Вычисление статистических характеристик
В программе Microsoft Excel
В состав Microsoft Excel входит пакет анализа данных, предназначенный для решения сложных статистических и инженерных задач. В пакете представлено большое число статистических функций, обозначение и назначение которых приведено ниже:
| СРОТКЛ
| Вычисляет среднее абсолютных значений отклонений точек данных от среднего.
|
| СРЗНАЧ
| Вычисляет среднее (арифметическое) своих аргументов.
|
| СРЗНАЧА
| Вычисляет среднее (арифметическое) своих аргументов, включая числа, текст и логические значения.
|
| ДОВЕРИТ
| Вычисляет доверительный интервал для среднего генеральной совокупности.
|
| КОРРЕЛ
| Вычисляет коэффициент корреляции между двумя множествами данных.
|
| СЧЁТ
| Подсчитывает количество чисел в списке аргументов.
|
| СЧЁТЗ
| Подсчитывает количество значений в списке аргументов.
|
| КОВАР
| Вычисляет ковариацию, среднее попарных произведений отклонений.
|
| КВАДРОТКЛ
| Вычисляет сумму квадратов отклонений.
|
| ЭКСПРАСП
| Вычисляет экспоненциальное распределение.
|
| ПРЕДСКАЗ
| Вычисляет значение линейного тренда.
|
| ЧАСТОТА
| Вычисляет распределение частот в виде вертикального массива.
|
| ФТЕСТ
| Вычисляет результат F-теста.
|
| СРГЕОМ
| Вычисляет среднее геометрическое.
|
| ОТРЕЗОК
| Вычисляет отрезок, отсекаемый на оси линией линейной регрессии.
|
| ЭКСЦЕСС
| Вычисляет эксцесс множества данных.
|
| НАИБОЛЬШИЙ
| Вычисляет k-ое наибольшее значение из множества данных.
|
| ЛИНЕЙН
| Вычисляет параметры линейного тренда.
|
| МАКС
| Вычисляет максимальное значение из списка аргументов.
|
| МАКСА
| Вычисляет максимальное значение из списка аргументов, включая числа, текст и логические значения.
|
| МЕДИАНА
| Вычисляет медиану заданных чисел.
|
| МИН
| Вычисляет минимальное значение из списка аргументов.
|
| МИНА
| Вычисляет минимальное значение из списка аргументов, включая числа, текст и логические значения.
|
| МОДА
| Вычисляет значение моды множества данных.
|
| НОРМРАСП
| Вычисляет нормальную функцию распределения.
|
| НОРМОБР
| Вычисляет обратное нормальное распределение.
|
| НОРМСТРАСП
| Вычисляет стандартное нормальное интегральное распределение.
|
| НОРМСТОБР
| Вычисляет обратное значение стандартного нормального распределения.
|
| ПИРСОН
| Вычисляет коэффициент корреляции Пирсона.
|
| ПЕРСЕНТИЛЬ
| Вычисляет k-ую персентиль для значений из интервала.
|
| ПРОЦЕНТРАНГ
| Вычисляет процентную норму значения в множестве данных.
|
| ВЕРОЯТНОСТЬ
| Вычисляет вероятность того, что значение из интервала находится внутри заданных пределов.
|
| КВАРТИЛЬ
| Вычисляет квартиль множества данных.
|
| СКОС
| Вычисляет асимметрию распределения.
|
| НАКЛОН
| Вычисляет наклон линии линейной регрессии.
|
| НАИМЕНЬШИЙ
| Вычисляет k-ое наименьшее значение в множестве данных.
|
| НОРМАЛИЗАЦИЯ
| Вычисляет нормализованное значение.
|
| СТАНДОТКЛОН
| Оценивает стандартное отклонение по выборке.
|
| СТАНДОТКЛОНА
| Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения.
|
| СТАНДОТКЛОНП
| Вычисляет стандартное отклонение по генеральной совокупности.
|
| СТАНДОТКЛОНПА
| Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения.
|
| СТОШYX
| Вычисляет стандартную ошибку предсказанных значений y для каждого значения x в регрессии.
|
| СТЬЮДРАСП
| Вычисляет t-распределение Стьюдента.
|
| СТЬЮДРАСПОБР
| Вычисляет обратное t-распределение Стьюдента.
|
| ТТЕСТ
| Вычисляет вероятность, связанную с t-условием Стьюдента.
|
| ДИСП
| Оценивает дисперсию по выборке.
|
| ДИСПА
| Оценивает дисперсию по выборке, включая числа, текст и логические значения.
|
| ДИСПР
| Вычисляет дисперсию для генеральной совокупности.
|
| ДИСПРА
| Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения.
|
Некоторые из указанных функций являются встроенными, другие доступны только после установки пакета анализа. Для установки пакета анализа (если нет строки Анализ данных в меню Сервис) необходимо в меню Сервис загрузить Надстройки инапротив Пакет анализа поставить флажок.
Для анализа данных с помощью статистических функций следует выбрать пустую ячейку для записи результата расчета (например, нижнюю ячейку анализируемого столбца в электронной таблице), в командной строке набрать знак “=”, далее написать заглавными буквами наименование функции, в скобках после наименования функции указать аргументы функции (числа, ссылки на ячейки, имена, текст) и нажать клавишу Enter. Анализ будет выполнен с помощью подходящей статистической или инженерной макрофункции, а результат будет помещен в выбранную пустую ячейку. Статистические функции наиболее удобно вычислять для больших массивов, сведенных в таблицы. Для распространения результатов расчета функции на анализируемые столбцы или строки таблицы полученный результат в выделенной ячейке тянут мышкой вдоль строки или столбца электронной таблицы.
Примеры написания функций (синтаксис):
=КВАДРОТКЛ (4;5;8;7;11;4;3);
=КВАДРОТКЛ (А1:А7).
При написании формул придерживаются следующих правил. В формулах приводят только парное количество скобок, каждая скобка является частью пары открывающей и закрывающей скобок. При указании ссылки на диапазон ячеек используют двоеточие (:) в качестве разделителя между первой и последней ячейками диапазона. Допускается вложение в строку формул не более семи функций. Если формула содержит ссылки на значения ячеек других листов или книг, а имя другой книги или листа содержит небуквенные знаки, это имя необходимо заключить в апострофы ('). Не задают формат для чисел, вводимых в формулы. Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторяют процедуру для каждого листа в отдельности.
Ниже приведены примеры написания и расчета наиболее часто используемых статистических функций.
Дисперсия выборки
Расчетная формула:
Sy2 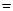
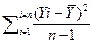
Синтаксис: =ДИСП(число1; число 2;..)
Пример 3: для таблицы экспериментальных данных, приведенной в примере 1 (выше), и занимающей ячейки в электронной таблице в диапазоне А2:F9, вычислить дисперсии для каждого из столбцов.
Для этого произведем операции аналогичные в примере 1, с тем отличием, что в ячейку А12 формул запишем: =ДИСП(А2:А9). Результаты расчета дисперсий приведены в 12-й строке ниже.
| Обозначение ячеек
| A
| B
| C
| D
| E
| F
|
|
| 16,28571
| 3,007857
| 0,01685
| 1764,286
| 0,504107
| 0,000585
|
T-Распределение Стьюдента
Вычисляет величину уровня значимости (в долях) a=1-Р для известного значения t-распределения Стьюдента.
Синтаксис: =СТЬЮДРАСП (x; степени_свободы; хвосты)
x — численное значение величины t-распределения Стьюдента.
Степени_свободы — (f=n-1) целое, указывающее число степеней свободы.
Хвосты — число вычисляемых хвостов распределения. Если хвосты = 1, то функция СТЬЮДРАСП вычисляет одностороннее распределение. Если хвосты = 2, то функция СТЬЮДРАСП вычисляет двухстороннее распределение.
Замечания:
- Если какой-либо из аргументов не является числом, то функция СТЬЮДРАСП вычисляет значение ошибки #ЗНАЧ!.
- Если степени_свободы < 1, то функция СТЬЮДРАСП вычисляет значение ошибки #ЧИСЛО!.
- Аргументы степени_свободы и хвосты усекаются до целых.
- Если хвосты — любое значение, отличное от 1 и 2, то функция СТЬЮДРАСП вычисляет значение ошибки #ЧИСЛО!.
- Если x < 0, то функция СТЬЮДРАСП вычисляет значение ошибки #ЧИСЛО!.
Пример 1: Найти величину уровня значимости a и доверительной вероятности для критерия Стьюдента t=2.306 (двухстороннего распределения) и числа измерений 9 (число степеней свободы 8). В пустую ячейку электронной таблицы внесем запись =СТЬЮДРАСП(2,306;8;2), получим результат 0,0500. Из анализа величины a=0,05 следует, что доверительная вероятность измерений составляет 0,95.
Пример 2: Найти величину уровня значимости a и доверительной вероятности для критерия Стьюдента t=1,397 (двухстороннего распределения) и числа измерений 9 (число степеней свободы 8). В ячейку электронной таблицы запишем =СТЬЮДРАСП(1,397;8;2), получим результат 0,200. Из анализа величины a=0,20 следует, что доверительная вероятность измерений составляет 0,80.
Входной интервал
Для задания входного интервала введите ссылку на ячейки, содержащие анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк.
Группирование
Установите переключатель в положение По столбцам или По строкам в зависимости от расположения данных во входном диапазоне.
Метки в первой строке
Установите переключатель в положение Метки в первой строке, если первая строка во входном диапазоне содержит названия столбцов. Установите переключатель в положение Метки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Уровень надежности
Установите флажок, если в выходную таблицу необходимо включить строку для уровня надежности. В поле введите требуемое значение. Например, значение 95% вычисляет уровень надежности среднего со значимостью 0.05.
К-ый наибольший (используется только тогда, когда не выводится Итоговая статистика)
Установите флажок, если в выходную таблицу необходимо включить строку для k-го наибольшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать максимум из набора данных.
К-ый наименьший (используется только тогда, когда не выводится Итоговая статистика)
Установите флажок, если в выходную таблицу необходимо включить строку для k-го наименьшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать минимум из набора данных.
Выходной диапазон
Введите ссылку на левую верхнюю ячейку выходного диапазона. Этот инструмент анализа выводит два столбца сведений для каждого набора данных. Левый столбец содержит метки статистических данных; правый столбец содержит статистические данные. Состоящий их двух столбцов диапазон статистических данных будет выведен для каждого столбца или для каждой строки входного диапазона в зависимости от положения переключателя.
Новый лист
Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая книга
Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Итоговая статистика
Установите флажок, если в выходном диапазоне необходимо получить по одному полю для каждого из следующих видов статистических данных: Среднее, Стандартная ошибка (среднего), Медиана, Мода, Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность, Интервал, Минимум, Максимум, Сумма, Счет, Наибольшее (#), Наименьшее (#), Уровень надежности.
Пример 1. Провести статистические расчеты состава насыщенного осветленного щелока, подаваемого в вакуум-кристаллизационную установку производства хлорида калия (за период с января по конец ноября) с помощью пакета Описательная статистика. Состав щелока приведен ниже.
Состав насыщенного осветленного щелока
в галургическом производстве КС1, %
| Месяц
| KCl
| NaCl
| MgCl2
| CaSO4
| CaCl2
| Br-
|
| январь
| 20,3
| 17,4
| 0,42
| 0,16
| 0,08
| 0,110
|
|
| 21,1
| 17,5
| 0,40
| 0,18
| 0,18
| 0,104
|
|
| 20,4
| 17,3
| 0,29
| 0,2
| 0,2
| 0,113
|
| февраль
| 20,9
| 16,7
| 0,56
| 0,12
| 0,29
| 0,125
|
|
| 21,5
| 16,9
| 0,52
| 0,18
| 0,22
| 0,124
|
|
| 21,1
| 17,5
| 0,36
| 0,18
| 0,26
| 0,124
|
| март
| 20,8
| 17,3
| 0,58
| 0,17
| 0,29
| 0,124
|
|
| 21,2
| 16,8
| 0,52
| 0,2
| 0,28
| 0,127
|
|
| 20,7
| 15,4
| 0,58
| 0,16
| 0,36
| 0,146
|
| апрель
| 20,6
| 17,0
| 0,38
| 0,17
| 0,30
| 0,130
|
|
| 21,2
| 17,3
| 0,31
| 0,09
| 0,29
| 0,136
|
|
| 20,5
| 17,0
| 0,51
| 0,17
| 0,30
| 0,152
|
| май
| 21,1
| 17,2
| 0,66
| 0,18
| 0,12
| 0,150
|
|
| 21,2
| 16,4
| 0,87
| 0,13
| 0,38
| 0,169
|
|
| 20,4
| 17,3
| 0,52
| 0,15
| 0,34
| 0,158
|
| июнь
| 20,9
| 16,8
| 1,07
| 0,15
| 0,39
| 0,181
|
|
| 21,0
| 17,3
| 0,90
| 0,15
| 0,39
| 0,162
|
|
| 20,7
| 17,4
| 1,29
| 0,12
| 0,46
| 0,176
|
| июль
| 20,0
| 17,0
| 1,00
| 0,14
| 0,42
| 0,169
|
|
| 20,8
| 16,9
| 0,88
| 0,11
| 0,42
| 0,169
|
|
| 20,6
| 16,2
| 1,02
| 0,12
| 0,44
| 0,166
|
| август
| 20,2
| 16,9
| 1,14
| 0,15
| 0,29
| 0,168
|
|
| 21,8
| 17,2
| 1,02
| 0,18
| 0,32
| 0,138
|
| сентябрь
| 20,6
| 16,9
| 1,16
| 0,12
| 0,41
| 0,162
|
|
| 19,9
| 17,2
| 1,05
| 0,14
| 0,39
| 0,145
|
|
| 20,1
| 15,8
| 1,18
| 0,16
| 0,38
| 0,148
|
| октябрь
| 20,6
| 16,9
| 0,90
| 0,14
| 0,42
| 0,160
|
|
| 20,5
| 16,0
| 1,19
| 0,12
| 0,51
| 0,171
|
|
| 20,2
| 16,8
| 1,14
| 0,14
| 0,43
| 0,168
|
| ноябрь
| 20,5
| 17,4
| 0,75
| 0,14
| 0,39
| 0,157
|
|
| 20,3
| 17,0
| 0,84
| 0,16
| 0,27
| 0,150
|
|
| 21,9
| 15,9
| 1,09
| 0,17
| 0,45
| 0,096
|
Для решения задачи выделим приведенную таблицу и скопируем все данные таблицы в программу Microsoft Excel (ячейки А1-G34), сохраним файл в Microsoft Excel под определенным именем. Далее в меню Microsoft Excel с помощью мышки выбираем Сервис, в котором обращаемся к команде Анализ данных. В появившемся диалоговом окне Инструменты анализа выбираем Описательная статистика и команду ОК.
После вхождения в пакет Описательная статистика ипоявления диалогового окна, указываем входной интервал (ячейки В2:G34). Их можно указать путем написания номеров ячеек в виде: $В$2:$G$34 или путем выделения мышкой или клавишами клавиатуры (Shift + ®) столбцов непосредственно на электронной таблице (не указывая левый столбец с указанием месяцев года). Далее выбираем группирование По столбцам, ставим флажок напротив Метки в первой строке (чтобы буквенные обозначения столбцов вывести в итоговой таблице), отмечаем флажками адрес и параметры вывода данных: Новый рабочий лист, Итоговая таблица, Уровень надежности (95%), нажимаем команду ОК. Результаты расчета выводятся на новый рабочий лист в виде таблицы, приведенной ниже.
| KCl
|
| NaCl
|
| MgCl2
|
| CaSO4
|
| CaCl2
|
| Br-
|
|
| Среднее
| 20,737
| Среднее
| 16,893
| Среднее
| 0,7843
| Среднее
| 0,1515
| Среднее
| 0,3334
| Среднее
| 0,1461
|
| Стандартная ошибка
| 0,0858
| Стандартная ошибка
| 0,0934
| Стандартная ошибка
| 0,0545
| Стандартная ошибка
| 0,0047
| Стандартная ошибка
| 0,0177
| Стандартная ошибка
| 0,0040
|
| Медиана
| 20,65
| Медиана
|
| Медиана
| 0,855
| Медиана
| 0,15
| Медиана
| 0,35
| Медиана
| 0,15
|
| Мода
| 20,6
| Мода
| 17,3
| Мода
| 0,52
| Мода
| 0,18
| Мода
| 0,29
| Мода
| 0,124
|
| Стандартное отклонение
| 0,4857
| Стандартное отклонение
| 0,5285
| Стандартное отклонение
| 0,3084
| Стандартное отклонение
| 0,0266
| Стандартное отклонение
| 0,1006
| Стандартное отклонение
| 0,0227
|
| Дисперсия выборки
| 0,2359
| Дисперсия выборки
| 0,2793
| Дисперсия выборки
| 0,0951
| Дисперсия выборки
| 0,0007
| Дисперсия выборки
| 0,0101
| Дисперсия выборки
| 0,0005
|
| Эксцесс
| 0,1066
| Эксцесс
| 1,1760
| Эксцесс
| -1,4379
| Эксцесс
| -0,4137
| Эксцесс
| 0,1953
| Эксцесс
| -0,7151
|
| Асимметричность
| 0,548549
| Асимметричность
| -1,2912
| Асимметричность
| -0,0812
| Асимметричность
| -0,2005
| Асимметричность
| -0,6784
| Асимметричность
| -0,5209
|
| Интервал
|
| Интервал
| 2,1
| Интервал
|
| Интервал
| 0,11
| Интервал
| 0,43
| Интервал
| 0,085
|
| Минимум
| 19,9
| Минимум
| 15,4
| Минимум
| 0,29
| Минимум
| 0,09
| Минимум
| 0,08
| Минимум
| 0,096
|
| Максимум
| 21,9
| Максимум
| 17,5
| Максимум
| 1,29
| Максимум
| 0,2
| Максимум
| 0,51
| Максимум
| 0,181
|
| Сумма
| 663,6
| Сумма
| 540,6
| Сумма
| 25,1
| Сумма
| 4,85
| Сумма
| 10,67
| Сумма
| 4,678
|
| Счет
|
| Счет
|
| Счет
|
| Счет
|
| Счет
|
| Счет
|
|
| Уровень надежности(95,0%)
| 0,1751
| Уровень надежности(95,0%)
| 0,190545
| Уровень надежности(95,0%)
| 0,1112
| Уровень надежности(95,0%)
| 0,0096
| Уровень надежности(95,0%)
| 0,0362
| Уровень надежности(95,0%)
| 0,0082
|
В отредактированном редактором Microsoft Excel (после удаления повторяющихся столбцов обозначений статистических параметров) и в более компактном виде (после сокращения числа знаков после запятой в ячейках таблицы) результаты статистических расчетов можно представить в таблице, приведенной ниже.
Статистические характеристики состава насыщенного щелока
| Статист-е показатели
| KCl
| NaCl
| MgCl2
| CaSO4
| CaCl2
| Br-
|
| Среднее
| 20,74
| 16,89
| 0,78
| 0,15
| 0,33
| 0,15
|
| Стандартная ошибка
| 0,09
| 0,09
| 0,05
| 0,00
| 0,02
| 0,00
|
| Медиана
| 20,65
| 17,00
| 0,86
| 0,15
| 0,35
| 0,15
|
| Мода
| 20,60
| 17,30
| 0,52
| 0,18
| 0,29
| 0,12
|
| Стандартное отклонение (СКО)
| 0,49
| 0,53
| 0,31
| 0,03
| 0,10
| 0,02
|
| Дисперсия выборки
| 0,24
| 0,28
| 0,10
| 0,0007
| 0,01
| 0,0005
|
| Эксцесс
| 0,11
| 1,18
| -1,44
| -0,41
| 0,20
| -0,72
|
| Асимметричность
| 0,55
| -1,29
| -0,08
| -0,20
| -0,68
| -0,52
|
| Интервал
| 2,00
| 2,10
| 1,00
| 0,11
| 0,43
| 0,09
|
| Минимум
| 19,90
| 15,40
| 0,29
| 0,09
| 0,08
| 0,10
|
| Максимум
| 21,90
| 17,50
| 1,29
| 0,20
| 0,51
| 0,18
|
| Сумма
| 663,60
| 540,60
| 25,10
| 4,85
| 10,67
| 4,68
|
| Счет
| 32,00
| 32,00
| 32,00
| 32,00
| 32,00
| 32,00
|
| Уровень надежности (95,0%)
| 0,18
| 0,19
| 0,11
| 0,01
| 0,04
| 0,01
|
В итоговой табл. результатов статистических расчетов уровень надежности представляет собой доверительный интервал, интервал – разность между максимальным и минимальным значениями выборки, счет – число значений (размер) выборки, сумма – сумма всех значений выборки.
Вычисление статистических характеристик
В программе Microsoft Excel
В состав Microsoft Excel входит пакет анализа данных, предназначенный для решения сложных статистических и инженерных задач. В пакете представлено большое число статистических функций, обозначение и назначение которых приведено ниже:
| СРОТКЛ
| Вычисляет среднее абсолютных значений отклонений точек данных от среднего.
|
| СРЗНАЧ
| Вычисляет среднее (арифметическое) своих аргументов.
|
| СРЗНАЧА
| Вычисляет среднее (арифметическое) своих аргументов, включая числа, текст и логические значения.
|
| ДОВЕРИТ
| Вычисляет доверительный интервал для среднего генеральной совокупности.
|
| КОРРЕЛ
| Вычисляет коэффициент корреляции между двумя множествами данных.
|
| СЧЁТ
| Подсчитывает количество чисел в списке аргументов.
|
| СЧЁТЗ
| Подсчитывает количество значений в списке аргументов.
|
| КОВАР
| Вычисляет ковариацию, среднее попарных произведений отклонений.
|
| КВАДРОТКЛ
| Вычисляет сумму квадратов отклонений.
|
| ЭКСПРАСП
| Вычисляет экспоненциальное распределение.
|
| ПРЕДСКАЗ
| Вычисляет значение линейного тренда.
|
| ЧАСТОТА
| Вычисляет распределение частот в виде вертикального массива.
|
| ФТЕСТ
| Вычисляет результат F-теста.
|
| СРГЕОМ
| Вычисляет среднее геометрическое.
|
| ОТРЕЗОК
| Вычисляет отрезок, отсекаемый на оси линией линейной регрессии.
|
| ЭКСЦЕСС
| Вычисляет эксцесс множества данных.
|
| НАИБОЛЬШИЙ
| Вычисляет k-ое наибольшее значение из множества данных.
|
| ЛИНЕЙН
| Вычисляет параметры линейного тренда.
|
| МАКС
| Вычисляет максимальное значение из списка аргументов.
|
| МАКСА
| Вычисляет максимальное значение из списка аргументов, включая числа, текст и логические значения.
|
| МЕДИАНА
| Вычисляет медиану заданных чисел.
|
| МИН
| Вычисляет минимальное значение из списка аргументов.
|
| МИНА
| Вычисляет минимальное значение из списка аргументов, включая числа, текст и логические значения.
|
| МОДА
| Вычисляет значение моды множества данных.
|
| НОРМРАСП
| Вычисляет нормальную функцию распределения.
|
| НОРМОБР
| Вычисляет обратное нормальное распределение.
|
| НОРМСТРАСП
| Вычисляет стандартное нормальное интегральное распределение.
|
| НОРМСТОБР
| Вычисляет обратное значение стандартного нормального распределения.
|
| ПИРСОН
| Вычисляет коэффициент корреляции Пирсона.
|
| ПЕРСЕНТИЛЬ
| Вычисляет k-ую персентиль для значений из интервала.
|
| ПРОЦЕНТРАНГ
| Вычисляет процентную норму значения в множестве данных.
|
| ВЕРОЯТНОСТЬ
| Вычисляет вероятность того, что значение из интервала находится внутри заданных пределов.
|
| КВАРТИЛЬ
| Вычисляет квартиль множества данных.
|
| СКОС
| Вычисляет асимметрию распределения.
|
| НАКЛОН
| Вычисляет наклон линии линейной регрессии.
|
| НАИМЕНЬШИЙ
| Вычисляет k-ое наименьшее значение в множестве данных.
|
| НОРМАЛИЗАЦИЯ
| Вычисляет нормализованное значение.
|
| СТАНДОТКЛОН
| Оценивает стандартное отклонение по выборке.
|
| СТАНДОТКЛОНА
| Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения.
|
| СТАНДОТКЛОНП
| Вычисляет стандартное отклонение по генеральной совокупности.
|
| СТАНДОТКЛОНПА
| Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения.
|
| СТОШYX
| Вычисляет стандартную ошибку предсказанных значений y для каждого значения x в регрессии.
|
| СТЬЮДРАСП
| Вычисляет t-распределение Стьюдента.
|
| СТЬЮДРАСПОБР
| Вычисляет обратное t-распределение Стьюдента.
|
| ТТЕСТ
| Вычисляет вероятность, связанную с t-условием Стьюдента.
|
| ДИСП
| Оценивает дисперсию по выборке.
|
| ДИСПА
| Оценивает дисперсию по выборке, включая числа, текст и логические значения.
|
| ДИСПР
| Вычисляет дисперсию для генеральной совокупности.
|
| ДИСПРА
| Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения.
|
Некоторые из указанных функций являются встроенными, другие доступны только после установки пакета анализа. Для установки пакета анализа (если нет строки Анализ данных в меню Сервис) необходимо в меню Сервис загрузить Надстройки инапротив Пакет анализа поставить флажок.
Для анализа данных с помощью статистических функций следует выбрать пустую ячейку для записи результата расчета (например, нижнюю ячейку анализируемого столбца в электронной таблице), в командной строке набрать знак “=”, далее написать заглавными буквами наименование функции, в скобках после наименования функции указать аргументы функции (числа, ссылки на ячейки, имена, текст) и нажать клавишу Enter. Анализ будет выполнен с помощью подходящей статистической или инженерной макрофункции, а результат будет помещен в выбранную пустую ячейку. Статистические функции наиболее удобно вычислять для больших массивов, сведенных в таблицы. Для распространения результатов расчета функции на анализируемые столбцы или строки таблицы полученный результат в выделенной ячейке тянут мышкой вдоль строки или столбца электронной таблицы.
Примеры написания функций (синтаксис):
=КВАДРОТКЛ (4;5;8;7;11;4;3);
=КВАДРОТКЛ (А1:А7).
При написании формул придерживаются следующих правил. В формулах приводят только парное количество скобок, каждая скобка является частью пары открывающей и закрывающей скобок. При указании ссылки на диапазон ячеек используют двоеточие (:) в качестве разделителя между первой и последней ячейками диапазона. Допускается вложение в строку формул не более семи функций. Если формула содержит ссылки на значения ячеек других листов или книг, а имя другой книги или листа содержит небуквенные знаки, это имя необходимо заключить в апострофы ('). Не задают формат для чисел, вводимых в формулы. Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторяют процедуру для каждого листа в отдельности.
Ниже приведены примеры написания и расчета наиболее часто используемых статистических функций.





