Алгоритм “первого подходящего”. При очередном запросе на выделение памяти администратор кучи подбирает в списке свободных блоков первый встретившийся блок, размер которого не меньше требуемого. В среднем необходим просмотр половины всего списка свободных блоков. Недостаток этого алгоритма заключается в том, что он не сохраняет крупные свободные блоки.
Алгоритм “наиболее подходящего”. При очередном запросе на выделение памяти администратор кучи подбирает в списке свободных блоков наименьший блок, размер которого больше или равен запросу. Алгоритм “наиболее подходящего” обеспечивает сохранение более крупных свободных блоков, но может потребовать просмотра всего списка свободных блоков. Кроме того, со временем этот алгоритм имеет тенденцию к созданию большого количества свободных блоков малого размера, которые не смогут удовлетворить ни один запрос на выделение памяти. Администратор кучи Turbo Pascal реализует алгоритм “наиболее подходящего”.
Для того чтобы уменьшить количество просмотров списка свободных блоков используются модификации этих алгоритмов. Можно сохранять в специальном указателе адрес свободного блока наибольшего размера и начинать поиск именно с этого блока. Поиск можно начинать с того блока, который был освобожден последним. Свободные блоки можно упорядочить по возрастанию или уменьшению их размеров, но тогда потребуется дополнительно хранить в дескрипторе каждого свободного блока начальный адрес этого блока.
Алгоритм “близнецов”. Идея этого алгоритма состоит в том, что организуются списки свободных блоков отдельно для каждого размера 2k, 0 <= k <= m. Вся область памяти кучи состоит из 2m слов, которые, можно считать, имеют адреса с 0 по 2m – 1. Первоначально свободным является весь блок из 2m слов. Далее, когда требуется блок из 2k слов, а свободных блоков такого размера нет, расщепляется на две равные части блок большего размера; в результате появится блок размера 2k (т.е. все блоки имеют длину, кратную 2). Когда один блок расщепляется на два (каждый из которых равен половине первоначального), эти два блока называются близнецами. Позднее, когда оба близнеца освобождаются, они опять объединяются в один блок. Преимуществом этого алгоритма является скорость, но его реализация усложняется за счет необходимости вести систему списков свободных блоков.
Фрагментация
Если блоки переменной длины выделяются или освобождаются в произвольном порядке, то список свободных блоков может стать очень длинным, особенно если блоки при освобождении не укрупняются. Это приводит к ситуации, когда в ответ на очередной запрос о выделении памяти размера size байт в куче не окажется непрерывного свободного участка требуемого размера, т.е. MaxAvail < size, в то время как суммарный объем свободной памяти достаточен для выполнения запроса, т.е. MemAvail >= size. Разбиение всей доступной памяти области кучи на большое количество блоков относительно малого размера называется внешней фрагментацией.
Внутренняя фрагментация связана с появлением неиспользуемых, но и недоступных участков памяти. Внутренняя фрагментация порождается, в частности, механизмом формирования списка свободных блоков. Так, если запрашиваемый размер памяти не кратен восьми байтам, в куче образуется “дырка” размером 1-7 байт, причем этот участок не может использоваться ни при каком другом запросе динамической памяти до того момента, когда связанный с ним объект не будет удален из кучи. Внутренняя фрагментация может возникнуть также вследствие реализации алгоритма резервирования блоков, имеющих размер, больший запрошенного (т.е. за счет отказа от деления блока на части, одна из которых может оказаться совсем маленькой). Внутреннюю фрагментацию могут вызвать сами пользователи, резервируя память “про запас”, заведомо большего размера, чем может понадобиться в текущий момент выполнения программы. Внутренняя фрагментация приводит к ситуации, когда на некоторый запрос будет получен отказ из-за отсутствия блоков требуемого размера, хотя зарезервированной, но не используемой памяти более чем достаточно для удовлетворения запроса, т.е. MaxAvail < size, MemAvail < size, где siz e – размер запроса.
Накопление мусора
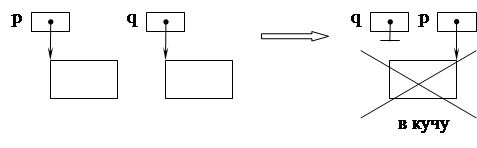
Мусором называются блоки памяти, доступ к которым во время выполнения программы оказался потерян, так что эти блоки больше не используются, но и не могут быть возвращены в кучу. Возникновение мусора иллюстрирует программный фрагмент и рис. 48.
...
var p,q: PList;
begin
new (p); new (q);
…
p:=q;...
end;
Рис. 48. Возникновение мусора
В результате накопления мусора уменьшается объем доступной свободной памяти и возрастает вероятность отказа на запрос о выделении памяти. Существуют специальные программы, называемые “сборщиками мусора ”. Они могут быть вызваны, когда запасы имеющейся памяти почти исчерпаны или когда невозможно удовлетворить очередной запрос на выделение памяти, или когда размер доступной области памяти стал меньше некоторого заранее заданного числа. На время работы сборщика мусора нормальное выполнение программы приостанавливается. Алгоритм сбора мусора обычно выполняется в два этапа. На первом этапе осуществляется просмотр всех указателей от всех программных объектов ко всем зарезервированным блокам. Каждый блок, к которому есть доступ, маркируется. На втором этапе просматривается вся куча, метки у маркированных блоков стираются, а все блоки, которые не были отмечены, возвращаются в список свободной памяти. Сбор мусора снижает эффективность выполнения программы, особенно если свободная память практически исчерпана, поэтому многие администраторы динамической памяти (в частности, в Turbo Pascal) не используют сборщики мусора. Контроль за предотвращением возникновения мусора возлагается на программиста.
Висящие ссылки
Висящая ссылка (указатель) - это существующий в программе указатель, который открывает доступ к уже несуществующему объекту (т.е. к уже освобожденному участку памяти). Возникновение висящей ссылки иллюстрирует программный фрагмент и рис. 49.
...
var p,q: PList;
begin
new (p); q:=p;
...
dispose(p); p:=nil;
{ q – висящая ссылка }
end;
Рис. 49. Возникновение висящей ссылки
Если освобожденный блок будет вновь зарезервирован, а затем к нему применен висящий указатель, то программа вновь обратится к этому блоку, который теперь предназначен совсем для других целей. Ошибочное использование висящего указателя иллюстрирует программный фрагмент и рис. 50.
Type
PT1 = ^ T1; PT2 = ^ T2;
T1 = record T2 = record
x, y: word a: byte; b: char; c: integer
 end; end;
end; end;
Var p, q: PT1; r: PT2;
...
new (p);
readln (p^.x, p^.y);
q:=p;
...
dispose (p); p:=nil;
...
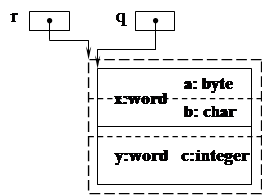 new (r);
new (r);
readln(r^.a);
readln(r^.b);
readln(r^.c);
...
writeln(q^.x); {? }
writeln(q^.y); {? }
Рис. 50. Ошибочное применение висящего указателя
Через указатель q по-прежнему видна структура, соответствующая объекту типа Т1 с атрибутами х и у, ранее размещенному в том блоке памяти, который позже был зарезервирован для объекта типа Т2 с атрибутами а, в, с. Результат применения в программе висящей ссылки приводит к ошибкам, которые трудно обнаружить, поэтому висящие ссылки “опаснее” накопления мусора.
Проблему висящих ссылок можно было бы решить, если бы администратор реализовывал метод счетчиков ссылок. В этом методе для каждого зарезервированного блока имеется счетчик, показывающий, сколько объектов программы имеют непосредственный доступ к этому блоку, т.е. указатель на него. Когда некоторый блок резервируется впервые, его счетчик ссылок устанавливается в 1. Каждый раз, когда создается связь между некоторым идентификатором и этим блоком, значение счетчика ссылок увеличивается на 1; каждый раз, когда такая связь уничтожается, значение счетчика ссылок уменьшается на 1. Когда значение счетчика ссылок становится равным нулю, соответствующий блок оказывается недоступным, а, следовательно, неиспользуемым. В этот момент он возвращается в список свободной памяти. Однако ведение счетчиков ссылок может значительно увеличить время исполнения программы, поэтому в администраторах этот метод практически не используется, а контроль за отсутствием висящих ссылок возлагается на программиста.
5. множественная интерпретация объектов
5.1. Совместимость типов. Приведение и преобразование типов
Языки программирования со строгой типизацией построены на основе соблюдения концепции типов, в соответствии с которой все операции, определенные в языке, могут применяться только к операндам совместимых типов. Два типа считаются совместимыми, если:
¨ оба ини есть один и тот же тип;
¨ оба вещественные;
¨ оба целые;
¨ один тип есть тип-диапазон второго типа;
¨ оба являются типами-диапазонами одного и того же базового типа;
¨ оба являются множествами, составленными из элементов одного и того же базового типа;
¨ один тип – есть тип-строка, а другой – тип-строка или символ;
¨ один тип есть любой указатель, а другой – нетипизированный указатель;
¨ оба есть процедурные типы с обинаковым типом результата (для функций), количеством параметров и типом взаимно соответствующих параметров.
Два объекта совместимы по представлению, если размеры их элементов хранения равны. Объекты совместимы по присваиванию, если в элемент хранения объекта одного типа может быть занесено значение элемента хранения другого объекта или значение выражения. Совместимость по присваиванию реализуется через приведение и преобразование типов.
Приведение типа возможно только для объектов, совместимых по представлению. Приведение типа состоит в следующем: определяя тип объекта, мы определяем представление (структуру) элемента хранения объекта данного типа. Но если “взглянуть” на образ объекта в памяти с точки зрения машинного представления другого типа, то можно трактовать тот же самый элемент хранения как принадлежащий другому типу. Для этого используются функции приведения типов:
Функция приведения:
Имя_типа (Имя_переменной)
Имя_типа (Выражение).
Функции приведения типа определены как для стандартных, так и для пользовательских типов. Функции приведения типов могут использоваться как в левой, так и в правой части оператора присваивания, т.к. приведение типа не изменяет внутреннего представления объекта, а изменяет только его интерпретацию.
| Type
|
|
| Rec = array [1…4] of byte;
|
|
| Var A: Rec; L: longint; b: byte; w: word;
|
|
| begin
|
|
| А [1]: = …; А [2]: =…; А [3]: =…; А[4]: =…;
| { инициализация массива }
|
| L: = LongInt (А);
| { приведение типа Rec к типу LongInt в правой части оператора присваивания }
|
| ...
|
|
| L: = 123456;
| { инициализация переменной L }
|
| b: = Rec (L) [3];
| { приведение типа LongInt к типу Rec в правой части оператора присваивания }
|
| Rec (L) [1]: = 10;
| { приведение типа LongInt к типу Rec в левой части оператора присваивания }
|
| ...
|
|
| w:=word(-6);
| { приведение типа Integer к типу Word: w = 65530 (см. 1.1.1) }
|
| end.
|
|
| | | | | | |
Преобразование типа изменяет внутреннее представление объектов, т.е. их элементы хранения. При выполнении преобразования к типу большей мощности, у которого размер элемента хранения больше, значения атрибутов объекта будут целиком записаны в младшие байты. Если выполняется преобразование к типу меньшей мощности, от элемента хранения объекта берутся только младшие байты. Таким образом, в результате преобразования типа длина внутреннего представления объекта может как увеличиться, так и уменьшиться.
Преобразование типа может быть явным, неявным и автоопределенным. Неявное преобразование возможно в выражениях, составленных из вещественных и целочисленных переменных, переменные типа INTEGER автоматически преобразуются к типу REAL, и все выражение в целом приобретает вещественный тип. Явные преобразования связаны с использованием специальных функций преобразования, определенных в языке, аргументы которых принадлежат одному типу, а значения - другому.
| function Chr (X: byte): char;
| { возвращает символ с заданным порядковым номером X }
|
| function Ord (X: любой порядковый тип): longint;
| { возвращает порядковый номер, соответ- ствующий значению X порядкового типа }
|
| function Odd (X: любой порядковый тип): boolean;
| { проверяет, является ли аргумент нечетным числом }
|
| function Round (R: real): longint;
| { округляет значение R вещественного типа до ближайшего целого }
|
| function Trunc (R: real): longint;
| { усекает значение вещественного типа путем отбрасывания дробной части }
|
| function Hi (X: word): byte;
| { возвращает старший байт аргумента X }
|
| function Lo (X: word): byte;
| { возвращает младший байт аргумента X }
|
Автоопределенное преобразование связано с использованием только в правой части оператора присваивания функций преобразования вида:
Имя_типа (Имя_переменной)
Имя_типа (Выражение).
Функции преобразования типа определены как для стандартных, так и для пользовательских типов.
| Var L: longint; W: word;
|
|
| begin
|
|
| integer (‘d’);
| { преобразованием типа Char к типу Integer }
|
| byte (534);
| { преобразование типа Word к типу Byte }
|
| ...
|
|
| W:=word (L);
| { преобразование типа LongInt к типу Word }
|
| ...
|
|
| end.
|
|
Методы совмещения типов
Различные методы совмещения типов связаны с маскированием. Маскирование позволяет изменить интерпретацию данных, содержащихся в элементах хранения объектов. Маска – это некоторый тип данных, определяющий вид интерпретации. Накладывая различные маски на одну и ту же область памяти, можно рассматривать размещенные в ней данные как принадлежащие объектам различных типов. Маскирование может быть реализовано с помощью средств, встроенных в язык программирования, или с помощью указателей. Средства языка PASCAL, реализующие совмещение типов:
¨ записи с вариантной частью,
¨ директива ABSOLUTE,
¨ параметры процедур и функций без типа,
¨ открытые массивы.
5.2.1. Запись с вариантной частью
Запись с вариантной частью используется для работы с объектами различной структуры как с переменными одного и того же типа. Запись с вариантной частью состоит из одного или нескольких фиксированных полей (полей фиксированного размера) и единственной вариантной части, которая должна располагаться в конце записи.
Type
Rec =record
f1: integer;
case f2: boolean of
false: (f3, f4, f5: char);
true: (f6: word)
end;
Var r1, r2: rec;
Вариантная часть задается предложением вида:
Case селектор_вариантов of …
В конце вариантной части не следует ставить END как пару к CASE…OF. (Поскольку вариантная часть - всегда последняя в записи, за ней все же стоит END, но лишь как пара к RECORD). Селектор вариантов может быть именованным или неименованным, должен иметь любой порядковый тип (стандартный или пользовательский). Вариантная часть состоит из нескольких вариантов. Каждый вариант определяется константой выбора, за которой следует двоеточие и список полей данного варианта, заключенный в круглые скобки. Селектор варианта может принимать значение любой константы выбора.
Особенностью вариантной части является то, что все заданные в ней варианты “накладываются” друг на друга и используют одну и ту же область памяти (рис. 51). В элементе хранения конкретного объекта типа записи с вариантами всегда присутствует единственный вариант.
Рис. 51. Элементы хранения объектов, использующих запись с вариантной частью
Размер элемента хранения объектов, содержащих запись с вариантами, определяется размером самого длинного варианта:
Sizeof (Rec) = Sizeof (f1) + Sizeof (f2) + max { Sizeof (f3) + Sizeof (f4) + Sizeof (f5), Sizeof (f6) }.
Sizeof (Rec) = 6.
Таким образом, компилятор не отводит отдельную область памяти для каждого варианта, а выделяет участок памяти, достаточный для размещения варианта самого большого размера.
При использовании именованного селектора в целях дополнительного контроля следует присваивать значение селектору перед тем, как присвоить значения полям варианта, а также проверять значение селектора перед обращением к полям варианта.
Записи с вариантами применяются для описания узлов разнородных списков. Рассмотрим разнородный список, содержащий информацию о геометрических фигурах, составляющих некоторый проект (см. 4.8). Элемент хранения узла разнородного списка содержит фиксированные поля, которые располагаются в начале записи: связь в списке, координаты точки, относительно которой строится фигура. Далее рсполагается поле селектора вариантов и поля вариантов, соответствующие трем типам геометрических фигур.
| Type
|
|
| Figure = (circle, rectangle, triangle);
| { тип фигуры }
|
| PPolygon = ^ Polygon;
| { указатель на эл-т хранения узла разнородного списка }
|
| Polygon = record
| { эл-т хранения узла разнородного списка }
|
| link: PPolygon;
| { связь в списке }
|
| x,y: word;
| { координаты точки, относительно которой строится фигура }
|
| case kind: Figure of
| { селектор варианта, определяющий тип фигуры }
|
| circle: (radius: word);
| { окружность }
|
| rectangle: (height, width: word);
| { прямоугольник }
|
| triangle: (x1,y1,x2,y2: word)
| { треугольник }
|
| end;
|
|
|
|
|
| Var f: PPpolygon;
| { указатель на первый узел списка }
|
|
|
|
| { создание элемента хранения узла и занесение его в разнородный список }
|
| Procedure Create_Node(var first: PPolygon; t: Figure);
| { t – тип фигуры }
|
| Var p: PPolygon;
| { first – указатель на первый узел списка }
|
| begin
|
|
| new(p);
|
|
| writeln(‘введите координаты точки, относительно которой строится фигура’);
|
|
| write(‘x=’); readln(p^.x);
|
|
| write(‘y=’); readln(p^.y);
|
|
| p^.kind:=t;
| { заполнение поля селектора вариантов }
|
| case t of
| { заполнение полей вариантов в зависимости от типа фигуры: }
|
| circle:
| { окружность }
|
| begin write(‘введите значение радиуса = ’); readln(p^.radius) end;
|
|
| rectangle:
| { прямоугольник }
|
| begin
|
|
| write(‘введите значение высоты = ’); readln(p^.height);
|
|
| write(‘введите значение ширины = ’); readln(p^.width)
|
|
| end;
|
|
| triangle:
| { треугольник }
|
| begin
|
|
| writeln(‘введите координаты второй вершины’);
|
|
| write(‘x=’); readln(p^.x1);
|
|
| write(‘y=’); readln(p^.y1);
|
|
| writeln(‘введите координаты третьей вершины’);
|
|
| write(‘x=’); readln(p^.x2);
|
|
| write(‘y=’); readln(p^.y2);
|
|
| end;
|
|
| end;
|
|
| p^.link:=first; first:=p;
| { включение элемента хранения узла в список }
|
| end;
|
|
|
|
|
| Procedure Print(first: PPolygon);
| { просмотр содержимого разнородного списка }
|
| Var p: PPolygon;
|
|
| begin
|
|
| p:=first;
|
|
| while p <> nil do begin
|
|
| writeln(‘координаты точки, относительно которой построена фигура’);
|
|
| writeln(‘x= ‘, p^.x, ‘y= ‘, p^.y);
|
|
| case p^.kind of
| { проверка значения поля селектора вариантов: }
|
| circle:
| { окружность }
|
| writeln(‘радиус окружности = ‘, p^.radius);
|
|
| rectangle:
| { прямоуглоьник }
|
| writeln(‘высота прям-ка = ’, p^.height, ‘ширина прям-ка = ‘, p^.width);
|
|
| triangle:
| { треугольник }
|
| begin
|
|
| writeln(‘координаты второй вершины треугольника‘);
|
|
| writeln(‘x= ‘, p^.x1, ‘y= ‘, p^.y1);
|
|
| writeln(‘координаты третьей вершины треугольника‘);
|
|
| writeln(‘x= ‘, p^.x2, ‘y= ‘, p^.y2);
|
|
| end;
|
|
| end;
|
|
| p:=p^.link
|
|
| end;
|
|
|
|
|
| ...
|
|
| Procedure Destroy(var first: PPolygon);
| { разрушение разнородного списка }
|
| begin
|
|
| ...
|
|
| end;
|
|
|
|
|
| begin
|
|
| f:=nil;
| { первоначально список пуст }
|
| Create_Node(f,rectangle);
|
|
| Create_Node(f,triangle);
|
|
| Create_Node(f,rectangle);
|
|
| Create_Node(f,circle);...
|
|
| Print(f);...
|
|
| Destroy(f);
|
|
| end.
|
|
| | | | | | | | | | | | |
Неименованный селектор вариантов используется для приведения типов (память для него в элементе хранения объекта не отводится).
| Type
|
|
| Mem = record
|
|
| case byte of
|
|
| 0: (byt: array [1..4] of byte );
|
|
| 1: (wo: array [1..2] of word );
|
|
| 2: (l: longint)
|
|
| end;
|
|
| Var m: Mem; w: word; b: byte;
|
|
| begin
|
|
| m.l:=123456;
| { инициализация переменной типа Mem значением типа LongInt }
|
| b:=m.byt[4];
| { преобразование типа Mem к типу Byte }
|
| w:=m.wo[1];
| { преобразолвание типа Mem к типу Word }
|
| ...
|
|
| | | |
Sizeof (Mem) = 4.
Объект m имеет три варианта, каждый из которых размещается в одном и том же элементе хранения размером 4 байта. В зависимости от того, к какому полю записи происходит обращение в программе, элемент хранения объекта m трактуется как массив из четырех байтов, массив из двух слов или длинное целое число.
5.2.2. Использование директивы ABSOLUTE
Совмещение данных в памяти может быть достигнуто при явном размещении данных разного типа по одному и тому же абсолютному адресу. Для размещения объекта по нужному абсолютному адресу после идентификатора и типа объекта следует указать стандартную директиву ABSOLUTE, за которой следует либо абсолютный адрес, либо идентификатор ранее определенного объекта. Абсолютный адрес задается парой чисел типа WORD (как правило, в шестнадцатиричном формате), разделенных двоеточием, причем первое число трактуется как сегмент, а второе – как смещение адреса.
Var b: byte absolute $0000: $0100;
Тип объекта, описанного с директивой absolute, является маской и определяет вид интерпретации данных, находящихся по заданному адресу. При определении переменной с директивой absolute фактически происходит наложение маски на область памяти по заданному адресу. Обращение к этой переменной в программе позволяет соответствующим образом интерпретировать данные, находящиеся по этому адресу.
Если за директивой absolute указан идентификатор ранее определенного объекта, то в памяти происходит совмещение данных различных типов, причем младшие байты внутреннего представления этих данных будут располагаться по одному и тому же абсолютному адресу.
Type MI = array [1..3] of integer; { маска }
Var x: real; { интерпретируемая область памяти }
y: MI absolute x; { наложение маски }
begin
x:=…; { инициализация переменной x }
writeln(y[2]); { интерпретация данных, хранящихся в переменной x,
через маску }
Eсли происходит совмещение объектов, элементы хранения которых имеют разную длину, следует размещать меньший объект по адресу большего, а не наоборот (рис.52).
Var st: string [20]; { размещение объекта меньшего размера }
stlen: byte absolute st; { по адресу объекта большего размера }
Рис. 52. Совмещение объектов с помощью директивы ABSOLUTE
Var stlen: byte; w: word; { ошибка: размещение объекта большего размера } st: string [20] absolute stlen; { по адресу объекта меньшего размера }
Запись в переменную st может испортить данные, располагающиеся за stlen.
Рассмотрим пример совмещения данных с использованием директивы ABSOLUTE. Образ текстового экрана (25 строк на 80 столбцов) в области оперативной памяти, называемой видеопамятью, начинается с адреса $B8000: $0000 и занимает 4000 байтов. Структура видеопамяти проста: видимые строки экрана хранятся последовательно. Один символ на экране занимает два байта в памяти: первый байт – ASCII код символа, второй байт – атрибут символа, задающий цвет символа, цвет фона и признак мерцания символа. Поэтому все четные адреса видеопамяти, начиная с 0, содержат символы, а нечетные – атрибуты. На образ текстового экрана в видеопамяти можно наложить маску - структуру двумерного массива, который рассчитан на 25 * 80 = 2000 элементов, включающих символы, находящиеся на экране, и их атрибуты. Использование такой маски облегчает работу с видеопамятью, т.к. позволяет получить доступ к отдельному символу и его атрибутам.
Пусть требуется установить значение текстового атрибута в видеопамяти для символа с координатами (x,y). Заметим, что координата x фактически задает номер столбца, а координата y – номер строки в двумерном массиве - маске.
| Type
|
|
| VideoWord= record
| { образ одного символа в видеопамяти: }
|
| symbol: char;
| { ASCII код символа }
|
| attr: byte
| { атрибут символа }
|
| end;
|
|
|
|
|
| { маска – образ текстового экрана в видеопамяти - тип данных }
|
| TextScreen = array [1..25, 1..80] of VideoWord;
|
|
|
|
|
| { наложение маски по абсолютному адресу в видеопамяти }
|
| Var T: TextScreen absolute $B8000: $0000;
|
|
|
|
|
| { интерпретация данных, хранящихся по абсолютному адресу, через маску }
|
| Procedure Change_Attr(x,y: byte;
| { x, y – координаты символа на экране }
|
| textattr: byte);
| { textattr – атрибут символа }
|
| begin
|
|
| T[y,x].attr:=textattr
| { установка атрибута символа с использованием маски }
|
| end;
|
|
| | | | | |
Параметры без типа
Формальный параметр без типа внутри процедуры или функции не имеет типа и его перед использованием следует преобразовать к конкретному типу с помощью автоопределенного преобразования. Параметр без типа передается только по ссылке. Внутри процедуры или функции должна быть определена маска, задающая вид интерпретации элементов фактического параметра, передаваемого в процедуру или функцию при вызове. Напомним, что маска – это тип. Размерность маски рекомендуется выбирать так, чтобы она была рассчитана на максимальное количество данных интерпретируемого типа, которое может разместиться в пределах сегмента. (Если размер маски превышает 65520 байт, на этапе компиляции выдается сообщение об ошибке). Тип фактического параметра может быть любым, но дополнительно в процедуру или функцию следует передавать истинную размерность фактического параметра.
Пример. Просуммировать N элементов одномерных числовых массивов произвольной размерности.
| ...
|
|
| Var
| { фактические параметры - }
|
| Ar_Byte1: array[1..200] of byte;
| { интерпретируемые }
|
| Ar_Byte2: array[1..2000] of byte;
| { области }
|
| Ar_Int: array[1..500] of integer;
| { памяти }
|
|
|
|
| Function Sum(var X; n: word): longint;
| { X – параметр без типа, n – размерность массива }
|
| Type
|
|
| Xtype =array[0..65520] of byte;
| {Маска – одномерный массив типа Byte }
|
| Var
|
|
| summa: longint; i: word;
|
|
| begin
|
|
| summa:=0;
|
|
| for i:=1 to n do
|
|
| { XType(X)[i] – автоопределенное преобразование элемента массива-
параметра X к типу элемента массива-маски Byte }
|
|
| summa:=summa + XType(X)[i];
| { интерпретация элементов массива X через маску }
|
| Sum:=summa;
|
|
| end;
|
|
|
|
|
| begin
|
|
| ...
|
|
| writeln(Sum(Ar_Byte1, 200));
|
|
| writeln(Sum(Ar_Int, 500));
|
|
| writeln(Sum(Ar_Byte2, 2000));
|
|
| ...
|
|
| | | | | |
В качестве первого параметра функции Sum можно использовать массив любого типа и любой размерности. В теле функции выполняется автоопределенное преобразование элемента массива-параметра X к типу элемента массива-маски Byte. Если бы в теле функции была определена маска другого типа, например, Word, преобразование выполнялось бы к этому типу.
Открытые массивы
В качестве параметров-переменных процедуры или функции могут использоваться массивы и строки открытого типа, у которых не задаются размеры. В качестве фактического параметра можно использовать массив любого размера, но содержать он должен элементы того же типа, что и открытый массив. Истинный размер массива-фактического параметра определяется с помощью встроенной функции HIGH. Открытый массив задается как обычный массив, но без указания индексов и трактуется как маска. Индексирование элементов массива-фактического параметра начинается с нуля, а максимальный индекс равен значению функции HIGH.
| ...
|
|
| var
| { фактические параметры - }
|
| Ar1: array[1..100] of integer;
| { интерпретируемые }
|
| Ar2: array[1..1000] of integer;
| { области памяти }
|
| s: integer;
|
|
|
|
|
| Procedure Sum(var X: array of integer;
| { X – окрытый массив, его тип – }
|
| var summa: integer);
| { маска }
|
| Var i: word;
|
|
| begin
|
|
| summa:=0;
|
|
| for i:=0 to high(X) do
| { интерпретация элементов массива }
|
| summa:=summa + X[i];
| { через маску }
|
| end
|
|
|
|
|
| begin
|
|
| ...
|
|
| Sum(Ar1,s); writeln(s);
|
|
| Sum(Ar2,s); writeln(s);
|
|
| ...
| |