Цель: привитие навыков визуализации взаимосвязи объектов в метрическом пространстве с последующим их дескриптивным описанием.
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Цель многомерного шкалирования – выявить структуру исследуемого множества объектов, выделив набор потенциальных переменных, по которым различаются объекты, и описать каждый объект в терминах этих переменных.
В качестве средства решения используется геометрическое представление объектов в виде точек пространства небольшого числа измерений. Необходимо построить пространство и расположить в нем точки-объекты так, чтобы расстояния между ними наилучшим образом (в смысле некоторого критерия) соответствовали заданным различиям.
Формальная постановка задачи шкалирования выглядит следующим образом. По исходной матрице попарных различий G построить координатное пространство возможно меньшей размерности r и найти в нем координаты точек-объектов так, чтобы матрица расстояний D между ними, вычисленная по введенной на Х метрике, была, в смысле некоторого критерия, близка к исходной матрице G:
 ,
,  ,
,  .
.
Различают метрическое и неметрическое шкалирование. В метрическом шкалировании матрица различий G удовлетворяет аксиомам метрики, то есть является матрицей расстояний, тогда как в неметрическом – этого не требуется. Здесь необходимо обеспечить соответствие порядка расстояний порядку различий:
 →
→  .
.
Решение задачи многомерного метрического шкалирования проводят по методу Торгерсона, опирающегося на теорему Янга-Хаусхолдера. Для неметрического шкалирования широкое распространение получил алгоритм Краскала.
В методе главных проекций Торгерсона предполагается, что матрица G – матрица евклидовых расстояний между объектами, не содержащая ошибок. По матрице G вычисляют симметричную матрицу Bi размерности NхN с элементами bjk, представляющими скалярное произведение векторов  с началом в точке i и концами в точках j и k:
с началом в точке i и концами в точках j и k:
 .
.
Любая из N точек может быть взята в качестве i -й. Таким образом можно получить N возможных матриц Bi. Согласно теореме Янга-Хаусхолдера:
1. Если какая-либо Bi (i =1,2,…, n) является положительно полуопределенной (ППО), то различия между объектами можно рассматривать как расстояния между точками в вещественном евклидовом пространстве.
2. Ранг любой ППО матрицы соответствует размерности r множества точек. (Напомним, то ранг ППО матрицы равен числу положительных собственных значений).
3. Любую ППО матрицу можно факторизовать в виде Bi = XX’. Элементы Х есть проекции точек-объектов на r ортогональных осей в r- мерном вещественном пространстве с центром в точке i.
Рассмотрим один из известных алгоритмов неметрического многомерного шкалирования, предложенный Дж. Краскалом.
Пусть 
 – оценки координат, где i – номер точки; k – номер координаты;
– оценки координат, где i – номер точки; k – номер координаты; 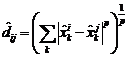 – оценка расстояний по
– оценка расстояний по  -метрике;
-метрике;  – ранговые образы расстояний, иначе отклонения. Эти величины должны соответствовать, насколько это возможно, оценкам расстояний, но с сохранением условия монотонности:
– ранговые образы расстояний, иначе отклонения. Эти величины должны соответствовать, насколько это возможно, оценкам расстояний, но с сохранением условия монотонности:
 .
.
Для оценки степени расхождения вводят меру соответствия (S -стресс):
 либо
либо  ,
,
где  – среднее арифметическое оцененных расстояний.
– среднее арифметическое оцененных расстояний.
Наряду с S -стрессом используется SS -стресс, где в числителе оценки расстояний и отклонения заменены их квадратами. SS -стресс обеспечивает более быструю сходимость, если матрица различий симметрична.
Алгоритм Краскала состоит из пяти основных этапов:
1. Формирование стартовой конфигурации, то есть получение начальных оценок координат (размерность пространства предполагается известной);
2. Стандартизация расстояний и оценок координат;
3. Неметрический этап, в ходе которого вычисляются отклонения;
4. Метрический этап: перерасчет оценок координат.
5. Подсчет меры соответствия.
Если мера улучшилась, то возвращаются к этапу 2; в противном случае – работа алгоритма завершается.
Для текущей конфигурации точек можно построить график зависимости воспроизведенных расстояний от исходных расстояний. Такая диаграмма рассеяния называется диаграммой Шепарда. По оси ординат откладываются воспроизведенные расстояния, а по оси абсцисс — исходные расстояния между объектами. На этом графике также строится график ступенчатой функции. Ее линия представляет собой результат монотонного преобразования исходных данных. Если бы все воспроизведенные расстояния легли бы на эту ступенчатую линию, то ранги наблюдаемых расстояний был бы в точности воспроизведен полученным решением (пространственной моделью). Отклонения от этой линии показывают на ухудшение качества согласия (т. е. качества подгонки модели).
Чем больше размерность r пространства, тем точнее можно воспроизвести исходную матрицу расстояний, однако практический интерес представляют пространства невысокой размерности, поскольку упрощается визуальный анализ получающейся конфигурации точек и интерпретация латентных переменных.
КОНТРОЛЬНЫЕ ВОПРОСЫ
- В чем состоит цель многомерного шкалирования?
- Каким условиям должна удовлетворять матрица различий в метрическом шкалировании?
- В чем состоит теорема Янга-Хаусхолдера?
- Что показывает диаграмма Шепарда?
- Как подбирается размерность r метрического пространства?
- Чем SS —стрессы отличаются от S -стресса?
ЗАДАНИЕ
1. Подготовить исходные данные (по указанию преподавателя).
2. Освоить работу с модулем «Многомерное шкалирование».
в пакете STATISTICA
3. Проинтерпретировать полученные результаты
Модуль «Многомерное шкалирование» пакета Statistica поддерживает только формат данных в виде матриц. К ним относятся как симметричные, так и треугольные матрицы. Для того чтобы файл входных данных был распознан как файл матрицы, он должен удовлетворять следующим условиям:
· Число строк = число столбцов + 4.
· Матрица должна быть квадратной, а названия строк и столбцов должны совпадать.
· Последние 4 строки содержат следующие сведения:
Means. В этой строке показано среднее арифметическое всех значений конкретного столбца. Для матриц сходств и различий эта строка может быть пустой.
St.Dev. В этой строке показана дисперсия значений конкретного столбца. Для матриц сходств и различий эта строка может быть пустой.
No.Cases.В этой строке задано число строк данной матрицы.(Обязательный параметр.)
Matrix.Данный параметр определяет тип используемой матрицы;
1-корреляционная матрица;
2-матрица сходств;
3-матрица различий;
4-ковариационная матрица.
(Обязательный параметр.)
Корреляционная матрица (Matrix=1). Корреляционные матрицы можно создать, например, с помощью команды Save correlation Matrix в модуле Multiple Regression-Reviewing Descriptive Statisics. Корреляционную матрицу можно также создать вручную, задав корреляции в обычной таблице и включив в файл последние четыре строки, описывающие матрицу.
Матрица сходств (Matrix=2). В этой матрице выражены сходства между объектами (переменными). Этот тип файла матрицы можно импортировать либо создать вручную, задав в обычнй таблице и включив в файл последние четыре строки, описывающие матрицу.
Матрица различий (Matrix=3). Эту матрицу можно создать вручную либо использовать команду Save distance matrix модуля Cluster Analysis - Joining Results.
Ковариационная матрица (Matrix=4). Квадратные ковариационные матрицы содержат коэффициенты ковариации для всех пар указанных переменных. На диагонали при этом находятся дисперсии для каждой переменной. Ковариационные матрицы могут быть созданы вручную путем ввода коэффициентов ковариации в обычную таблицу и добавления в нее последних четырех строк, описывающих тип матрицы.
РЕКОМЕНДУЕМАЯ ЛИТЕРАТУРА [4, 12, 14]
СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
- Айвазян C.А., Енюков И.С., Мешалкин Л.Д. Прикладная статистика. Классификация и снижение размерности. М.: Финансы и статистика, 1989.
- Демиденко Е.З. Линейная и нелинейная регрессии. М. Финансы и статистика, 1981.
- Джонстон Дж. Эконометрические методы. М.: Статистика, 1980.
- Дэйвисон М. Многомерное шкалирование. М.: Финансы и статистика, 1988.
- Иберла К.Факторный анализ. М.:Статистика,1980.
- Канторович Г.Г. Анализ временных рядов. // Экономический журнал ВШЭ, №3, 2002.
- Кремер Н.Ш., Путко Б.А. Эконометрика. М.: ЮНИТИ, 2006.
- Луговская Л.В. Эконометрика в вопросах и ответах. М.: Проспект, 2005.
- Лукашин Ю.П. Адаптивные методы краткосрочного прогнозирования. М.: Статистика, 1979.
- Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. М.: «Дело», 2001.
- Мостеллер Ф., Тьюки Дж. Анализ данных и регрессия. М.: Финансы и статистика, 1982.
- Низаметдинов Ш.У. Анализ данных. М.: МИФИ, 2006.
- Прикладная статистика. Основы эконометрики: Учебник для вузов: в 2 т. 2-е изд., испр.Т.2. Айвазян С.А. Основы эконометрики. М.: ЮНИТИ-ДАНА, 2001.
- Терехина А.Ю. Анализ данных методами многомерного шкалирования. М.: Наука, 1986.
- Тюрин Ю.Н., Макаров А.А. Анализ данных на компьютере. 3-е изд. М.: ИНФРА-М, 2003.
ПРИЛОЖЕНИЕ 1. Статистические таблицы
T - распределение
Таблица содержит значения е, полученные из условия Р (| Т | < e= 1 -q, где q- уровень значимости (q =0,05); T - случайная величина, удовлетворяющая t– распределению с заданным числом степеней свободы (ЧСС).
| ЧСС
|
|
|
|
|
|
|
|
|
| е
| 12,71
| 4,30
| 3,18
| 2,78
| 2,57
| 2,45
| 2,36
| 2,31
|
Продолжение табл.
|
|
|
|
|
|
|
|
|
| 2,26
| 2,23
| 2,13
| 2,09
| 2,04
| 2,02
| 2,00
| 1,98
|
χ2--распределение
Таблица содержит значения е, полученные из условия Р (| Т | < e= 1 -q, где q- уровень значимости (q =0,05); Х - случайная величина, распределенная по закону χ2 - с заданным числом степеней свободы (ЧСС).
| ЧСС
|
|
|
|
|
|
|
|
|
|
| е
| 3,84
| 5,99
| 7,82
| 9,49
| 11,1
| 12,6
| 14,1
| 15,5
| 16,9
|
Продолжение табл.
|
|
|
|
|
|
|
|
|
|
|
| 18,3
| 21,0
| 23,7
| 26,3
| 28,9
| 31,4
| 55,8
| 79,1
|
|
|
Критерий Баргмана
| Число
переме-нных
| Уровень значимости 0,05
| Уровень значимости 0.25
|
| Число общих факторов
| Число общих факторов
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | | |
| | | | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
95% -ное F-распределение
| Число степе-ней свободы знаменателя
| Число степеней свободы числителя
|
|
|
|
|
|
|
|
|
|
|
|
18.5
10.1
7.71
6.61
5.99
5.59
5.32
5.12
4.96
4.54
4.35
4.08
3.94
3.89
|
19.0
9.55
6.94
5.79
5.14
4.74
4.46
4.26
4.10
3.68
3.49
3.23
3.09
3.04
|
19.2
9.28
6.59
5.41
4.76
4.35
4.07
3.86
3.71
3.29
3.10
2.84
2.70
2.65
|
19.2
9.12
6.39
5.19
4.53
4.12
3.84
3.63
3.48
3.06
2.87
2.61
2.46
2.42
|
19.3
9.01
6.26
5.05
4.39
3.97
3.69
3.48
3.33
2.90
2.71
2.45
2.31
2.26
|
19.3
8.94
6.16
4.95
4.28
3.87
3.58
3.37
3.22
2.79
2.60
2.34
2.19
2.14
|
19.4
8.49
6.09
4.88
4.21
3.79
3.50
3.29
3.14
2.71
2.51
2.25
2.10
2.06
|
19.4
8.85
6.04
4.82
4.15
3.73
3.44
3.23
3.07
2.64
2.45
2.18
2.03
1.98
|
Продолжение таблицы
| |
|
|
|
|
|
|
|
|
|
19.4
8.81
6.00
4.77
4.10
3.68
3.39
3.18
3.02
2.59
2.39
2.12
1.97
1.93
|
19.4
8.79
5.96
4.74
4.06
3.64
3.35
3.14
2.98
2.54
2.35
2.08
1.93
1.88
|
19.4
8.71
5.87
4.64
3.96
3.53
3.24
3.03
2.86
2.42
2.22
1.95
1.79
1.74
|
19.4
8.66
5.80
4.56
3.87
3.44
3.15
2.93
2.77
2.33
2.12
1.84
1.68
1.62
|
19.5
8.59
5.72
4.46
3.77
3.34
3.05
2.83
2.66
2.20
1.99
1.69
1.52
1.46
|
19.5
8.55
5.66
4.41
3.71
3.37
2.97
2.76
2.59
2.12
1.91
1.59
1.39
1.32
|
19.5
8.54
5.65
4.39
3.69
3.25
2.95
2.73
2.56
2.10
1.88
1.55
1.34
1.26
|
Значения статистики Дарбина-Уотсона dL и dV при уровне значимости 0.05
| Число наблюдений
| Число членов в уравнении регрессии, не считая свободного
|
|
|
|
|
|
|
| dL dV
| dL dV
| dL dV
| DL dV
| dL dV
|
|
| 1.08 1.36
1.10 1.37
1.13 1.38
1.16 1.39
1.18 1.40
1.20 1.41
1.24 1.43
1.27 1.45
1.30 1.46
1.33 1.48
1.35 1.49
1.40 1.52
1.44 1.54
1.48 1.57
1.50 1.59
1.53 1.60
1.55 1.62
1.58 1.64
1.61 1.66
1.63 1.68
1.65 1.69
| 0.95 1.54
0.98 1.54
1.02 1.54
1.05 1.53
1.08 1.53
1.10 1.54
1.15 1.54
1.19 1.55
1.22 1.55
1.26 1.56
1.28 1.57
1.34 1.58
1.39 1.60
1.34 1.62
1.46 1.63
1.49 1.64
1.51 1.65
1.55 1.67
1.59 1.69
1.61 1.70
1.63 1.72
| 0.82 1.75
0.86 1.73
0.90 1.71
0.93 1.69
0.97 1.68
1.00 1.68
1.05 1.66
1.10 1.66
1.14 1.65
1.18 1.65
1.21 1.65
1.28 1.65
1.34 1.66
1.38 1.67
1.42 1.67
1.45 1.68
1.48 1.69
1.52 1.70
1.56 1.72
1.59 1.73
1.61 1.74
| 0.69 1.97
0.74 1.93
0.78 1.90
0.82 1.87
0.86 1.85
0.90 1.83
0.96 1.80
1.01 1.78
1.06 1.76
1.10 1.75
1.14 1.74
1.22 1.73
1.29 1.72
1.34 1.72
1.38 1.72
1.41 1.72
1.44 1.73
1.49 1.74
1.53 1.74
1.57 1.75
1.59 1.76
| 0.56 2.21
0.62 2.15
0.67 2.10
0.71 2.06
0.75 2.02
0.79 1.99
0.86 1.94
0.93 1.90
0.98 1.88
1.03 1.85
1.07 1.83
1.16 1.80
1.23 1.79
1.29 1.78
1.34 1.77
1.38 1.77
1.41 1.77
1.46 1.77
1.51 1.77
1.54 1.78
1.57 1.78
|
ПРИЛОЖЕНИЕ 2. Список сокращений и терминов, встречающихся в экранных формах, и их значение.
ACF -автокорреляционная функция;
AR -авто регрессия;
Dependent -зависимый;
DF -число степеней свободы;
DurbWat -статистика Дарбина-Уотсона;
Eigenvalue -собственное значение;
Estimate -оценка;
Exp.power -экспоненциальная зависимость;
F -enter-пороговое значение F -распределения;
F -ratio-вычисленное (расчетное) значение F -распределения;
F -remove-пороговое значение F -распределения для удаления переменной из
уравнения регрессии;
Independent -независимый;
Intersept -свободный член а 0 в линейной регрессии;
Lag – отставание (запаздывание, сдвиг);
MA -скользящее среднее;
MAE -среднее абсолютное отклонение;
ME -среднее отклонение;
Outlier -выброс, анормальное значение;
PACF -частная автокорреляционная функция;
P level – уровень значимости
Plot…. -построить график;
Reciprocal -обратный;
Residual -остаток;
R-squared -квадрат коэффициента множественной корреляции, иначе
коэффициент детерминации;
R-sq(adj) -правленный коэффициент детерминации;
SAR -сезонная авторегрессия;
Save results -сохранить результаты на диске или в оперативной памяти
для дальнейшего использования;
Scatterplot -диаграмма рассеяния;
SE -стандартное отклонение;
Seasonality -сезонность, сезонная составляющая;
Slope -коэффициент а 1 в линейной регрессии y = a 0+ a 1 x;
SMA -скользящее среднее для сезонной составляющей ряда;
S-surve - S-образная кривая (y=exp(a+b/x));
Stepwise -пошаговый;
t -value –вычисленное (расчетное) значение t -распределения.
ПРИЛОЖЕНИЕ 3. Варианты исходных данных для лабораторной работы «Регрессионный анализ»
| №
вар
| Выборка 1 (основная)
| Выборка 2 (Чоу)
| №
вар.
| Выборка 1 (основная)
| Выборка 2 (Чоу)
|
|
|
|
|
|
|
|
|
| автомобили США
|
|
| средние по массе автомобили
|
|
|
| автомобили Европы
|
|
| тяжелые автомобили
|
|
|
| автомобили Японии
|
|
| автомобили выпуска после 1979 г.
|
|
|
| автомобили не из США
|
|
| автомобили выпуска после 1980 г.
|
|
|
| автомобили не из Европы
|
|
| авто выпуска до 1979 г. включительно
|
|
|
| автомобили не из Японии
|
|
| авто с временем разгона 11,0-13,1 сек.
|
|
|
| 4-цилиндровые автомобили
|
|
| авто с временем разгона 13,2-14,0 сек.
|
|
|
| 6-цилиндровые автомобили
|
|
| авто с временем разгона 14,1-14,5 сек.
|
|
|
| 8-цилиндровые автомобили
|
|
| авто с временем разгона 14,6-15,0 сек.
|
|
|
| 6- и 8-цилиндровые автомобили
|
|
| авто с временем разгона 15,1-15,5 сек.
|
|
|
| 4- и 6-цилиндровые автомобили
|
|
| авто с временем разгона 15,6-16,0 сек.
|
|
|
| 4- и 8-цилиндровые автомобили
|
|
| авто с временем разгона 16,1-16,9 сек.
|
|
|
| маломощные автомобили
|
|
| авто с временем разгона 17,0-17,9 сек.
|
|
|
| автомобили средней мощности
|
|
| авто с временем разгона 18,0-19,2 сек.
|
|
|
| мощные автомобили
|
|
| авто с временем разгона 19,3-25,0 сек.
|
|
|
| дешевые автомобили США
|
|
| авто с объемом двигателя 70-89дм3
|
|
|
| средние по цене автомобили США
|
|
| авто с объемом двигателя 90-99 дм3.
|
|
|
| дорогие автомобили США
|
|
| авто с объемом двигателя 100-112 дм3.
|
|
|
| дешевые автомобили Европы
|
|
| авто с объемом двигателя 113-130 дм3
|
|
|
| средние по цене автоЕвропы
|
|
| авто с объемом двигателя 131-141 дм3.
|
|
|
| дорогие автомобили Европы
|
|
| авто с объемом двигателя 142-152 дм3
|
|
|
| дешевые автомобили Японии
|
|
| авто с объемом двигателя 155-200 дм3.
|
|
|
| средние по цене автоЯпонии
|
|
| авто с объемом двигателя >200 дм3
|
|
|
| дорогие автомобили Японии
|
|
| автомобили массой 1755-1950 фунтов
|
|
|
| авто с mpg в диапазоне 15,5-20,0
|
|
| автомобили массой 1951-1991 фунтов
|
|
|
| авто с mpg в диапазоне 20,1-22,5
|
|
| автомобили массой 1992-2115 фунтов
|
|
|
| авто с mpg в диапазоне 22,6-25,5
|
|
| автомобили массой 2116-2170 фунтов
|
|
|
| авто с mpg в диапазоне 25,6-27,5
|
|
| автомобили массой 2171-2296 фунтов
|
|
|
| авто с mpg в диапазоне 27,6-30,5
|
|
| автомобили массой 2297-2450 фунтов
|
|
|
| авто с mpg в диапазоне 30,6-32,5
|
|
| автомобили массой 2451-2610 фунтов
|
|
|
| авто с mpg в диапазоне 32,6-35,0
|
|
| автомобили массой 2611-2705 фунтов
|
|
|
| авто с mpg в диапазоне 35,1-37,9
|
|
| автомобили массой 2706-2831 фунтов
|
|
|
| авто с mpg в диапазоне 38,0-47,0
|
|
| автомобили массой 2832-2960 фунтов
|
|
|
| автомобили США выпуска 1978 г.
|
|
| автомобили массой 2961-3200 фунтов
|
|
|
| автомобили США выпуска 1979 г.
|
|
| автомобили массой 3201-3416 фунтов
|
|
|
| автомобили США выпуска 1980 г.
|
|
| автомобили массой 3417-3621 фунтов
|
|
|
| автомобили выпуска 1978 г.
|
|
| автомобили массой 3622-4370 фунтов
|
|
|
| автомобили выпуска 1979 г.
|
|
| автомобили мощностью 48-65 л.с.
|
|
|
| автомобили выпуска 1980 г.
|
|
| автомобили мощностью 66-69 л.с.
|
|
|
| автомобили Ford
|
|
| автомобили мощностью 70-76 л.с.
|
|
|
| автомобили Volkswagen
|
|
| автомобили мощностью 77-86 л.с.
|
|
|
| легкие автомобили США
|
|
| автомобили мощностью 87-90 л.с.
|
|
|
| средние по массе автомобили США
|
|
| автомобили мощностью 91-92 л.с.
|
|
|
| тяжелые автомобили США
|
|
| автомобили мощностью 93-110 л.с.
|
|
|
| легкие автомобили
|
|
| автомобили мощностью 111-165 л.с.
|
|
Примечания.
В колонках 1 и 4 указан номер варианта, который соответствует порядковому номеру студента в группе (на потоке).
В колонках 2 и 5 указан признак-условие, по которому формируется выборка из массива данных.
В колонках 3 и 6 указан номер варианта, по основной выборке которого формируется вторая выборка для теста Чоу.
Приложение 4. Указания по выполнению работы «Кластерный анализ»
Предварительная визуальная кластеризация.
Проводится с помощью звездных диаграмм, лиц Чернова, главных компонент. Диаграммы и лица Чернова доступны через пункт меню Graph → Icon Plots (Рис. 1)

|
| Рисунок 1
|
Работа с диалоговым окном Icon Plots (Рис. 2).
Перейти на закладку Advanced, в методе стандартизации (Standardize) выбрать пункт Cases. Нажать кнопку Variables и в появившемся диалоговом окне выбрать интересующие переменные.
Далее выбрать сначала Stars (звездные диаграммы), затем Chernoff Faces (лица Чернова)
По полученным диаграммам приблизительно определить число кластеров.

|
| Рисунок 2
|
Кластеризация методом К- средних
Сначала необходимо стандартизовать данные: п. меню Data → Standardize, в появившемся диалоговом окне (Рис. 3) указать переменные по которым будет проводиться анализ.

|
| Рисунок 3
|
Затем перейти непосредственно к процедуре кластерного анализа: п. меню Statiatics → Multivariate Exploratory Techniques → Cluster Analysis (Рис. 4)

|
| Рисунок 4
|
В диалоговом окне кластерного анализа (Рис. 5) выбрать пункт K-means clustering

|
| Рисунок 5
|
В следующем диалоговом окне снова используется закладка Advanced (Рис. 6)

|
| Рисунок 6
|
- Кнопка Variables – нажать и указать переменные для анализа
- Выпадающий список Cluster – указать кластеризацию по объектам (cases)
- Число кластеров (Number of clusters) – указать число кластеров, полученное по результатам визуального анализа числа кластеров (звездные диаграммы и лица Чернова)
- В методах выбора начальных центров кластеров (Initial cluster centers) выбрать третью позицию, для реализации метода К -средних.
После расчета в пакете Statistica появится следующее диалоговое окно (Рис. 7)

|
| Рисунок 7
|
В верхней части окна содержится информация о прошедшем процессе кластеризации, а именно: число переменных, по которым проводился анализ, число объектов, метод обработки недостающих данных, число кластеров, и число шагов, потребовавшихся для решения. Эту часть окна можно свернуть кнопкой  , либо скопировать информацию в буфер обмена
, либо скопировать информацию в буфер обмена 
Нижняя часть окна содержит панель с шестью (табл.1) кнопками описательных статистик. По нажатию любой из них соответствующая информация выводится в, так называемую, рабочую книгу (Workbook).
Таблица 1
| Кнопка
| Назначение
|

| В нескольких таблицах статистика средних значений переменных по каждому кластеру, а также расстояния (под гл. диагональю)и квадраты расстояний (над гл. диагональю) между кластерами
|

| Данные для дисперсионного анализа
|

| Выводит график средних значений переменных для каждого кластера (эти графики помогут выявить качественную переменную, отвечающую за состав кластера)
|

| Описательная статистика переменных по каждому кластеру
|

| Состав каждого кластера, и расстояния между объектами и центром кластера
|

| Сохраняет выбранные данные и принадлежность к кластеру
|
Данные о расстояниях между кластерами и расстояниях от объектов до центров кластеров используются для оценки качества разбиения.
Иерархический кластерный анализ.
Вернуться к первому диалогу кластерного анализа (Рис. 5), выбрать пункт Joining, и подтвердить нажатием кнопки ОК
|
| Рисунок 8
|

|
| Рисунок 9
|
Снова необходимо использовать закладку Advanced. Требуется указать:
- переменные, по которым ведется анализ
- тип входных данных (в нашем случае это просто значения)
- кластеризация проводится по объектам(Cluster → Cases(rows))
- правило объединения (взвешенное среднее)
- вид метрики.
Фактически, дендрограмма показывает ход объединения объектов в кластеры.

|
| Рисунок 10
|
Таблица 2
| Кнопка
| Назначение
|

| Вывод дендрограммы
|

| выдает матрицу, которая по шагам позволяет отследить процесс построения дендрограммы
|

| График позволяет отследить изменение расстояний между объектами на каждом шаге
|

| Матрица расстояний между объектами
|
ПРИЛОЖЕНИЕ 5. Пример отчета






