Первый вариант параллельного алгоритма для метод сеток может быть получен, путем разрешения произвольного порядока пересчета значений 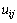 . Программа для данного способа может быть представлена так:
. Программа для данного способа может быть представлена так:
// Алгоритм 6.2 omp_lock_t dmax_lock; omp_init_lock (dmax_lock); do { dmax = 0; // максимальное изменение значений u
#pragma omp parallel for shared(u,n,dmax) private(i,temp,d) for (i=1; i<N+1; i++) {
#pragma omp parallel for shared(u,n,dmax) private(j,temp,d) for (j=1; j<N+1; j++) { temp = u[i][j]; u[i][j] = 0.25*(u[i-1][j]+u[i+1][j]+ u[i][j-1]+u[i][j+1]–h*h*f[i][j]); d = fabs(temp-u[i][j]);
omp_set_lock(dmax_lock); if (dmax < d) dmax = d;
omp_unset_lock(dmax_lock); } // конец вложенной параллельной области } // конец внешней параллельной области } while (dmax > eps);
Следует отметить, что программа получена из исходного последовательного кода путем добавления директив и операторов обращения к функциям библиотеки OpenMP (эти дополнительные строки в программе выделены темным шрифтом, обратная наклонная черта в конце директив означает продолжение директив на следующих строках программы).
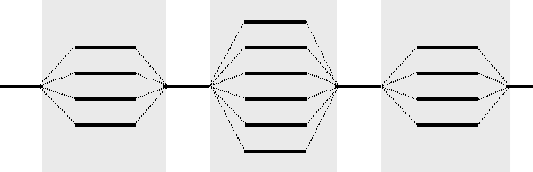
Рис. 6.3. Параллельные области, создаваемые директивами OpenMP
Параллельные области в данном примере задаются директивой parallel for, являются вложенными и включают в свой состав операторы цикла for. Компилятор с технологией OpenMP, разделяет выполнение итераций цикла между несколькими потоками программы, кол-во которых совпадает с числом процессоров в вычислительной системе. Параметры директивы shared и private определяют доступность данных в потоках программы – переменные, описанные как shared, являются общими для потоков, для переменных с описанием private создаются отдельные копии для каждого потока, которые могут использоваться в потоках независимо друг от друга.
Общие данные обеспечивает возможность взаимодействия потоков, а разделяемые переменные при этом могут рассматриваться как общие ресурсы потоков и их использование должно выполняться с соблюдением правил взаимоисключения. В данном примере таким разделяемым ресурсом является величина dmax, доступ потоков к которой регулируется специальной служебной переменной (семафором) dmax_lock и функциями omp_set_lock (разрешение или блокировка доступа) и omp_unset_lock (снятие запрета на доступ). Такая организация программы гарантирует единственность доступа потоков для изменения разделяемых данных; участки программного кода (блоки между обращениями к функциям omp_set_lock и omp_unset_lock), для которых обеспечивается взаимоисключение, обычно называются критическими секциями.
Данные вычислительных экспериментов представлены в табл. 6.1 (для параллельных программ, разработанных с использованием технологии OpenMP, использовался четырехпроцессорный сервер с процессорами Pentium III, 700 Mhz, 512 RAM).
Таблица 6.1. Результаты вычислительных экспериментов для параллельных вариантов алгоритма Гаусса-Зейделя (p =4)
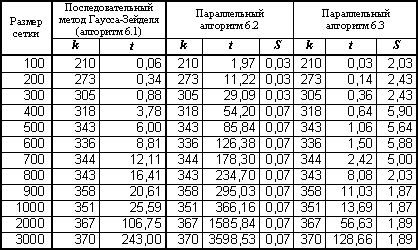
(k – количество итераций, t – время в сек., а S – это ускорение)
В результате, разработанный параллельный алгоритм является корректным, т.е. обеспечивающим решение поставленной задачи. Использованный при разработке подход обеспечивает получение практически максимально возможного параллелизма – для выполнения программы может быть задействовано вплоть до 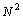 процессоров. Но все же результат не может быть признан удовлетворительным – программа будет работать медленно и ускорение вычислений от использования нескольких процессоров окажется не особо заметным. Основная причина – чрезмерно высокая синхронизация параллельных участков программы. Каждый параллельный поток после усреднения значений должен проверить значение величины dmax.
процессоров. Но все же результат не может быть признан удовлетворительным – программа будет работать медленно и ускорение вычислений от использования нескольких процессоров окажется не особо заметным. Основная причина – чрезмерно высокая синхронизация параллельных участков программы. Каждый параллельный поток после усреднения значений должен проверить значение величины dmax.
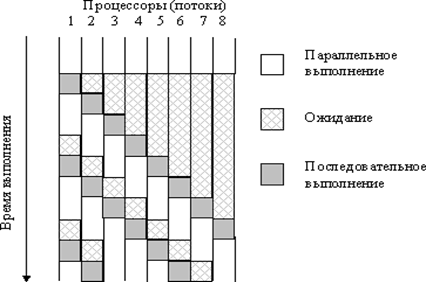
Рис. 6.4. Пример схемы выполнения параллельных потоков при наличии синхронизации (взаимоисключения)
Разрешение на использование переменной может получить только один поток, а все остальные потоки будут блокированы. После освобождения общей переменной управление может получить следующий поток и так далее. В результате необходимости синхронизации доступа многопотоковая параллельная программа превращается фактически в последовательно выполняемый код, причем менее эффективный, чем исходный последовательный вариант, т.к. организация синхронизации приводит к дополнительным вычислительным затратам(рис. 6.4).
Но, несмотря на идеальное распределение вычислительной нагрузки между процессорами, для приведенного на рис. 6.4 соотношения параллельных и последовательных вычислений, в каждый текущий момент времени (после момента первой синхронизации) только не более двух процессоров одновременно выполняют действия, связанные с решением задачи.
Сериализацией (serialization) называют эффект вырождения параллелизма из-за интенсивной синхронизации параллельных участков программы.
Для достижения эффективности параллельных вычислений используют уменьшение необходимых моментов синхронизации параллельных участков программы. Так мы можем ограничиться распараллеливанием только одного внешнего цикла for. Для снижения количества возможных блокировок применим многоуровневую схему расчета для оценки максимальной погрешности: пусть параллельно выполняемый поток первоначально формирует локальную оценку погрешности dm только для своих обрабатываемых данных, затем при завершении вычислений поток сравнивает свою оценку dm с общей оценкой погрешности dmax.
Вариант программы решения задачи Дирихле теперь имеет вид:
// Алгоритм 6.3 omp_lock_t dmax_lock; omp_init_lock(dmax_lock); do { dmax = 0; // максимальное изменение значений u
#pragma omp parallel for shared(u,n,dmax)\ private(i,temp,d,dm) for (i=1; i<N+1; i++) {
dm = 0; for (j=1; j<N+1; j++) { temp = u[i][j]; u[i][j] = 0.25*(u[i-1][j]+u[i+1][j]+ u[i][j-1]+u[i][j+1]–h*h*f[i][j]); d = fabs(temp-u[i][j])
if (dm < d) dm = d; } omp_set_lock(dmax_lock); if (dmax < dm) dmax = dm; omp_unset_lock(dmax_lock); } } // конец параллельной области } while (dmax > eps);
В результате выполненного изменения схемы вычислений, количество обращений к общей переменной dmax уменьшается с 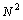 до
до 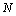 раз, что должно приводить к существенному снижению затрат на синхронизацию потоков и уменьшению проявления эффекта сериализации вычислений. Результаты экспериментов с данным вариантом параллельного алгоритма, приведенные в табл. 6.1, показывают существенное изменение ситуации – ускорение в ряде экспериментов оказывается даже большим, чем используемое количество процессоров (такой эффект сверхлинейного ускорения достигается за счет наличия у каждого из процессоров вычислительного сервера своей быстрой кэш памяти). Улучшение показателей параллельного алгоритма достигнуто при снижении максимально возможного параллелизма (для выполнения программы может использоваться не более процессоров).
раз, что должно приводить к существенному снижению затрат на синхронизацию потоков и уменьшению проявления эффекта сериализации вычислений. Результаты экспериментов с данным вариантом параллельного алгоритма, приведенные в табл. 6.1, показывают существенное изменение ситуации – ускорение в ряде экспериментов оказывается даже большим, чем используемое количество процессоров (такой эффект сверхлинейного ускорения достигается за счет наличия у каждого из процессоров вычислительного сервера своей быстрой кэш памяти). Улучшение показателей параллельного алгоритма достигнуто при снижении максимально возможного параллелизма (для выполнения программы может использоваться не более процессоров).





