В ранних системах с графическим пользовательским интерфейсом, та' ких как самый первый Macintosh, позиционная система извлечения имела определенный смысл. Она была продиктована метафорой рабо' чего стола (вы ведь не пользуетесь указателем при поиске бумажки на рабочем столе), а на дискете емкостью 144 Кбайт помещалось не так уж много документов. Современные настольные системы могут вме' щать в 500 000 раз больше документов (не говоря уже о том, что скры' то в недрах скромной локальной сети)! Тем не менее для управления этими данными мы все еще пользуемся старыми метафорами и преж' ней моделью извлечения. Мы продолжаем создавать программные системы извлечения данных в строгом соответствии с моделью реали' зации системы хранения, пренебрегая той мощью и простотой, кото' рыми могла бы обладать система для поиска файлов, отличная от сис' темы для их сохранения.
| |
| |  |
1 Теодор Джуда – американский инженер'железнодорожник, стоявший у ис' токов строительства Тихоокеанской железной дороги. – Примеч. ред.
Система, основанная на извлечении по атрибутам, позволила бы нам искать документы по содержимому и осмысленным свойствам (ска' жем, по времени последнего изменения). Назначение подобной систе' мы – дать пользователям механизм, позволяющий описывать предмет поиска естественным образом. Например, сотрудница отдела продаж, которой необходимо найти коммерческое предложение, недавно от' правленное клиенту «Widgetco», могла бы выразить свою мысль так:
«Покажи мне все документы в формате Word, связанные с Widgetco, которые я вчера редактировала или выводила на печать».
Качественная система извлечения по атрибутам позволяет пользовате' лям выполнять также поиск по синонимам, по смежным темам и по атрибутам или тегам (меткам), присвоенным отдельным документам. У пользователя появляется возможность динамически определять на' боры документов, имеющих общие атрибуты. Вернемся к нашему при' меру с сотрудницей отдела продаж. Предположим, она рассылает пись' ма с предложениями всем потенциальным клиентам. Каждое письмо является индивидуальным и при этом естественным образом объедине' но с файлами, относящимися к конкретному клиенту. Однако между этими письмами существует определенная связь, поскольку они слу' жат одной цели – предложению делового сотрудничества. Было бы удобно, если бы пользователь мог найти и собрать вместе все такие письма, сохранив уникальность каждого и его связь с соответствую' щим клиентом. Файловая система, жестко связанная с местоположе' нием – с единственным местом хранения, – вынуждена хранить доку' менты на основании единственного атрибута (клиент или тип доку' мента), а не набора характеристик.
Система может многое узнать о документе, если будет достаточно вни' мательна к нему. Если система поиска по атрибутам запомнит хотя бы часть этой информации, она облегчит ношу, лежащую на плечах поль' зователя. Например, программа могла бы легко запомнить следующее:
• приложение, создавшее документ;
• содержание и формат документа;
• последнее приложение, открывавшее документ;
• размер документа и то, является ли документ необычно маленьким или большим;
• лежал ли документ на протяжении долгого времени без движения;
• продолжительность последнего сеанса работы с документом;
• объем информации, добавленной или удаленной при последнем ре' дактировании;
• был ли документ создан с нуля или путем копирования другого до' кумента;
• часто ли документ редактируется;
• часто ли документ просматривается;
• был ли документ распечатан, и если да, то на каком устройстве;
• часто ли документ выводился на печать, и вносились ли в него из' менения каждый раз непосредственно перед печатью;
• отправлялся ли документ по факсу, и если да, то кому;
• отправлялся ли документ по электронной почте, и если да, то кому.
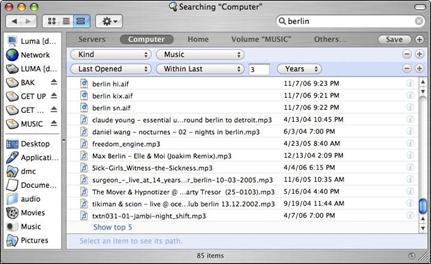
Spotlight – механизм поиска в операционной системе Apple Mac OS X – организует эффективную систему извлечения по атрибутам (рис. 15.1). Пользователь может не только искать документы по осмысленным свойствам, но и сохранять поисковые запросы в качестве «умных па' пок» (Smart Folders), позволяющих, в частности, видеть в одной папке все документы, относящиеся к одному конкретному клиенту, а в дру' гой – все коммерческие предложения (при этом Spotlight все же не в состоянии самостоятельно распознать коммерческие предложения, и пользователю придется приложить некоторые усилия, чтобы обозна' чить их). Следует заметить, что полезность Spotlight во многом опре' деляется скоростью получения результатов. Это важное отличие Spot' light от встроенного поиска Windows было реализовано с помощью специального технического решения, в котором содержимое жесткого диска индексируется системой во время простоя компьютера.
Система извлечения на основе атрибутов способна находить докумен' ты, не требуя от пользователя предварительных действий по организа' ции хранения документов, однако возможность помечать документы тегами или присваивать им атрибуты имеет значительную ценность.
Рис. 15.1. Spotlight, механизм поиска в Apple OS X, позволяет пользователям находить документы по осмысленным атрибутам, например по имени документа, его типу и дате последнего сеанса работы с ним
Она не только позволяет пользователям заполнять пробелы в тех слу' чаях, когда технология не способна самостоятельно выявить осмыс' ленные атрибуты, но дает также людям возможность де'факто опреде' лять организационные схемы исходя из того, как они осознают и ис' пользуют информацию. Механизм извлечения на основе таких меток часто называют «фолксономией» (то есть «народной таксономией»). Создание термина приписывается информационному архитектору То' масу Вандер Валу (Thomas Vander Wal). Фолксономии могут прино' сить особенно заметную пользу в социальных контекстах и совместной работе, где создают альтернативу глобальной таксономии, если неже' лательно или неудобно заставлять всех следовать ей и думать в терми' нах нормализованной лексики. Этот подход применяется в системах поиска информации таких проектов, как Flickr, del.icio.us и Library' Thing (рис. 15.2), где люди имеют возможность просматривать и нахо' дить документы (фотографии и гиперссылки соответственно) на осно' ве атрибутов, определенных самими пользователями.
| |
| | 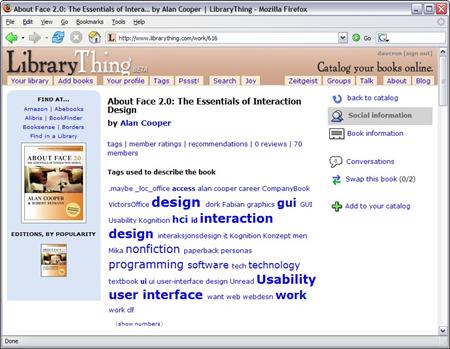 |
Рис. 15.2. LibraryThing – это веб-приложение, позволяющее пользователям вести каталоги своих книжных коллекций во Всемирной паутине с использо- ванием системы тегов. Применение тегов ко всем книгам всех коллекций создало демократичную систему организации, основанную на том,
как сообщество читателей описывает книги