Прежде чем мы двинемся дальше, я хотел бы подытожить то, о чем мы говорили ранее. Итак, все системы письма стремятся к компромиссу между точной репрезентацией звука и быстрой передачей смысла. Эта дилемма находит непосредственное отражение в мозге читателя. Во время чтения мы задействуем два пути обработки информации, которые сосуществуют и дополняют друг друга. Редкие и новые слова, а также те, что произносятся так, как пишутся, мы предпочитаем обрабатывать с помощью фонологического маршрута: сначала мы расшифровываем буквенную цепочку, затем преобразуем ее в звук и, наконец, пытаемся получить доступ к значению звукового паттерна (если таковое имеется). Когда же мы сталкиваемся со словами, которые употребляются достаточно часто или произносятся не так, как пишутся, мы выбираем другой маршрут: сперва мы извлекаем значение слова, а потом, на базе этой лексической информации, восстанавливаем его произношение (рис. 1.4).
Наилучшее доказательство существования двух механизмов чтения ученые получили в рамках изучения травм головного мозга и их психологических последствий. Некоторые пациенты после инсульта и других повреждений теряют способность быстро определять произношение написанных слов[72]. Очевидно, у таких людей поврежден механизм, преобразующий буквы в звуки. Хотя раньше они читали абсолютно нормально, налицо все признаки синдрома, называемого фонологической дислексией. Больные не могут читать вслух редкие слова, даже если те произносятся так, как пишутся (например, «секстант»), а также неологизмы и выдуманные слова (например, «гаджет», «сине‑алый» или «киськисеп»[73]). Как ни странно, часто используемые слова они понимают и могут прочесть вслух, причем даже в том случае, если их произношение не совпадает с написанием (например, «глаз», «солнце», «мужчина»[74]). Иногда они путают одно слово с другим. Фонологический дислексик может, например, прочитать слово «мясо» как «еда»[75] или слово «живописец» как «художник». Сама природа этих ошибок свидетельствует о том, что доступ к значению слова в основном не нарушен. Если бы больной вообще не понимал слово, которое он пытается прочесть, он бы не смог извлечь даже приблизительное его значение. Пациенты с фонологической дислексией, по‑видимому, узнают написанные слова, хотя определение их произношения становится практически невозможным. Складывается впечатление, будто один из маршрутов для чтения (от букв к звуку) у них заблокирован, в то время как по другому пути (от букв к смыслу) информация циркулирует по‑прежнему.
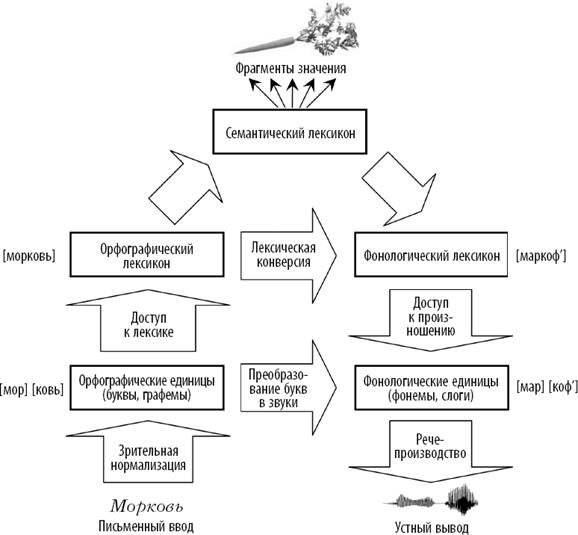
Рис. 1.4. Чтение слов происходит по нескольким параллельным маршрутам. Чтобы перейти от написанного слова (внизу слева) к его произношению (внизу справа), мозг задействует пути, которые обозначены на рисунке прямоугольниками и стрелками. Если слово пишется так, как произносится, мы используем поверхностный маршрут и преобразуем буквы в звуки напрямую. Если слово пишется не так, как произносится, например «морковь», необходимо обратиться к более глубинным репрезентациям. Последние можно сравнить с ментальными лексиконами, которые придают значению словесную форму.
Возможна и противоположная ситуация. Люди, страдающие другим синдромом, так называемой поверхностной дислексией, лишены прямого доступа к значению слов и во время чтения вынуждены медленно проговаривать слово за словом. В этом случае особенно ярко проявляются ограничения «молчаливого голоса». Например, пациенты с поверхностной дислексией могут читать слова и неологизмы, которые произносятся так, как пишутся (например, «банан» или «мем»[76]), но не слова, написание и произношение которых отличаются. Обычно они стандартизируют их путем слепого преобразования в звуки. Один больной, например, прочитал «enough»[77] как [ɪnog], а затем уверял, что никогда не слышал этого странного слова. Очевидно, при поверхностной дислексии прямой путь от букв к ментальному лексикону заблокирован, в то время как преобразование букв в звуки продолжает функционировать.
Контраст между этими разновидностями дислексии подтверждает существование двух совершенно разных механизмов чтения. Кроме того, он свидетельствует о том, что ни один из них не позволяет читать все слова. Прямой путь – от букв к словам и их значениям – может быть использован для чтения большинства слов, если они употребляются достаточно часто, но не работает с редкими и новыми словами, которые отсутствуют в нашем ментальном лексиконе. И наоборот, альтернативный путь – от букв к звукам и от звуков к значению – не поможет при чтении омофонов (например, «блог» – «блок»[78]) и слов, которые пишутся не так, как произносятся (например, «мужчина»), но играет незаменимую роль в заучивании новых слов. Когда мы читаем, оба маршрута дополняют друг друга, и каждый вносит свой вклад в уточнение произношения. Большая часть фонем слова может быть извлечена из буквенной цепочки путем применения простых правил преобразования букв в звук. Периодически возникающие двусмысленности при этом разрешаются на основании подсказок более высоких лексических и семантических уровней. В детстве эти два маршрута не всегда скоординированы. Некоторые дети в основном полагаются на прямой маршрут. Они пытаются угадать слово и зачастую подменяют его синонимом (например, читают слово «здание» как «дом»[79]). Другие бормочут себе под нос все предложение, проговаривая каждую букву, но не могут перейти от звуков к значению. Необходимы годы тренировки, прежде чем эти два маршрута смогут создать единую интегрированную систему чтения, какую мы наблюдаем у взрослых.
Согласно большинству современных моделей чтения, беглое чтение предполагает тесное взаимодействие между двумя вышеописанными маршрутами. При этом роль каждого зависит как от слова, которое необходимо прочитать (известное – неизвестное; частое – редкое; произносится так, как пишется – произносится не так, как пишется), так и от поставленной задачи (чтение вслух – понимание текста). В 1980‑х и 1990‑х годах некоторые исследователи попытались объяснить эти наблюдения одномаршрутной системой. В то время особый интерес вызвали только появившиеся нейросетевые модели. Многие рассматривали их как универсальные самообучающиеся машины, способные овладеть любым навыком в отсутствие заранее заданной когнитивной структуры. Было предположено, что овладение навыком чтения можно смоделировать путем соединения буквенных входов с фонологическими выходами, а промежуточные связи настроить с помощью мощного алгоритма обучения. Таким образом ученые надеялись получить единую сеть, которая могла бы имитировать нормальное чтение и его патологии, но без необходимости принимать во внимание множественные пути обработки информации в коре. Хотя в то время такие сети рассматривались в качестве огромного шага вперед, особенно в сфере моделирования преобразования букв в звуки[80], большинство современных исследователей убеждены, что этот подход неверен. По моему мнению, невозможно смоделировать чтение без тщательного анализа структуры мозга, которая включает множество параллельных и отчасти избыточных путей. Практически все современные модели чтения, даже если они основаны на искусственных нейросетях, построены на идее множественных маршрутов[81]. Обсуждая церебральные механизмы чтения, мы увидим, что характерной особенностью строения коры является наличие различных параллельных путей. Таким образом, даже модель с двумя путями, вероятно, не отражает истинную сложность нейронных систем, отвечающих за чтение. Разделение на два пути – фонологический и семантический – создано исключительно для удобства.
Ментальные словари
Пока мы говорили о поверхностном маршруте, преобразующем графемы в фонемы, у вас могло сложиться впечатление, будто мысленное чтение сводится к короткому перечню относительно простых действий. Казалось бы, достаточно сохранить карту нескольких сотен графем и их произношений. Однако если мы посмотрим на то, как работает глубинный маршрут, позволяющий распознавать тысячи знакомых слов, то убедимся, что требуется хранилище побольше. Специалисты по когнитивной психологии сравнивают его со словарем или «ментальным лексиконом». Без сомнения, о ментальных словарях следует говорить во множественном числе: в наших головах содержится самая разная информация о словах. У всех нас есть свой собственный ментальный орфографический словарь, в котором собраны письменные формы всех известных нам слов. Эти орфографические воспоминания, вероятно, хранятся в виде иерархических деревьев букв, графем, слогов и морфем. Например, слово «морковь» должно выглядеть как [мор] + [ковь]. Кроме того, у нас имеется отдельный «фонологический словарь». Он подсказывает нам, что «морковь» произносится как [маркофь]. Третий словарь – грамматический: в нем указано, что «морковь» – существительное женского рода единственного числа, относится к 3‑му склонению и так далее. Наконец, каждое слово ассоциируется с десятками семантических признаков, определяющих его значение: морковь – это съедобный овощ удлиненной формы, характерного оранжевого цвета и прочее. Все эти ментальные словари открываются один за другим по мере того, как наш мозг извлекает соответствующую информацию. Образно говоря, в нашем сознании имеется целая библиотека справочников – от руководств по правописанию до энциклопедий.
Количество словарных статей в ментальных словарях огромно. Объем лексических знаний человека, как правило, сильно недооценивают. Я сам слышал, как весьма сведущие люди отстаивали общепринятое представление о том, будто в пьесах Расина и Корнеля использовано не больше 2000 слов. Говорят, что бейсик‑инглиш[82] – сильно упрощенный вариант английского языка, включающий всего 850 слов – позволяет успешно выражать мысли и эмоции. Некоторые даже утверждают, будто словарный запас подростков, проживающих в бедных районах мегаполисов, сократился до 500 слов! Это не так. Согласно научным данным, лексикон среднестатистического человека составляет несколько десятков тысяч слов. Стандартный словарь содержит около 100 000 статей; как показывают исследования на основе выборочного метода, любой носитель английского языка знает около 40 000 или 50 000 из них – и это без учета составных слов. Если добавить к ним примерно такое же количество имен собственных, аббревиатур (CIA, FBI), товарных знаков (Nike, Coca‑Cola) и иностранных слов, получится, что в общей сложности каждый из наших ментальных лексиконов содержит от 50 000 до 100 000 записей. Эти числа – еще одно доказательство невероятных возможностей нашего мозга. Читая слово, любой человек с легкостью извлекает нужное значение из 50 тысяч возможных за десятые доли секунды. А ведь все, что у него есть в качестве источника – это несколько крошечных полосок света на сетчатке.
Собрание демонов
Работу системы чтения в условиях, близких к продиктованным нашей нервной системой, имитируют несколько моделей лексического доступа. Почти все они основаны на идеях, впервые сформулированных Оливером Селфриджем в 1959 году. Селфридж предположил, что наш лексикон похож на огромное собрание «демонов», или «пандемониум»[83]. Согласно этой метафоре, ментальный лексикон можно представить в виде гигантского полукруга, в котором десятки тысяч демонов соперничают друг с другом. Каждый демон реагирует только на одно слово и сообщает об этом криком. Всякий раз, когда на сетчатке возникает цепочка букв, все демоны «разглядывают» ее одновременно. Те, кто «видит» свое слово, громко вопят. Таким образом, когда появляется слово «scream» («крик»), отвечающий за него демон начинает кричать. Вместе с ним голосит и его сосед, который кодирует слово «cream» («сливки»). Так «scream» или «cream»? После непродолжительного состязания защитник «сливок» вынужден уступить – ясно, что его противник получил более сильную поддержку от стимульной строки «s‑c‑r‑e‑a‑m». В этот момент слово распознается, и соответствующая информация может быть передана остальной системе.
За кажущейся простотой этой метафоры скрывается несколько ключевых идей о том, как именно функционирует нервная система во время чтения:
• МАССОВАЯ ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА: все демоны работают одновременно. В результате нет никакой необходимости исследовать каждое из 50 000 слов в нашем ментальном словаре одно за другим. Следовательно, массовый параллелизм пандемониума приводит к существенной экономии времени.
• ПРОСТОТА: каждый демон выполняет элементарную задачу – он проверяет, в какой степени стимульные буквы соответствуют его целевому слову. Таким образом, модель пандемониума успешно обходится без гомункула, или маленького человечка, который, согласно народной психологии, управляет нашим мозгом. (А кто управляет его мозгом? Второй, совсем крошечный гомункул?) В этом отношении модель пандемониума можно сравнить с девизом философа Дэна Деннета: «Человек выбрасывает из схемы воображаемого гомункула и заменяет его армией идиотов, которые и выполняют всю работу»[84].
• КОНКУРЕНЦИЯ И НАДЕЖНОСТЬ: демоны борются за право представлять правильное слово. Конкуренция обеспечивает гибкость и надежность. Пандемониум автоматически приспосабливается к сложности поставленной задачи. Когда вокруг нет соперников, даже такое редкое, неправильно написанное слово, как «astrqlabe»[85], может быть распознано очень быстро – представляющий его демон, даже если изначально он кричит тихо, в конце концов одержит победу. Другое дело, если стимулом будет такое слово, как «lead». В этом случае активизируются многие демоны (например, «bead», «head», «read», «lean», «leaf», «lend» и прочие). Лишь после ожесточенных споров демон слова «lead» сумеет взять верх.
Все эти свойства (в упрощенном виде) согласуются с основными характеристиками нашей нервной системы. Человеческий мозг, состоящий почти из 100 миллиардов (1011) клеток, представляет собой архетип массово‑параллельной системы, где все нейроны работают одновременно. Связи, которые их соединяют, так называемые синапсы, передают информацию о внешнем сенсорном стимуле. Некоторые из этих синапсов являются ингибирующими (тормозящими). Это означает, что при срабатывании исходного нейрона происходит подавление возбуждения других нервных клеток. Канадский нейрофизиолог Дональд Хебб уподобил результат сети «клеточных ансамблей» – коалиций нейронов, постоянно конкурирующих между собой. По этой причине неудивительно, что пандемониум Селфриджа послужил источником вдохновения для многих теоретических моделей нервной системы, включая первые нейросетевые модели чтения. На рис. 1.5 показана одна из самых ранних моделей, предложенная Джеем Макклелландом и Дэвидом Румельхартом в 1981 году[86]. Она включает три иерархических уровня нейроноподобных модулей:
• Нижние входные модули чувствительны к линейным сегментам, отображаемым на сетчатке глаза.
• В середине находятся детекторы букв, которые срабатывают всякий раз, когда появляется определенная буква.
• Верхние модули кодируют целые слова.
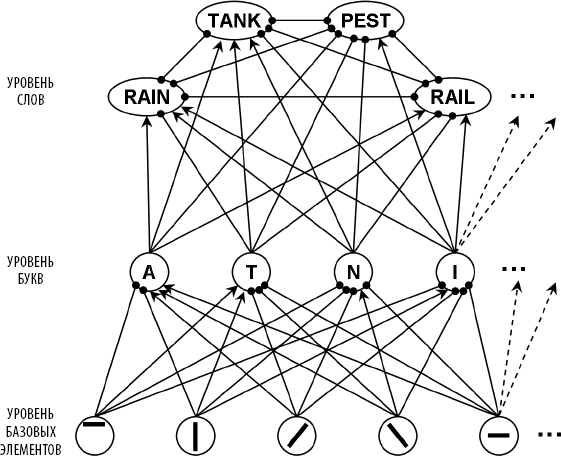
Рис. 1.5. Процесс идентификации слов подобен обширному собранию, где тысячи буквенных и словесных модулей сообща пытаются обеспечить наилучшую интерпретацию входной буквенной цепочки. В модели Макклелланда и Румельхарта, фрагмент которой приведен на рисунке, базовые характеристики входной цепочки активируют детекторы букв, а те подключаются к детекторам соответствующих слов. Связи могут быть возбуждающими (стрелки) или тормозящими (линии с черными кружками на конце). Конкуренция между лексическими модулями в конечном счете позволяет идентифицировать доминирующее слово – наиболее подходящую гипотезу о поступающей буквенной цепочке, которую выбирает сеть.
Все они соединены многочисленными связями. Подобное взаимодействие (коннективность) превращает сетевую динамику в сложную политическую игру, в которой буквы и слова поддерживают, критикуют или исключают друг друга. Если вы внимательно посмотрите на рисунок, то увидите возбуждающие связи, обозначенные стрелочками, и ингибирующие связи, обозначенные кружочками. Их роль заключается в распространении голосов каждого из демонов. Входной детектор, кодирующий некий базовый элемент, например вертикальную черту, посылает сигнал всем буквам, содержащим этот специфический компонент. Иными словами, каждый зрительный нейрон «голосует» за ту или иную букву. На следующем уровне детекторы букв избирают целые слова, стимулируя соответствующие им модули. Наличие букв «А» и «N», например, поддерживает слова «RAIN» и «TANK», частично выступает в пользу слова «RAIL», но совсем не реагирует на слово «PEST».
Не менее важную роль в отборе наилучшего кандидата играет и торможение. Благодаря тормозящим связям буквы могут «голосовать» против слов, которые их не содержат. Например, модуль, кодирующий букву «N», выступает против слова «RAIL» и оказывает на него сдерживающее влияние. Кроме того, конкурирующие слова подавляют друг друга. Таким образом, идентификация слова «RAIN» несовместима с присутствием слова «RAIL», и наоборот.
Нисходящие связи ведут от слов к составляющим их буквам. Этот процесс можно сравнить с сенатом, где буквы представлены словами. Слова же активно поддерживают буквы, которые за них «проголосовали». Взаимные связи позволяют создавать устойчивые коалиции, способные компенсировать случайное отсутствие буквы. Например, если в слове «крокдил» отсутствует «o», то его соседи все равно «изберут» слово «крокодил», а последний «проголосует» за наличие средней буквы «о», которой физически нет. В целом для интеграции многочисленных статистических ограничений, объединяющих уровни слов, букв и базовых элементов, требуются миллионы связей.
Другие тонкости позволяют всей сети работать бесперебойно. Например, словесным модулям могут быть присущи разные пороги активации. Слово, которое встречается часто, характеризуется более низким порогом, нежели редкое слово, и при равной восходящей поддержке имеет больше шансов на «победу». Самые последние модели также осуществляют подробное кодирование позиции буквы в слове. Такая сеть обладает столь сложной динамикой, что полностью описать ее математически невозможно. Приходится прибегать к компьютерным симуляциям – только так мы можем установить, сколько времени требуется системе, чтобы определить правильное слово и то, как часто она ошибается.
Параллельное чтение
Если когнитивисты до сих пор не отказались от всех подобных сложных моделей чтения, то это потому, что их прогнозы отлично согласуются с эмпирическими данными. Модели, вдохновленные идеей пандемониума Селфриджа, не только воспроизводят результаты классических экспериментов по скорости чтения и ошибкам, но и позволяют открыть новые явления, составляющие фундаментальные свойства нашего считывающего аппарата.
Допустим, вас попросили разработать программное обеспечение для распознавания письменной речи. Независимо от того, какое решение вы выберете, на длинных словах ваша программа, скорее всего, будет работать медленнее. Для программы, например, совершенно естественно обрабатывать буквы одну за другой, слева направо. В силу постепенной обработки можно ожидать, что слово из шести букв займет примерно вдвое больше времени, чем слово из трех букв. В любой последовательной модели время распознавания должно увеличиваться прямо пропорционально количеству букв.
Но это – машина. Для человеческого мозга правило «время чтения прямо пропорционально количеству букв» не выполняется. У грамотных взрослых время, затраченное на чтение слова, практически не зависит от его длины. Иначе говоря, если слова содержат не более шести или семи букв, их распознавание занимает приблизительно такое же количество времени, как и коротких[87]. Это значит, что наш мозг задействует механизм параллельной обработки букв, то есть он может обрабатывать все буквы одновременно. Этот результат несовместим с метафорой компьютерного сканера, зато в точности согласуется с гипотезой пандемониума, в рамках которой миллионы специализированных процессоров работают одновременно и параллельно на каждом из нескольких уровней (базовые элементы, буквы и слова).
Активное декодирование букв
Продолжим эту компьютерную метафору. В классической компьютерной программе информация обычно обрабатывается в несколько последовательных этапов – от простейших операций до самых сложных. Наиболее логичная цепочка выглядит так: первая подпрограмма распознает отдельные буквы, вторая группирует их в графемы, третья исследует потенциальные слова. Проблема в том, что такие программы, как правило, крайне нетерпимы к ошибкам. Любой сбой на первом этапе обычно приводит к срыву всего процесса распознавания. Даже самое лучшее программное обеспечение для определения символов, которое имеют современные сканеры, очень чувствительно к качеству изображения – несколько пылинок на сканирующем окне могут превратить идеальную страницу в искаженный текст, который компьютер считает тарабарщиной.
В отличие от машины, наша зрительная система обожает разрешать двусмысленности. Хотите убедиться в этом сами? Прочтите следующее предложение:
На шерраее шуршиш оеенняя лисшва[88].
Только что ваш взгляд успешно преодолел целый ряд сложностей, которые поставили бы в тупик любую классическую компьютерную программу. Вы заметили, что в слове «террасе» буквы «с» и «е» на самом деле написаны одинаково? То же самое мы видим в слове «осенняя», но ваша зрительная система воспринимает первую букву как «с», а вторую – как «е». Слово «шуршит» еще хуже. Буквы «ш», «т» и «и» так похожи![89] Подобные сложности разрешаются контекстом: цепочка букв «иуртиш» едва ли существует, а вот вариант «шуршит» отлично вписывается в остальное предложение.
Таким образом, неоднозначности, которые привели бы к сбою в любой машине, человек даже не воспринимает. Эта устойчивость к ошибкам, практически несовместимая с классической компьютерной программой, прекрасно согласуется с идеей пандемониума, где буквы, графемы и слова поддерживают друг друга за счет множества избыточных связей. Тайного «сговора» букв, слов и контекста достаточно, чтобы обеспечить необычайную надежность нашего считывающего аппарата. Альберто Мангуэль был прав: именно читатель придает смысл написанному тексту – его «опытный взгляд» вдыхает жизнь в то, что иначе осталось бы мертвой буквой. Идентификация букв и слов есть результат активного нисходящего процесса декодирования, в рамках которого мозг посылает к зрительному сигналу ту или иную информацию.
Психологи обнаружили любопытное проявление этого активного процесса декодирования – так называемый эффект превосходства слова. В классическом эксперименте Джеральда Райхера[90] взрослых испытуемых просят определить, какая из двух возможных букв (например, «D» или «T») появляется на экране. Уровень сложности корректируется таким образом, чтобы человек лишь изредка давал правильный ответ. Иногда буква показывается одна («D» или «T»), а иногда – в контексте других букв, образующих слово (например, «HEAD» или «HEAT»[91]). Обратите внимание, что дополнительные буквы не добавляют никакой полезной информации. Поскольку в обоих случаях присутствуют одни и те же начальные сочетания «HEA‑», испытуемые должны принять решение исключительно на основе последней буквы. Как ни странно, все они гораздо хуже справлялись с задачей, если буква высвечивается на экране одна, а не в сопровождении трех других! Идентификация улучшается в разы, когда буква представлена в контексте слова. Похоже, предъявление целого слова помогает частично устранить шум во входном стимуле. Этот эффект сохраняется даже в том случае, если буква находится в составе неологизма («GERD» или «GERT»[92]) или в цепочке согласных, которая выглядит как настоящее слово («SPRD» или «SPRT»[93]). Однако это не работает со случайными последовательностями («GQSD» или «GQST»)[94].
Опять же это явление трудно объяснить с помощью линейной модели обработки информации, в которой идентификация отдельных букв обязательно предшествует их объединению в более крупные единицы. Эффект превосходства слова, напротив, подчеркивает избыточность и параллелизм процедур зрительного распознавания слов. Даже когда мы сосредотачиваем внимание на одной букве, мы автоматически обращаемся к контексту, в который она помещена. Если этот контекст является словом или его фрагментом, он дает нам доступ к большему количеству уровней кодирования (графемы, слоги и морфемы), чьи «голоса» добавляются к «голосам» букв и облегчают их восприятие. Большинство моделей чтения объясняют эффект превосходства слова следующим образом: буквы и слова взаимодействуют в рамках двустороннего процесса – детекторы графем и детекторы слов более высокого уровня поддерживают обнаружение букв, совместимых с интерпретацией исходной цепочки. Проще говоря, то, что мы видим, зависит от нашего восприятия.
Конкуренция в чтении
Итак, компьютерная метафора, сравнивающая человека со сканером, некорректна. Расшифровка слова не происходит строго последовательно, а время, необходимое для его чтения, не связано с количеством букв в нем. Поэтому вернемся к модели пандемониума, где распознавание осуществляется собранием демонов. Время, которое ему требуется для принятия важного решения («время конвергенции»), зависит не столько от содержания самой проблемы, сколько от споров, которые она вызывает. Когда все сенаторы согласны, самый сложный закон будет принят без длительных прений. И наоборот, даже незначительный вопрос, если он затрагивает деликатную проблему, может обернуться ожесточенными дебатами.
Исследования чтения показывают, что мозг во время этого процесса во многом ведет себя как ментальный сенат. Распознавание слова требует того, чтобы все задействованные системы пришли к согласию относительно интерпретации входящей информации. Таким образом, время, необходимое на чтение слова, в первую очередь зависит от конфликтов и коалиций, которые оно порождает в структуре коры.
Специалисты по экспериментальной психологии обнаружили, что конфликты могут возникать на всех уровнях обработки слова. Например, было установлено, что слова из ментального лексикона конкурируют со своими «соседями» – словами, которые отличаются от них всего на одну букву[95]. Так, слово «сом» сожительствует со словами «дом», «ком», «лом», «ром», «том», «сам», «сок», «сон» и «сор»[96], а слово «идея» – одинокий отшельник, «живущий» один. Опыт показывает, что количество соседей слова, в особенности их относительная частотность, играют ключевую роль в скорости, с которой мы это слово распознаем[97].
Во многих случаях наличие соседей помогает. Чем больше таковых имеет слово, тем быстрее мы можем определить, что оно принадлежит к лексикону нашего родного языка. Так, наличие соседей делает слово «сом» более типичным для русской орфографии, чем слово «идея». Кроме того, плотно заселенные «кварталы» обеспечивают больше возможностей для обучения. Например, у нас гораздо больше шансов запомнить написание и произношение слов, которые заканчиваются на «‑ом», чем одного слова, заканчивающегося на «‑дея». Поэтому этот «изгой» хуже кодируется как на зрительном, так и на фонологическом уровне.
Впрочем, много соседей – это не всегда хорошо. Как правило, чтобы понять или назвать слово, необходима однозначная идентификация. Следовательно, отделение от всех соседей – операция, требующая времени и усилий, особенно в том случае, если те употребляются часто, а, значит, выигрывают в лексической конкуренции. Например, называние слова «сом» происходит относительно медленно, поскольку оно конкурирует с такими часто встречающимися словами, как «сон»[98] и «сок»[99]. Наш лексикон – это арена, на которой идет жестокая борьба, причем более употребляемые слова имеют выраженное преимущество.
Конкуренция возникает и в рамках фонологического маршрута, преобразующего буквы в звуки. Например, чтобы вслух прочитать слово «beach», носителю английского языка требуется больше времени, чем слово «black». В слове «beach» исходная буквенная цепочка разбивается на сложные графемы «ea» и «ch», произношение которых отличается от произношения отдельных букв «e», «a», «c» или «h». Слово «black» проще, поскольку каждая из его букв непосредственно соответствует закрепленному за ней звуку. Чтобы продемонстрировать скрытый конфликт между уровнем букв и уровнем графем, обратимся к экспериментальной психологии. Как показывают исследования, определение слова, состоящего из сложных графем, включает короткий период бессознательной конкуренции, которая ведет к замедлению реакции. В результате называние слов с диграфами занимает больше времени, чем в случае с простыми словами, такими как «black»[100].
Примечательно, что большинство этих конфликтов разрешаются автоматически, без вмешательства сознания. Базовая стратегия, к которой прибегает наша нервная система при столкновении с неоднозначностью, состоит в том, чтобы не исключать ни одного возможного варианта. Разумеется, это выполнимо только в системе с множеством параллельных путей, обеспечивающих одновременное исследование нескольких интерпретаций. Ввиду такой открытой организации последующие уровни анализа могут делиться своими соображениями, пока не будет достигнуто решение, удовлетворяющее всех участников процесса. В некоторых случаях только контекст позволяет установить значение слова или его произношение. Возьмем следующее предложение: «Принц запер замок на замок»[101]. Эксперименты показывают, что в таких случаях мозг бессознательно активирует все возможные интерпретации слова, пока контекст не ограничит толкование одним значением[102]. К счастью, наши процессы чтения настолько эффективны, что мы редко осознаем подобные двусмысленности – если только они не очень смешные, как в случае с писательницей Дороти Паркер, которая во время медового месяца пропустила срок сдачи рукописи. «Скажите редактору, – попросила она своего агента, – что я была занята. Дела, знаете ли… Если честно, я просто затрахалась. Ну или без “за”»[103].





