 2 524 756,0
|
|
| 2 524 756,0
| 2 510 557,7
|
|
| 2 510 557,7
| 2 451 398,2
|
|
| 2 451 398,2
| 2 357 201,1
|
|
| 2 357 201,1
| 2 292 453,8
|
|
| 2 292 453,8
| 0,0
|
Таблица 1.1.11 – Регрессионная статистика
| Множественный R
| 0,76357318
|
| R-квадрат
| 0,583044
|
| Нормированный R-квадрат
| 0,53115308
|
| Стандартная ошибка
| 1,16754552
|
| Наблюдения
|
|
Таблица 1.1.12 – Дисперсионный анализ
|
| df
| SS
| MS
| F
| Значимость F
|
| Регрессия
|
| 22,62445327
| 22,62445327
| 22,3733534
| 0,00255928
|
| Остаток
|
| 15,82242233
| 0,988901396
|
|
|
| Итого
|
| 29,56352
|
|
|
|
Таблица 1.1.13 – Коэффициенты регрессии
|
| Коэффициенты
| Стандартная ошибка
| t-статистика
| P-Значение
| Нижние 95%
| Верхние 95%
| Нижние 95,0%
| Верхние 95,0%
|
| Y-пересечение
| 9,60871794
| 8,365568375
| 1,286435495
| 0,30398556
| -8,4639938
| 27,68142965
| -8,463993768
| 27,6814297
|
| Переменная X 1
| 0,82797648
| 0,246417812
| 3,763257413
| 0,00255928
| 0,29562316
| 1,360329798
| 0,295623163
| 1,3603298
|
Согласно результатам, временной ряд является стационарным.
Таблица 1.1.14 – Исходные данные для теста Дики-Фуллера экзогенной переменной
|
| X1-3
| X1-3
|
|
| 3 292 921,8
| 3 257 927,7
|
|
| 3 257 927,7
| 3 224 968,7
|
|
| 3 224 968,7
| 3 188 823,0
|
|
| 3 188 823,0
| 3 158 928,4
|
|
| 3 158 928,4
| 3 120 953,4
|
|
| 3 120 953,4
| 3 077 667,9
|
|
| 3 077 667,9
| 3 041 706,5
|
|
| 3 041 706,5
| 3 005 259,9
|
|
| 3 005 259,9
| 2 969 265,9
|
|
| 2 969 265,9
| 2 911 259,7
|
|
| 2 911 259,7
| 2 863 002,2
|
|
| 2 863 002,2
| 2 812 393,3
|
|
| 2 812 393,3
| 2 761 457,9
|
|
| 2 761 457,9
| 2 738 430,5
|
|
| 2 738 430,5
| 2 676 672,3
|
|
| 2 676 672,3
| 2 631 782,2
|
|
| 2 631 782,2
| 2 524 296,8
|
|
| 2 524 296,8
| 0,0
|
Таблица 1.1.15 – Регрессионная статистика
| Множественный R
| 0,66812653
|
| R-квадрат
| 0,44639306
|
| Нормированный R-квадрат
| 0,40666408
|
| Стандартная ошибка
| 1,02160233
|
| Наблюдения
|
|
Таблица 1.1.16 – Дисперсионный анализ
|
| df
| SS
| MS
| F
| Значимость F
|
| Регрессия
|
| 14,90990412
| 14,90990412
| 12,9013719
| 0,00443826
|
| Остаток
|
| 13,84461954
| 0,865288721
|
|
|
| Итого
|
| 25,86808
|
|
|
|
Таблица 1.1.17 – Коэффициенты регрессии
|
| Коэффициенты
| Стандартная ошибка
| t-статистика
| P-Значение
| Нижние 95%
| Верхние 95%
| Нижние 95,0%
| Верхние 95,0%
|
| Y-пересечение
| 8,4076282
| 7,319872328
| 1,125631058
| 0,26598737
| -7,4059945
| 24,22125095
| -7,405994547
| 24,2212509
|
| Переменная X 1
| 0,72447942
| 0,215615586
| 3,292850236
| 0,00443826
| 0,25867027
| 1,190288573
| 0,258670267
| 1,19028857
|
Таблица 1.1.18 – Исходные данные для теста Дики-Фуллера экзогенной переменной
|
| X1-4
| X1-4
|
|
| 16 152 292,3
| 18 588 136,0
|
|
| 18 588 136,0
| 18 449 616,4
|
|
| 18 449 616,4
| 18 120 946,7
|
|
| 18 120 946,7
| 18 060 527,3
|
|
| 18 060 527,3
| 15 085 082,5
|
|
| 15 085 082,5
| 12 365 710,3
|
|
| 12 365 710,3
| 15 938 328,5
|
|
| 15 938 328,5
| 13 788 270,7
|
|
| 13 788 270,7
| 11 946 665,9
|
|
| 11 946 665,9
| 11 414 334,4
|
|
| 11 414 334,4
| 10 905 723,1
|
|
| 10 905 723,1
| 10 419 775,0
|
|
| 10 419 775,0
| 9 955 480,2
|
|
| 9 955 480,2
| 9 511 874,0
|
|
| 9 511 874,0
| 9 088 034,4
|
|
| 9 088 034,4
| 8 683 080,7
|
|
| 8 683 080,7
| 8 296 171,3
|
|
| 8 296 171,3
| 0,0
|
Таблица 1.1.19 – Регрессионная статистика
| Множественный R
| 0,78402603
|
| R-квадрат
| 0,61469682
|
| Нормированный R-квадрат
| 0,5599888
|
| Стандартная ошибка
| 1,19881906
|
| Наблюдения
|
|
Таблица 1.1.20 – Дисперсионный анализ
|
| df
| SS
| MS
| F
| Значимость F
|
| Регрессия
|
| 25,13885796
| 25,13885796
| 25,5257406
| 0,00224321
|
| Остаток
|
| 16,24623722
| 1,015389826
|
|
|
| Итого
|
| 30,3554
|
|
|
|
Таблица 1.1.21 – Коэффициенты регрессии
|
| Коэффициенты
| Стандартная ошибка
| t-статистика
| P-Значение
| Нижние 95%
| Верхние 95%
| Нижние 95,0%
| Верхние 95,0%
|
| Y-пересечение
| 9,86609432
| 8,589646099
| 1,320893589
| 0,31212803
| -8,6907079
| 28,42289652
| -8,690707887
| 28,4228965
|
| Переменная X 1
| 0,85015442
| 0,253018289
| 3,864058951
| 0,00224321
| 0,30354164
| 1,396767203
| 0,30354164
| 1,3967672
|
Согласно результатам, временной ряд является стационарным.
Согласно результатам теста Дики-Фуллера, все временные ряды являются стационарными.
5. Проверить экзогенные параметры на мультиколлинеарность. В случае если коэффициент попарной корреляции превышает 0,7, следует исключить из дальнейшего анализа одну переменную из пары.
Проверка проводится в программе Excel.
Таблица 1.1.22 – Коэффициенты корреляции экзогенных переменных
|
| X1-1
| X1-2
| X1-3
| X1-4
|
| X1-1
|
|
|
|
|
| X1-2
| 0,558199793
|
|
|
|
| X1-3
| 0,656480343
| 0,69825066
|
|
|
| X1-4
| 0,677570227
| 0,53762084
| 0,53653335
|
|
Все экзогенные параметры принимаются в дальнейший анализ.
6. Проверка коэффициентов парной корреляции на значимость с помощью t-критерия Стьюдента для показателей. Если tрасч≥tтабл, то полученные коэффициенты значимы т.е. выборка соответствует генеральной совокупности.
Для оценки значимости коэффициентов корреляции следует рассчитать t-критерий Стьюдента для каждой попарной корреляции по формуле:
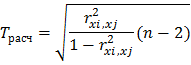
Результаты расчета представлены в таблице 1.1.28
Таблица 1.1.23 – Значения t-критерия Стьюдента для показателей
|
| X1-1
| X1-2
| X1-3
|
| X1-2
| 2,773892351
|
|
|
| X1-3
| 3,588204997
| 4,021719301
|
|
| X1-4
| 3,798576274
| 2,62891657
| 2,62144616
|
При уровне значимости α=0,05, числу степеней свободы n-2=17, 
Так как во всех случаях  , коэффициенты считаются значимыми.
, коэффициенты считаются значимыми.
7. Проверить автокорреляцию показателей. Выбрать те лаги, которые имеют сильную корреляционную связь со значением показателя в последнем периоде. Провести проверку значимости коэффициентов автокорреляции с помощью критерия Бокса – Пирсона или критерия Льюнга-Бокса.
Проверка значимости коэффициентов автокорреляции по Q-статистике Бокса-Пирса осуществляется по формуле:

Проверка значимости коэффициентов автокорреляции по Q-статистике Льюнга-Бокса осуществляется по формуле:

где n — число наблюдений,  — автокорреляция k-го порядка, и m — число проверяемых лагов.
— автокорреляция k-го порядка, и m — число проверяемых лагов.
Как по тесту Бокса-Пирса, так и по тесту Льюнга-Бокса, в случае если  , коэффициенты считаются значимыми.
, коэффициенты считаются значимыми.  определяется по таблице.
определяется по таблице.
Анализ автокорреляции осуществляется в программе Statistica. Результаты приведены ниже.
Таблица 1.1.24 – Коэффициенты автокорреляции эндогенной переменной.
| Авто-корр.
| Ст.Ошибка
| Бокса-Льюнга Q
| p
|
| 0,788097
| 0,212398
| 13,76766
| 0,000207
|
| 0,586880
| 0,206413
| 21,85158
| 0,000018
|
| 0,464307
| 0,200250
| 27,22764
| 0,000005
|
| 0,307873
| 0,193892
| 29,74894
| 0,000006
|
| 0,098481
| 0,187317
| 30,02534
| 0,000015
|
| -0,010493
| 0,180503
| 30,02872
| 0,000039
|
| -0,065857
| 0,173422
| 30,17293
| 0,000089
|
| -0,217354
| 0,166039
| 31,88655
| 0,000098
|
Так как более точной является Q-статистика Льюнга-Бокса, для анализа она является более предпочтительной. Анализ автокорреляции в программе Statistica помимо коэффициентов автокорреляции автоматически рассчитывает Q-статистику Льюнга-Бокса и значимость для каждого коэффициента (столбец 4 в табл.). Проверка значимости по Q-статистике Льюнга-Бокса равна 13,768 
Коэффициенты являются значимыми. Эндогенный параметр отражает зависимость от одного прошлого периода.
Таблица 1.1.25 – Коэффициенты автокорреляции экзогенной переменной
| Авто-корр.
| Ст.Ошибка
| Бокса-Льюнга Q
| p
|
| 0,058390
| 0,240906
| 0,058745
| 0,808491
|
| -0,097439
| 0,231455
| 0,235972
| 0,888709
|
| 0,072972
| 0,221601
| 0,344406
| 0,951471
|
| -0,020062
| 0,211289
| 0,353422
| 0,986109
|
| 0,106329
| 0,200446
| 0,634814
| 0,986353
|
| -0,117875
| 0,188982
| 1,023862
| 0,984690
|
| -0,025870
| 0,176777
| 1,045279
| 0,994064
|
| 0,097508
| 0,163663
| 1,400238
| 0,994242
|
Так как более точной является Q-статистика Льюнга-Бокса, для анализа она является более предпочтительной. Анализ автокорреляции в программе Statistica помимо коэффициентов автокорреляции автоматически рассчитывает Q-статистику Льюнга-Бокса и значимость для каждого коэффициента (столбец 4 в табл.). Проверка значимости по Q-статистике Льюнга-Бокса равна
Коэффициенты являются значимыми. Экзогенный параметр не отражает зависимость от прошлых периодов.
Таблица 1.1.26 – Коэффициенты автокорреляции экзогенной переменной
| Авто-корр.
| Ст.Ошибка
| Бокса-Льюнга Q
| p
|
| -0,209257
| 0,240906
| 0,754509
| 0,385059
|
| -0,227440
| 0,231455
| 1,720116
| 0,423147
|
| 0,197537
| 0,221601
| 2,514721
| 0,472647
|
| -0,267234
| 0,211289
| 4,114392
| 0,390764
|
| -0,186608
| 0,200446
| 4,981084
| 0,418212
|
| 0,228068
| 0,188982
| 6,437504
| 0,376029
|
| -0,140023
| 0,176777
| 7,064912
| 0,422176
|
| -0,074587
| 0,163663
| 7,272609
| 0,507542
|
Так как более точной является Q-статистика Льюнга-Бокса, для анализа она является более предпочтительной. Анализ автокорреляции в программе Statistica помимо коэффициентов автокорреляции автоматически рассчитывает Q-статистику Льюнга-Бокса и значимость для каждого коэффициента (столбец 4 в табл.). Проверка значимости по Q-статистике Льюнга-Бокса равна
Коэффициенты являются значимыми. Экзогенный параметр не отражает зависимость от прошлых периодов.
Таблица 1.1.27 – Коэффициенты автокорреляции экзогенной переменной
| Авто-корр.
| Ст.Ошибка
| Бокса-Льюнга Q
| p
|
| -0,039257
| 0,240906
| 0,026555
| 0,870553
|
| 0,135797
| 0,231455
| 0,370784
| 0,830779
|
| -0,162048
| 0,221601
| 0,905527
| 0,824094
|
| -0,174252
| 0,211289
| 1,585671
| 0,811363
|
| 0,178332
| 0,200446
| 2,377198
| 0,794861
|
| 0,132876
| 0,188982
| 2,871568
| 0,824779
|
| -0,059691
| 0,176777
| 2,985585
| 0,886324
|
| -0,112531
| 0,163663
| 3,458344
| 0,902388
|
Так как более точной является Q-статистика Льюнга-Бокса, для анализа она является более предпочтительной. Анализ автокорреляции в программе Statistica помимо коэффициентов автокорреляции автоматически рассчитывает Q-статистику Льюнга-Бокса и значимость для каждого коэффициента (столбец 4 в табл.). Проверка значимости по Q-статистике Льюнга-Бокса равна
Коэффициенты являются значимыми. Экзогенный параметр не отражает зависимость от прошлых периодов.
Таблица 1.1.28 – Коэффициенты автокорреляции экзогенной переменной
| Авто-корр.
| Ст.Ошибка
| Бокса-Льюнга Q
| p
|
| 0,535648
| 0,240906
| 4,94384
| 0,026191
|
| 0,405896
| 0,231455
| 8,01920
| 0,018150
|
| -0,177110
| 0,221601
| 8,65796
| 0,034218
|
| -0,287211
| 0,211289
| 10,50574
| 0,032737
|
| -0,527063
| 0,200446
| 17,41975
| 0,003775
|
| -0,361673
| 0,188982
| 21,08235
| 0,001777
|
| -0,343205
| 0,176777
| 24,85161
| 0,000809
|
| -0,058108
| 0,163663
| 24,97767
| 0,001573
|
Так как более точной является Q-статистика Льюнга-Бокса, для анализа она является более предпочтительной. Анализ автокорреляции в программе Statistica помимо коэффициентов автокорреляции автоматически рассчитывает Q-статистику Льюнга-Бокса и значимость для каждого коэффициента (столбец 4 в табл.). Проверка значимости по Q-статистике Льюнга-Бокса равна
Коэффициенты являются значимыми. Экзогенный параметр не отражает зависимость от прошлых периодов.
8. Построить модель ADL.
С учетом результатов предшествующих анализов, ADL-модель принимает вид:

9. Решить построенную модель регрессии для показателей. Найти коэффициенты модели, используя регрессионный анализ. Написать уравнение модели с найденными коэффициентами.
Регрессионный анализ осуществляется в программе Excel.
Таблица 1.1.29 – Регрессионная статистика
| Множественный R
| 0,987422669
|
| R-квадрат
| 0,975003527
|
| Нормированный R-квадрат
| 0,96964714
|
| Стандартная ошибка
| 370,0463062
|
| Наблюдения
|
|
Таблица 1.1.30 – Дисперсионный анализ
|
| df
| SS
| MS
| F
| Значимость F
|
| Регрессия
|
| 74776931,8
| 24925643,9
| 182,0263413
| 1,89482E-11
|
| Остаток
|
| 1917079,76
| 136934,269
|
|
|
| Итого
|
| 76694011,6
|
|
|
|
Таблица 1.1.31 – Коэффициенты регрессии
|
| Коэффициенты
| Стандартная ошибка
| t-статистика
| P-Значение
| Нижние 95%
| Верхние 95%
| Нижние 95,0%
| Верхние 95,0%
|
| Y-пересечение
| -7404,814458
| 2850,63781
| -2,5975992
| 0,021075573
| -13518,82449
| -1290,8044
| -13518,824
| -1290,804427
|
| Переменная X 1
| 0,001345574
| 0,00602619
| 0,22328774
| 0,826536747
| -0,011579312
| 0,01427046
| -0,0115793
| 0,014270459
|
| Переменная X 2
| 0,002486776
| 0,00614555
| 0,40464654
| 0,691852003
| -0,010694122
| 0,01566767
| -0,0106941
| 0,015667674
|
| Переменная X 3
| 0,000338087
| 6,9139E-05
| 4,88996614
| 0,000238728
| 0,000189799
| 0,00048638
| 0,0001898
| 0,000486375
|
| Переменная X 4
| 0,000154422
| 0,25301829
| 3,86405895
| 0,00224321
| 0,30354164
| 1,3967672
| 0,30354164
| 1,396767203
|
| Переменная X 5
| 0,000264715
| 0,2200159
| 3,36005126
| 0,005120784
| 0,263949252
| 1,21458018
| 0,26394925
| 1,214580177
|
Согласно результатам, уравнение записывается:
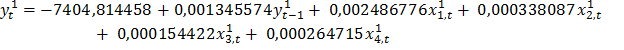
10. Проверить значимость регрессионной модели и коэффициентов регрессии. Проверить модели на достоверность с помощью F-критерия Фишера и коэффициента детерминации. Если Fр≥Fф, то построенная модель значима, т.е. выборка соответствует генеральной совокупности. Чем ближе коэффициент детерминации к 1, тем точнее модель, то есть коэффициент должен быть не менее 0,7 (R2≥0,7).
F-критерия Фишера рассчитывается по формуле:

где R - коэффициент корреляции;
f1 и f2 - число степеней свободы.
Первая дробь в уравнении равна отношению объясненной дисперсии к необъясненной. Каждая из этих дисперсий делится на свою степень свободы (вторая дробь в выражении). Число степеней свободы объясненной дисперсии f1 равно количеству объясняющих переменных линейной модели.
Число степеней свободы необъясненной дисперсии f2 = T-k-1, где T-количество временных периодов, k-количество объясняющих переменных.
Для проверки значимости уравнения регрессии вычисленное значение критерия Фишера сравнивают с табличным, взятым для числа степеней свободы f1 (бóльшая дисперсия) и f2 (меньшая дисперсия) на выбранном уровне значимости (обычно 0.05). Если рассчитанный критерий Фишера выше, чем табличный, то объясненная дисперсия существенно больше, чем необъясненная, и модель является значимой.
При осуществлении регрессионного анализа в программе Excel коэффициент детерминации и F-критерия Фишера рассчитывается автоматически. Коэффициент детерминации 0,975003527≥ 0,7, F-критерия Фишера 182,026, Fрасчетное ≥ Fтабличное, модель считается значимой.






