Будем рассматривать систему SMP (S ymmetric M ulti P rocessor – симметричный мультипроцессор), в которой каждый процессор взаимозаменим с другими процессорами, все процессоры имеют равный доступ ко всем модулям памяти[14] и всем устройствам ввода – вывода.
В основе самых простых мультипроцессоров лежит только одна шина (рис. а). Два или более процессоров и один или несколько модулей памяти используют для взаимодействия через одну и туже шину. Если процессору нужно считать слово из памяти, он сначала проверяет, свободна ли шина. Если шина свободна, процессор помещает адрес нужного слова на шину, устанавливает несколько сигналов управления и ждёт, когда память поместит на шину нужное слово.
Если шина занята, процессор просто ждёт, когда она освободится. При наличии двух или трёх процессоров доступ к шине вполне управляем, при наличии 32 и 64 процессоров возникают трудности. Производительность системы будет полностью ограничиваться пропускной способностью шины, а большинство процессоров будут простаивать большую часть времени.

Для решения этой проблемы следует добавить кэш-память к каждому процессору (рис. б). Кэш-память может находиться внутри микросхемы процессора, рядом с микросхемой процессора, на плате процессора. Допустимы комбинации этих вариантов. Поскольку теперь считывать слова можно из кэш-памяти, движения в шине будет меньше, и система сможет поддерживать большее количество процессоров.

Другим вариантом решения является разработка, в которой каждый процессор имеет не только кэш-память, но и свою локальную память, к которой он получает доступ через назначенную локальную шину (рис. в). Для оптимального использования такой конфигурации компилятор должен поместить в локальные модули памяти весь текст программы, цепочки, константы, другие данные, предназначенные только для чтения, стеки и локальные переменные. Общая разделённая память используется только для общих переменных. В большинстве случаев такое разумное размещение сильно сокращает количество данных, передаваемых по шине, и не требует активного вмешательства со стороны процессора.
6.4 Основные классы ВС
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
На рисунке 6.10 приведены классы параллельных вычислительных систем
Машины класса SIMD
Машины SIMD распадаются на две подгруппы, они используются для быстрого выполнения больших научных программ[15]. В первую подгруппу попадают многочисленные суперкомпьютеры и другие машины, которые оперируют векторами, выполняя одну и ту же операцию над каждым элементом вектора. Во вторую подгруппу попадают машины типа ILLIAC IV, в которых главный блок управления посылает команды нескольким независимым АЛУ.
В машинах данного класса реализуется параллелизм на уровне процессоров. Над одной задачей работают одновременно несколько процессоров, производительность удается улучшить в 50, 100 и более раз.
Матричный процессор состоит из большого числа сходных процессоров, которые выполняют одну и ту же последовательность команд применительно к разным наборам данных. Количество суммирующих устройств равно количеству элементов в массиве. Процессоры логически скомпонованы в матрицу и работают синхронно, то есть присутствует только один поток команд для всех. Матрица процессорных элементов конструктивно реализована на едином кристалле или на нескольких. Назначение матричных вычислительных систем - обработка больших массивов данных (во многом схоже с назначением векторных ВС). В основе матричных систем лежит матричный процессор (array processor), состоящий из регулярного массива процессорных элементов (ПЭ).

Данные процессоры выпускаются в незначительном количестве ввиду их узкой специализации и сложностях программирования.
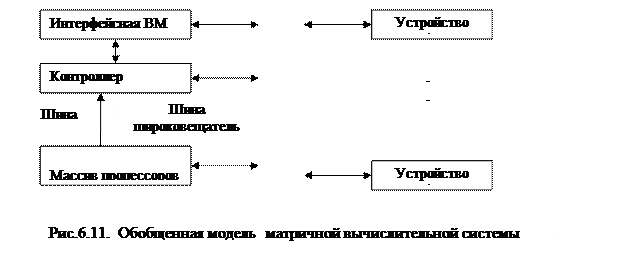
Структура матричной вычислительной системы представлена на рисунке 6.2.
Рассмотрим компоненты обобщенной модели матричной ВС:
· массив процессоров (МПр)осуществляет параллельную обработку множественных элементов данных;
· контроллер массива процессоров (КМП)генерирует единый поток команд, управляющий обработкой данных в массиве процессоров, выполняет последовательный программный код, реализует операции условного и безусловного переходов, транслирует в МПр команды, данные и сигналы управления. Команды обрабатываются процессорами в режиме жесткой синхронизации;
· сигналы управления используются для синхронизации команд и пересылок, а также для управления процессом вычислений, в частности определяют, какие процессоры массива должны выполнять операцию, а какие – нет;
· шина широковещательной рассылки служит для передачи команд, данных и сигналов управления из КМП в массив процессоров;
· шина результата служит для трансляции результатов вычислений из МПр в КМП (это требуется, поскольку выполнение операций условного перехода зависит от результатов вычислений);
· интерфейсная ВМ (front-end computer) служит для обеспечения пользователя удобным интерфейсом при создании и отладке программ. В роли такой ВМ выступает универсальная вычислительная машина, на которую дополнительно возлагается задача загрузки программ и данных в КМП. Кроме того, загрузка программ и данных в КМП может производиться и напрямую с устройств ввода/вывода, например с магнитных дисков. После загрузки КМП приступает к выполнению программы, транслируя в МПр по широковещательной шине соответствующие SIMD-команды.
Для хранения множественных наборов данных в нем, помимо множества процессоров, должно присутствовать и множество модулей памяти. Кроме того, в массиве должна быть реализована сеть взаимосвязей, как между процессорами, так и между процессорами и модулями памяти.
Таким образом, под термином массив процессоров понимают блок, состоящий из процессоров, модулей памяти и сети соединений. Дополнительную гибкость при работе с рассматриваемой системой обеспечивает механизм маскирования, позволяющий привлекать к участию в операциях лишь определенное подмножество из входящих в массив процессоров. Маскирование реализуется как на стадии компиляции, так и на этапе выполнения, при этом процессоры, исключенные путем установки в ноль соответствующих битов маски, во время выполнения команды простаивают.
Векторный процессор обеспечивает параллельное выполнение операций над массивами данных, векторами. Очень похож на матричный процессор, но все операции сложения выполняются в одном блоке суммирования, который имеет конвейерную структуру. Векторные процессоры можно добавлять к обычному процессору.
Векторные операции обеспечивают идеальную возможность полной загрузки вычислительного конвейера. При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений на векторной машине состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы.
Машины класса MIMD
Системы MIMD можно разделить на мультипроцессоры (машины с памятью совместного использования) и мультикомпьютеры[16] (машины с передачей сообщений). Мультипроцессор – это компьютерная система, которая содержит несколько процессоров и одно адресное пространство, видимое для всех процессоров. Он запускает одну копию операционной системы с одним набором таблиц, в том числе таблицами, которые следят, какие страницы памяти заняты, а какие свободны. Когда процесс блокируется, его процессор сохраняет своё состояние в таблицах операционной системы, а затем просматривает эти таблицы для нахождения другого процессора, который нужно запустить. Именно наличие одного отображения отличает мультипроцессора и мультикомпьютера.
Мультипроцессор, как и все компьютеры, должен содержать устройства ввода-вывода (диски, сетевые адаптеры и т. п.). В одних мультипроцессорных системах только определенные процессоры имеют доступ к устройствам ввода-вывода и, следовательно, имеют специальную функцию ввода-вывода. В других мультипроцессорных системах каждый процессор имеет доступ к любому устройству ввода-вывода. Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода и каждый процессор взаимозаменим с другими процессорами, то такая система называется SMP (Symmetric Multiprocessor — симметричный мультипроцессор).
В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу, но обычно используется второй вариант.
Существует три типа мультипроцессоров. Они отличаются друг от друга по способу реализации памяти совместного использования. Они называются UMA (Uniform Memory Access — архитектура с однородным доступом к памяти), NUMA (NonUniform Memory Access — архитектура с неоднородным доступом к памяти) и СОМА (Cache Only Memory Access — архитектура с доступом только к кэш-памяти).
UMA –это наиболее распространенная архитектура памяти параллельных ВС с общей памятью. В машинах UMА каждый процессор имеет одно и то же время доступа к любому модулю памяти. Иными словами, каждое слово памяти можно считать с той же скоростью, что и любое другое слово памяти. Если это технически невозможно, самые быстрые обращения замедляются, чтобы соответствовать самым медленным, поэтому программисты не увидят никакой разницы. Это и значит «однородный». Такая однородность делает производительность предсказуемой, а этот фактор очень важен для написания эффективной программы.
Технически UMA-системы предполагают наличие узла, соединяющего каждый из n процессоров с каждым из m модулей памяти. Простейший путь построения таких ВС - объединение нескольких процессоров (P) с единой памятью (Mp) посредством общей шины (рис.). В этом случае, однако, в каждый момент времени обмен по шине может вести только один из процессоров, то есть процессоры должны соперничать за доступ к шине. Когда процессор Рi, выбирает из памяти команду, остальные процессоры Pj (i< > j) должны ожидать, пока шина освободится. Если в систему входят только два процессора, они в состоянии работать с производительностью, близкой к максимальной, поскольку их доступ к шине можно чередовать: пока один процессор декодирует и выполняет команду, другой вправе использовать шину для выборки из памяти следующей команды. Однако когда добавляется третий процессор, производительность начинает падать.
. Производительность системы будет полностью ограничиваться пропускной способностью шины, а большинство процессоров будут простаивать большую часть времени.
| Рис.6.12. Рост производительности вычислений в зависимости от числа процессоров
| |

Для решения этой проблемы следует добавить кэш-память к каждому процессору (рис. б). Кэш-память может находиться внутри микросхемы процессора, рядом с микросхемой процессора, на плате процессора. Допустимы комбинации этих вариантов. Поскольку теперь считывать слова можно из кэш-памяти, движения в шине будет меньше, и система сможет поддерживать большее количество процессоров.
При наличии на шине десяти процессоров, кривая быстродействия шины становится горизонтальной, так что добавление 11-го процессора уже не дает повышения производительности. Нижняя кривая на рисунке иллюстрирует тот факт, что память и шина обладают фиксированной пропускной способностью, определяемой комбинацией длительности цикла памяти и протоколом шины, и в многопроцессорной системе с общей шиной эта пропускная способность распределена между несколькими процессорами./. Если длительность цикла процессора больше по сравнению с циклом памяти, к шине можно подключать много процессоров. Однако фактически процессор обычно намного быстрее памяти, поэтому данная схема широкого применения не находит./
Другим вариантом решения является разработка, в которой каждый процессор имеет не только кэш-память, но и свою локальную память, к которой он получает доступ через назначенную локальную шину (рис. в). Для оптимального использования такой конфигурации компилятор должен поместить в локальные модули памяти весь текст программы, цепочки, константы, другие данные, предназначенные только для чтения, стеки и локальные переменные. Общая разделённая память используется только для общих переменных. В большинстве случаев такое разумное размещение сильно сокращает количество данных, передаваемых по шине, и не требует активного вмешательства со стороны процессора.
Даже при всех возможных оптимизациях использование только одной шины ограничивает размер мультипроцессора UMA до 16 или 32 процессоров. Чтобы получить больший размер, требуется другой тип коммуникационной сети. Самая простая схема соединения n процессоров с n модулями памяти — координатный коммутатор. Координатные коммутаторы используются на протяжении многих десятилетий для соединения группы входящих линий с рядом выходящих линий произвольным образом.
Координатный коммутатор представляет собой неблокируемую сеть. Это значит, что процессор всегда будет связан с нужным модулем памяти, даже если какая-то линия или узел уже заняты. Более того, никакого предварительного планирования не требуется.
Недостаток системы: рост узлов как n 2. При наличии 1000 процессоров и 1000 модулей памяти получаем число узлов – 1 млн. Координатные коммутаторы используются для систем средних размеров.
В мультипроцессорах UMA с многоступенчатыми сетями коммутаторы (коммутатор содержит два входа и два выхода.) располагаются в несколько ступеней, обеспечивая параллельное выполнение запросов в модули памяти. Многоступенчатое расположение коммутаторов позволяет уменьшить количество коммутаторов, так для n процессоров и n модулей памяти количество коммутаторов составляет (n/2)log2n.
Размер мультипроцессоров UMA с одной шиной обычно ограничивается до нескольких десятков процессоров, а для координатных мультипроцессоров или мультипроцессоров с коммутаторами требуется дорогое аппаратное обеспечение, и они не намного больше по размеру. Чтобы получить более 100 процессоров, нужно что-то предпринять. Отметим, что все модули памяти имеют одинаковое время доступа.
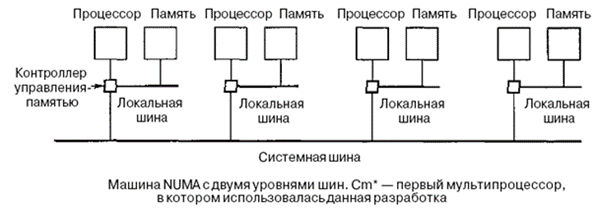
Для большей масштабируемости[17] мультипроцессоров приспособлена архитектура NUMA (NonUniform Memory Access — с неоднородным доступом к памяти). Как и мультипроцессоры UMA, они обеспечивают единое адресное пространство для всех процессоров, но, в отличие от машин UMA, доступ к локальным модулям памяти происходит быстрее, чем к удаленным модулям памяти.
Машины NUMA имеют три ключевые характеристики, которыми все они обладают и которые в совокупности отличают их от других мультипроцессоров:
· существует одно адресное пространство, видимое для всех процессоров;
· доступ к удаленной памяти производится с использованием команд LOAD и STORE;
· доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти. Доступ процессора к собственной локальной памяти производится напрямую, что намного быстрее, чем доступ к удаленной памяти через коммутатор или сеть.
В рамках концепции NUMA реализуется несколько различных подходов, обозначаемых аббревиатурами СОМА, cc-numa и nc-numa.
Особенности COMA:
· локальная память каждого процессора рассматривается как кэш для доступа «своего» процессора;
· кэш-память всех процессоров рассматриваются как глобальная память системы, а сама глобальная память отсутствует;
· данные не привязаны к конкретному модулю памяти и не имеют уникального адреса, остающегося неизменным в течение всего времени существования переменной;
· данные переносятся в кэш-память того процессора, который последним их запросил. Перенос данных из одного локального кэша в другой не требует участия в этом процессе операционной системы, но подразумевает сложную и дорогостоящую аппаратуру управления памятью.
Достоинство - всегда единственная копия данных в быстрой локальной кэш-память.
Недостаток - если данные требуются нескольким процессорам, то строка кэш-памяти с данными должна перемещаться туда и обратно при каждом доступе к данным.
Особенности NC-NUMA (No Caching NUMA- NUMA без кэширования)
· отсутствует кэш-память, это значит, что память гарантированно согласованна;
· каждое слово памяти находится только в одном месте, нет копий;
· от того, в какой памяти находится слово, зависит производительность;
· имеется страничный сканер, который может перемещать страницы памяти между блоками памяти в зависимости от статистики.
Недостаток - низкая расширяемость.
Особенности CC-NUMA (Cache Coherent Non-Uniform Memory Architecture)
· наличие кэш-памяти у процессоров.
· совместимость кэш-памяти на программном или аппаратном уровне.
Способы обеспечения совместимости кэш-память:
· отслеживание системной шины (низкая масштабируемость, простота технической реализации);
· использование каталога (хранение БД кэш-строк в высокоскоростном специализированном аппаратном обеспечении)
Во вторую подкатегорию машин MIMD попадают мультикомпьютеры, которые в отличие от мультипроцессоров не имеют памяти совместного использования на архитектурном уровне. Другими словами, операционная система в процессоре мультикомпьютера не может получить доступ к памяти, относящейся к другому процессору, просто путем выполнения команды LOAD. Ему приходится отправлять сообщение и ждать ответа. Именно способность операционной системы считывать слово из отдаленного модуля памяти с помощью команды LOAD отличает мультипроцессоры от мультикомпьютеров. Как мы уже говорили, даже в мультикомпьютере пользовательские программы могут обращаться к другим модулям памяти с помощью команд LOAD и STORE, но эту иллюзию создает операционная система, а не аппаратное обеспечение. Разница незначительна, но очень важна. Так как мультикомпьютеры не имеют прямого доступа к отдаленным модулям памяти, они иногда называются машинами NORMA (NO Remote Memory Access — без доступа к отдаленным модулям памяти).
В мультикомпьютере для взаимодействия между процессорами часто используются примитивы send и receive. Поэтому программное обеспечение мультикомпьютера имеет более сложную структуру, чем программное обеспечение мультипроцессора. При этом основной проблемой становится правильное разделение данных и разумное их размещение. В мультипроцессоре размещение частей не влияет на правильность выполнения задачи, хотя может повлиять на производительность.
Построение большого мультикомпьютера обходится значительно дешевле и гораздо проще, чем мультипроцессора с таким же количеством процессоров. Реализация общей памяти, разделяемой несколькими сотнями процессоров, является весьма сложной задачей, а построить мультикомпьютер, содержащий 10000 процессоров и более, сравнительно легко.
Мультикомпьютеры можно разделить на две категории. Первая категория содержит процессоры МРР (Massively Parallel Processors — процессоры с массовым параллелизмом) — дорогостоящие суперкомпьютеры, которые состоят из большого количества процессоров, связанных высокоскоростной коммуникационной сетью. В качестве примеров можно назвать Cray T3E и IBM SP/2.
Процессоры MPP относятся к кластерной системе (способ соединения процессоров друг с другом). Критическим параметром, влияющим на величину производительности такой системы, является расстояние между процессорами. Соединив вместе 8 персональных компьютеров, получим систему для проведения высокопроизводительных вычислений, проблема будет состоять в нахождении наиболее эффективного способа соединения стандартных средств друг с другом, поскольку при увеличении производительности каждого процессора в 8 раз производительность системы в целом в 8 раз не увеличится.
Пусть имеется 8 равноправных процессоров, соединенных с помощью общей шины (рис. 6., а). Если P бит/с – пропускная способность шины, то пропускная способность каждого процессора составит P/ 8 бит/с. Такая система не будет расширяемой.
При тех же действиях с топологией типа решетки (рис. 6., б) соотношение числа каналов к количеству процессоров будет соответственно 1,4 (12 процессоров 17 каналов).
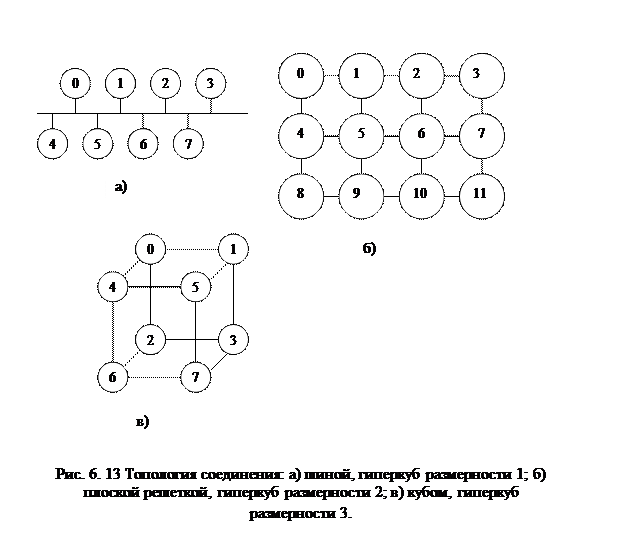
При таком типе соединения максимальное расстояние между процессорами окажется равным 5 (количество связей между процессорами, отделяющих самый ближний процессор от самого дальнего). Теория же показывает, что если в системе максимальное расстояние между процессорами больше 4, то такая система не может работать эффективно. Поэтому, при соединении 12 процессоров друг с другом плоская схема является не эффективной. Для получения более компактной конфигурации необходимо решить задачу о нахождении фигуры, имеющей максимальный объем при минимальной площади поверхности. В трехмерном пространстве таким свойством обладает шар. Но поскольку нам необходимо построить узловую систему, то вместо шара приходится использовать куб (если число процессоров равно 8) или гиперкуб, если число процессоров больше 8. Размерность гиперкуба будет определяться в зависимости от числа процессоров, которые необходимо соединить. Так, для соединения 16 процессоров потребуется 4-х мерный гиперкуб. Для его построения следует взять обычный 3-х мерный куб, сдвинуть в еще одном направлении и, соединив вершины, получить гиперкуб размером 4.
Гиперкуб представляет собой архитектуру с большим числом процессоров (2 n),связанных в систему таким образом, что каждый из них можно представить одной из вершин n – мерного двоичного гиперкуба. Архитектура отличается регулярностью и простотой. Каждый процессор связан только с n другими соседними, и при этом переход между любой парой процессоров не более чем через n ребер. Максимальный кратчайший путь между вершинами имеет всего log2n ребер.
Вторая категория мультикомпьютеров включает рабочие станции, которые связываются с помощью уже имеющейся технологии соединения. Эти примитивные машины называются NOW (Network of Workstations — сеть рабочих станций) и COW (ClusterofWorkstattions — кластер рабочих станций).





