Параллельный вариант метода сеток при ленточном разделении данных состоит в обработке полос на всех имеющихся серверах одновременно в соответствии со следующей схемой работы:
Алгоритм 6.8 // схема Гаусса-Зейделя, ленточное разделение данных // действия, выполняемые на каждом процессоре do { // <обмен граничных строк полос с соседями> // <обработка полосы> // <вычисление общей погрешности вычислений dmax>} while (dmax > eps); // eps - точность решения
· ProcNum – номер процессора, на котором выполняются описываемые действия,
· PrevProc, NextProc – номера соседних процессоров, содержащих предшествующую и следующую полосы,
· NP – количество процессоров,
· M – количество строк в полосе (без учета продублированных граничных строк),
· N – количество внутренних узлов в строке сетки (т.е. всего в строке N+2 узла).
Для нумерации строк полосы будем использовать нумерацию, при которой строки 0 и M+1 есть продублированные из соседних полос граничные строки, а строки собственной полосы процессора имеют номера от 1 до M.
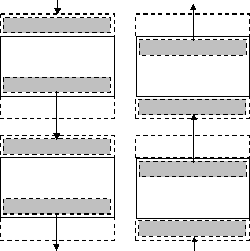
Рис. 6.11. Схема передачи граничных строк между соседними процессорами
Процедура обмена граничных строк между соседними процессорами может быть разделена на две последовательные операции, во время первой из которых каждый процессор передает свою нижнюю граничную строку следующему процессору и принимает такую же строку от предыдущего процессора (рис. 6.11). Вторая часть передачи строк выполняется в обратном направлении: процессоры передают свои верхние граничные строки своим предыдущим соседям и принимают переданные строки от следующих процессоров.
Выполнение подобных операций передачи данных в общем виде может быть представлено следующим образом (для краткости рассмотрим только первую часть процедуры обмена):
// передача нижней граничной строки следующему // процессору и прием передаваемой строки от // предыдущего процессора if (ProcNum!= NP-1)Send(u[M][*],N+2,NextProc); if (ProcNum!= 0)Receive(u[0][*],N+2,PrevProc);
(для записи процедур приема-передачи используется близкий к стандарту MPI [20] формат, где первый и второй параметры представляют пересылаемые данные и их объем, а третий параметр определяет адресат (для операции Send) или источник (для операции Receive) пересылки данных).
Для передачи данных могут быть задействованы два различных механизма. При первом из них выполнение программ, инициировавших операцию передачи, приостанавливается до полного завершения всех действий по пересылке данных (т.е. до момента получения процессором-адресатом всех передаваемых ему данных). Операции приема-передачи, реализуемые подобным образом называются синхронными или блокирующими. Иной подход – а синхронная или неблокирующая передача состоит в том, что операции приема-передачи только инициируют процесс пересылки и на этом завершают свое выполнение. В результате программы, не дожидаясь завершения длительных коммуникационных операций продолжают свои вычислительные действия, проверяя по мере необходимости готовность передаваемых данных. Оба варианта операций передачи используются при организации параллельных вычислений и имеют свои достоинства и недостатки. Синхронные процедуры передачи более просты для использования и более надежны; неблокирующие операции могут позволить совместить процессы передачи данных и вычислений, но приводят к повышению сложности программирования. Для организации пересылки данных будут использоваться операции приема-передачи блокирующего типа.
Последовательность блокирующих операций приема-передачи данных (вначале Send, затем Receive) приводит к строго последовательной схеме выполнения процесса пересылок строк, потому как все процессоры одновременно обращаются к операции Send и переходят в режим ожидания. Первым процессором, готовым к приему пересылаемых данных, будет сервер с номером NP-1, а процессор NP-2 выполнит операцию передачи своей граничной строки и перейдет к приему строки от процессора NP-3 и т.д. Общее количество повторений таких операций равно NP-1. Аналогично происходит выполнение и второй части процедуры пересылки граничных строк перед началом обработки строк (рис. 6.11).
Последовательный характер рассмотренных операций пересылок данных определяется выбранным способом очередности выполнения. Изменим этот порядок очередности при помощи чередования приема и передачи для процессоров с четными и нечетными номерами:
// передача нижней граничной строки следующему // процессору и прием передаваемой строки от // предыдущего процессора if (ProcNum % 2 == 1) { // нечетный процессор if (ProcNum!= NP-1)Send(u[M][*],N+2,NextProc); if (ProcNum!= 0)Receive(u[0][*],N+2,PrevProc); } else { // процессор с четным номером if (ProcNum!= 0)Receive(u[0][*],N+2,PrevProc); if (ProcNum!= NP-1)Send(u[M][*],N+2,NextProc); }
Данный прием позволяет выполнить все необходимые операции передачи всего за два последовательных шага. На первом шаге все процессоры с нечетными номерами отправляют данные, а процессоры с четными номерами осуществляют прием этих данных. На втором шаге роли процессоров меняются – четные процессоры выполняют Send, нечетные процессоры исполняют операцию приема Receive.
Рассмотренные последовательности операций приема-передачи для взаимодействия соседних процессоров широко используются в практике параллельных вычислений. Как результат, во многих базовых библиотеках параллельных программ имеются процедуры для поддержки подобных действий. Так, в стандарте MPI предусмотрена операция Sendrecv, с использованием которой предыдущий фрагмент программного кода может быть записан более кратко:
// передача нижней граничной строки следующему // процессору и прием передаваемой строки от // предыдущего процессора
Sendrecv (u[M][*],N+2,NextProc,u[0][*],N+2,PrevProc);
Реализация подобной объединенной функции Sendrecv обычно выполняется таким образом, чтобы обеспечить и корректную работу на крайних процессорах, когда не нужно выполнять одну из операций передачи или приема, и организацию чередования процедур передачи на процессорах для ухода от тупиковых ситуаций и возможности параллельного выполнения всех необходимых пересылок данных.






