Входной поток: алфавит { a 1, a 2, …, a N}.
Выходной поток: алфавит {0, 1}.
Пусть у нас буквы a, b, c, d расположены в терминальных вершинах дерева:

Рис.1.
Каждой букве мы можем приписать путь до нее от корня дерева, считая, например, передвижение по ветви влево — 0, вправо — 1:
a ~ 0, b ~ 10, c ~ 110, d ~ 111.
Разберем на примере процедуру построения дерева по входной последовательности, состоящей из a 1, a 2, a 3, a 4, a 5.
Пусть a 1, a 2, a 3, a 4, a 5 встретились 5, 3, 10, 1 и 4 раза соответственно. Строим гистограмму частот этих символов.

Рис.2.
1. Берем две самые редкие буквы: a 2 и a 4, создаем временный узел a 6, для которого a 2 и a 4 — нижние листья, (частота a 6) = (частота a 2) + (частота a 4) = 4. a 2 и a 4 в дальнейшем не рассматриваем.
2. Из a 1, a 3, a 5, a 6 выбираем две самые редкие буквы: a 5 и a 6, создаем временный узел a 7 с частотой 4 + 4 = 8, для которого a 5 и a 6 — нижние листья. a 5 и a 6 в дальнейшем не рассматриваем.
3. Из a 1, a 3, a 7 выбираем две самые редкие буквы: a 1 и a 7, создаем a 8 с частотой 13, для которого a1 и a 7 — нижние листья. a 1 и a 7 в дальнейшем не рассматриваем.
4. Создаем a 9, с нижними листьями a 3, a 8.
Получаем дерево:
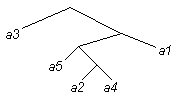 Рис.3.
Рис.3.
Свойства метода Хаффмана:
1. Код Хаффмана оптимален (в смысле результата наименьшей длины в пределе) в классе алгоритмов, использующих префиксный код.
2. Таблицу частот символов можно или строить для каждой входной последовательности свою, или использовать фиксированную таблицу кодов, или строить ее динамически по имеющимся на каждый момент данным.
Кодирование Хаффмана используется, например, в JPG.
При описании реализации этого метода многие авторы пишут о том, что список символов должен быть упорядочен по вероятностям символов, и это упорядочение нужно обновлять после каждой склейки. Так поступать, конечно, неразумно. После начального упорядочения (символы располагаются по возрастанию их вероятностей) дополнительных упорядочений производить не требуется. Достаточно организовать еще один список для новых символов. Добавление идет в конец этого списка, и возрастание вероятностей в нем обеспечивается само по себе. А при выборе двух символов с наименьшими вероятностями мы используем виртуальный список — результат слияния старого и нового списков. Поскольку размер нового списка известен, (на один элемент короче исходного) такой список реализуется обычным массивом.
Метод Хаффмена легко допускает всевозможные "усовершенствования". Например, при заметном преобладании какого-либо из символов, вызывающем его многократные повторы, можно сначала заменить последовательности повторов более экономной записью, а затем уже использовать метод Хаффмена.
Из рассмотрения задач поиска и кодирования следуют некоторые практические рекомендации качественного характера: полезно называть длинными именами те объекты в программах, которые редко используются, и короткими именами — используемые часто. Нужно располагать ближе и удобнее то, что используется чаще, и т. п.
Первоначально возможность сжатия текстов была интересна только специалистам по телеграфной и радиосвязи (включая очень рано появившиеся работы по экономной передаче телевизионных изображений). С появлением персональных компьютеров программы сжатия текстов вошли в обиход практически всех потребителей вычислительной техники, а в последних версиях операционных систем, например в MS DOS начиная с версии 6.0, сжимающие программы становятся уже системной частью. Некоторые из схем сжатия информации запатентованы, и выпускаются реализующие их электронные устройства.
Пример использования метода Хаффмена.
Исходный текст (223 знака, прописные буквы для простоты заменены строчными, знаки препинания и переводы строк удалены, межсловный пробел заменен подчеркиванием, в каждой строке по 50 символов):
ехали_меаведи_на_велосипеде_а_за_ними_кот_задом_на
перед_а_за_ним_комарики_на_воздушном_шарике_а_за_н
ими_раки_на_хромой_собаке_волки_на_кобыле_львы_в_а
втомобиле_зайчики_в_трамвайчике_жаба_на_метле_едут
_и_смеются_пряники_жуют
По этому тексту получаем следующую статистику:
е17 х2 а24 л7 и20 _40 м12 д7 в9
н11 о13 с4 п3 з6 к11 т7 р7 у3
ш2 й3 б4 ы2 ь1 ч2 ж2 ю2 я2
или после сортировки по убыванию частот
_40 а24 и20 е17 о13 м12 н11 к11 в9
л7 д7 т7 р7 з6 с4 б4 пЗ йЗ
у3 х2 ш2 ы2 ч2 ж2 ю2 я2 ь1
Кодовые последовательности после применения алгоритма Хаффмена:
_ 111 а 010 и 000 е 1100 о 1000 м 0110 и 0010 к 0011 в 11010
л 10100 д 10101 т 10010 р 10011 з 110110 с 101100 б 101101
п 011110 и 011100 у 011101 х 1101110 ш 1101111 ы 1011110
ч 1011111 ж 1011100 ю 1011101 я 0111110 ь 0111111
Применяя эти кодовые последовательности для кодирования текста, получаем такой двоичный текст (длина строки — 64 бита):
110011011100101010000011101101100101011101011001010100011100100101111101011001010010001011000000111101100101011100111010111110110010111001000001100001110011100010010111110110010101011000011011100100100111101100100111100101011110101111101100101110010000011011100111000011001010011000001100011100100101111101010001101101010101110111011110010100001101111101111010100110000011110011101011111011001011100100000110000111100110100011000111001001011111011101001110000110100001110011110110010001011010100011110011111010100010100001100011100100101110011100010110110111101010011001111010001111111101010111101111101011101011010100101000011010001011010001010011001111101100100111001011111000001100011111010111100101001101001101101001001110010111110000011110011110111000101011010101110010010111011011001001010100110011111001010101110110010111000111101100011011001011101100101011000111110111011110100110111110001000000110001111011100011101101110110010
Получилось немного меньше 119 байтов, так что исходный текст сокращен почти вдвое (правда, если не считать самой кодовой таблицы)
По методу Хаффмена получается максимальное сжатие, и, казалось бы, ни о каком дальнейшем улучшении уже не может быть и речи. Вспомним, однако, что минимизируется математическое ожидание последовательности независимых символов, — код Хаффмена никак не использует информацию о закономерностях чередования символов в кодируемом тексте, закономерностях сложных и плохо описываемых математическими моделями.
4.2. Метод Зива Лемпеля (LZ-метод)
4.2.1. Основные определения
"Символ": фундаментальный элемент данных. В обычных текстовых файлах это отдельный байт. В растровых изображениях это индекс, который указывает цвет данного пиксела. Будем ссылаться на произвольный символ как на "K".
"Поток символов": поток символов такой, как файл данных.
"Цепочка": несколько последовательных символов. Длина цепочки может изменяться от 1 до очень большого числа символов. Будем указывать произвольную цепочку как "[...]K".
"Префикс": почти то же самое, что цепочка, но подразумевается, что префикс непосредственно предшествует символу, и префикс может иметь нулевую длину. Будем ссылаться на произвольный префикс, как на "[...]".
"Корень": односимвольная цепочка. Для большинства целей это просто символ, но иногда это может быть иначе. Это [...]K, где [...] пуста.
"Код": число, определяемое известным количеством бит, которое кодирует цепочку.
"Поток кодов": выходной поток кодов, таких как "растровые данные".
"Элемент": код и его цепочка.
"Таблица цепочек": список элементов обычно, но не обязательно, уникальных.
Краткое описание LZ-метода
Рассмотрим алгоритм декодирования. Пусть входной поток байтов  был закодирован в последовательность байтов
был закодирован в последовательность байтов  .
.
Алгоритм декодирования
пусть по c 1 … ck -1 уже восстановили a 1 … ai -1,
читаем ck
если (первый бит ck = 0) то //(см. пример на рис.1)
рассмотреть остальные биты ck как двоичную запись числа n
следующие n символов ck +1 … ck + n просто скопировать на выход
если (первый бит ck = 1) то //(см. пример на рис.2)
рассмотреть остальные биты ck как двоичную запись числа n;
считать ck +1 — смещение назад;
скопировать на выход  ;
;
конец алгоритма

Рис.4

Рис.5
“Минусы” LZ-метода:
ü cj ограничены (~ 16 бит), следовательно, смещение назад ограничено, т.е. кодировщик “забывает” начало входного потока;
ü долгий процесс кодирования.
Пример LZ-метода
По методу Зива-Лемпеля тот же пример кодируется следующим образом. Сначала записаны номера строк, затем сами строки, затем представление каждой из этих строк в виде пар (номер предыдущей строки, дополняющий символ). В начале образовалось семь строк длины 1. Восьмая буква совпала с первой строкой, поэтому восьмая строка составлена из первой строки и буквы “а”. Девятая строка состоит из одной буквы, а десятая — из восьмой строки и буквы “и”.
| 1
| е
| 0е
|
| 2
| х
| 0х
|
| 3
| а
| 0а
|
| 4
| л
| 0л
|
| 5
| и
| 0и
|
| 6
| _
| 0_
|
| 7
| м
| 0м
|
| 8
| ед
| 1д
|
| 9
| в
| 0в
|
| 10
| еди
| 8и
|
| 11
| _н
| 6н
|
| 12
| а_
| 3_
|
| 13
| ве
| 9е
|
| 14
| ло
| 4о
|
| 15
| с
| 0с
|
| 16
| ип
| 5п
|
| 17
| еде
| 8е
|
| 18
| _а
| 6а
|
| 19
| _з
| 6з
|
| 20
| а_н
| 12н
|
| 21
| им
| 5м
|
| 22
| и_
| 5_
|
| 23
| к
| 0к
|
| 24
| о
| 0о
|
| 25
| т
| 0т
|
| 26
| _за
| 19а
|
| 27
| д
| 0д
|
| 28
| ом
| 24м
|
| 29
| _на
| 11а
|
| 30
| п
| 0п
|
| 31
| ер
| 1р
|
| 32
| ед_
| 8_
|
| 33
| а_з
| 12з
|
| 34
| а_ни
| 20и
|
| 35
| м_
| 7_
|
| 36
| ко
| 23о
|
| 37
| ма
| 7а
|
| 38
| р
| 0р
|
| 39
| ик
| 5к
|
| 40
| и_н
| 22н
|
| 41
| а_в
| 12в
|
| 42
| оз
| 24з
|
| 43
| ду
| 27у
|
| 44
| ш
| 0ш
|
| 45
| н
| 0н
|
| 46
| ом_
| 28_
|
| 47
| ша
| 44ф
|
| 48
| ри
| 38и
|
| 49
| ке
| 23е
|
| 50
| _а_
| 18_
|
| 51
| з
| 0з
|
| 52
| а_ним
| 34м
|
| 53
| и_р
| 22р
|
| 54
| ак
| 3к
|
| 55
| и_на
| 40а
|
| 56
| _х
| 6х
|
| 57
| ро
| 38о
|
| 58
| мо
| 7о
|
| 59
| й
| 0й
|
| 60
| _с
| 6с
|
| 61
| об
| 24б
|
| 62
| аке
| 54е
|
| 63
| _в
| 6в
|
| 64
| ол
| 24л
|
| 65
| ки
| 23и
|
| 66
| _на_
| 29_
|
| 67
| коб
| 36б
|
| 68
| ы
| 0ы
|
| 69
| ле
| 4е
|
| 70
| _л
| 6л
|
| 71
| ь
| 0ь
|
| 72
| вы
| 9ы
|
| 73
| _в_
| 63_
|
| 74
| ав
| 3в
|
| 75
| то
| 25о
|
| 76
| моб
| 58б
|
| 77
| ил
| 5л
|
| 78
| е_
| 1_
|
| 79
| за
| 51а
|
| 80
| йч
| 59ч
|
| 81
| ики
| 39и
|
| 82
| _в_т
| 73т
|
| 83
| ра
| 38а
|
| 84
| мв
| 7в
|
| 85
| ай
| 3й
|
| 86
| ч
| 0ч
|
| 87
| ике
| 39е
|
| 88
| _ж
| 6ж
|
| 89
| аб
| 3б
|
| 90
| а_на
| 20а
|
| 91
| _м
| 6м
|
| 92
| ет
| 1т
|
| 93
| ле_
| 69_
|
| 94
| еду
| 8у
|
| 95
| _т
| 25_
|
| 96
| и_с
| 22с
|
| 97
| ме
| 7е
|
| 98
| ю
| 0ю
|
| 99
| тс
| 25с
|
| 100
| я
| 0я
|
| 101
| _п
| 6п
|
| 102
| ря
| 38я
|
| 103
| ни
| 45и
|
| 104
| ки_
| 65_
|
| 105
| ж
| 0ж
|
| 106
| у
| 0у
|
| 107
| ют
| 98т
|
| 108
| \n
| 0
|
| 109
| eof
| 0
|
Полезно взглянуть на рис. 6, где показаны длины получающихся строк и их изменяющаяся средняя длина. Вы видите, что только около семидесятой строки средняя длина строки превосходит 2 и при записи каждого номера строки в один байт получается небольшой выигрыш. При увеличении длины кодируемого текста выигрыш растет, а закодированную информацию можно еще дополнительно сжимать.

Рис. 6. Длины кодовых строк и поведение средней длины
4.3. Метод Зива-Лемпеля-Велча (LZW-метод)
Общие положения
При сжатии и раскрытии LZW манипулирует тремя объектами: потоком символов, потоком кодов и таблицей цепочек. При сжатии поток символов является входным и поток кодов - выходным. При раскрытии входным является поток кодов, а поток символов - выходным. Таблица цепочек порождается и при сжатии и при раскрытии, однако она никогда не передается от сжатия к раскрытию и наоборот.
Краткое описание LZW-метода
Пусть на вход подаются символы a, b, c, … (256 различных символов по 8 бит). Идея в том, что часто встречающиеся слова (т.е. последовательности символов) будем хранить в “словаре”.
Алгоритм кодирования (Пример работы алгоритма см. на рис. 7)
Кладем в словарь символы a, b, c, … под номерами 0.. 255, соответственно.
строка = пустая
пока (поток не пуст) //смотрим входной поток
строка += след.элемент
если (строка есть в словаре) то продолжить;
иначе
// код(строка0) — код, соответствующий строке0 в словаре
вывести код(строка – последний элемент)
добавить_в_словарь(строка)
строка = последний_элемент(строка)
конец если
конец пока
конец алгоритма
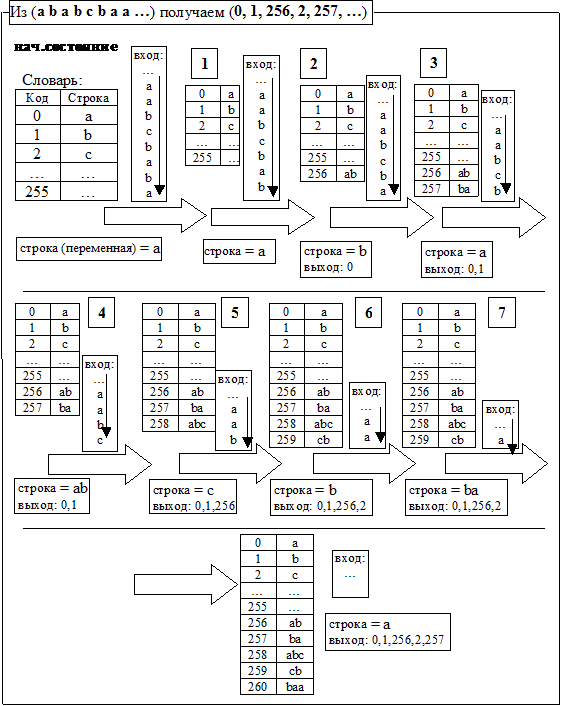
Рис.7. Работа кодировщика LZW
Утверждение. По выходной последовательности реконструируется и словарь, и входная последовательность.
Алгоритм декодирования
Кладем в словарь символы a, b, c, … под номерами 0.. 255, соответственно.
пока (поток не пуст)
код = следующий код из потока
1 если (в словаре есть слово для кода) (рис. 8)
вывести содержимое_словаря(по коду)
добавить в словарь(содерж_словаря(по прошлому_коду) +перв_символ(содерж_словаря(по коду)))
2 иначе
строка = содерж_словаря(по прошлому_коду) + перв_символ(содерж_словаря(по прошлому_коду))
вывести(строка)
добавить в словарь(строка)
конец если
конец пока
конец алгоритма

Рис. 8. Шаг работы декодировщика LZW в случае 1
Возникают следующие вопросы.
1. Пока в словарь добавили мало слов, на представление кода можно отводить меньше бит: до 512 слов — 9 бит на код, от 512 до 1024 — 10 бит и т.д. Изменение длины кодов должны контролировать и кодировщик, и декодировщик.
2. Если словарь кончится: обнуляем словарь (главное, это должны знать и кодировщик, и декодировщик).
3. Чтобы поиск последовательности в словаре занимал меньше времени можно организовать словарь в виде бинарного дерева поиска.
При сравнительно небольших затратах на одну кодовую комбинацию получается достаточно большой диапазон номеров, например, при 12 битах (полтора байта) можно закодировать примерно 4000 строк и не требуется никаких дополнительных затрат на таблицу исходных символов.
Важное преимущество LZ-методов и в том, что они адаптивны, т. е. сами приспосабливаются к особенностям текста и не требуют предварительного просмотра, как метод Хаффмена. Правда, существуют и адаптивные варианты кодирования по Хаффмену. Эти и другие методы можно найти в обзорах по сжатию данных, например в [5].
Сейчас массовое использование персональных компьютеров сделало популярными многочисленные "архивирующие программы", среди них наиболее известны arj, zip, zoo, rar, а в среде UNIX — программы compress, gzip, compact. Популярна сжатая система хранения информации на диске. В системе программирования JAVA предусмотрено хранение в сжатой форме исполняемых файлов. Алгоритмическую основу архивирующих программ образуют методы Хаффмена и Зива—Лемпеля с различными модификациями и усовершенствованиями.
Пример LZW-метода.
Исходные символы текста получают свои кодовые номера априори, например номерами могут быть ASCII-коды символов, а встречающиеся в тексте цепочки символов заносятся в кодовую таблицу для возможного дальнейшего использования.
Здесь в первой колонке мы видим префикс рассматриваемой строки (в начале процесса он пуст), во второй колонке—очередной символ входного текста. Если текущая строка—конкатенация префикса и символа—уже включена в кодовую таблицу, она становится новым префиксом, в противном же случае она регистрируется, префикс (непустой) выводится в результат, а символ заменяет его как новый префикс.
В начале процесса букву “е” сохраняем как префикс. Далее, строка “ех” не встречалась – регистрируем ее с кодом 27 (т.к. в исходном алфавите 27 символов, пронумерованные от 0 до 26 в алфавитном порядке, код 0 имеет символ “_”), букву “х” запоминаем как новый префикс.
| ех
| 27
| е
|
| ха
| 28
| х
|
| ал
| 29
| а
|
| ли
| 30
| л
|
| и_
| 31
| и
|
| _м
| 32
| _
|
| ме
| 33
| м
|
| ед
| 34
| е
|
| дв
| 35
| д
|
| ве
| 36
| в
|
| еди
| 37
| 34
|
| и_н
| 38
| 31
|
| на
| 39
| н
|
| а_
| 40
| а
|
| _в
| 41
| _
|
| вел
| 42
| 36
|
| ло
| 43
| л
|
| ос
| 44
| о
|
| си
| 45
| с
|
| ип
| 46
| и
|
| пе
| 47
| п
|
| еде
| 47
| 34
|
| е_
| 49
| е
|
| _а
| 50
| _
|
| а_з
| 51
| 40
|
| за
| 52
| з
|
| а_н
| 53
| 40
|
| ни
| 54
| н
|
| им
| 55
| и
|
| ми
| 56
| м
|
| и_к
| 57
| 31
|
| ко
| 58
| к
|
| от
| 59
| о
|
| т_
| 60
| т
|
| _з
| 61
| _
|
| зад
| 62
| 52
|
| до
| 63
| д
|
| ом
| 64
| о
|
| м_
| 65
| м
|
Метод Барроуза-Уиллера.
Общие положения.
Алгоритм сжатия данных на основе преобразования Барроуза-Уилера (Burrows-Wheeler Transform, далее BWT) впервые был описан сравнительно недавно - в 1994 году. Он был опубликован 10 мая в статье "A Block-sorting Lossless Data Compression Algorithm". Хотя утверждается, что один из его авторов, Майкл Уилер, придумал его гораздо раньше, в 1983 году, но тогда не придал ему надлежащего значения.
Сейчас этот метод стремительно обретает популярность среди исследователей в области сжатия данных, появляется все больше и больше научных статей, ему посвященных. Не обделяют его вниманием и программисты, разрабатывающие новые архиваторы. Этот метод привлекателен своей простотой и элегантностью, которые, я надеюсь, оценит также и читатель.
Классический алгоритм, описанный в оригинальной статье, представлял собой совокупность трех методов:
- метод сортировки блока данных (собственно который и называется преобразованием Барроуза-Уилера),
- MoveToFront-преобразование (известное также, как метод перемещения стопки книг),
- простой статистический кодер для сжатия преобразованных на первых двух этапах данных.
4.4.2. 1 этап. Преобразование Барроуза-Уилера.
Прямое преобразование.
Это преобразование, конечно, является основой описываемого алгоритма сжатия. Вкратце, его можно описать как способ перестановки символов в блоке данных, позволяющий осуществить эффективное сжатие. Процедуру преобразования можно условно разделить на четыре этапа:
1) выделяется блок из входного потока,
2) формируется матрица всех перестановок, полученных в результате
3) все перестановки сортируются в соответствии с лексикографическим порядком символов каждой перестановки,
4) на выход подается последний столбец матрицы и номер строки, соответствующей оригинальному блоку.
На всякий случай следует принять специальные меры, способные предотвратить возможное зацикливание при попытке сравнить две одинаковые строки. Например, при переходе через границу блока прерывать сравнение и принимать однозначное решение в пользу одной из строк.
На вход первого этапа зададим фразу “абракадабра” и получим матрицу всех перестановок.
абракадабра
бракадабраа
ракадабрааб
акадабраабр
кадабраабра
адабраабрак
дабраабрака
абраабракад
браабракада
раабракадаб
аабракадабр
Затем отсортируем полученные строки, предварительно пометив исходную.
0 аабракадабр
1 абраабракад
2 абракадабра исходная строка
3 адабраабрак
4 акадабраабр
5 браабракада
6 бракадабраа
7 дабраабрака
8 кадабраабра
9 раабракадаб
10 ракадабрааб
Таким образом, на выходе первого этапа, взяв последний столбец, мы получили строку "рдакраааабб" и номер исходной строки в отсортированной матрице, равный 2.
Следует отметить основополагающее свойство преобразования. Поскольку осуществлялись именно циклические сдвиги, символы последнего столбца предшествуют начальным символам строк, которые в наибольшей степени участвовали в сортировке. Таким образом, если в исходном файле есть две похожие строки, то символы, предшествующие им обоим, будут находиться поблизости друг от друга в блоке, полученном в результате преобразования. И чем больше эти строки похожи, тем больше вероятность того, что эти символы будут находиться рядом. Здесь и далее строки, следующие во входном блоке за символами из блока выходного, будут называться контекстами.
Поскольку BWT преобразует поток данных, обладающий сложными статистическими свойствами высокого порядка, в поток со статистикой гораздо меньшего порядка, данный метод очень удобен для последующего сжатия.
И действительно, если у нас в тексте часто встречается какое-то слово, например, как слово "архиватор", то в матрице перестановок нам будут часто встречаться строки, начинающиеся с "рхиватор". Легко догадаться, что практически во всех этих строках в конце будет находиться символ "а". Таким образом, чем больше в файле похожих строк, тем больше похожих символов мы получим рядом в результате преобразования и тем легче нам будет при сжатии.
По результатам тестов на стандартном тестовом наборе, используемом для сравнения свойств алгоритмов сжатия, Calgary Corpus, количество нулей на paperi (статья на английском языке) составило 58.4%, на progp (программа) - 74%, geo (двоичный файл) - 35.8%.
Обратное преобразование.
Для восстановления матрицы перестановок отсортируем единственное, что у нас есть - символы последнего столбца. И благодаря этому получим первый столбец. Ведь строки матрицы были отсортированы именно начиная с первого столбца - значит, упорядоченные символы - это и есть первый столбец.
| 0
| а………р
|
| 1
| а………д
|
| 2
| а………а
|
| 3
| а………к
|
| 4
| а………р
|
| 5
| б………а
|
| 6
| б………а
|
| 7
| д………а
|
| 8
| к………а
|
| 9
| р………б
|
| 10
| р………б
|
Можно заметить, что символы последнего столбца с символами первого образуют пары - ведь строки получены в результате циклического сдвига. И отсортировав эти пары мы получим уже два известных столбца в левой части матрицы. И так далее, пока не восстановим всю матрицу целиком.
| 0
| аа..……р
| ааб.……р
| аабр……р
|
…
| аабракадабр
|
| 1
| аб..……д
| абр.……д
| абра……д
| абраабракад
|
| 2
| аб..……а
| абр.……а
| абра……а
| абракадабра
|
| 3
| ад..……к
| ада.……к
| адаб……к
| адабраабрак
|
| 4
| ак..……р
| ака.……р
| акад……р
| акадабраабр
|
| 5
| бр..……а
| бра.……а
| браа……а
| браабракада
|
| 6
| бр..……а
| бра.……а
| брак……а
| бракадабраа
|
| 7
| да..……а
| даб.……а
| дабр……а
| дабраабрака
|
| 8
| ка..……а
| кад.……а
| када……а
| кадабраабра
|
| 9
| ра..……б
| раа.……б
| рааб……б
| раабракадаб
|
| 10
| ра..……б
| рак.……б
| рака……б
| ракадабрааб
|
И, зная номер исходной строки, без труда находим ее в матрице перестановок.
На самом деле нет необходимости воспроизводить посимвольно все строки матрицы по одному символу. Обратите внимание, что при каждом проявлении доселе неизвестного столбца выполнялись одни и те же действия. А именно, из строки, начинающейся с некоторого символа последнего столбца получалась строка, в которой этот символ находится на первой позиции. Из строки 0 получается строка 9, из 1 - 7 и т.п.:
| 0
| а………р
| 9
|
| 1
| а………д
| 7
|
| 2
| а………а
| 0
|
| 3
| а………к
| 8
|
| 4
| а………р
| 10
|
| 5
| б………а
| 1
|
| 6
| б………а
| 2
|
| 7
| д………а
| 3
|
| 8
| к………а
| 4
|
| 9
| р………б
| 5
|
| 10
| р………б
| 6
|
Для получения вектора обратного преобразования, определим порядок получения символов первого столбца из символов последнего (отсортируем последнюю таблицу по третьему столбцу):
| 2
| а………а
| 0
|
| 5
| б………а
| 1
|
| 6
| б………а
| 2
|
| 7
| д………а
| 3
|
| 8
| к………а
| 4
|
| 9
| р………б
| 5
|
| 10
| р………б
| 6
|
| 1
| а………д
| 7
|
| 3
| а………к
| 8
|
| 0
| а………р
| 9
|
| 4
| а………р
| 10
|
Полученные значения { 2, 5, 6, 7, 8, 9, 10, 1, 3, 0, 4 } и есть искомый вектор, содержащий номера позиций символов, упорядоченных в соответствии с положением в алфавите, в строке, которую нам надо декодировать.
 Для получения исходной строки необходимо лишь выписать символы из строки преобразованной ("рдакраааабб") в порядке, соответствующему данному вектору, начиная с номера, переданного нам вместе со строкой (т.е. 2).
Для получения исходной строки необходимо лишь выписать символы из строки преобразованной ("рдакраааабб") в порядке, соответствующему данному вектору, начиная с номера, переданного нам вместе со строкой (т.е. 2).
  2 2
| а………а
| 0
|
 
 5 5
| б………а
| 1
|
 6 6
| б………а
| 2
|

 7 7
| д………а
| 3
|

 8 8
| к………а
| 4
|

9
| р………б
| 5
|

10
| р………б
| 6
|
1
| а………д
| 7
|
3
| а………к
| 8
|
0
| а………р
| 9
|
4
| а………р
| 10
|
Критерием правильности выполненных действий в данном случае является тот факт, что маршрут должен закончится на той же позиции, что и начинался.
Этап. MTF–метод.
Как было сказано выше, это тоже преобразование. Его алгоритм легко понять, если представить стопку книг, каждая из которых соответствует определенному символу. По мере востребования из стопки вытаскивается нужная книга и кладется сверху. Через некоторое время те книги, которые используются часто, оказываются ближе к верхушке стопки.
Вернемся к нашему примеру, а именно, к полученной в результате работы BWT строке "рдакраааабб". Символы этой строки принадлежат алфавиту, содержащему пять элементов. Предположим для простоты, что других символов мы не используем, а начальный список MTF содержит эти символы в следующем порядке: { 'а', 'б', 'д', 'к', 'р' }.
Приступим к преобразованию. Символ 'р' является пятым элементом списка, поэтому первым выходным кодом становится код 4. После перемещения символа 'р' в начало списка, тот принимает вид {'р', 'а', 'б', 'д', 'к'}. И т.п.
| Символ
| Список
| Выход
|
| р
| абдкр
| 4
|
| д
| рабдк
| 3
|
| а
| драбк
| 2
|
| к
| адрбк
| 4
|
| р
| кадрб
| 3
|
| а
| ркадб
| 2
|
| а
| аркдб
| 0
|
| а
| аркдб
| 0
|
| а
| аркдб
| 0
|
| б
| аркдб
| 4
|
| б
| баркд
| 0
|
На выход второго этапа подается строка “43243200040” и алфавит {'а', 'б', 'д', 'к', 'р' }.
Обратное преобразование выполняется симметрично.
Этап. Статистический кодер.
В качестве статистического кодера наиболее часто используют метод Хаффмена (см. пункт 1.1 данной главы.). В рассматриваемом примере дерево преобразований Хаффмена может выглядеть например так:
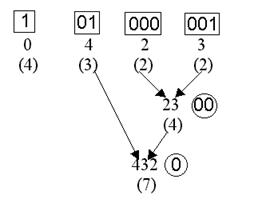
Рис. 9.
Таким образом на выход третьего этапа подается строка
010010000101001000111011,
занимающая 24 бита, и алфавит Хаффмена.
В качестве упражнения можно рекомендовать проделать обратные преобразования всего BWT-метода следующей строки:
010001010000101110.
Дополнительная информация:
1) алфавит Хаффмена:
2) алфавит MTF: арты
3) номер строки для преобразований Барроуза: 7.











