Безусловно, следует сравнить архиваторы как по силе сжатия, так и по скорости работы и по расходам памяти.
Сравнение будет производиться с архиваторами, использующими LZ77 и метод Хаффман (сокращенно LZHuf). Эти архиваторы получили наибольшее применение еще со времен, когда компьютеры не имели мощности и объема памяти, достаточных для того, чтобы пользователям компьютеров были привлекательны более изощренные методы. В качестве представителей можно назвать PKZIP, WinZIP, 7ZIP, RAR, АСЕ, CABARC, ARJ, JAR.
Также стоит сравнить с архиваторами, использующими метод РРМ (Prediction by Partial Matching) – частичные совпадения. Среди них - НА, RK (а также RKUC, RKIVE), BOA, PPMD.
Скорость сжатия - на уровне архиваторов, применяющих LZHuf Хаффмана, а на больших словарях (от 1Mb) - и быстрее. У сжимателя, использующего преобразование Шиндлера, SZIP, скорость сжатия для малых порядков еще выше.
Скорость разжатия у архиваторов, использующих BWT, в 3-4 раза быстрее сжатия. В целом, классические LZHuf разжимают, конечно, быстрее.
Степень сжатия сильно зависит от типа сжимаемых данных. Наиболее эффективно использование BWT для текстов и любых потоков данных со стабильными контекстами. В этом случае рассматриваемые компрессоры по своим характеристикам близки к РРМ-сжимателям при, как правило, большей скорости.
На неоднородных данных известные BWT-архиваторы заметно уступают по сжатию лучшим современным сжимателям на LZHuf и чуть не дотягивают до результатов, показываемых представителям РРМ-сжатия. Впрочем, есть способы сильно увеличить сжатие неоднородных файлов. Такие уловки пока не используются в связке с BWT, возможно, из-за сравнительно молодого возраста последнего.
Расходы памяти при сжатии довольно близки у всех рассматриваемых методов и могут колебаться в больших пределах. Если не рассматривать специфические экономные реализации - LZHuf с маленьким словарем, РРМ с малым числом контекстов и BWT с кластерной сортировкой, то основные различия в требованиях к памяти наблюдаются при декодировании. Наиболее скромными в этом отношении являются архиваторы, и чльзующие LZHuf. РРМ'ы памяти требуют столько же, сколько же и при сжатии. Промежуточное положение занимают BWT-компрессоры.
Глава 5. Теория сжатия графической информации.
Введение.
Еще одна очень важная трактовка набора из нулей и единиц – это кодирование геометрического изображения. Двухцветная картинка (будем по традиции говорить о черно-белой картинке – черный рисунок на белом фоне) может трактоваться как растр – совокупность отдельных точек, расставленных на прямоугольной решетке. Сопоставляя черным точкам единицы, а белым – нули, мы и кодируем таблицу в виде нулей и единиц. Затем таблицу можно “вытянуть” в одну линию, соединяя ее строки и столбцы.
Пример[5]: Рассмотрим решетку 16x16 и картинку на ней, изображенные на рис. 10. Кодируя столбцы числами в диапазоне 0:216-1, получаем вектор, который удобнее представить в шестнадцатеричной системе:
0000, 0000, 1800, 2С00, 2604, 7208, 4208, 4605,
2В83, 3С7С, 0C08, 0030, 0020, 0010, 0000, 0000.
Возможность точечного рисования картинок широко используется в вычислительной технике и в обработке изображений. Например, экран дисплея рассматривается как растр, в котором (условно, для какой-то конкретной модели) 960 строк по 1280 точек в каждой, т.е. в общем сложности 1 228 800 точек. Для сохранения такого набора нужно (по 8 точек в одном байте) 150 Кбайтов.
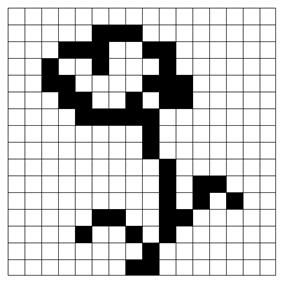
Рис. 10.
Поскольку любой рисунок может быть представлен как некоторая строка символов, к данной строке может быть применен любой из рассмотренных методов сжатия текстовой информации. Наряду с этими методами существует ряд методов, применимых исключительно к графической информации.
Рассмотрим два основных понятия.
1. Сжатие без потерь: пусть изображение I задано как множество атрибутов пикселей, пусть после применения к I алгоритма A мы получили набор данных I 1, тогда существует алгоритм A‑1: 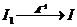 . Т.е. можно реконструировать I. (Сжатие без потерь применяется в PCX, PING, GIF, …)
. Т.е. можно реконструировать I. (Сжатие без потерь применяется в PCX, PING, GIF, …)
2. Сжатие с потерями, т.е. 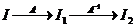 , где
, где 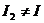 . При этом возникает вопрос, насколько велико визуальное отличие I 2от I, и как его оценивать. (JPEG)
. При этом возникает вопрос, насколько велико визуальное отличие I 2от I, и как его оценивать. (JPEG)
Утверждение. Не существует алгоритма, который сжимал бы без потерь любой набор данных.
Одна из серьезных проблем машинной графики заключается в том, что до сих пор не найден адекватный критерий оценки потерь качества изображения. А теряется оно постоянно — при оцифровке, при переводе в ограниченную палитру цветов, при переводе в другую систему цветопредставления для печати, и, что для нас особенно важно, при архивации с потерями. Можно привести пример простого критерия: среднеквадратичное отклонение значений пикселов (L2 мера, или root mean square — RMS):
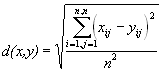
По нему изображение будет сильно испорчено при понижении яркости всего на 5% (глаз этого не заметит — у разных мониторов настройка яркости варьируется гораздо сильнее). В то же время изображения со “снегом” — резким изменением цвета отдельных точек, слабыми полосами или “муаром” будут признаны “почти не изменившимися”. Свои неприятные стороны есть и у других критериев.
Рассмотрим, например, максимальное отклонение:
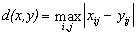
Эта мера, как можно догадаться, крайне чувствительна к биению отдельных пикселов. Т.е. во всем изображении может существенно измениться только значение одного пиксела (что практически незаметно для глаза), однако согласно этой мере изображение будет сильно испорчено.
Мера, которую сейчас используют на практике, называется мерой отношения сигнала к шуму (peak-to-peak signal-to-noise ratio — PSNR).

Данная мера, по сути, аналогична среднеквадратичному отклонению, однако пользоваться ей несколько удобнее за счет логарифмического масштаба шкалы. Ей присущи те же недостатки, что и среднеквадратичному отклонению.
Лучше всего потери качества изображений оценивают наши глаза. Отличной считается архивация, при которой невозможно на глаз различить первоначальное и разархивированное изображения. Хорошей — когда сказать, какое из изображений подвергалось архивации, можно только сравнивая две находящихся рядом картинки. При дальнейшем увеличении степени сжатия, как правило, становятся заметны побочные эффекты, характерные для данного алгоритма. На практике, даже при отличном сохранении качества, в изображение могут быть внесены регулярные специфические изменения. Поэтому алгоритмы архивации с потерями не рекомендуется использовать при сжатии изображений, которые в дальнейшем собираются либо печатать с высоким качеством, либо обрабатывать программами распознавания образов. Неприятные эффекты с такими изображениями, как мы уже говорили, могут возникнуть даже при простом масштабировании изображения.
RLE-метод.
RLE — битовый уровень
Рассмотрим черно-белое изображение, на входе — последовательность битов, где 0 и 1 чередуются (все изображение разбивается на строки, которые выстраиваются друг за другом). Подряд обычно идет несколько 0 или 1, и можно помнить лишь количество идущих подряд одинаковых цифр. Т.е. последовательности
0000 11111 000 11111111111
соответствует набор чисел 4 5 3 11. Возникает следующий нюанс: числа, соответствующие входной последовательности, также надо кодировать битами. Можно считать, что каждое число изменяется от 0 до 7, тогда последовательности 11111111111 можно сопоставить, например, числа 7 0 4, т.е. 7 единиц, 0 нулей, 4 единицы.
Идея этого метода используется при передаче факсов.
RLE — байтовый уровень
Предположим, что на вход подается полутоновое изображение, где на цвет пикселя отводится 1 байт. Ясно, что по сравнению с черно-белым растром ожидание длинной цепочки одинаковых битов существенно снижается.
Будем разбивать входной поток на байты (буквы) и кодировать повторяющиеся буквы парой (счетчик, буква).
Т.е. AABBBCDAA кодируем (2A) (3B) (1C) (1D) (2A). Однако могут быть длинные отрезки данных, где ничего не повторяется, а мы кодируем каждую букву парой цифра-буква.
Пусть у нас есть фиксированное число M (от 0 до 255). Тогда одиночную букву 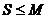 можно закодировать ею самою — выход = S, одиночную букву от M до 255 — парой (1S), причем, если надо сказать, что подряд несколько букв S, то выход = CS, где
можно закодировать ею самою — выход = S, одиночную букву от M до 255 — парой (1S), причем, если надо сказать, что подряд несколько букв S, то выход = CS, где  , а
, а  — количество идущих подряд букв S. Тогда алгоритм декодирования будет выглядеть так:
— количество идущих подряд букв S. Тогда алгоритм декодирования будет выглядеть так:
Алгоритм декодирования
C = считать следующий символ.
если (C > M) то
C-M — счетчик,
следующий в последовательности — символ,
который надо повторить C-M раз
иначе
C — символ, надо вывести C
конец алгоритма
Встает вопрос, как выбрать M.
В PCX считается, если первые два бита — 11, то остальное — счетчик.
Кроме как в PCX, этот алгоритм используется также в JPG.
Легко представить пример, когда изложенные алгоритмы не приводят к уменьшению объема информации. Например, камера слежения, где из-за различных наводок возникает много шумов, следовательно, одинаковые подряд идущие биты редки.
5.2. Волновой метод (wavelet-метод)
Описание метода
Данный алгоритм является рекурсивным алгоритмом сжатия. На русский язык wavelet переводится как волновое сжатие или как сжатие с использованием всплесков. Этот вид архивации известен довольно давно и напрямую исходит из идеи использования когерентности областей. Ориентирован алгоритм на цветные и черно-белые изображения с плавными переходами. Идеален для картинок типа рентгеновских снимков. Коэффициент сжатия задается и варьируется в пределах 5-100. При попытке задать больший коэффициент на резких границах, особенно проходящих по диагонали, проявляется “лестничный эффект” — ступеньки разной яркости размером в несколько пикселов.
Обоснование метода заключается в использовании локального всплеска (см. рис. 11) вместо глобально-периодических функций, т.е. таких функций 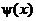 , что:
, что:
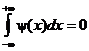 и
и  , при
, при 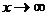 .
.
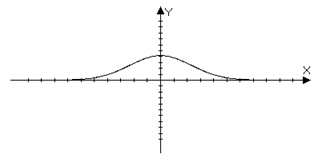
Рисунок 11. Пример локального всплеска.
Рассмотрим пример таких функций - систему Хаара. В общем виде она записывается так:

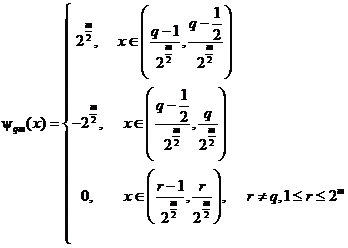
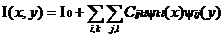 - общий вид обратного
- общий вид обратного
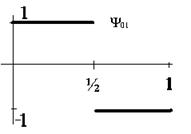

Если преобразование применяется к строке то так (здесь рассматриваем функцию  , которая определена на отрезке от 0 до 1, который разбит на
, которая определена на отрезке от 0 до 1, который разбит на 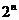 частей, см. рис. 12):
частей, см. рис. 12):
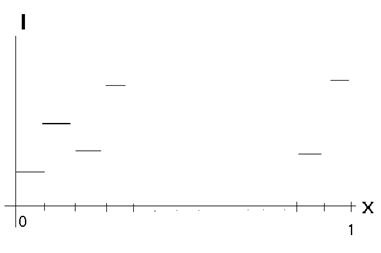
Рисунок 12. Строка изображения

Получается, что мы берём на каждом шаге некоторое среднее значение функции в точке.
Пусть 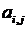 - величина яркости точки (i,j). Идея алгоритма заключается в том, что мы сохраняем в файл разницу — число между средними значениями соседних блоков в изображении, которая обычно принимает значения, близкие к 0. Нетрудно видеть, что расчетные формулы в случае двухмерного изображения будут иметь вид:
- величина яркости точки (i,j). Идея алгоритма заключается в том, что мы сохраняем в файл разницу — число между средними значениями соседних блоков в изображении, которая обычно принимает значения, близкие к 0. Нетрудно видеть, что расчетные формулы в случае двухмерного изображения будут иметь вид:
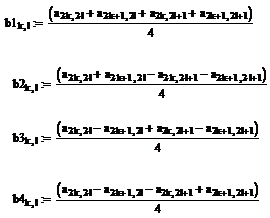
Используя эти формулы, например, для изображения 512х512 пикселов получим после первого преобразования 4 матрицы размером 256х256 элементов.
В первой, как легко догадаться, будет храниться уменьшенная копия изображения. Во второй — усредненные разности пар значений пикселов по горизонтали. В третьей — усредненные разности пар значений пикселов по вертикали. В четвертой — усредненные разности значений пикселов по диагонали. По аналогии с двумерным случаем мы можем повторить наше преобразование и получить вместо первой матрицы 4 матрицы размером 128х128. Повторив наше преобразование в третий раз, мы получим в итоге: 4 матрицы 64х64, 3 матрицы 128х128 и 3 матрицы 256х256. На практике при записи в файл, значениями, получаемыми в последней строке, обычно пренебрегают (сразу получая выигрыш примерно на треть размера файла — 1- 1/4 - 1/16 - 1/64...).
К достоинствам этого алгоритма можно отнести то, что он очень легко позволяет реализовать возможность постепенного “проявления” изображения при передаче изображения по сети. Кроме того, поскольку в начале изображения мы фактически храним его уменьшенную копию, упрощается показ “огрубленного” изображения по заголовку.
В отличие от JPEG и фрактального алгоритма, которые будут описаны ниже, данный метод не оперирует блоками, например, 8х8 пикселов. Точнее, мы оперируем блоками 2х2, 4х4, 8х8 и т.д. Однако за счет того, что коэффициенты для этих блоков мы сохраняем независимо, мы можем достаточно легко избежать дробления изображения на “мозаичные” квадраты.
Пример волнового метода
Волновой метод рассмотрим на примере рисунка “Дракон”, заданного кодами цветов:
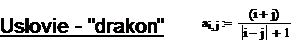
Тогда после первой и второй итерации рисунок будет выглядеть, соответственно, следующим образом:
5.3. Дискретное косинус-преобразование (ДКП-метод).
Описание метода.
Будем рассматривать изображение как целочисленную функцию 2-ух переменных 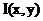 , где значение цвета, либо его номер в палитре, либо, например, интенсивность – это зависит от цветовой модели представления изображения.
, где значение цвета, либо его номер в палитре, либо, например, интенсивность – это зависит от цветовой модели представления изображения.
Эту функцию можно разложить в ряд: 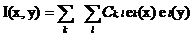 .
.
Рассмотрим разложение в ряд Фурье. Здесь:  , соответственно получим разложение:
, соответственно получим разложение: 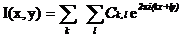 . Т.к.
. Т.к. 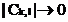 , при
, при 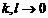
 можно ограничиться конечными
можно ограничиться конечными  и
и 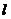 . Поскольку это есть разложение в ряд по косинусам и синусам, то так можно судить о периодичности изображения как функции. Для сжатия изображений практически не используется.
. Поскольку это есть разложение в ряд по косинусам и синусам, то так можно судить о периодичности изображения как функции. Для сжатия изображений практически не используется.
Более применимым и широко используемым является дискретное косинусное преобразование (ДКП) (DCT - Discrete Cosine Transform)
Пусть наше изображение квадратное, т.е. размера  .
.
Рассмотрим прямое преобразование (Forward):
 , где
, где  ,
, 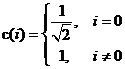
Существует и обратное преобразование (inverse):
 ,где ,
,где ,
В чём же смысл, если коэффициентов столько же?
Рассмотрим некоторые:

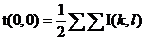 - фактически среднее арифметическое изображения;
- фактически среднее арифметическое изображения;

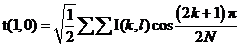 - появляется первый косинус (см. рис. 13).
- появляется первый косинус (см. рис. 13).

Рисунок 1 3. График при i=1, j=0.
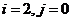
 (см. рис. 14)
(см. рис. 14)

Рисунок 14. График при i=2, j=0.
Можно сделать вывод, что ДКП раскладывает изображение по амплитудам некоторых частот. Таким образом, получится матрица, где будет много коэффициентов близких к нулю.
Пример ДКП-метода.
Дискретное косинус-преобразование рассмотрим на примере растрового рисунка “Гриб”:

Расчетные формулы прямого косинус-преобразования имеют следующий вид:
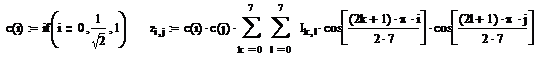
Процесс квантования даст следующую матрицу:
Выполняя обратное косинус-преобразование
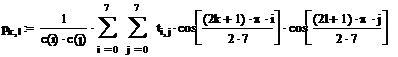
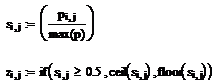
и сравнивая исходный и полученный рисунки, получаем:
Классический алгоритм JPG.
Будем рассматривать изображение как целочисленную функцию двух переменных 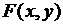 , где
, где  - значение цвета, либо его номер в палитре, либо, например, интенсивность - это зависит от цветовой модели представления изображения,
- значение цвета, либо его номер в палитре, либо, например, интенсивность - это зависит от цветовой модели представления изображения,  - координаты данной точки.
- координаты данной точки.
Шаг 1. Воспользуемся принципом, заложенным в основу алгоритма JPEG (JPEG – Joint Photographic Expert Group - подразделение в рамках ISO - Международной организации по стандартизации; алгоритм разработан группой экспертов в области фотографии специально для сжатия 24-битных изображений). В частности, переведем изображение из цветового пространства RGB, с компонентами, отвечающими за красную (Red), зеленую (Green) и синюю (Blue) составляющие цвета точки, в цветовое пространство YCrCb (иногда называют YUV).
Здесь Y - яркостная составляющая, а Cr, Cb - компоненты, отвечающие за цвет (хроматический красный и хроматический синий). За счет того, что человеческий глаз менее чувствителен к цвету, чем к яркости, появляется возможность архивировать массивы для Cr и Cb компонент с большими потерями и, соответственно, большими коэффициентами сжатия. Подобное преобразование уже давно используется в телевидении. На сигналы, отвечающие за цвет, там выделяется более узкая полоса частот.
Упрощенные схемы прямого и обратного преобразований выглядят следующим образом:
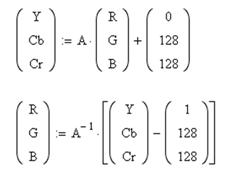
где  - матрица перехода.
- матрица перехода.
Шаг 2. Изображение разбивается на матрицы 8х8. Формируем из каждой три рабочие матрицы дискретного косинус-преобразования (ДКП) - по 8 бит отдельно для каждой компоненты. При больших коэффициентах сжатия этот шаг может выполняться чуть сложнее.
В алгоритме JPEG изображение делится по компоненте Y - как и в первом случае, а для компонент Cr и Cb матрицы набираются через строчку и через столбец так, как это показано на риc 11. Т.е. из исходной матрицы размером 16x16 получается только одна рабочая матрица ДКП. При этом теряется 3/4 полезной информации о цветовых составляющих изображения, но осуществляется сжатие сразу в два раза. Мы можем поступать так благодаря работе в пространстве YCrCb. На результирующем RGB изображении при сравнительно небольших коэффициентах сжатия, как показала практика, это сказывается несильно.

Рис. 15. Стандартный алгоритм JPG.
Некоторым недостатком данного этапа является то, что информация о пропущенных "квадратах" является навсегда утеряной. Однако, в предположении, что - всего лишь функция, зависящая от двух переменных, в данном алгоритме могут быть использованы элементы теории приближения и данная функция может быть восстановлена с достаточной степенью точности даже при больших коэффициентах сжатия.
Шаг 3. Применяем ДКП к каждой рабочей матрице. При этом мы получаем матрицу, в которой коэффициенты в левом верхнем углу соответствуют низкочастотной составляющей изображения, а в правом нижнем — высокочастотной.
В упрощенном виде это преобразование можно представить так:
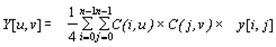 ,
,
где
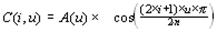 ,
,
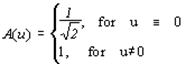
Шаг 4. Производим квантование. В принципе, это просто деление рабочей матрицы на матрицу квантования поэлементно. Для каждой компоненты (Y, U и V), в общем случае, задается своя матрица квантования q[u,v] (далее МК).

На этом шаге осуществляется управление степенью сжатия, и происходят самые большие потери. Понятно, что, задавая МК с большими коэффициентами, мы получим больше нулей и, следовательно, большую степень сжатия.
В стандарт JPEG включены рекомендованные МК, построенные опытным путем. Матрицы для большего или меньшего коэффициентов сжатия получают путем умножения исходной матрицы на некоторое число gamma.
С квантованием связаны и специфические эффекты алгоритма. При больших значениях коэффициента gamma потери в низких частотах могут быть настолько велики, что изображение распадется на квадраты 8х8. Потери в высоких частотах могут проявиться в так называемом “эффекте Гиббса”, когда вокруг контуров с резким переходом цвета образуется своеобразный “нимб”.
Шаг 5. Переводим матрицу 8x8 в 64-элементный вектор при помощи “зигзаг”-сканирования, т.е. берем элементы с индексами (0,0), (0,1), (1,0), (2,0)...
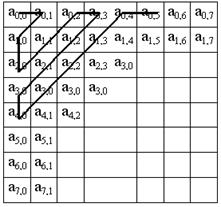
Таким образом, в начале вектора мы получаем коэффициенты матрицы, соответствующие низким частотам, а в конце — высоким.
Шаг 6. Свертываем вектор с помощью алгоритма группового кодирования. При этом получаем пары типа (пропустить, число), где “пропустить” является счетчиком пропускаемых нулей, а “число” — значение, которое необходимо поставить в следующую ячейку. Так, вектор 42 3 0 0 0 -2 0 0 0 0 1... будет свернут в пары (0,42) (0,3) (3,-2) (4,1)....
Шаг 7. Свертываем получившиеся пары кодированием по Хаффману с фиксированной таблицей.
Процесс восстановления изображения полностью симметричен на всех шагах алгоритма до предпоследнего.
Существенными положительными сторонами алгоритма является то, что:
1. Задается степень сжатия.
2. Выходное цветное изображение может иметь 24 бита на точку.
Отрицательными сторонами стандартного алгоритма JPEG является то, что:
1) При повышении степени сжатия изображение распадается на отдельные квадраты (8x8). Это связано с тем, что происходят большие потери в низких частотах при квантовании, и восстановить исходные данные становится невозможно.
2) Проявляется эффект Гиббса - ореолы по границам резких переходов цветов.
Не очень приятным свойством JPEG является также то, что нередко горизонтальные и вертикальные полосы на дисплее абсолютно не видны и могут проявиться только при печати в виде муарового узора. Он возникает при наложении наклонного растра печати на горизонтальные и вертикальные полосы изображения. Из-за этих сюрпризов JPEG не рекомендуется активно использовать в полиграфии, задавая высокие коэффициенты. Однако при архивации изображений, предназначенных для просмотра человеком, он на данный момент незаменим.
Фрактальный алгоритм.
Фрактальная архивация основана на том, что мы представляем изображение в более компактной форме — с помощью коэффициентов системы итерируемых функций (Iterated Function System — далее по тексту как IFS). Прежде, чем рассматривать сам процесс архивации, разберем, как IFS строит изображение, т.е. процесс декомпрессии.
Строго говоря, IFS представляет собой набор трехмерных аффинных преобразований, в нашем случае переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (х_координата, у_координата, яркость).
Наиболее наглядно этот процесс продемонстрировал Барнсли в своей книге “Fractal Image Compression”. Там введено понятие Фотокопировальной Машины, состоящей из экрана, на котором изображена исходная картинка, и системы линз, проецирующих изображение на другой экран (рис. 16):
· Линзы могут проецировать часть изображения произвольной формы в любое другое место нового изображения.
· Области, в которые проецируются изображения, не пересекаются.
· Линза может менять яркость и уменьшать контрастность.
· Линза может зеркально отражать и поворачивать свой фрагмент изображения.
· Линза должна масштабировать (уменьшать) свой фрагмент изображения.

Рис. 16.
Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется “ неподвижной точкой ” или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Таким образом, интуитивно понятно, что система итерируемых функций задает фрактал (нестрого — самоподобный математический объект).
Наиболее известны два изображения, полученных с помощью IFS: “треугольник Серпинского” и “папоротник Барнсли” (рис. 17). “Треугольник Серпинского” задается тремя, а “папоротник Барнсли” четырьмя аффинными преобразованиями (или, в нашей терминологии, “линзами”). Каждое преобразование кодируется буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.

Рис. 17. Папоротник Барнсли.
Из вышесказанного становится понятно, как работает архиватор, и почему ему требуется так много времени. Фактически, фрактальная компрессия — это поиск самоподобных областей в изображении и определение для них параметров аффинных преобразований.
В худшем случае, если не будет применяться оптимизирующий алгоритм, потребуется перебор и сравнение всех возможных фрагментов изображения разного размера. Даже для небольших изображений при учете дискретности мы получим астрономическое число перебираемых вариантов. Причем, даже резкое сужение классов преобразований, например, за счет масштабирования только в определенное количество раз, не дает заметного выигрыша во времени. Кроме того, при этом теряется качество изображения. Подавляющее большинство исследований в области фрактальной компрессии сейчас направлены на уменьшение времени архивации, необходимого для получения качественного изображения.
Далее приводятся основные определения и теоремы, на которых базируется фрактальная компрессия.
Определение. Преобразование 
 , представимое в виде
, представимое в виде
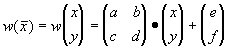
где a, b, c, d, e, f действительные числа и 
 называется двумерным аффинным преобразованием.
называется двумерным аффинным преобразованием.
Определение. Преобразование 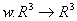
 , представимое в виде
, представимое в виде

где a, b, c, d, e, f, p, q, r, s, t, u действительные числа и 
 называется трехмерным аффинным преобразованием.
называется трехмерным аффинным преобразованием.
Определение. Пусть 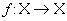
 — преобразование в пространстве Х. Точка
— преобразование в пространстве Х. Точка 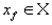
 такая, что
такая, что 
 называется неподвижной точкой (аттрактором) преобразования.
называется неподвижной точкой (аттрактором) преобразования.
Определение. Преобразование  в метрическом пространстве (Х, d) называется сжимающим, если существует число s:
в метрическом пространстве (Х, d) называется сжимающим, если существует число s: 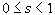
 , такое, что
, такое, что
 .
.
Замечание: Формально мы можем использовать любое сжимающее отображение при фрактальной компрессии, но реально используются лишь трехмерные аффинные преобразования с достаточно сильными ограничениями на коэффициенты.
Теорема. (О сжимающем преобразовании)
Пусть в полном метрическом пространстве (Х, d). Тогда существует в точности одна неподвижная точка 
 этого преобразования, и для любой точки
этого преобразования, и для любой точки 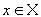
 последовательность
последовательность 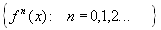
 сходится к
сходится к 
 .
.
Более общая формулировка этой теоремы гарантирует нам сходимость.
Определение. Изображением называется функция S, определенная на единичном квадрате и принимающая значения от 0 до 1 или 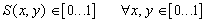

Пусть трехмерное аффинное преобразование 
 , записано в виде
, записано в виде
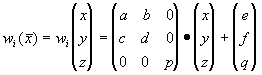

и определено на компактном подмножестве 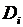
 декартова квадрата [0..1]x[0..1]. Тогда оно переведет часть поверхности S в область
декартова квадрата [0..1]x[0..1]. Тогда оно переведет часть поверхности S в область 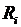
 , расположенную со сдвигом (e,f) и поворотом, заданным матрицей
, расположенную со сдвигом (e,f) и поворотом, заданным матрицей

 .
.
При этом, если интерпретировать значение S как яркость соответствующих точек, она уменьшится в p раз (преобразование обязано быть сжимающим) и изменится на сдвиг q.
Определение. Конечная совокупность W сжимающих трехмерных аффинных преобразований 
 , определенных на областях , таких, что
, определенных на областях , таких, что 
 и
и 
 , называется системой итерируемых функций ( IFS).
, называется системой итерируемых функций ( IFS).
Системе итерируемых функций однозначно сопоставляется неподвижная точка — изображение. Таким образом, процесс компрессии заключается в поиске коэффициентов системы, а процесс декомпрессии — в проведении итераций системы до стабилизации полученного изображения (неподвижной точки IFS). На практике бывает достаточно 7-16 итераций. Области в дальнейшем будут именоваться ранговыми, а области — доменными.
Построение алгоритма
Как уже стало очевидным из изложенного выше, основной задачей при компрессии фрактальным алгоритмом является нахождение соответствующих аффинных преобразований. В самом общем случае мы можем переводить любые по размеру и форме области изображения, однако в этом случае получается астрономическое число перебираемых вариантов разных фрагментов, которое невозможно обработать на текущий момент даже на суперкомпьютере.
В учебном варианте алгоритма, изложенном далее, сделаны следующие ограничения на области:
1. Все области являются квадратами со сторонами, параллельными сторонам изображения. Это ограничение достаточно жесткое. Фактически мы собираемся аппроксимировать все многообразие геометрических фигур лишь квадратами.
2. При переводе доменной области в ранговую уменьшение размеров производится ровно в два раза. Это существенно упрощает как компрессор, так и декомпрессор, т.к. задача масштабирования небольших областей является нетривиальной.
3. Все доменные блоки — квадраты и имеют фиксированный размер. Изображение равномерной сеткой разбивается на набор доменных блоков.
4. Доменные области берутся “через точку” и по Х, и по Y, что сразу уменьшает перебор в 4 раза.
5. При переводе доменной области в ранговую поворот куба возможен только на 00, 900, 1800 или 2700. Также допускается зеркальное отражение. Общее число возможных преобразований (считая пустое) — 8.
6. Масштабирование (сжатие) по вертикали (яркости) осуществляется в фиксированное число раз — в 0,75.

Эти ограничения позволяют:
1. Построить алгоритм, для которого требуется сравнительно малое число операций даже на достаточно больших изображениях.
2. Очень компактно представить данные для записи в файл. Нам требуется на каждое аффинное преобразование в IFS:
· два числа для того, чтобы задать смещение доменного блока. Если мы ограничим входные изображения размером 512х512, то достаточно будет по 8 бит на каждое число.
· три бита для того, чтобы задать преобразование симметрии при переводе доменного блока в ранговый.
· 7-9 бит для того, чтобы задать сдвиг по яркости при переводе.
Информацию о размере блоков можно хранить в заголовке файла. Таким образом, мы затратили менее 4 байт на одно аффинное преобразование. В зависимости от того, каков размер блока, можно высчитать, сколько блоков будет в изображении. Таким образом, мы можем получить оценку степени компрессии.
Например, для файла в градациях серого 256 цветов 512х512 пикселов при размере блока 8 пикселов аффинных преобразований будет 4096 (512/8x512/8). На каждое потребуется 3.5 байта. Следовательно, если исходный файл занимал 262144 (512х512) байт (без учета заголовка), то файл с коэффициентами будет занимать 14336 байт. Коэффициент архивации — 18 раз. При этом мы не учитываем, что файл с коэффициентами тоже может обладать избыточностью и архивироваться методом архивации без потерь, например L