Создание и редактирование структуры (матрицы) базы социологических данных в SPSS.
Матрица данных
Предположим, что 10 анкет были заполнены следующим образом:
| number
| Var1
| Var2
| age
| terr
|
|
| Единая Россия
| женский
|
| Сургут
|
|
| Единая Россия
| мужской
|
| Нефтеюганск
|
|
| КПРФ
| мужской
|
| Нефтеюганск
|
|
| Единая Россия
| женский
|
| Нефтеюганск
|
|
| Правое дело
| мужской
|
| Нижневартовск
|
|
| КПРФ
| женский
|
| Нижневартовск
|
|
| Справедливая Россия
| мужской
|
| Сургут
|
|
| Справедливая Россия
| женский
|
| Сургут
|
|
| Справедливая Россия
| мужской
|
| Сургут
|
|
| Единая Россия
| женский
|
| Сургут
|
Приведенная выше таблица называется матрицей данных. Данные, предназначенные для обработки в SPSS для Windows, должны быть представлены в виде такой матрицы. Матрица данных состоит из определенного числа строк и столбцов. Каждая строка соответствует одной анкете, а каждый столбец — одной переменной. Так как в нашем небольшом опросе участвовало 10 респондентов, матрица содержит 10 строк. Создание и редактирование файлов данных
После запуска программы SPSS в открывшемся диалоговом окне редактора данных DataEditor нужно перейти на вкладку (Просмотр переменных), щелкнув на ее ярлычке мышью.
Вкладка (Просмотр данных), которая отображается сразу после запуска редактора, предназначена для ввода значений в создаваемый файл данных.
Вкладка (Просмотр переменных) позволяет задать структуру файла данных (создать макет данных), то есть определить имена, метки и структуры переменных. Заголовки столбцов представляют собой параметры каждой из переменных, например, Name (Имя), Type (Тип), Width (Ширина) и т.д.
Что редактируем?
-Имя переменной: Чтобы задать имя переменной, нужно:Введите в текстовом поле Name (Имя) выбранное имя переменной.При выборе имени переменной следует соблюдать определенные правила:
Имена переменных могут содержать буквы латинского алфавита и цифры. Кроме того, допускаются спе-циальные символы _ (подчеркивание),. (точка), а также символы @ и #. Не разрешаются, например, пробелы, знаки других алфавитов и специальные символы, такие как!,?," и *.
Имя переменной должно начинаться с буквы.
Последний символ имени не может быть точкой или знаком подчеркивания (_).
Длина имени переменной не должна превышать восьми символов.
Чтобы задать имя первой переменной, просто введите его с клавиатуры в текущую ячейку.
-Тип переменной: можем задать не число, а валюту, дату и пр.
- Ширина: Параметр (ширина) позволяет задать максимальное количество знаков, которое может иметь значение переменной, включая дробную часть. По умолчанию задана ширина – 8 знаков.
-Десятичные: предназначен для задания числа десятичных знаков после запятой в случае, если тип переменной допускает использование дробных чисел. Для строковых переменных значение в ячейке (Десятичные) автоматически устанавливается равным нулю, а для числовых переменных – равным 2.
-Метка— это название, позволяющая описать переменную более подробно. Метка перемен-ной может содержать до 256 символов. В метках переменных различаются прописные и строчные буквы. Они отображаются в том виде, в каком были введены.
-Значения: это название, позволяющее более подробно описать возможные значения переменной. Так, например, в случае переменной var2 – «пол» - можно задать метку "мужской" для значения "1" и метку "женский" для значения "2". Нажимать «Добавить» при каждой заданной метке.
-Пропущенные значения. Необходимость в этом параметры возникает, когда требуется различать причины пропусков значений. Например, пропуск в данных может быть обусловлен тем, что респондент еще не был опрошен, а может быть, он отказался отвечать на данный вопрос.Поэтому можно для еще не опрошенных оставлять пустую ячейку, при вводе данных, а для не опреде-лившихся можно обозначить кодом «9». Если ввести значение «0» в столбец Missingvalues, то оно не будет использоваться в дальнейшем при обработке наряду с пустыми ячейками.
(!)Чтобы задать пропущенные значения, щелкните в поле Пропущенные на кнопке с тремя точками. Откроется диалоговое окно (Определение пропущенных значений). По умолчанию предлагается вариант (Нет пропущенных значений), то есть все значения в настоящее время рассматриваются как допустимые.
- Поле Columns определяет ширину, которую будет иметь в таблице данный столбец при отображении значений. Стандарт – 8.
- Шкала измерения. Здесь можно задать шкалу переменной, которая может быть номинальной, порядковой или количественная. По умолчанию принимается колич.шкала измерения.
Номинальная шкала включает в себя класс переменных, значения которых можно разделить на группы, но невозможно проранжировать. Примерами соответствующих переменных являются пол, национальность, религия и т.д.
Порядковая шкала включает в себя класс переменных, значения которых можно не только разделить на группы, но и проранжировать в зависимости от выраженности измеряемого свойства. Пример: степень удовлентворенности – оч, не оч, совсем нет
Количественная шкала включает в себя класс переменных, значения которых можно как разделить на группы и проранжировать, так и определить их величину в точных терминах (те самые "на сколько?" и "во сколько?"). Типичными примерами соответствующих переменных являются возраст, заробтная плата, количество детей и т.д.
Файл разбиения
Файл разбиения "расщепляет" данные файла на отдельные группы для анализа, в соответствии со значениями одной или нескольких группирующих переменных. Если задано несколько группирующих переменных, то наблюдения будут группироваться по значениям каждой переменной внутри групп, образованных значениями предыдущей переменной в списке Группы образуются по. Если, например, вы выберете пол, а затем национальность, то наблюдения будут отсортированы сначала по значениям переменной пол, а затем внутри каждой полученной категории - по значениям переменной национальность.
- Можно задать до 8-ми группирующих переменных.
- Каждые 8 байтов длинной текстовой переменной (с длиной более 8 байтов) считаются отдельной переменной, вплоть до достижения предела восьми группирующих переменных.
- Наблюдения должны быть отсортированы по значениям группирующих переменных и в том же порядке, что и переменные в списке Группы образуются по. Если файл данных еще не отсортирован, выберите альтернативу Сортировать по группирующим переменным.
Сравнить группы. Группы разбиения представляются вместе для сравнения. В случае сводных таблиц - создается одна таблица, в которую включаются группирующие переменные, причем после построения их можно свободно перемещать между строками, столбцами и слоями таблицы. В случае диаграмм - для каждой группы в файле разбиения создается отдельная диаграмма, и эти диаграммы выводятся вместе в средстве просмотра.
Организовать вывод по группам. Все результаты каждой процедуры выводятся отдельно для каждой группы разбиения.
Как расщепить файл
- Выберите в меню:
Данные> Расщепить файл...
- Выберите Сравнить группы или Организовать вывод по группам.
- Выберите одну или несколько группирующих переменных.
Если файл данных еще не отсортирован по значениям группирующих переменных, выберите Сортировать по группирующим переменным.
6. Технология отбора данных в SPSS с помощью задания условий.
. Чтобы применить фильтрацию (отбор) наблюдений, необходимо выбрать:
Данные
Отобрать наблюдения
Команда Отобрать наблюдения выбирает из всей совокупности наблюдений подмножество (подвыборку) разными способами –
Ø это может быть случайная выборка (Random sample of cases), когда случайным образом выбирается определенное число наблюдений. Это бывает полезно, если обрабатывается не весь файл, а только его часть с целью сокращения времени предварительного анализа.
Ø а может быть выборка по условию (If condition is satistfied). Из файла данных выбираются только те наблюдения, которыее удовлетворяют некоторому условию. В качестве условия следует задать логическое выражение. Для каждого наблюдения оно принимает либо истинное, либо ложное значение, либо не принимает никакого значения. Если условие истинно, то наблюдение выбирается, в противном случае — отбрасывается.
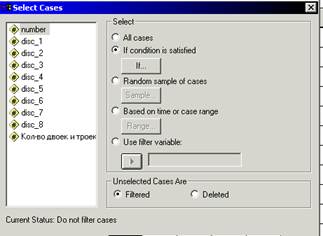

Ø Нажимаем кнопку __ if__, чтобы задать условия отбора наблюдений. 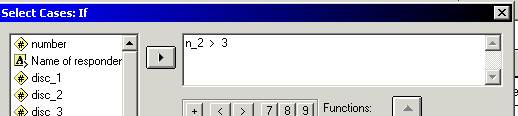
Ø Наблюдения, не попавшие в указанное подмножество, не используются в дальнейшем анализе. Их как будто нет, однако они сохраняются в исходном файле данных. Визуально их легко выделить, так как соответствующий им номер строки перечеркнут. Данная операция действует только в пределах текущего сеанса работы. При повторной загрузке файла данных снова доступна вся совокупность. Если же в течение того же сеанса вы хотите вернуться к полной выборке, то надо снять фильтр, снова выполнив команду Отобрать наблюдения, но ужевыбравопцию Все наблюдения..
Анализ
Описательные статистики
Таблицы сопряженности
Откроется диалоговое окно Таблицы сопряженности (рис. 36).
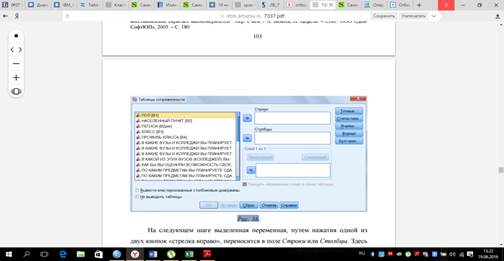
Список исходных переменных содержит переменные открытого файла данных. Здесь можно выбрать переменные для строк и столбцов таблицы сопряженности. Для каждого сочетания двух переменных будет создана таблица сопряженности. Например, если в списке Строки находится три переменных, а в списке Столбцы – две, то мы получим 3х2 = 6 таблиц сопряженности55. В этом окне слева стоит список переменных, из которого и выбираются перемен-ные, необходимые для построения таблицы. Выбор переменной осуществляется путем выделения в списке ее имени.
На следующем шаге выделенная переменная, путем нажатия одной из двух кнопок «стрелка вправо», переносится в поле Строки или Столбцы. Здесь и возникает содержательная исследовательская задача: какая переменная в таблице будет записана в качестве подлежащего, а какая в качестве сказуемого. Ее решение предполагает наличие предварительных гипотез и знание характеристик первичных распределений анализируемого массива данных. При анализе зависимостей двух переменных важнейшим является вопрос о том, какую из переменных считать зависимой, т.е. подверженной влиянию, а какую – независимой, т.е. влияющей.
Для задания статистик, например, вычисления процентов по строкам и столбцам таблицы, используется кнопка Ячейки, открывающая дополнительное диалоговое окно рассматриваемой процедуры (рис. 37).
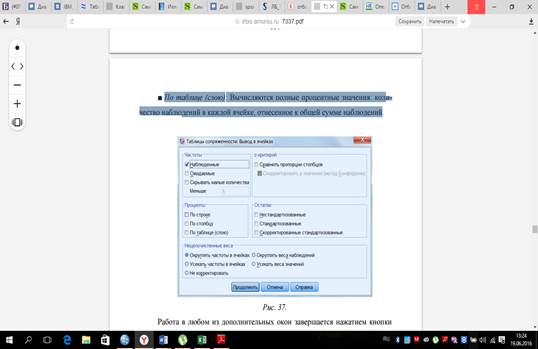
В группе Проценты можно выбрать один или более из нижеследующих
вариантов отображения:
■Построке: Вычисляютсяпроцентныезначенияпострокам: количествонаблюдений в каждой ячейке, отнесенное к сумме по строке.
■Постолбцу: Вычисляютсяпроцентныезначенияпостолбцам: количество наблюдений в каждой ячейке в отношении к сумме столбца.105
■Потаблице (слою): Вычисляютсяполныепроцентныезначения: количество наблюдений в каждой ячейке, отнесенное к общей сумме наблюдений
Работа в любом из дополнительных окон завершается нажатием кнопки Продолжить. Выполнение этой команды ведет к возврату в главное окно процедуры, в котором после нажатия кнопки ОК процедура начнет выполняться, а результаты появятся в окне просмотра56. Первая таблица содержит информацию о числе самих наблюдений; два наблюдения содержат пропущенные значения по крайней мере в одной из двух участвующих переменных. Вторая таблица – это собственно таблица сопряженности.

Создание OLAP кубов
Для получения итогов выполните команду: Analyze\Reports\ OLAP Cubes…( Анализ\ Отчеты\OLAP кубы...)
В диалоговом окне OLAP Кубы выберите одну или несколько количественных анализируемых переменных.
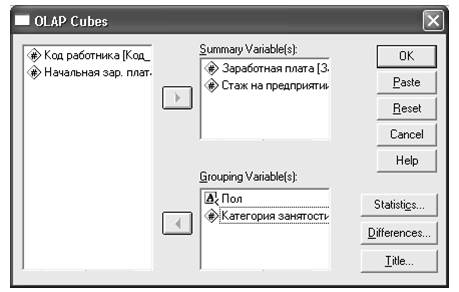
Рис. 1. Диалоговое окно OLAP Cubes
Выберите одну или несколько категориальных группирующих переменных.
Для данных файла Работники.sav диалоговое окно OLAP Cubes представлено на Рис. 1.
Выбрать, какие итоговые функции будут рассчитаны, можно нажав кнопку Statistics ( Статистики). В диалоговом окне OLAP Cubes: Statistics следует добавить или убрать вычисляемые статистики. Нажмите кнопку Continue ( Продолжить).
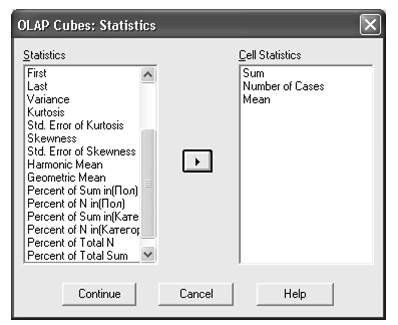
Рис. 2. Диалоговоеокно OLAP Cubes: Statistics
В результате получится таблица, приведенная на Рис. 3.
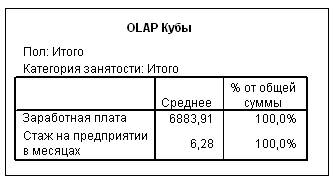
Рис. 3. Пример OLAP Куба
На первый взгляд, этот результат ничем не примечателен, более того отсутствуют «обещанные» итоги по группам категориальных переменных. Для того чтобы их увидеть необходимо, дважды щелкнуть на OLAP Кубе. В строке Пол и Категория занятости появятся стрелки, позволяющие активизировать поля со списками – категориями, по которым подводятся итоги (см. Рис. 4). В традиционной терминологии они называются «слоями». 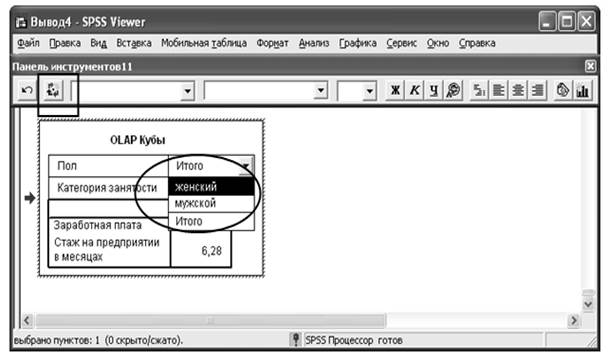
Рис. 4. Поле со списком, для выбора слоя OLAP Куба
Изменить структуру уже созданного OLAP Куба можно, активизировав с помощью кнопки Поля вращения на Панели инструментов одноименного диалогового окна. Кнопка Поля вращения на Рис. 5 выделена прямоугольником.
На Рис. 5 подписаны все элементы, позволяющие управлять структурой OLAP Куба. Например, чтобы поменять порядок группирующих переменных нужно мышью поменять местами обозначающие их элементы.
Описание соответствующих манипуляций достаточно многословно. Лучшим способом понимания технологии изменения структуры OLAP Куба, на наш взгляд, является экспериментальный путь. Попробуйте «подвигать» в диалоговом окне Поля вращения управляющие элементы и проанализируйте результат.
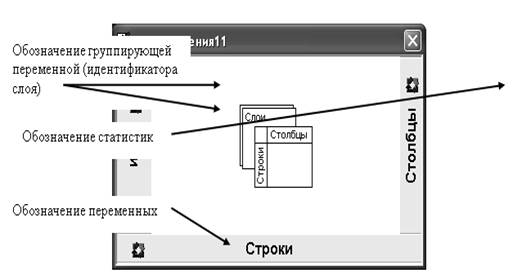
Рис. 5. Диалоговое окно Поля вращения
11. Технология использования командного языка SPSS.
В IBM® SPSS® Statistics есть мощный командный язык, позволяющий сохранять и автоматизировать многие задачи. Командный язык также позволяет пользоваться некоторыми функциональными возможностями, недоступными через меню и диалоговые окна.
Большинство процедур SPSS Statistics можно запустить через меню и диалоговые окна. Однако некоторые процедуры и их параметры доступны только при использовании командного языка – синтаксиса. Синтаксис также позволяет сохранять команды в специальном файле, что в свою очередь позволяет повторять проведенный анализ через какое-то время и запускать его автоматическое выполнение при помощи производственного задания.
Файл командного языка (синтаксиса) – это простой текстовый файл. Хотя можно открыть окно синтаксиса и набирать в нем команды вручную, обычно, бывает проще дать возможность SPSS Statistics помочь Вам построить файл синтаксиса одним из следующих методов:
• Вставкой команд из диалоговых окон
• Копированием команд из журнала
• Копированием команд из файла журнала сеанса.
Подробная информация о синтаксисе содержится в справочной системе, а также в отдельном документе Руководстве по синтаксису, вызываемом в меню Справка. Контекстную справку для текущей команды синтаксиса можно вызвать клавишей F1.
Редактор синтаксиса
Редактор синтаксиса представляет собой текстовое окно, применяемое для набора и запуска на исполнение команд SPSS. Вы можете вводить команды непосредственно в окне набора или просто переносить установки диалоговых окон при помощи выключателя Paste (Вставить), находящегося в самих диалоговых окнах. Этот перенос возможен благодаря тому, что все диалоговые окна написаны на командном языке SPSS. С целью реализации дополнительных возможностей или каких-либо индивидуальных подходов к обработке данных, команды, помещённые в редактор синтаксиса, можно изменять.
- Откройте сначала файл
- Чтобы открыть редактор синтаксиса, выберите в меню File (Файл) / New (Новый) / Syntax (Синтаксис).
- Наберитеследующуюкоманду: FREQUENCIESVARIABLES = sexalterparty.(Как пример!!!!)
- Запустите команду SPSS на исполнение путём нажатия кнопки со значком Run / Current (Выполнить текущую команду).

SPSS перейдёт в окно просмотра результатов. В окне просмотра будет отображены распределения частот переменных sex, alter и party.
Для выполнения команд SPSS при помощи редактора синтаксиса, поступайте следующим образом:
- Выделите щелчком и перетаскиванием курсора команды, которые Вы хотели бы выполнить.
- Если вы хотите выполнить одну команду, расположите курсор в любом месте этой команды.
- Если Вы желаете выполнить все команды, находящиеся в редакторе, выберите в меню Edit (Правка) / SelectAll (Выделить всё). В редакторе будут выделены все команды.
- Затем для выполнения команд щёлкните на кнопке RunCurrent (Выполнить текущую команду) редактора синтаксиса или нажмите одновременно клавиши <Ctrl><R>.
Сохранение файла синтаксиса
Для сохранения файла синтаксиса необходимо выполнить следующие шаги:
- Активируйте редактор синтаксиса, в котором содержатся команды, предназначенные для сохранения.
- Выберите в меню File (Файл) / Save (Сохранить).
Откроется диалоговое окно Saveas... (Сохранить как). В соответствии с установками программа SPSS прибавляет к своим синтаксическим файлам расширение.sps.
- Введите название сохраняемого файла и подтвердите нажатием кнопки Save (Сохранить).
Можно также щёлкнуть на значке сохранения SaveFile (Сохранить файл)
12. Построение двумерных и многомерных таблиц с помощью модуля SPSSTables.
13. Создание таблиц для переменных с одинаковыми вариантами ответа с помощью модуля SPSSTables.
Меняем шкалу в Стране на номинальную
Анализ
Настраиваемые табл
Настраиваемые табл
Переменные b4-b10 (с одинаковыми вариантами ответа) зажимаем, переносим левой кнопкой в окно в Строки
Снизу справа в Расположение категорий выбираем Метки строк в столбцах
Для %% в строках выбираем Итоговые статистики - % по столбцу, меняем формат и кол-во десятичных знаков
Для Подытога: Категории и итоги, добавить Подытог после 5го значения 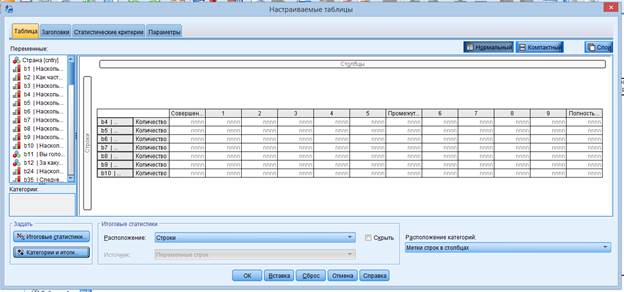
Создание и редактирование структуры (матрицы) базы социологических данных в SPSS.
Матрица данных
Предположим, что 10 анкет были заполнены следующим образом:
| number
| Var1
| Var2
| age
| terr
|
|
| Единая Россия
| женский
|
| Сургут
|
|
| Единая Россия
| мужской
|
| Нефтеюганск
|
|
| КПРФ
| мужской
|
| Нефтеюганск
|
|
| Единая Россия
| женский
|
| Нефтеюганск
|
|
| Правое дело
| мужской
|
| Нижневартовск
|
|
| КПРФ
| женский
|
| Нижневартовск
|
|
| Справедливая Россия
| мужской
|
| Сургут
|
|
| Справедливая Россия
| женский
|
| Сургут
|
|
| Справедливая Россия
| мужской
|
| Сургут
|
|
| Единая Россия
| женский
|
| Сургут
|
Приведенная выше таблица называется матрицей данных. Данные, предназначенные для обработки в SPSS для Windows, должны быть представлены в виде такой матрицы. Матрица данных состоит из определенного числа строк и столбцов. Каждая строка соответствует одной анкете, а каждый столбец — одной переменной. Так как в нашем небольшом опросе участвовало 10 респондентов, матрица содержит 10 строк. Создание и редактирование файлов данных
После запуска программы SPSS в открывшемся диалоговом окне редактора данных DataEditor нужно перейти на вкладку (Просмотр переменных), щелкнув на ее ярлычке мышью.
Вкладка (Просмотр данных), которая отображается сразу после запуска редактора, предназначена для ввода значений в создаваемый файл данных.
Вкладка (Просмотр переменных) позволяет задать структуру файла данных (создать макет данных), то есть определить имена, метки и структуры переменных. Заголовки столбцов представляют собой параметры каждой из переменных, например, Name (Имя), Type (Тип), Width (Ширина) и т.д.
Что редактируем?
-Имя переменной: Чтобы задать имя переменной, нужно:Введите в текстовом поле Name (Имя) выбранное имя переменной.При выборе имени переменной следует соблюдать определенные правила:
Имена переменных могут содержать буквы латинского алфавита и цифры. Кроме того, допускаются спе-циальные символы _ (подчеркивание),. (точка), а также символы @ и #. Не разрешаются, например, пробелы, знаки других алфавитов и специальные символы, такие как!,?," и *.
Имя переменной должно начинаться с буквы.
Последний символ имени не может быть точкой или знаком подчеркивания (_).
Длина имени переменной не должна превышать восьми символов.
Чтобы задать имя первой переменной, просто введите его с клавиатуры в текущую ячейку.
-Тип переменной: можем задать не число, а валюту, дату и пр.
- Ширина: Параметр (ширина) позволяет задать максимальное количество знаков, которое может иметь значение переменной, включая дробную часть. По умолчанию задана ширина – 8 знаков.
-Десятичные: предназначен для задания числа десятичных знаков после запятой в случае, если тип переменной допускает использование дробных чисел. Для строковых переменных значение в ячейке (Десятичные) автоматически устанавливается равным нулю, а для числовых переменных – равным 2.
-Метка— это название, позволяющая описать переменную более подробно. Метка перемен-ной может содержать до 256 символов. В метках переменных различаются прописные и строчные буквы. Они отображаются в том виде, в каком были введены.
-Значения: это название, позволяющее более подробно описать возможные значения переменной. Так, например, в случае переменной var2 – «пол» - можно задать метку "мужской" для значения "1" и метку "женский" для значения "2". Нажимать «Добавить» при каждой заданной метке.
-Пропущенные значения. Необходимость в этом параметры возникает, когда требуется различать причины пропусков значений. Например, пропуск в данных может быть обусловлен тем, что респондент еще не был опрошен, а может быть, он отказался отвечать на данный вопрос.Поэтому можно для еще не опрошенных оставлять пустую ячейку, при вводе данных, а для не опреде-лившихся можно обозначить кодом «9». Если ввести значение «0» в столбец Missingvalues, то оно не будет использоваться в дальнейшем при обработке наряду с пустыми ячейками.
(!)Чтобы задать пропущенные значения, щелкните в поле Пропущенные на кнопке с тремя точками. Откроется диалоговое окно (Определение пропущенных значений). По умолчанию предлагается вариант (Нет пропущенных значений), то есть все значения в настоящее время рассматриваются как допустимые.
- Поле Columns определяет ширину, которую будет иметь в таблице данный столбец при отображении значений. Стандарт – 8.
- Шкала измерения. Здесь можно задать шкалу переменной, которая может быть номинальной, порядковой или количественная. По умолчанию принимается колич.шкала измерения.
Номинальная шкала включает в себя класс переменных, значения которых можно разделить на группы, но невозможно проранжировать. Примерами соответствующих переменных являются пол, национальность, религия и т.д.
Порядковая шкала включает в себя класс переменных, значения которых можно не только разделить на группы, но и проранжировать в зависимости от выраженности измеряемого свойства. Пример: степень удовлентворенности – оч, не оч, совсем нет
Количественная шкала включает в себя класс переменных, значения которых можно как разделить на группы и проранжировать, так и определить их величину в точных терминах (те самые "на сколько?" и "во сколько?"). Типичными примерами соответствующих переменных являются возраст, заробтная плата, количество детей и т.д.





