

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Папиллярные узоры пальцев рук - маркер спортивных способностей: дерматоглифические признаки формируются на 3-5 месяце беременности, не изменяются в течение жизни...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Папиллярные узоры пальцев рук - маркер спортивных способностей: дерматоглифические признаки формируются на 3-5 месяце беременности, не изменяются в течение жизни...
Топ:
Техника безопасности при работе на пароконвектомате: К обслуживанию пароконвектомата допускаются лица, прошедшие технический минимум по эксплуатации оборудования...
Основы обеспечения единства измерений: Обеспечение единства измерений - деятельность метрологических служб, направленная на достижение...
Выпускная квалификационная работа: Основная часть ВКР, как правило, состоит из двух-трех глав, каждая из которых, в свою очередь...
Интересное:
Как мы говорим и как мы слушаем: общение можно сравнить с огромным зонтиком, под которым скрыто все...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Принципы управления денежными потоками: одним из методов контроля за состоянием денежной наличности является...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
В противоположность объединению выборок можно использовать разделение на группы, чтобы заставить кого-то поверить в то, чего на самом деле нет. Чтобы, например, заявить, что X — это главная причина Y, мне нужно просто разделить все остальные причины на более мелкие подгруппы.
Предположим, вы производите очистители воздуха и проводите кампанию, чтобы доказать, что респираторные заболевания — основная причина смерти в Соединенных Штатах, значительно превосходящая по частоте, например, заболевания сердечно-сосудистой системы или рак. Если говорить честно, то на сегодняшний день основная причина смерти в США — болезни сердца. По данным Центров по контролю и профилактике заболеваний в стране в 2013 году смерть в основном наступала по следующим причинам[59]:
болезни сердца: 611 105;
рак: 584 881;
хронические заболевания нижних дыхательных путей: 149 205.
Даже если отбросить тот неприятный факт, что домашние очистители воздуха не сильно защищают от хронических респираторных заболеваний, эти данные не станут убедительным доводом для вашей компании. Вам бы, конечно, хотелось спасать более 100 тысяч жизней в год, но тот факт, что вы сумели справиться с третьей по важности причиной смерти, не сильно поможет вашей рекламной кампании. Хотя постойте! Ведь болезнь сердца — это не одно заболевание, их несколько:
острая ревматическая лихорадка и хроническое ревматическое заболевание сердца: 3260
гипертоническая болезнь сердца: 37 144
острый инфаркт миокарда: 116 793
сердечная недостаточность: 65 120
И так далее. Подобным же образом разбейте на подгруппы виды рака — и дело в шляпе! Заболевания нижних дыхательных путей становятся причиной смерти номер один. И вот вы уже заработали свой бонус. Некоторые производители продуктов питания использовали эту стратегию, чтобы скрыть количество жиров и сахаров, содержащихся в их продуктах.
|
|
Как собирают данные
Помните, во вступлении к этой части книги было написано, что именно люди собирают статистические данные. Это они решают, что считать и как потом быть с результатами. В процессе сбора данных может возникнуть множество ошибок и перекосов, а это, в свою очередь, может привести миллионы людей к неправильным выводам. И хотя большинство из нас никогда не будут собирать данные, научиться критически думать об этом довольно легко и доступно каждому.
Данные получают самыми разными способами: изучая записи (например, касающиеся рождаемости и смерти, предоставленные государственным ведомством, больницей или церковью), проводя исследования и опросы, делая наблюдения (например, считая электрические автомобили, проносящиеся мимо на пересечении Основной улицы с Третьей) или путем умозаключений (если продажи подгузников ползут вверх, значит, вероятно, растет уровень рождаемости). Перекосы, неточности и откровенные ошибки могут появиться на любом этапе. Важно время от времени задаваться вопросами: «А мы и правда можем узнать об этом?» или «Откуда им это известно?»
Формирование выборки
Астрогеологи собирают образцы камней с лунной поверхности — они не исследуют Луну полностью. Исследователям не нужно разговаривать с каждым конкретным избирателем, чтобы понять, кто из кандидатов выбился в лидеры гонки, или вести подсчет всех, кто заходит в приемный покой, чтобы понять, как долго пациенту приходится ждать приема. Это было бы непрактично и слишком дорого. Специалисты используют выборки и на их основании строят оценки. Если выборки сделаны правильно, то оценка может быть в высшей степени точной. В случае с подсчетом голосов, например, узнать, каковы настроения в стране (а это примерно 234 миллиона человек в возрасте старше 21 года), можно, опросив 1067 человек. Биопсии 1/1000 органа достаточно для диагностирования рака.
|
|
Однако надо помнить, что выборка должна быть репрезентативной. А это бывает в случае, когда каждый человек или предмет в изучаемой группе имеет равные шансы быть выбранным. Если это не так, то ваша выборка окажется нерепрезентативной (перекошенной). Если рак обнаружен только в одной части органа, а вы делаете пробы на другой, то он не будет диагностирован. Если же он затронул лишь малую часть органа, а вы взяли 15 проб в этом месте, то вы можете сделать вывод, что весь орган покрыт раковыми клетками, хотя это совсем не так.
Мы не всегда знаем наперед — даже со всеми возможностями биопсии или опросами общественного мнения, — в каком интервале меняется изучаемый показатель. Если бы все элементы в совокупности были одинаковыми, то для выборки было бы достаточно одного из них. Будь у нас множество генетически идентичных людей с одинаковым внутренним миром и жизненным опытом, мы могли бы узнать все что угодно обо всех, просто изучив одного из них. Но каждая группа неоднородна, ее члены отличаются друг от друга, поэтому формировать выборку нужно очень аккуратно, чтобы точно знать, что мы охватили все возможные различия, которые имеют значение (потому что не каждое из них имеет значение). Например, мы знаем: если лишить человека кислорода, он умрет. В этом отношении люди друг от друга не сильно отличаются (хотя и отличаются по времени, которое они могут протянуть без кислорода). Но если я хочу узнать, сколько килограммов человек может поднять в технике жима лежа, начинаются различия — придется измерить показатель у большой группы самых разных людей, чтобы определить диапазон его изменения и стабильное среднее арифметическое. Я бы хотел опросить высоких и низких, полных и худых, мужчин и женщин, детей, бодибилдеров, домоседов, людей, принимающих анаболики, и трезвенников. Есть, наверное, и другие факторы, которые имеют значение, например сколько часов человек спал накануне тестирования, сколько времени прошло с момента последнего приема пищи, в гневе он или спокоен и т. д. Кроме того, есть вещи, которые мы вообще не считаем важными: кто был в тот день авиадиспетчером в аэропорту Сен-Юбер в Квебеке; обслужили ли случайно взятого посетителя в ресторане Абердина в тот день вовремя или нет. Это влияет на другие показатели, которые мы исследуем (латентный сексизм в индустрии авиаперевозок; удовлетворение посетителей в ресторанах Северо-Западного региона), но не на жим лежа.
|
|
В задачу статистика входит составление списка того, что имеет значение для получения репрезентативной выборки. Следует избегать наметившейся тенденции, когда переменные выбираются такие, чтобы было легко их идентифицировать или собирать по ним данные, — ведь бывает так, что значимые показатели не очевидны или их сложно измерять. Как говорил Галилео Галилей, следует измерять то, что измеримо, и делать измеримым то, что таковым не является. Некоторые наиболее творческие прорывы в науке оказались возможны потому, что были предложены способы измерить важные показатели, которые раньше измерять не умели.
Однако даже измерение и попытки контролировать переменные, о которых вы знаете, могут стать проблемой. Предположим, вы хотите изучить существующие на данный момент мнения об изменении климата в Соединенных Штатах. Вам выделили небольшую сумму денег, чтобы вы наняли помощников и купили статистическую программу для вашего компьютера. Так случилось, что вы живете в Сан-Франциско и поэтому решаете провести исследование здесь. У вас уже сложности: Сан-Франциско — нерепрезентативный город для всей остальной части Калифорнии, не говоря уже о Соединенных Штатах в целом. Понимая это, вы принимаете решение провести свой опрос в августе, поскольку, по результатам исследований, это самый пик туристического сезона и люди со всей страны едут в Сан-Франциско, так что (думаете вы) вы сможете изучить все многообразие мнений.
Но подождите: можно ли считать тех, кто приедет в Сан-Франциско, репрезентативной выборкой? Ведь вы будете учитывать только людей, которые могут себе позволить поездку, и тех, кто хочет провести свои каникулы в городе, вместо того чтобы, скажем, ехать в национальный парк (может даже случиться так, что вы невольно отдадите предпочтение либералам, так как Сан-Франциско известен своим либерализмом).
|
|
И тогда вы решаете, что не можете позволить себе исследовать мнение всех американцев и правильнее будет сконцентрироваться на жителях Сан-Франциско. Вы отправляете своих помощников на Юнион-сквер, где они будут останавливать прохожих и задавать им интересующие вас вопросы. Вы проводите инструктаж: вам нужны люди разных возрастов, этнической принадлежности, по-разному одетых, с татуировками и без них — короче говоря, вас интересует срез общества, самые его разные представители. Но у вас по-прежнему проблема: ведь вы вряд ли встретите на улице людей, прикованных к постели, молодых мам с маленькими детьми, тех, кто работает по сменам и отсыпается днем, а также сотни тысяч жителей Сан-Франциско, которые по каким-то причинам не придут в тот день на Юнион-сквер — в ту часть города, которая славится дорогими магазинами и ресторанами. Если вы отправите своих помощников в район Мишн-дистрикт, это поможет решить проблему социально-экономического статуса опрашиваемых, но не решит остальных ваших проблем. Выборка должна пройти такой тест: все ли представители группы имеют равные шансы попасть в нее? Очевидный ответ: нет.
В таком случае вы делаете стратифицированную случайную выборку. Это значит, что вы делите всю группу на страты или подгруппы, представляющие интерес, и набираете людей из них, соблюдая пропорцию по отношению к совокупности. Если вы проведете исследование, касающееся изменения климата, и обнаружите, что мнения не имеют ничего общего с расовыми категориями, вам не нужно будет создавать группы, основанные на расе[60]. К тому же делать какие-то предположения насчет расы может быть затруднительно или оскорбительно — а что вы будете делать с людьми смешанной расы? Поместите их в одну категорию или другую, а может, создадите для них отдельную? И что же потом? Появится категория для американцев, рожденных в браках, где один родитель — афроамериканец, а второй — представитель европейского типа или латиноамериканец, в браках, где смешана восточноазиатская и иранская кровь, и т. д.? В таком случае категории могут стать слишком узкими, и это только затруднит ваше исследование. Другая сложность: вам хочется, чтобы опрашиваемые были разного возраста, но ведь бывает, что люди стесняются говорить, сколько им лет[61]. Вы можете выбирать тех, кому явно за 40 или явно меньше, но при этом пропустите тех, кому около 38 или кто едва разменял пятый десяток.
Чтобы решить проблему с теми, кто отсутствует в течение дня, вы просто можете ходить по домам и разговаривать с каждым, кто откроет дверь. Но, опять же, если вы будете так ходить в дневное время, то упустите тех, кто на работе. Если вы будете ходить так по вечерам, то не учтете любителей клубной жизни, тех, кто работает посменно, тех, кто ходит в церковь на ночные службы, киноманов и тех, кто часто ходит в рестораны. А как, создав страты, вы получите случайную выборку в рамках ваших подгрупп? Все вышеописанные проблемы актуальны и по сей день — выделение подгрупп не решает той проблемы, что даже в рамках подгруппы вам нужно будет получить репрезентативное разнообразие других факторов, которые могут повлиять на ваши данные. Видимо, нам придется собрать все имеющиеся на Луне камни, чтобы провести качественный анализ пород.
|
|
Но не спешите сдаваться. Стратифицированная случайная выборка лучше нестратифицированной. Если вы наугад отберете несколько студентов для изучения полученного ими академического опыта, то, возможно, получите выборку студентов, которые учатся в крупных государственных вузах, — в случайную выборку, скорее всего, попадут именно они, потому что таких большинство. Вам известно, что студенческая жизнь в маленьких частных гуманитарных вузах складывается совершенно по-другому, поэтому вам нужно удостовериться, что в вашей выборке есть и такие студенты, — и в вашу стратифицированную выборку попадут студенты из учебных заведений самых разных размеров.

«Опросив каждую птичку, встретившуюся на тротуаре за пределами этого здания, мы пришли к заключению, что птицы предпочитают бейглы!»
Следует отличать случайную выборку от удобной — когда вы просто опрашиваете своих знакомых или людей на улице, которые кажутся вам подходящими. Без случайности выборки ваш опрос может оказаться предвзятым.
Именно из-за формирования выборок сбор данных может превратиться в бесконечную битву за отсутствие предвзятости. И исследователи побеждают не всегда. Всякий раз, читая в газете, что 71 % британцев отдают чему-то предпочтение, мы должны спрашивать себя: «Да, но 71 % каких именно британцев?»[62]
Прибавьте к этому тот факт, что вопросы, которые мы задаем людям, — лишь выборка всех возможных вопросов, которые мы могли бы задать. Так же как их ответы, в свою очередь, могут быть всего лишь выборкой тех неоднозначных мнений и жизненного опыта, которыми они обладают. Что еще хуже, они могут понимать или не понимать, что мы спрашиваем, а пока они отвечают, их может что-то отвлекать. И гораздо чаще, чем хотелось бы тем, кто проводит опросы общественного мнения, люди намеренно дают неправильный ответ. Ведь люди — существа социальные; многие стараются избегать столкновений или хотят угодить и потому отвечают так, чтобы соответствовать ожиданиям. С другой стороны, есть ведь и такие члены общества, которые лишены избирательных прав или придерживаются нонконформистских взглядов и потому будут отвечать неискренне, примеряя маску этакого бунтаря, просто чтобы узнать, каково это — шокировать и бросать вызов[63].
Получить непредвзятую выборку не так-то просто. Когда вы держите в руках статистические данные, спросите себя: «А какой перекос мог получиться в этой выборке? Не смещена ли она?»
Выборка дает нам оценки чего-либо, и почти всегда они отличаются от истинного значения, сильно или не очень. Это называется погрешностью. Воспринимайте ее как цену, которую вы платите, чтобы не выслушивать каждого человека в группе или чтобы не изучать каждый отдельный камень на Луне[64]. Конечно, ошибки могут возникнуть, даже если вы действительно поговорили с каждым, — так случается из-за дефектов измерительного аппарата. Погрешность не имеет ничего общего с неточностями в самом исследовании — скорее она отражает степень ошибки в самом процессе отбора данных для анализа. Но давайте на мгновение забудем об этом, поскольку есть еще один вид измерений, который сопровождает любую строго собранную выборку: доверительный интервал.
Погрешность показывает, насколько близки полученные результаты к истинным значениям, а доверительный интервал — это степень уверенности в том, что оценка не выходит за пределы этой погрешности. Например, в стандартном опросе, предполагающем выбор из двух возможностей, случайная выборка из 1067 взрослых американцев даст погрешность в 3 % в любую сторону (напишем ±3 %). Значит, если опрос покажет, что 45 % американцев поддерживают кандидата А, а 47 % — кандидата Б, истинное значение будет приблизительно между 42 и 48 % для А и между 44 и 50 % для Б. Обратите внимание, что получившиеся промежутки пересекаются[65]. Это означает, что разница в 2 % между кандидатом А и кандидатом Б находится в рамках погрешности: мы не можем сказать, что один из них на самом деле опережает другого, и потому сложно пока предсказать исход гонки.
Насколько мы уверены в том, что погрешность равна 3 %, а не больше? Мы находим доверительный интервал. В приведенном мной примере рассматривался интервал с уровнем доверия 95 %. Это означает, что если бы мы проводили голосование сто раз при использовании тех же самых выборочных методов, в 95 случаях из этих 100 полученный интервал содержал бы истинное значение. В 5 случаях из 100 истинное значение выходило бы за полученные рамки[66]. При этом доверительный интервал не говорит нам, насколько сильно оно за них выходит: разница могла бы быть как большой, так и маленькой; для ответа на этот вопрос придется прибегать к другим статистическим методам.
Уровень доверия можно установить такой, какой хочется, но обычно это 95 %. Чтобы сузить доверительный интервал, можно сделать одно из двух: либо при заданном уровне доверия увеличить размер выборки, либо для заданного размера выборки уменьшить уровень доверия. В случае с фиксированным размером выборки изменение уровня доверия с 95 до 99 увеличит размер интервала. В большинстве случаев дополнительные расходы или неудобства того просто не стоят, тем более что уже на следующий день или на следующей неделе под влиянием внешних факторов респонденты могут поменять свое мнение.
Обратите внимание, что для очень больших совокупностей — как, например, население США — нам нужно сделать очень маленькую выборку, меньше 0,0005 %. Но для совокупностей поменьше — например, в случае с корпорацией или школой — доля попавших в выборку должна быть больше. В компании, штат которой составляет 10 000 сотрудников, нам бы пришлось отобрать 964 (почти 10 %), чтобы получить 3 %-ную погрешность с уровнем доверия в 95 %, а в компании, где работает 1000 сотрудников, из них нужно отобрать 600 (60 %).
Допустимая погрешность и доверительный интервал применимы к выборкам любого рода, не только к людям: можно отслеживать количество электромобилей в городе, злокачественных клеток в поджелудочной железе или ртути в рыбе, которую продают в супермаркете. Допустимая погрешность и размер выборки, представленные на графике ниже, указаны для доверительного интервала в 95 %.
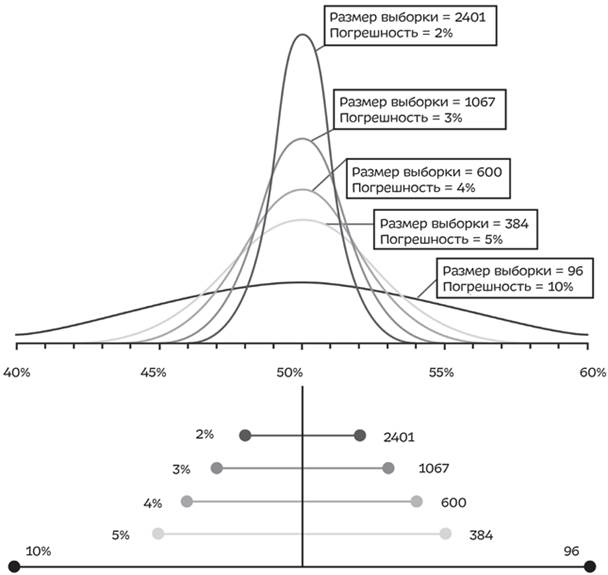
В конце книги вы найдете формулу, по которой можно подсчитать погрешность, а кроме того, существует множество онлайн-калькуляторов[67]. Если вы видите, что статистический результат приведен, а погрешность не указана, можете подсчитать ее самостоятельно, просто выяснив количество людей, участвовавших в опросе. Вы увидите: такое случается на каждом шагу, а докладчик или организация, проводившая опрос, не предоставляет эту информацию. Это похоже на график без осей — можно легко обманывать с помощью статистики, просто не сообщая погрешность или доверительный интервал. Вот так, например: мой пес по кличке Шедоу занимает лидирующую позицию на выборах губернатора от штата Миссисипи, у него 76 % голосов. (С не указанной в докладе погрешностью в ±76 %[68]. Голосуйте за Шедоу!!!)
|
|
|

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...

Биохимия спиртового брожения: Основу технологии получения пива составляет спиртовое брожение, - при котором сахар превращается...

Индивидуальные очистные сооружения: К классу индивидуальных очистных сооружений относят сооружения, пропускная способность которых...

Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!