Поскольку на практике разных пользователей системы обычно интересует доступ к одним и тем же данным, наиболее простым разнесением функций такой системы между несколькими компьютерами будет разделение логических уровней приложения между одной серверной частью приложения, отвечающим за доступ к данным, и находящимися на нескольких компьютерах клиентскими частями, реализующими интерфейс пользователя. Логика приложения может быть отнесена к серверу, клиентам, или разделена между ними (рис. 1.3).
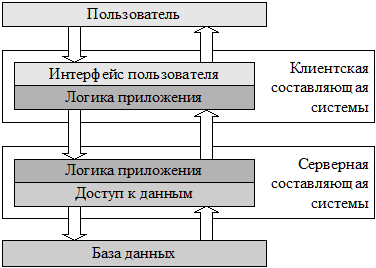
Рисунок 1.3. Двухзвенная архитектура
Архитектуру построенных по такому принципу приложений называют клиент-серверной или двухзвенной. На практике подобные системы часто не относят к классу распределенных, но формально они могут считаться простейшими представителями распределенных систем.
Развитием архитектуры клиент-сервер является трехзвенная архитектура, в которой интерфейс пользователя, логика приложения и доступ к данным выделены в самостоятельные составляющие системы, которые могут работать на независимых компьютерах (рис. 1.4).
я 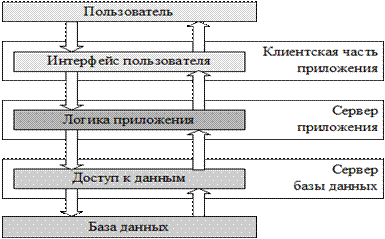
Запрос пользователя в подобных системах последовательно обрабатывается клиентской частью системы, сервером логики приложения и сервером баз данных. Однако обычно под распределенной системой понимают системы с более сложной архитектурой, чем трехзвенная.
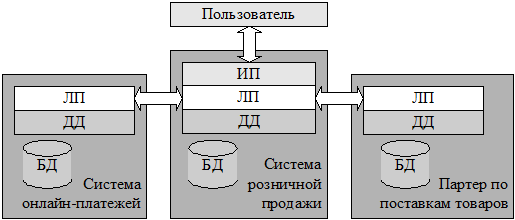
Применительно к приложениям автоматизации деятельности предприятия, распределенными обычно называют системы с логикой приложения, распределенной между несколькими компонентами системы, каждая из которых может выполняться на отдельном компьютере. Например, реализация логики приложения системы розничных продаж должна использовать запросы к логике приложения третьих фирм, таких как поставщики товаров, системы электронных платежей или банки, предоставляющие потребительские кредиты (рис 1.5).
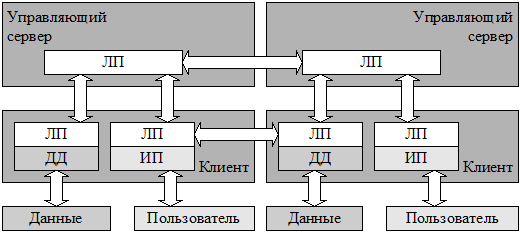
Таким образом, в обиходе под распределенной системой часто подразумевают рост многозвенной архитектуры «в ширину», когда запросы пользователя не проходят последовательно от интерфейса пользователя до единственного сервера баз данных. В качестве другого примера распределенной системы можно привести сети прямого обмена данными между клиентами (peer-to-peer networks). Если предыдущий пример имел «древовидную» архитектуру, то сети прямого обмена организованы более сложным образом, рис. 1.6. Подобные системы являются в настоящий момент, вероятно, одними из крупнейших существующих распределенных систем, объединяющие миллионы компьютеров.
Требования к распределенным системам
Чтобы достигнуть цели своего существования – улучшения выполнения запросов пользователя – распределенная система должна удовлетворять некоторым необходимым требованиям. Можно сформулировать следующий набор требований, которым в наилучшем случае должна удовлетворять распределенная вычислительная система.
Открытость. Все протоколы взаимодействия компонент внутри распределенной системы в идеальном случае должны быть основаны на общедоступных стандартах. Это позволяет использовать для создания компонент различные средства разработки и операционные системы. Каждая компонента должна иметь точную и полную спецификацию своих сервисов. В этом случае компоненты распределенной системы могут быть созданы независимыми разработчиками. При нарушении этого требования может исчезнуть возможность создания распределенной системы, охватывающей несколько независимых организаций.
Масштабируемость. Масштабируемость вычислительных систем имеет несколько аспектов. Наиболее важный из них для данного курса – возможность добавление в распределенную систему новых компьютеров для увеличения производительности системы, что связано с понятием балансировки нагрузки (load balancing) на серверы системы. К масштабированию относятся так же вопросы эффективного распределение ресурсов сервера, обслуживающего запросы клиентов.
Поддержание логической целостности данных. Запрос пользователя в распределенной системе должен либо корректно выполняться целиком, либо не выполняться вообще. Ситуация, когда часть компонент системы корректно обработали поступивший запрос, а часть – нет, является наихудшей.
Устойчивость. Под устойчивостью понимается возможность дублирования несколькими компьютерами одних и тех же функций или же возможность автоматического распределения функций внутри системы в случае выхода из строя одного из компьютеров. В идеальном случае это означает полное отсутствие уникальной точки сбоя, то есть выход из строя одного любого компьютера не приводит к невозможности обслужить запрос пользователя.
Безопасность. Каждый компонент, образующий распределенную систему, должен быть уверен, что его функции используются авторизированными на это компонентами или пользователями. Данные, передаваемые между компонентами, должны быть защищены как от искажения, так и от просмотра третьими сторонами.
Эффективность. В узком смысле применительно к распределенным системам под эффективностью будет пониматься минимизация накладных расходов, связанных с распределенным характером системы. Поскольку эффективность в данном узком смысле может противоречить безопасности, открытости и надежности системы, следует отметить, что требование эффективности в данном контексте является наименее приоритетным.
Основные условия и требования к распределенной обработке данных
Такая отличительная особенность БД, как многоцелевое параллельное использование данных, предопределяет наличие средств, обеспечивающих практически одновременный и независимый доступ к одним и тем же данным. Причём сама база может быть размещена на одном или нескольких компьютерах.
Ведущими поставщиками СУБД сформулированные следующие свойства "идеальной" системы управления распределёнными БД:
Прозрачность относительно расположения данных: СУБД должна представлять все данные так, как если бы они были локальными.
Гетерогенность системы: СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью (независимость от СУБД).
Прозрачность относительно сети: СУБД должна одинаково работать в условиях разнородных сетей.
Поддержка распределенных запросов: пользователь должен иметь возможность объединять данные из любых баз, даже если они размещены в разных системах.
Поддержка распределенных изменений: пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в разных системах.
Поддержка распределенных транзакций: СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов как в отдельных системах, так и в сети.
Безопасность: СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа.
Универсальность доступа: СУБД должна обеспечивать единую методику доступа ко всем данным.
Ни одна из существующих СУБД не смогла достигнуть этого идеала из-за ряда практических проблем, например, низкой, несбалансированной производительности сетей передачи данных, необходимости обеспечивать совместимость данных стандартного типа, для хранения которых в разных системах используются разные физические форматы и кодировки, необходимо обеспечивать совместимость СУБД разных типов и поставщиков и др.
Указанные причины определили на практике частичность и "этапность" введения в СУБД возможностей распределённой обработки данных. В простейшем случае пользователь по сети может обращаться к записям в БД, размещённым на других компьютерах. В других случаях СУБД производит аутентификацию удалённого клиента и устанавливает сетевые соединения.
Режимы работы с БД можно классифицировать по следующим признакам:
многозадачность - однопользовательский или многопользовательский;
правило обслуживания запросов - последовательное или параллельное; схема размещение данных - централизованная или распределённая БД.
Общая тенденция развития технологий обработки данных соответствует этапам развития СВТ и ИТ, и в первую очередь - сетевых. В этом смысле выделяют два класса: системы распределённой обработки данных и системы распределённых баз данных.
Системы распределённой обработки данных в основном отражают структуру и свойства многопользовательских ОС с БД, размещённой на большом центральном компьютере (мэйнфрейме). До недавнего времени это был единственно возможный вариант вычислительной среды для реализации больших БД. Клиентские места в этом случае реализовались в виде терминалов или мини-ЭВМ, обеспечивающих в основном вводвывод данных и не имеющих собственных вычислительных ресурсов для функционально-ориентированной обработки получаемых данных.
Развитие сетевых технологий в сочетании с широким распространением персональных ЭВМ и внедрением стандартов открытых систем привело к появлению систем БД, размещённых в сети разнотипных компьютеров. Такие системы распределённых баз данных обеспечивают обработку распределённых запросов, когда при обработке одного запроса используются ресурсы базы, размещенные в сети на различных ЭВМ. Система распределённых БД состоит из узлов, каждый из которых является СУБД, а узлы взаимодействуют между собой так, что БД любого узла доступна пользователю, так как если бы она была для него локальной. Соответственно, программы, обеспечивающие целевую (функциональную) обработку данных, могут быть организованы так, чтобы обеспечивать более эффективное использование совокупных вычислительных ресурсов за счёт специализированного разделения функций обработки между центральным процессом СУБД и клиентскими функционально-ориентированными процедурами.
Использование объектно-ориентированного подхода позволяет свести проектирование открытой системы к оптимальному синтезу функционально независимых компонент (объектов), совместно выполняющих заданные функции системы с требуемой эффективностью, и позволяющих адаптировать систему к вновь появляющимся задачам за счёт набора специфических свойств (наследование и проч.). Таким образом, значительно снижаются затраты на разработку, внедрение и модификацию систем.
Распределенные базы данных, РБД (англ. "Distributed DataBase", DDB) представляют определенным образом связанные между собой БД, рассредоточенные на какой-либо территории (локально или регионально), обеспечивающие свободный обмен информацией и поиск данных в них. Такие БД могут располагаться на различных узлах компьютерной сети.
Выделяют однородные и неоднородные РБД. Часто данные размещаются в БД и СУБД по месту своего возникновения или наиболее эффективного использования в ЭВМ, удаленных друг от друга на большие расстояния, хотя каждая из этих ЭВМ управляет своими локальными СУБД. Возникает необходимость решения задач с распределенными БД путем организации между ЭВМ сети передачи данных по каналам связи, а также обеспечения технической и программной поддержки обмена данными между ними.
Для работы с распределенными данными создаются системы управления распределенными базами данных (СУРБД), оснащенные каталогами, хранящими структуру сети, информацию о локальных СУРБД и БД, а также программным обеспечением, управляющим взаимодействием прикладной программы и конкретной локальной БД сети. Управление однотипными локальными СУРБД осуществляется просто. В противном случае в сеть РБД включают различные программные и технические устройства, обеспечивающие единый интерфейс, согласование и возможность выполнения информационных процессов (промежуточную интерфейсную СУРБД, протокол Z39.50 и др.).
Распределенные банки данных
Накапливаемая в сетях разнообразная машиночитаемая информация обычно не концентрируется в какой-либо одной ЭВМ, а распределена по различным ЭВМ. Доступ в подобные РБД (банки) осуществляется специальными сетевыми СУБД, дающими возможность безадресного обращения к данным, подобно обычным БД, реализованным на одной ЭВМ. Зная логическую структуру БД сети, абонент формирует запрос к ней (на языке манипулирования данными), не заботясь о том, в каких именно ЭВМ сети расположены интересующие его данные.
Интерфейс с реальной физической структурой данных осуществляется СУБД автоматически через систему машинных каталогов. При этом не исключено, что окончательный ответ на запрос абонента будет сформирован из данных, хранящихся не в одной, а в нескольких (удаленных друг от друга) ЭВМ сети. Формирование ответа предусматривает многократные обмены между различными ЭВМ и автоматическое редактирование текста ответа. Эта работа производится под управлением операционной системы сети.






