Пункты теста могут различаться не только с точки зрения их сложности (одни пункты сложнее других), но и с точки зрения того, насколько они могут различать респондентов с высокими и низкими уровнями выраженности признака. Эта характеристика пунктов называется дискриминативной (различительной) способностью, или дискриминативностью пункта. Дискриминативность пункта в IRT аналогична корреляции пункта со шкалой (item-total correlation) из общей теории тестов (Embertson & Reise, 2000).
Показатель дискриминативности пункта означает его релевантность той характеристике (признаку), которую измеряет шкала. Положительное значение дискриминативности означает, что пункт имеет какое-то отношение к измеряемой характеристике, а относительно высокое значение (например, 3.5 по сравнению с 0.5) указывает на относительно сильную взаимосвязь пункта и измеряемой характеристики. Напротив, пункт с коэффициентом дискриминативности 0 не имеет никакого отношения к той характеристике, которая предположительно измеряется шкалой, а пункт с отрицательным значением дискриминативности относится к этой характеристике обратно-пропорционально (т.е. чем выше уровень выраженности признака, тем менее вероятно, что ответ на пункт будет правильным). Таким образом, обычно предпочитают добиваться высоких и положительных значений дискриминативности пунктов.
Почему у одних пунктов хорошая дискриминативная способность, а у других – нет? Рассмотрим следующие два задания (пункта) из гипотетического теста по математике:
- Сколько аршинов в трех саженях? (a) 9 (b) 18
- Каков квадратный корень из 10000? (a) 10 (b) 100
Задумайтесь над первым вопросом. Что необходимо респонденту для того, чтобы ответить на него правильно? Чтобы ответить на этот вопрос, ученику необходимо обладать математическими способностями, достаточными для выполнения умножения. Тем не менее, этот пункт требует также дополнительных знаний о том, сколько аршинов входит в одну сажень. Тот факт, что для правильного ответа на пункт требуется что-то еще помимо математических способностей, означает, что пункт не слишком сильно связан с измерением именно математических способностей. Другими словами, высокий уровень математических способностей недостаточен для правильного решения этого задания. Ученик может быть способен выполнить умножение 3 на 3, но шанс, что он ответит на вопрос правильно, может быть невысок в силу того, что он не знает, что в одной сажени три аршина. Таким образом, дискриминативность данного пункта будет низкой, а его взаимосвязь с тем признаком, на измерение которого нацелен математический тест, - слабой. Другими словами, этот пункт не слишком хорошо справляется с задачей различения учеников с относительно высоким и относительно низким уровнем математических способностей. Даже если Сьюзи решит задание правильно, а Джонни – нет, мы не можем с уверенность делать вывод о том, что Сьюзи разбирается в математике лучше, чем Джонни. Возможно, Джонни разбирается в математике, но просто не знает, сколько аршинов содержится в одной сажени.
Рассмотрим теперь второй вопрос. Что необходимо респонденту для того, чтобы правильно на него ответить? Требуется умение извлекать квадратный корень, но никаких дополнительных знаний или умений не требуется. Единственное качество ученика, которое имеет отношение к ответу на этот пункт, - это математические способности. В связи с этим данный вопрос более «чисто» математический, и он сильнее взаимосвязан с измеряемым признаком (математические способности), чем первый вопрос. Следовательно, у этого пункта, вероятно, будет высокий показатель дискриминативности. Другими словами, этот пункт лучше справляется с задачей различения учеников с относительно высоким и относительно низким уровнем математических способностей. Если Сьюзи ответит на вопрос правильно, а Джонни – неправильно, мы можем с достаточной степенью уверенности утверждать, что Сьюзи в математике сильнее, чем Джонни.
ИЗМЕРИТЕЛЬНЫЕ МОДЕЛИ IRT
В практике применения IRT-анализа определяются компоненты, влияющие на вероятность того, что респондент ответит на пункт каким-то определенным образом. Измерительная модель задает математические отношения между результатом (например, баллом, который респондент получает за пункт) и параметрами, которые оказывают влияние на этот результат (например, характеристиками самого респондента и/или характеристиками пункта теста).
В рамках IRT были разработаны разнообразные измерительные модели, которые отличаются друг от друга по крайней мере в двух немаловажных аспектах. Первое важное различие измерительных моделей заключается в тех характеристиках пункта, или параметрах, которые включаются в модель. Второе различие касается шкалы, в которой измеряется ответ респондента (результат).
Наиболее простая модель IRT зачастую называется моделью Раша, или однофакторной логистической моделью (1ФЛ). Согласно модели Раша, ответ респондента на бинарный пункт (т.е. правильно / неправильно, справился / не справился, согласен / не согласен) определяется уровнем выраженности измеряемого признака у респондента и уровнем сложности самого пункта. Модель Раша можно выразить в терминах вероятности того, что респондент с определенным уровнем выраженности признака правильно ответит на пункт с определенным уровнем сложности. Зачастую (например, Embertson & Reise, 2000) эту зависимость представляют как
 .
.
Это уравнение требует некоторых пояснений:
Xis означает ответ (X) респондента s на пункт i.
θs означает уровень выраженности признака у респондента s.
βi означает сложность пункта i.
Xis = 1 означает, что респондент дал «правильный» ответ на пункт или согласился с утверждением.
e – основание натурального логарифма (т.е. e = 2.7182818…), число, которое есть на многих калькуляторах.
Таким образом, P (X is = 1 | θs, βi) означает вероятность (P) того, что респондент s ответит на пункт i правильно. Вертикальная линия в данной записи означает, что это «условная» вероятность. Вероятность правильного ответа респондента на пункт обусловлена выраженностью у респондента признака (θs) и сложностью пункта (βi). В IRT-анализе выраженность признака и сложность пункта обычно выражаются в стандартизованной шкале, где среднее значение равняется 0, а стандартное отклонение 1. Рассмотрим следующие примеры с выполнением теста на математические способности:
1. Какова вероятность того, что респондент с относительно высоким уровнем математических способностей (скажем, с уровнем математических способностей, на одно стандартное отклонение превышающим средний, т.е. θs = 1) правильно ответит на пункт с относительно низким уровнем сложности (скажем, βi = - 0.5)?

Т.е. существует вероятность 0.82, что данный респондент правильно ответит на данный пункт. Другими словами, весьма вероятно (более чем на 80 %), что респондент решит эту математическую задачу. Это очевидно и с точки зрения здравого смысла, поскольку в нашем примере респондент с хорошими математическими способностями выполняет относительно простое математическое задание.
2. Какова вероятность того, что респондент с математическими способностями ниже среднего (скажем, с математическими способностями, на 1.39 стандартного отклонения ниже среднего уровня, т.е. θs = - 1.39) правильно решит относительно несложное (скажем, βi = -1.61) задание?

Как видим, вероятность правильного решения задания для этого респондента составляет 0.56. Другими словами, существует слегка превышающий «50 на 50» шанс того, что респондент решит задание правильно. Это понятно и интуитивно, поскольку выраженность признака у нашего респондента (θs = - 1.39) лишь слегка превышает уровень сложности задания (βi = - 1.61). Как вы помните, уровень сложности пункта представляет собой такой уровень выраженности признака, при котором у респондента существует 50-типроцентый шанс ответить на пункт правильно. Поскольку выраженность признака у респондента несколько выше, чем сложность пункта, вероятность правильного ответа несколько превышает 0.50.
Немного более сложная измерительная модель IRT носит название двухфакторной логистической модели (2ФЛ), поскольку она включает в себя два параметра пунктов теста. Согласно этой модели, ответ респондента на бинарный пункт определяется уровнем выраженности у респондента искомого признака, сложностью пункта и дискриминативностью пункта. От модели Раша данная измерительная модель отличается тем, что сюда включен параметр дискриминативности. Эту модель можно (напр., Embertson & Reise, 2000) выразить так:
 ,
,
где αi означает дискриминативность пункта i, при этом большие значения αi означают большую дискриминативную способность. Модель 2ФЛ предполагает, что вероятность правильного ответа респондента на пункт обусловлена уровнем выраженности признака (θs), а также сложностью (βi) и дискриминативностью (αi) пункта. Рассмотрим снова пункты «Сколько аршинов в трех саженях?» и «Каков квадратный корень из 10 000?». Предположим, что оба пункта имеют одинаковый уровень сложности (скажем, β = - 0.5). Предположим также (как обсуждалось выше), что у них разная дискриминативная способность (например, α1 = 0.5 и α2 = 2).
Какова вероятность того, что Сьюзи, обладая относительно хорошими математическими способностями (скажем, уровнем математических способностей, на одно стандартное отклонение превышающим средний, θ = 1), правильно ответит на вопрос 1?

А какова вероятность того, что на этот вопрос правильно ответит обладающий средними познаниями в математике (θ = 0) Джонни?
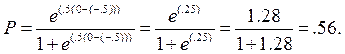
Заметьте разницу. В уровне математических способностей Сьюзи на одно стандартное отклонение опережает Джонни, однако ее шанс правильного ответа больше, чем у Джонни, всего на 0.12. Это относительно большая разница в уровне выраженности признака (одно стандартное отклонение) и относительно маленькая разница в вероятности правильного ответа на пункт.
Рассмотрим теперь вероятности того, что Сьюзи и Джонни правильно ответят на вопрос 2:
Сьюзи: 
Джонни: 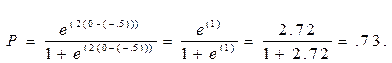
Заметьте разницу для этого вопроса. Для Сьюзи вероятность ответить на вопрос правильно составляет 0.95, для Джонни 0.73. Разница в математических способностях все еще составляет одно стандартное отклонение, но на этот раз шанс ответить на второй вопрос правильно у Сьюзи на 22 процента больше, чем у Джонни. Как видим, по сравнению с пунктом 1, пункт 2 (тот, у которого больше дискриминативность) более отчетливо различает респондентов с разными уровнями выраженности измеряемого признака.
Модель 2ФЛ является расширением модели Раша (т.е. 1ФЛ), однако существуют и другие модели, расширяющие уже 2ФЛ. Возможно, вы не удивитесь, услышав, что существует трехфакторная логистическая модель (3ФЛ), которая добавляет в число параметров еще одну характеристику пунктов. Воздержимся от обсуждения этой модели, отметим только, что третьим параметром является поправка на вероятность угадывания. В целом, 1ФЛ, 2ФЛ и 3ФЛ – это модели измерения в IRT, которые отличаются друг от друга количеством анализируемых параметров (характеристик пунктов). Как уже отмечалось, есть по крайней мере еще один аспект, по которому различные измерительные модели IRT отличаются друг от друга.
Второе различие между моделями IRT относится к шкале, в которой измеряется ответ респондента. До сих пор рассматривались модели (1ФЛ, 2ФЛ и 3ФЛ), предназначенные для бинарных (дихотомических) пунктов. Тем не менее, множество тестов и опросников в науках о поведении содержит пункты с более чем двумя вариантами ответов. Например, многие личностные опросники содержат самоочевидные утверждения (типа «Мне нравится общаться с друзьями») и предлагают респондентам три или более варианта ответа (например, совершенно не согласен, не согласен, нейтральный ответ, согласен, полностью согласен). Такие пункты известны как пункты с множественным выбором, и для них требуются другие измерительные модели IRT, отличные от тех, которые применяются для бинарных пунктов. Примерами IRT-моделей для пунктов с множественным выбором являются модель ранжированного ответа (graded response model, Samejima, 1969) и модель частично правильных ответов (partial credit model, Masters, 1982). Хотя эти модели отличаются тем, какие типы пунктов и шкал, в которых измеряется ответ респондента, они могут анализировать, все они основаны на тех же общих принципах, что и модели для бинарных пунктов. Все эти модели основаны на идее о том, что ответ респондента на пункт определяется уровнем выраженности у респондента измеряемого признака, а также характеристиками самого пункта, такими как сложность и дискриминативность.
ПРИМЕР ИЗ ОБЛАСТИ IRT: МОДЕЛЬ РАША
Вы можете поинтересоваться, как получить коэффициенты уровня выраженности признака и сложности пункта, которые используются в описанных выше уравнениях. В реальных прикладных исследованиях для этого почти всегда используются специальные статистические программы, анализирующие ответы респондентов на некий набор пунктов. Проводить анализы, основанные на теории IRT, позволяют такие программные пакеты, как PARSCALE, BILOG и MULTILOG, в настоящее время распространяемые компанией Scientific Software International[14]. Хотя ранние версии этих программ обладали не слишком дружественным интерфейсом, их последние модификации становятся все проще и удобнее в использовании. Тем не менее, пример относительно простого IRT-анализа, выполненного «от руки», позволит вам лучше понять процедуру вычисления и теорию IRT в целом.
В таблице 13.1 приведены (гипотетические) ответы шести респондентов на пять пунктов теста, измеряющего математические способности. В этой матрице данных правильные ответы обозначаются как 1, неправильные – 0. На практике обычно применяются куда большие наборы данных, с большим количеством респондентов и пунктов, однако мы используем этот упрощенный пример, чтобы продемонстрировать логику IRT-анализа как можно нагляднее.
Таблица 13.1. Сырые данные для примера IRT-анализа: гипотетический пятипунктовый тест на математические способности
| Респондент
| Пункт 1
| Пункт 2
| Пункт 3
| Пункт 4
| Пункт 5
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Важным этапом в анализе IRT является выбор подходящей измерительной модели. Заметьте, что ответы на пункты в данном примере выражены в бинарной шкале – правильно / неправильно. Поэтому пригодными для проведения анализа являются все измерительные модели, подходящие для анализа бинарных пунктов. Затем из всех таких моделей необходимо будет выбрать ту, в которой используются все интересующие исследователя параметры (характеристики) пунктов. Более сложная стратегия выбора предполагает количественную оценку того, какая из измерительных моделей «подходит» наилучшим образом, т.е. можно было бы провести анализы с использованием различных моделей, а затем определить, какую из них лучше применять для какого-либо конкретного набора данных. Для анализа приведенных данных, однако, выберем модель Раша (1ФЛ), поскольку она является простейшей.
На основе этих данных можно вычислить несколько коэффициентов. Модель Раша включает в себя два показателя, оказывающие влияние на то, как респондент отвечает на пункт – уровень выраженности искомого признака у респондента и уровень сложности самого пункта. Попробуем сначала получить всю необходимую информацию о респондентах и вычислим уровень выраженности признака для каждого из шести участников тестирования. После этого займемся вычислением сложности пунктов.
Таблица 13.2. Пример IRT-анализа: коэффициенты уровня выраженности признака и уровня сложности пунктов
| Респондент
| Пункт 1
| Пункт 2
| Пункт 3
| Пункт 4
| Пункт 5
| Доля правильных ответов
| Выраженность признака
|
|
|
|
|
|
|
| 0.20
| -1.39
|
|
|
|
|
|
|
| 0.60
| 0.41
|
|
|
|
|
|
|
| 0.60
| 0.41
|
|
|
|
|
|
|
| 0.60
| 0.41
|
|
|
|
|
|
|
| 0.80
| 1.39
|
|
|
|
|
|
|
| 0.20
| -1.39
|
| Доля правильных ответов
| 0.83
| 0.67
| 0.50
| 0.33
| 0.17
|
|
|
| Сложность
| -1.61
| -0.69
| 0.00
| 0.69
| 1.61
|
|
|
Вычисление уровня выраженности признака можно представить как двухэтапный процесс. Сначала для каждого из респондентов определяем долю правильных ответов. Доля правильных ответов респондента – это просто количество пунктов, на которые респондент дал правильный ответ, деленное на общее количество пунктов, на которые респондент ответил. Как показано в Таблице 13.1., респондент 5 правильно ответил на 4 пункта из 5 (4/5), поэтому доля правильных ответов этого респондента составляет 0.80. В Таблице 13.2 приведены доли правильных ответов для всех респондентов. Затем (на втором этапе) для определения уровней выраженности признака вычисляем натуральный логарифм отношения доли правильных ответов к доле неправильных ответов:
 ,
,
где Ps – доля правильных ответов респондента 5. Получается, что у респондента 5 довольно высокий уровень выраженности признака:
 .
.
Как видим, выраженность признака у респондента 5 почти на полтора стандартных отклонения превышает среднюю.
Вычисление уровня сложности пунктов также можно представить как двухэтапный процесс. Сперва определяем долю правильных ответов для каждого пункта. Доля правильных ответов на пункт – это количество респондентов, правильно ответивших на данный пункт, деленное на общее количество респондентов, которые на него отвечали. Например, на пункт 1 правильный ответ был дан пятью из шести респондентов, поэтому доля правильных ответов на пункт 1 составляет 5/6 = 0.83. В Таблице 13.2 приведены доли правильных ответов для всех пунктов. Для получения коэффициента сложности пунктов вычисляем натуральный логарифм отношения доли правильных ответов к доле неправильных ответов.
 ,
,
где Pi – доля правильных ответов на пункт i. Получается, что у пункта 1 довольно невысокий уровень сложности:
 .
.
Это означает, что даже для человека с относительно низким уровнем математических способностей (не более полутора стандартных отклонений ниже среднего) будет 50-процентная вероятность ответить на данный пункт правильно. В Таблице 13.2 приведены коэффициенты сложности всех пяти пунктов.
Таблица 13.2 содержит информацию относительно математических способностей респондентов и сложности пунктов. Эти результаты были получены с использованием приложения Microsoft Excel, а не в специализированном на IRT пакете программ. Специализированные программы (которыми и следует пользоваться для полноценного анализа IRT) проводят дополнительные вычисления и оценивают коэффициенты более точно. Эти дополнительные вычисления представляют собой итеративную (многократную) процедуру, в которой первоначальная оценка коэффициентов впоследствии уточняется в серии последовательных шагов до тех пор, пока не будет удовлетворяться заранее заданный математический критерий. Детальное описание такой процедуры выходит за пределы этой книги, однако итеративные процессы вычисления используются во многих методах многомерного статистического анализа.






