Ниже приведена классическая структура компилятора.
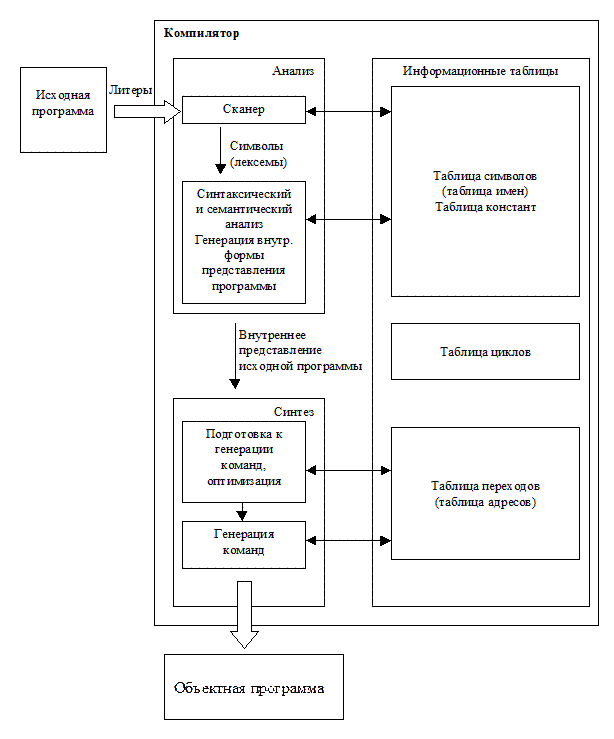
Рассмотрим далее некоторые ее составляющие.
Исходная программа - текст программы на языке высокого уровня, который должен быть переведен в машинный код.
Информационные таблицы - самостоятельные структуры, заполняющиеся в ходе лексического анализа и дополняющиеся во время работы.
Лексический анализатор (или сканер), имеющий на выходе поток лексем, нужен для того, чтобы убрать все лишнее (комментарии, разделители), выделить лексемы, т.е. лексические единицы, из которых строится машинный язык, и преобразовать их к внутренним или промежуточным формам представления. На этом этапе идет активная работа с таблицами, в которые заносится информация о распознанных лексемах, их типах, значениях и т.д. Результатом является поток лексем, эквивалентный исходному тексту.
Синтаксический анализатор необходим для того, чтобы выяснить, удовлетворяют ли предложения, из которых состоит исходная программа, правилам грамматики этого языка. Наряду с проверкой синтаксиса параллельно происходит генерация внутренней формы представления программы.
ОСНОВНЫЕ ЧАСТИ КОМПИЛЯТОРА
Итак, можно выделить следующие этапы компиляции:
Лексический анализ. Замена лексем их внутренним представлением (например, замена операторов, разделителей и идентификаторов числами).
Синтаксический анализ. Иногда на этом этапе также вводятся дополнительные разделители и заменяются существующие для облегчения обработки.
Генерация промежуточного кода (трансляция). На этом этапе осуществляется контроль типа и вида всех идентификаторов и других операндов. При этом обычно преобразование исходной программы в промежуточную (например, польскую) форму записи осуществляется одновременно с синтаксическим анализом.
Оптимизация кода.
Распределение памяти для переменных в готовой программе.
Генерация объектного кода и компоновка программных сегментов.
На всех этих этапах происходит работа с различного рода таблицами. В частности, для каждого блока (если таковые существуют в языке) идентификаторы, описанные внутри, запоминаются вместе со своими атрибутами. Условно все эти этапы можно изобразить следующим образом:
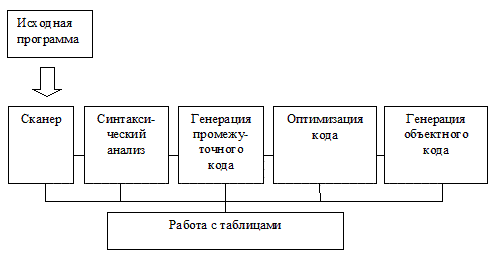
Очевидна зависимость структуры компилятора от структуры ЭВМ, точнее, от имеющейся производительности системы. Например, при малой памяти увеличивается количество проходов компиляции(т.н. многопроходные компиляторы), а при наличии памяти большого объема можно все этапы компиляции произвести за один проход(и тогда мы имеем дело с однопроходным компилятором). Тем не менее, независимо от вычислительных ресурсов, всю вышеперечисленную работу приходится так или иначе делать.
Далее мы рассмотрим вкратце некоторые из этих составных частей процесса компиляции.
Лексический анализ (сканер)
На входе сканера - цепочка символов некоторого алфавита (именно так выглядит для сканера наша исходная программа). При этом некоторые комбинации символов рассматриваются сканером как единые объекты. Например:
- один или более пробелов заменяются одним пробелом;
- ключевые слова (вроде BEGIN, END, INTEGER и др.);
- цепочка символов, представляющая константу;
- цепочка символов, представляющая идентификатор (имя);
Таким образом, лексический анализатор (ЛА) группирует определенные терминальные символы (т.е. входные символы) в единые синтаксические объекты - лексемы. В простейшем случае лексема - это пара вида <тип_лексемы, значение>.
Задача выделения лексем из входного потока зачастую оказывается весьма нетривиальной и зависящей от структуры конкретного языка. Как будет интерпретироваться такая входная последовательность "567АВ"? Это может быть одна лексема (идентификатор), а может – и пара лексем – константа "567" и имя "АВ". Во втором случае либо между лексемами необходимо указание разделителя (например, пробела), либо надо заранее знать, что будет следовать дальше.
Существует два основных типа лексических анализаторов - прямые (ПЛА) и непрямые (НЛА).
Прямой ЛА определяет лексему, расположенную непосредственно справа от текущего указателя, и сдвигает указатель вправо от части текста, образующей лексему (ПЛА определяет тип лексемы, которая образована символами справа от указателя).
Непрямой ЛА определяет, образуют ли знаки, расположенные непосредственно справа от указателя, лексему этого типа. Если да, то указатель передвигается вправо от части текста, образующей лексему. Иными словами, для него заранее задается тип лексемы, и он распознает символы справа от указателя и проверяет, удовлетворяют ли они заданному типу.
У ПЛА более сложная структура - он должен выполнять больше операций, нежели НЛА. Тем не менее в большинстве современных языков программирования используется синтаксис прямых лексических анализаторов (это может быть видно по внешнему виду фраз языка).
Фортран – это классический пример языка, использующего непрямой лексический анализатор. Все дело в том, что в этом языке игнорируются пробелы. Рассмотрим, например, конструкцию
DO5I=1,10 …
Для разбора этого предложения необходим непрямой лексический анализатор, который и определит, что означает цепочка "DO5I" – идентификатор "DO5I", или же ключевое слово "DO", за которым следует метка 5, а далее – имя переменной "I". Впрочем, аналогичные неприятности ожидают и разработчиков компиляторов языков типа C или C++, в которых существуют строковые комментарии "/*…*/" и "//…". При проведении лексического анализа, встретив символ "/", изначально неясно, является ли он оператором или началом строкового комментария. И вообще, многосимвольные лексемы – штука малоприятная для анализа.
Итак, на выходе сканера - внутреннее представление имен, разделителей и т.п. Например:
Вход сканера: AVR:= B + CDE; // Комментарии
Выход сканера: 38, -8, 65, -2, 184
(Если мы условимся обозначать оператор присваивания ":=" числом с кодом –8, операцию сложения – числом –2, а имена переменных числами 38, 65 и 184).
Кроме того, сканер занимается формированием различного рода таблиц. И прежде всего – таблицы имен, в которую он будет заносить распознанные имена – идентификаторы, константы, метки и т.п.
Работа с таблицами
Таблица имен представляет собой структуру, подобную следующей:
| Номер элемента
| Идентификатор
| Дополнительная информация (тип, размер и т.п.)
|
| 1
| A
| идент., тип = "строка"
|
| …
| …
| …
|
| N
| 3.1415
| константа, число
|
Механизм работы с таблицами должен обеспечивать:
(1) быстрое добавление новых идентификаторов и сведений о них;
(2) быстрый поиск информации.
К работе с таблицами мы еще вернемся, когда будем рассматривать хеш-функции.






