Интервальное оценивание числовых характеристик
И параметров распределения
генеральной совокупности [49, 50, 51].
8.1. Законы распределения случайных величин и их параметры.
Группированный статистический ряд.
Пусть имеется выборка (х1=xmin, х2,…, хn=xmax) из генеральной совокупности Х.
Промежуток [хmin, xmax] делится на некоторое число k равных по длине промежутков. Обозначим эти промежутки слева направо через:


Здесь принято: а0 = хmin, ak = xmax.
Пусть ni – число элементов выборки, попавших в промежуток Di. Числа n1, n2 … nk называют частотами попадания элементов выборки в рассматриваемые промежутки.
Определение 1. Совокупность промежутков и соответствующих им частот называется группированным статистическим рядом.
Для определения числа k промежутков рекомендуется следующая полуэмпирическая формула:
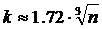
где n – объем выборки, как правило n Î [30, 100].
Применяется также формула Старджесса:

Длина h промежутков определится через размах R выборки соотношением:

Вместо группы элементов, попавших в конкретный интервал Di, может рассматриваться один их представитель. В качестве такого представителя выбирается средняя точка  промежутка Di.
промежутка Di.
Группированный статистический ряд обычно представляют в виде таблицы, что удобно выполнять в Excel.
Определение 2. Выборочной оценкой генеральной числовой характеристики называется ее приближенное значение, найденное по выборке.
Основными оценками являются:
Выборочное среднее  , которое является оценкой генерального математического ожидания m = M[X]:
, которое является оценкой генерального математического ожидания m = M[X]:
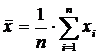 (8.1.1)
(8.1.1)
Выборочный центральный момент sd порядка d, который является оценкой генерального центрального момента порядка d (md = M[(X-m)d]):
 (8.1.2)
(8.1.2)
Выборочный начальный момент at порядка t, который является оценкой генерального начального момента порядка t at = M(Xt):
 (8.1.3)
(8.1.3)
Выборочная дисперсия s2, которая является оценкой генеральной дисперсии s2 = m2:
 (8.1.3)
(8.1.3)
Выборочное среднее квадратическое отклонение s, которое является оценкой генерального среднего квадратического отклонения  :
:
 (8.1.4)
(8.1.4)
С помощью группированного статистического ряда можно приближенно вычислить выборочные моменты. Так как группа элементов выборки, входящих в промежуток Di, заменяется средней точкой промежутка, то следует полагать, что элемент как бы встречается в выборке ni раз, т.е. имеет частоту ni. Получаем следующие формулы:

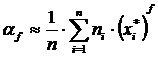
где ni – число элементов выборки, попавших в промежуток Di
n – объем выборки
Применение этих формул целесообразно при ручных расчетах.
8.2. Метод максимального правдоподобия
оценок параметров генерального распределения.
Пусть известен вид закона генерального распределения, а параметры  в него входящие, неизвестны. Возникает задача их статистической оценки.
в него входящие, неизвестны. Возникает задача их статистической оценки.
Метод максимального правдоподобия, созданный английским математиком Р. Фишером (1890-1962), является достаточно универсальным.
Пусть имеется выборка (х1, х2,…, хn) из генеральной совокупности с плотностью вероятности f(x,q), содержащей один неизвестный параметр q.
Выборка является n-мерной случайной величиной, компоненты xi которой взаимно независимы, одинаково распределены с плотностью f(x,q), следовательно, на основе теоремы умножения плотностей распределения случайных величин, плотность распределения n-мерной случайной величины (х1, х2,…, хn) будет равна:
 (8.2.1)
(8.2.1)
Эта функция называется функцией правдоподобия для рассматриваемой выборки.
Будем считать q неслучайной переменной величиной, а элементы х1, х2,…, хn выборки – фиксированными, т.к. выборка фактически осуществлена. Если придать q различные значения, то естественно ожидать, что плотность L(x1, x2,…, xn; q) примет максимальное значение в случае, когда значение q окажется равным истинному значению, т.к. при других значениях q менее вероятно за один раз получить именно данную выборку.
Эти интуитивные соображения приводят к тому, что за оценку q принимают такое его значение, при котором функция правдоподобия L(·) достигает максимума.
Поскольку L(·) состоит из произведений, то технически удобнее искать максимум логарифма:  , учитывая, что точка
, учитывая, что точка  , доставляющая максимум ln(L(·)), доставляет максимум и функции L(·).
, доставляющая максимум ln(L(·)), доставляет максимум и функции L(·).
Тогда, для определения составляем уравнение:
 ,
,
которое называется уравнением правдоподобия, а его решение
 ,
,
зависящее от элементов выборки, называют оценкой максимального правдоподобия.
В случае, когда генеральная плотность вероятности содержит k параметров, то вместо одного уравнения правдоподобия решается система уравнений:
 (8.2.2)
(8.2.2)
Рассмотрим несколько типовых примеров.
Пример 8.2.1.
Показательный закон с плотностью:

Функция правдоподобия при х > 0 имеет вид:

После логарифмирования:
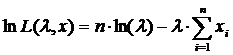
Находится частная производная функции L(l, x) по переменной l:
 ,
,
отсюда:
 , или
, или 
Пример 8.2.2.
Нормальный закон распределения с плотностью:

где m – математическое ожидание случайной величины Х генеральной совокупности;
s - среднее квадратическое отклонение случайной величины Х генеральной совокупности.
В данном случае имеется два параметра m и s2. Следовательно, функция правдоподобия L(m, s) имеет вид:

После логарифмирования:

Далее, дифференцируя [ln(L(m, s)] по m и s2, получаем систему уравнений правдоподобия:

Из первого уравнения находим:
 , откуда получаем
, откуда получаем 
Из второго уравнения:

Пример 8.2.3.
Равномерное распределение с плотностью:

Функция правдоподобия в этом случае имеет вид:

Необходимо найти такие значения (a, b), которые доставляют функции правдоподобия максимум.
Из последнего неравенства следует, что функция L(a,b) принимает максимальное значение при b = xmax и a = xmin. Таким образом, оценками максимального правдоподобия в случае равномерного закона распределения являются:

Пример 8.2.4.
Распределение Пуассона.
В случае дискретного закона распределения  функция правдоподобия определяется зависимостью:
функция правдоподобия определяется зависимостью:

Вероятность того, что случайная величина Х, распределенная по закону Пуассона, реализуется ровно k раз:

В этом случае необходимо найти такое значение параметра а, для которого функция правдоподобия L(a) достигнет своего максимума.
Тогда функцию правдоподобия можно представить в виде:

После логарифмирования:

Находим частную производную функции ln(L(a)) по аргументу а:

Откуда:

8.3. Проверка гипотезы о законе распределения
Генеральной совокупности.
Вначале выдвигается гипотеза о виде закона распределения, который может быть нормальным, Пуассона и т.д.
После того, как выбран вид закона распределения, возникает задача оценки его параметров и проверки закона в целом.
Наиболее обоснованным и часто используемым является метод с использованием критерия c2 (хи-квадрат), введенный английским статистиком К. Пирсоном (1900 г.) и существенно уточненным английским математиком Р. Фишером (1924 г.).
Ограничимся случаем одномерного распределения.
Пусть выдвинута гипотеза Н0 о генеральном законе распределения с функцией F(x). Конкурирующей гипотезой является гипотеза о справедливости одного из конкурирующих распределений.
Случай первый.
Теорема К. Пирсона.
Статистика (8.3.2) критерия c2 асимптотически при n ® ¥ распределена по закону c2 с (k -1) степенями свободы.
Аргументами статистики c2 являются частоты n 1, n 2,…, n k. Эти частоты связаны равенством:
 ,
,
следовательно, функция c2 имеет (k-1) независимых аргументов.
Случай второй.
Замечание.
Суждение о принятии или отвержении выдвинутой статистической гипотезы не являются абсолютными, а носят вероятностный характер. Принимая или отвергая гипотезу, могут быть совершены ошибки.
Ошибкой первого рода называется ошибка отвержения правильной гипотезы.
Ошибкой второго рода называется ошибка принятия неверной гипотезы.
Уровнем значимости называется такое значение вероятности, что событие с такой вероятностью практически не реализуется.
Вероятность ошибки первого рода равна уровню значимости a,
вероятность ошибки второго рода обозначается b:
По виду статистики c2 можно заключить, что большие значения c2 неприемлемы для справедливости гипотезы Н0. Отсюда следует, что критерий c2 является правосторонним, а критической областью будет промежуток вида  , где
, где  - квантиль порядка (1-a) распределения хи-квадрат с r степенями свободы (рис. 8.3.1).
- квантиль порядка (1-a) распределения хи-квадрат с r степенями свободы (рис. 8.3.1).
Из формулы (8.3.2) видно, что веса  пропорциональны n, т.е. с ростом n их значение увеличивается. Таким образом, если выдвинутая гипотеза Н0 неверна, то относительные частоты не будут близки к вероятностям pi, и с ростом n величина c2 будет увеличиваться. При фиксированном уровне значимости a будет фиксировано пороговое число . Поэтому, увеличение n приведет к неравенству:
пропорциональны n, т.е. с ростом n их значение увеличивается. Таким образом, если выдвинутая гипотеза Н0 неверна, то относительные частоты не будут близки к вероятностям pi, и с ростом n величина c2 будет увеличиваться. При фиксированном уровне значимости a будет фиксировано пороговое число . Поэтому, увеличение n приведет к неравенству:
 , (8.3.4)
, (8.3.4)
где  - выборочное значение статистики c2, вычисленное по (8.3.2).
- выборочное значение статистики c2, вычисленное по (8.3.2).
При реализации (8.3.4) попадет в критическую область, и неверная гипотеза будет отвергнута.
Рис. 8.3.1. Критическая область критерия хи-квадрат.
Из этих рассуждений следует, что при сомнительной ситуации, когда
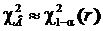 , следует увеличить объем выборки, например, в два раза, чтобы проверяемое неравенство было более четким.
, следует увеличить объем выборки, например, в два раза, чтобы проверяемое неравенство было более четким.
Замечание.
Практика применения критерия c2 показывает, что если для каких-либо подмножеств Di (i=1, 2, …, k) условие  не выполняется, то следует объединить соседние подмножества (промежутки).
не выполняется, то следует объединить соседние подмножества (промежутки).
Это условие выдвигается требованием близости величин  ,
,
(квадраты которых являются слагаемыми c2) к нормальным с математическим ожиданием равным нулю и средним квадратическим отклонением равным единице N(0, 1). Тогда случайная величина в формуле (8.3.2) будет распределена по закону, близкому к хи-квадрат. Такая близость обеспечивается достаточной численностью элементов в подмножествах Di.
Определение. Квантилью порядка d непрерывной случайной величины Х называется ее значение хd, являющееся корнем уравнения:
 (8.3.5)
(8.3.5)
Алгоритм проверки гипотезы
о законе распределения генеральной совокупности.
1. Выбирается уровень значимости a.
2. С помощью гипотетической функции распределения F(x) с числом оцениваемых параметров l вычисляются оценки вероятностей  , i = 1, 2,…, k.
, i = 1, 2,…, k.
3. По таблице (Приложение 8.4) находится квантиль распределения хи-квадрат с r = k- l -1 степенями свободы порядка 1-a.
4. Находятся частоты ni попадания элементов в подмножества DI, и вычисляется выборочное значение статистики критерия хи-квадрат:

5. Производится сравнение  с квантилью .
с квантилью .
Если < , то гипотеза Н0 принимается.
В противном случае гипотеза Н0 отвергается.
Пример 8.3.1.
Произведено 50 измерений уровня радиации в помещении. Результаты измерения (мкЗв/час) после их упорядочения в порядке возрастания сведены в табл. 8.3.1.
Таблица 8.3.1.
Результаты измерений после их упорядочения.
| 0.10
| 0.11
| 0.12
| 0.12
| 0.12
| 0.12
| 0.12
| 0.13
| 0.14
| 0.14
|
| 0.15
| 0.15
| 0.16
| 0.17
| 0.17
| 0.17
| 0.17
| 0.18
| 0.18
| 0.18
|
| 0.18
| 0.19
| 0.19
| 0.19
| 0.20
| 0.20
| 0.20
| 0.20
| 0.20
| 0.20
|
| 0.20
| 0.21
| 0.21
| 0.21
| 0.21
| 0.22
| 0.22
| 0.22
| 0.22
| 0.22
|
| 0.22
| 0.23
| 0.23
| 0.23
| 0.24
| 0.24
| 0.24
| 0.25
| 0.25
| 0.29
|
Выдвигается гипотеза Н0 о том, что распределение значений произведенных измерений подчинено нормальному закону. Требуется подтвердить или отвергнуть выдвинутую гипотезу.
Решение.
Представленные в табл. 8.3.1 данные представляют собой выборку объемом n = 50 значений уровня радиации в помещении.
Определяем число k интервалов для группированного ряда:
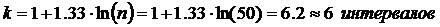
Определяем длину промежутков h:

Составляем табл. 8.3.2, содержащую границы интервалов.
Таблица 8.3.2.
Границы промежутков выборки.
| №
промежутка
| Границы интервалов
| Число значений в интервале, ni
| Средняя точка промежутка
|
| ai-1
| ai
|
|
| 0.1
| 0.13
|
| 0.1150
|
|
| 0.13
| 0.16
|
| 0.1450
|
|
| 0.16
| 0.19
|
| 0.1750
|
|
| 0.19
| 0.21
|
| 0.2000
|
|
| 0.21
| 0.24
|
| 0.2250
|
|
| 0.24
| 0.29
|
| 0.2650
|
| Сумма
|
|
|
Легко заметить, что значения границ определены прибавлением к левому значению интервала величины h, например:

Рассчитываем выборочные числовые характеристики для выборки табл. 8.3.1 с помощью группированного статистического ряда табл. 8.3.2. Составим табл. 8.3.3, где zi – средняя точка i-го интервала.
Таблица 8.3.3.
Расчет первых двух выборочных моментов.
| i
| ni
| zi
| (zi)2
| ni×zi
| ni×(zi)2
|
|
|
| 0.1150
| 0.0132
| 0.920
| 0.1058
|
|
|
| 0.1450
| 0.0210
| 0.725
| 0.1050
|
|
|
| 0.1750
| 0.0306
| 1.925
| 0.3368
|
|
|
| 0.2000
| 0.0400
| 2.200
| 0.4400
|
|
|
| 0.2250
| 0.0506
| 2.700
| 0.6075
|
|
|
| 0.2650
| 0.0702
| 0.795
| 0.2106
|
| S
|
| -
| -
| 9.265
| 1.8057
|
Используя данные табл. 8.3.3, находим выборочное среднее  , выборочные дисперсию s2 и среднее квадратическое отклонение s.
, выборочные дисперсию s2 и среднее квадратическое отклонение s.
С помощью группированного статистического ряда можно ориентировочно определить выборочные моменты, поскольку группа элементов выборки, входящих в промежуток Di может быть заменена средней точкой zi, т.е. можно считать, что элемент zi встречается в выборке ni раз, или имеет частоту ni, тогда:




 мкЗв/час
мкЗв/час
Вычисляем выборочное значение статистики критерия хи-квадрат (8.3.2), для чего составим табл. 8.3.4.
Таблица 8.3.4.
Вычисление 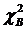 для проверки гипотезы о нормальном законе распределения измерений радиации в помещении.
для проверки гипотезы о нормальном законе распределения измерений радиации в помещении.
|
i
| Границы
ai-1
ai
|
ni
|

|
Ф0(bi-1)
Ф0(bi)
| pi=
Ф0(bi)-
-Ф0(bi-1)
|
n×pi
|
ni-n×pi
|

|
|
| - ¥
|
| - ¥
| - 0.5
| 0.01430
| 0.715
| 7.285
| 74.225
|
| 0.13
| -2.1993
| -0.4857
|
|
| 0.13
|
| -2.1993
| -0.4857
| 0.13027
| 6.5135
| - 1.5135
| 0.3517
|
| 0.16
| -1.0657
| -0.3554
|
|
| 0.16
|
| -1.0657
| -0.3554
| 0.38333
| 19.1665
| - 8.1665
| 3.4795
|
| 0.19
| 0.06802
| 0.0279
|
|
| 0.19
|
| 0.06802
| 0.0279
| 0.26599
| 13.2995
| - 2.2995
| 0.3975
|
| 0.21
| 0.82381
| 0.2939
|
|
| 0.21
|
| 0.82381
| 0.2939
| 0.18111
| 9.0555
| 2.9445
| 0.9574
|
| 0.24
| 1.95743
| 0.4750
|
|
| 0.24
|
| 1.95743
| 0.4750
| 0.02500
| 1.250
| 1.7500
| 2.4500
|
| + ¥
| + ¥
| 0.5
|
| S
|
|
|
|
| 1.00
|
| 0.0
| 81,8618
|
Число параметров, оцениваемых в нормальном законе распределения равно l = 2, следовательно, число степеней свободы асимптотического хи-квадрат распределения равно:

Выбираем уровень значимости a = 0.95, тогда квантиль хи-квадрат распределения (Приложение 8.4) равен 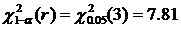 . Сравнивая на основе (8.3.4) выборочное значение
. Сравнивая на основе (8.3.4) выборочное значение  с квантилью
с квантилью  делаем [поскольку > ], вывод:
делаем [поскольку > ], вывод:
гипотеза Н0 о нормальном законе распределения полученных при измерениях значений уровня радиации в помещении отвергается.
8.4. Точность и надежность оценки вероятности реализации события с помощью его относительной частоты
при большом объеме выборки.
Пусть р – вероятность реализации события А,  - его относительная частота. Тогда, полагая:
- его относительная частота. Тогда, полагая:
 (8.4.1)
(8.4.1)
где: g - надежность (вероятность), с которой доверительный интервал накрывает значение вероятности р реализации события,
 - уровень значимости;
- уровень значимости;
 - квантиль нормального распределения N(0, 1) порядка
- квантиль нормального распределения N(0, 1) порядка  ;
;
e - половина длины доверительного интервала.
Тогда:
 (8.4.2)
(8.4.2)
Пример 8.4.1.
Известен объем выборки n=550, задана требуемая надежность g=0.95.
Необходимо построить доверительный интервал для вероятности с помощью найденной по выборке р* = 0.3.
Решение.
С помощью таблицы (Приложение 8.1) квантилей нормального распределения находим:

Определяем половину длины доверительного интервала:

Таким образом, значение искомой вероятности реализации события А с надежностью g = 0.95 находится в интервале [(р*- e), (р*+ e)]:

Пример 8.5.1.
Произведено n=30 измерений концентрации газа в резервуаре перед его очисткой. Сделано предположение о нормальном распределении результатов измерений в генеральной совокупности. Выборочное среднее и выборочное среднее квадратическое отклонение соответственно равны:
 ,
, 
Требуется с достоверностью 0.95 определить интервал значений истинного математического ожидания концентрации газа в резервуаре.
Решение.
По таблице распределения Стьюдента (Приложение 8.2) находим квантиль порядка 0.975 для 29 степеней свободы:

Тогда значение искомого математического ожидания с требуемой надежностью находится в интервале:

Или вероятность того, что 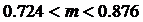 равна 0.95.
равна 0.95.
8.6. Доверительный интервал для среднего квадратического отклонения нормальной генеральной совокупности.
Если произведена выборка объемом n из генеральной совокупности, где по предположению случайная величина распределена по нормальному закону, вычислено выборочное среднее квадратическое отклонение s и задана требуемая надежность g, то соответствующий доверительный интервал, в котором содержится среднее квадратическое отклонение s, может быть определен с помощью c2 – распределения (Приложение 8.4) с n-1 степенями свободы порядков (1-g)/2 и (1+g)/2:
 (8.6.1)
(8.6.1)
Замечание. В знаменателе под знаком радикала не произведение c2 на (n-1), а c2 с (n-1) степенями свободы.
Пример 8.6.1.
По исходным данным примера 8.5.1 найти истинное среднее квадратическое отклонение концентрации газа в резервуаре.
По таблице распределения c2 находим соответствующие квантили:


Вычисляется доверительный интервал:
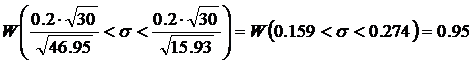
где W(А) – вероятность реализации события А.
Пример 8.7.1.
Пусть n1=16,  ; n2=20,
; n2=20,  ; a = 0.05.
; a = 0.05.
Требуется проверить предположение о равенстве дисперсий этих выборок.
Решение.
Числа свободы k1=15, k2=19.
Значение статистического критерия:
 ,
,
По таблице распределения Фишера находим квантиль F1-a(k1,k2):
F1-a(k1, k2) = F0.95 (15, 19) = 2.23
Поскольку выполняется неравенство:
FB < F1-a(k1,k2) – гипотеза о равенстве дисперсий принимается.
Пример 8.8.1.
Требуется сравнить содержание вредных примесей в воде (эффективности предпринятых мер повышения качества воды) технологического колодца с надежностью g = 0.95 (уровнем значимости a= 0.05).
Произведено две серии независимых измерений, Распределенных по нормальному закону. Первая серия (х) объемом n1= 19 измерений произведена до применения мер очистки воды, вторая (y) объемом n2= 21 измерение - после:
(Х): (0.11, 0.13, 0.22, 0.17, 0.19, 0.23, 0.25, 0.14, 0.18, 0.11, 0.15, 0.17, 0.10, 0.24, 0.16, 0.19, 0.21, 0.24, 0.20);
(Y): (0.19, 0.17, 0.10, 0.10, 0.20, 0.11, 0.15, 0.15, 0.19, 0.25, 0.21, 0.17, 0.10, 0.14, 0.18, 0.20, 0.21, 0.17, 0.11, 0.16, 0.19)
Решение.
1. Производятся непосредственные вычисления выборочных средних значений и выборочных дисперсий по выборкам:

2. Вычисляется отношение Фишера:

3. По таблице распределения Фишера находится квантиль:

Производится сравнение статистики критерия (отношения Фишера) со значением найденного квантиля.
Поскольку 1.227 < 2.17, то можно сделать вывод о том, что с вероятностью 0.95 обе выборки принадлежат генеральным совокупностям с равными дисперсиями.
4. Вычисляется критерий Стьюдента:

5. По таблице распределения Стьюдента (Приложение 8.2) находится квантиль:

6. Производится сравнение значений критерия Стьюдента и найденное значение квантиля:
0.966 < 2.0294
Следовательно, расхождения между математическими ожиданиями рассматриваемых совокупностей незначительны и гипотеза о равенстве математических ожиданий принимается. Т.е. использованные технологии повышения качества воды в колодце оказались с вероятностью 0.95 неэффективными (улучшения качества воды практически не произошло).
Пример 8.9.1.
Вернемся к исходным данным примера 8.8.1. Существо задачи состояло в необходимости сравнения содержания вредных примесей в воде (эффективности предпринятых мер повышения качества воды) технологического колодца с надежностью g = 0.95 (уровнем значимости a= 0.05).
Приложение 8.1.

Приложение 8.2.

Приложение 8.3.

Приложение 8.4.

Интервальное оценивание числовых характеристик
И параметров распределения
генеральной совокупности [49, 50, 51].
8.1. Законы распределения случайных величин и их параметры.
Группированный статистический ряд.
Пусть имеется выборка (х1=xmin, х2,…, хn=xmax) из генеральной совокупности Х.
Промежуток [хmin, xmax] делится на некоторое число k равных по длине промежутков. Обозначим эти промежутки слева направо через:
Здесь принято: а0 = хmin, ak = xmax.
Пусть ni – число элементов выборки, попавших в промежуток Di. Числа n1, n2 … nk называют частотами попадания элементов выборки в рассматриваемые промежутки.
Определение 1. Совокупность промежутков и соответствующих им частот называется группированным статистическим рядом.
Для определения числа k промежутков рекомендуется следующая полуэмпирическая формула:
где n – объем выборки, как правило n Î [30, 100].
Применяется также формула Старджесса:
Длина h промежутков определится через размах R выборки соотношением:
Вместо группы элементов, попавших в конкретный интервал Di, может рассматриваться один их представитель. В качестве такого представителя выбирается средняя точка промежутка Di.
Группированный статистический ряд обычно представляют в виде таблицы, что удобно выполнять в Excel.
Определение 2. Выборочной оценкой генеральной числовой характеристики называется ее приближенное значение, найденное по выборке.
Основными оценками являются:
Выборочное среднее , которое является оценкой генерального математического ожидания m = M[X]:
(8.1.1)
Выборочный центральный момент sd порядка d, который является оценкой генерального центрального момента порядка d (md = M[(X-m)d]):
(8.1.2)
Выборочный начальный момент at порядка t, который является оценкой генерального начального момента порядка t at = M(Xt):
(8.1.3)
Выборочная дисперсия s2, которая является оценкой генеральной дисперсии s2 = m2:
(8.1.3)
Выборочное среднее квадратическое отклонение s, которое является оценкой генерального среднего квадратического отклонения :
(8.1.4)
С помощью группированного статистического ряда можно приближенно вычислить выборочные моменты. Так как группа элементов выборки, входящих в промежуток Di, заменяется средней точкой промежутка, то следует полагать, что элемент как бы встречается в выборке ni раз, т.е. имеет частоту ni. Получаем следующие формулы:
где ni – число элементов выборки, попавших в промежуток Di
n – объем выборки
Применение этих формул целесообразно при ручных расчетах.
8.2. Метод максимального правдоподобия
оценок параметров генерального распределения.
Пусть известен вид закона генерального распределения, а параметры в него входящие, неизвестны. Возникает задача их статистической оценки.
Метод максимального правдоподобия, созданный английским математиком Р. Фишером (1890-1962), является достаточно универсальным.
Пусть имеется выборка (х1, х2,…, хn) из генеральной совокупности с плотностью вероятности f(x,q), содержащей один неизвестный параметр q.
Выборка является n-мерной случайной величиной, компоненты xi которой взаимно независимы, одинаково распределены с плотностью f(x,q), следовательно, на основе теоремы умножения плотностей распределения случайных величин, плотность распределения n-мерной случайной величины (х1, х2,…, хn) будет равна:
(8.2.1)
Эта функция называется функцией правдоподобия для рассматриваемой выборки.
Будем считать q неслучайной переменной величиной, а элементы х1, х2,…, хn выборки – фиксированными, т.к. выборка фактически осуществлена. Если придать q различные значения, то естественно ожидать, что плотность L(x1, x2,…, xn; q) примет максимальное значение в случае, когда значение q окажется равным истинному значению, т.к. при других значениях q менее вероятно за один раз получить именно данную выборку.
Эти интуитивные соображения приводят к тому, что за оценку q принимают такое его значение, при котором функция правдоподобия L(·) достигает максимума.
Поскольку L(·) состоит из произведений, то технически удобнее искать максимум логарифма: , учитывая, что точка , доставляющая максимум ln(L(·)), доставляет максимум и функции L(·).
Тогда, для определения составляем уравнение:
,
которое называется уравнением правдоподобия, а его решение
,
зависящее от элементов выборки, называют оценкой максимального правдоподобия.
В случае, когда генеральная плотность вероятности содержит k параметров, то вместо одного уравнения правдоподобия решается система уравнений:
(8.2.2)
Рассмотрим несколько типовых примеров.
Пример 8.2.1.
Показательный закон с плотностью:
Функция правдоподобия при х > 0 имеет вид:
После логарифмирования:
Находится частная производная функции L(l, x) по переменной l:
,
отсюда:
, или
Пример 8.2.2.
Нормальный закон распределения с плотностью:
где m – математическое ожидание случайной величины Х генеральной совокупности;
s - среднее квадратическое отклонение случайной величины Х генеральной совокупности.
В данном случае имеется два параметра m и s2. Следовательно, функция правдоподобия L(m, s) имеет вид:
После логарифмирования:
Далее, дифференцируя [ln(L(m, s)] по m и s2, получаем систему уравнений правдоподобия:
Из первого уравнения находим:
, откуда получаем
Из второго уравнения:
Пример 8.2.3.
Равномерное распределение с плотностью:
Функция правдоподобия в этом случае имеет вид:
Необходимо найти такие значе







