Epoch 1/10
| 60000/60000 -
| loss:
| 0.1262
| - acc:
| 0.9621
| - val_loss:
| 0.0514
| - val..
| _acc:
| 0.9830
|
| Epoch 2/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0436
| - acc:
| 0.9864
| - val_loss:
| 0.0320
| - val_
| _acc:
| 0.9892
|
| Epoch 3/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0296
| - acc:
| 0.9909
| - val_loss:
| 0.0268
| - val_
| _acc:
| 0.9922
|
| Epoch 4/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0242
| - acc:
| 0.9925
| - val-Usss:
| 0.0313
| - val_
| .acc:
| 0.9898
|
| Epoch 5/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0170
| - acc:
| 0.9944
| - val_loss:
| 0.0239
| - val_
| _acc:
| 0.9928
|
| Epoch 6/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0164
| - acc:
| 0.9950
| - val_loss:
| 0.0205
| - val_
| _acc:
| 0.9936
|
| Epoch 7/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0131
| - acc:
| 0.9959
| - val_loss:
| 0.0290
| - val_
| .acc:
| 0.9922
|
Epoch 8/10
| 60000/60000 -
| loss:
| 0.0117
| - асс:
| 0.9963
| - val__loss:
| 0.0259
| - val_
| _acc:
| 0.9920
|
| Epoch 9/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0103
| - acc:
| 0.9970
| - val__loss:
| 0.0331
| - val_
| acc:
| 0.9903
|
| Epoch 10/10
|
|
|
|
|
|
|
|
|
|
| 60000/60000 -
| loss:
| 0.0096
| - acc:
| 0.9973
| - val_loss:
| 0.0321
| - val_
| _acc:
| 0.9915
|
Test score: 0.03208116913667295
Test accuracy: 0.99150000000000005
Как видите, такая же сеть в Keras и работает примерно так же, достигая в данном случае точности в 99,15 % на валидационном множестве MNIST.
Кстати, этот пример позволяет нам упомянуть еще одну интересную возможность библиотеки Keras. Обратите внимание, что после шестой эпохи результат получался даже лучше: 99,36 % на валидационном множестве. Не исключено, что после этого у модели начался легкий оверфиттинг! и нам хотелось бы в итоге использовать веса модели после шестой эпохи, а не после десятой; в разделе 4.1 мы уже обсуждали этот бесхитростный метод «регуляризации» — раннюю остановку (early stopping).
Можно, конечно, написать цикл по эпохам обучения, проверять в этом цикле ошибку на валидационном множестве, сохранять веса модели в файл, а затем выбрать файл, соответствующий самой лучшей эпохе. Но оказывается, что в Keras все это можно выразить буквально в аргументах функции f11! Вот как обычно выглядит запуск обучения сложных моделей на практике:
pooet.flt(X_trai”, Y_train,
callbacks=[ ModeSChesCkpCn”(nPo0eS.hdf5’’, pocntoг=”val_acc”, save_best_only=True, save_weSghts_only=False, pode=”auto”)], validatio”_split=0.1" nb_eloch=10" batch_size=64)
Здесь аргумент callbacks позволяет задать функции, запускаемые после каждой эпохи обучения. Можно написать эти функции самому, а можно воспользоваться стандартными. Так, функция ModelCheckpoont из модуля keras.callbacks — это вспомогательная процедура, которая после каждой эпохи обучения сохраняет модель в файл, имя которого подается на вход, в данном случае pootS^d-f^. А параметр save_best_only=True позволяет после каждой эпохи проверять метрику качества, заданную в параметре poontor (в данном случае val-acc, то есть точность на валидационном множестве), и перезаписывать сохраняемую модель только в том случае, если эта метрика улучшилась. Обратите также внимание на параметр valldation_spllt: если у вас нет заранее выделенного тренировочного и. тестового
1 Для этой модели и датасета MNIST оверфиттинг вряд ли очень уж вероятен, но в целом. на практике часто бывает так, что лучшие значения метрик качества на валидационном множестве получаются где-то в начале процесса обучения, а потом, хотя ошибка на тренировочном множестве продолжает падать, ошибка на валидационном множестве только растет. В таких случаях и может пригодиться то, о чем мы сейчас говорим.
подмножеств (у нас они были сразу в датасете MNIST), то можно просто попросить Keras использовать для валидации случайное подмножество входных данных, составляющее заданную их долю, в данном случае 10 %.
5.4. Современные сверточные архитектуры
Когда читаешь газеты и журналы за последнее время, то иногда приходится с недоумением взглянуть на дату издания: не попался ли случайно в руки листок, писанный тому два, три века назад?
П. Л. Лавров. Хаос буржуазной цивилизации за последнее время
В этом разделе мы поговорим о том, как развиваются современные сверточные архитектуры и куда, вообще говоря, движется сейчас анализ изображений. Сначала давайте вернемся к глубоким архитектурам и, в частности, к сверткам с фильтрами размера 3x3. Одной из самых популярных глубоких сверточных архитектур является модель, которую принято называть VGG [507]. Название происходит от того, что эта модель была разработана в Оксфордском университете в Tpynrie визуальной геометрии (Visual Geometry Group), и их модели, представленные на ряд конкурсов по компьютерному зрению, выступали там под кодовым названием VGG. Соревнования проходили в 2014 году, что делает VGG самой «старой» из моделей, представленных в этом разделе.
VGG — это на самом деле сразу две конфигурации сверточных сетей, на 16 и 19 слоев. Основным нововведением, из-за которого мы и рассказываем о VGG, стала идея использовать фильтры размером 3 х 3 с единичным шагом свертки вместо использовавшихся в лучших моделях предыдущих лет сверток с фильтрами 7 х 7 с шагом 2 [407, 585] и 11 х 11с шагом 4 [284]. Причем это не просто утверждение из разряда «мы попробовали, и стало лучше», а хорошо аргументированное предложение; давайте попробуем разобраться в аргументах.
Во-первых, рецептивное поле трех подряд идущих сверточных слоев размером 3x3 имеет размер 7 х 7, в то время как весов у них будет всего 27, против 49 в фильтре 7 х 7. Аналогично обстоит дело и с фильтрами 11x11. Это значит, что VGG может стать более глубокой, то есть содержать больше слоев, при этом одновременно уменьшая общее число весов. Конечно, для того чтобы это было правдой, между соответствующими сверточными слоями не должно быть слоев субдискретизации.
Во-вторых, наличие дополнительной нелинейности между слоями позволяет увеличить «разрешающую способность» по сравнению с единственным слоем с большей сверткой. Этот же аргумент можно использовать как мотивацию для того, чтобы ввести в сеть свертки размером 1x1; такие слои тоже позволяют добавить дополнительную нелинейность в сеть, не меняя размер рецептивного поля.
| Рис. 5.6. Схема сети VGG-16
| |
Полученная в итоге модель в 2014 году одержала победу в одной из номинаций известного соревнования по компьютерному зрению, ImageNet Large Scale Visual Recognition Competition (ILSVRC) [244]. А популяризация сверточных слоев 3x3 привела, в частности, к тому, что NVIDIA в очередном релизе библиотеки cuDNN специально оптимизировала работу с такими свертками.
Схема одной из VGG-сетей показана на рис. 5.6. Обратите внимание на три вещи: во-первых, как по две-три свертки 3x3 следуют друг за другом без субдискретизации; во-вторых, как число карт признаков постепенно растет на более глубоких уровнях сети; в-третьих, как в конце полученные признаки окончательно «сплющиваются» в одномерный вектор и на нем работают последние, уже полносвязные слои. Все это стандартные методы создания архитектур глубоких сверточных сетей, и если вы будете разрабатывать свою архитектуру, вам наверняка стоит следовать этим общим принципам.
Кстати, веса уже готовых моделей, обученных на больших наборах данных, например ImageNet, можно найти в Интернете. В частности, с сайта авторов модели можно скачать веса и конфигурации моделей для популярной библиотеки для работы с нейронными сетями Caffe. Это общее место для многих современных моделей компьютерного зрения: дело в том, что даже с современными мощностями датасеты настолько большие, а обучение настолько долгое и сложное (например, в [507] сказано, что каждый вариант VGG в 2014 году обучали две-три недели на четырех лучших на тот момент видеокартах), что проще скачать готовые веса и, возможно, немного дообучить их для вашей конкретной задачи.
Следующая важная сверточная архитектура — это архитектура Inception [181]. Она была разработана в Google и появилась практически одновременно с VGG, в сентябре 2014 года; команда GoogLeNet победила с этой сетью в нескольких номинациях все того же конкурса ILSVRC-2014. Авторы архитектуры вдохновились идеями из работы 2012 года Network In Network [328], в которой была предложена идея использовать в качестве строительных блоков для глубоких сверточных сетей не просто последовательность «свертка — нелинейность — субдискретизация», как это обычно делается, а более сложные конструкции.
В [328] такими конструкциями были полноценные (но маленькие) нейронные сети с полносвязными слоями. А в Inception такой компонент «собирают» из небольших сверточных конструкций. Так что название сети отражает не только «глубину» из одноименного фильма, но и развитую там идею «вложенной» архитектуры: сон внутри сна внутри сна...
Эта работа содержит несколько крайне интересных и важных идей, благодаря которым, в частности, несмотря на большую заявленную глубину — 22 слоя без учета субдискретизации — у Inception на самом деле меньше параметров, чем у VGG!
Но давайте по порядку. «Строительными блоками» Inception являются модули, комбинирующие свертки размером 1x1, 3 х 3 и 5 х 5, а также max-pooling субдискретизацию. Каждый блок представляет собой объединение четырех «маленьких» сетей, выходы которых объединяются в выходные каналы и передаются на следующий слой. Выбор набора сверток и субдискретизации обусловлен скорее удобством, чем необходимостью, и при желании читатель может поэкспериментировать с другими конфигурациями. Команда GoogLeNet, разработавшая Inception, во второй версии своей модели тоже пересмотрела архитектуру этих модулей.
Одно из ключевых нововведений — использование сверточных слоев 1 х 1 не столько в качестве дополнительной нелинейности, сколько для понижения размерности между слоями. Свертки 3 х 3 и тем более 5x5 между слоями с большим числом каналов (а в Inception-модулях каналов может быть вплоть до 1024), оказываются крайне ресурсоемкими, несмотря на малые размеры отдельно взятых фильтров. А фильтры 1x1 могут помочь сократить число каналов, прежде чем подавать их на фильтры большего размера.
Эта идея отражена на рис. 5.7, а, на котором показана структура одного блока из исходной работы [181]. А на рис. 5.7, б представлена очень общая и высокоуровневая схема всей сети: она начинается с двух «обычных» сверточных слоев, а затем идут 11 Inoeptюn-модулей, дважды перемежаемых субдискретизацией, которая понижает размерность; после этого сеть завершается традиционными полносвязными слоями, дающими уже собственно выход классификатора.
Помимо конфигурации Inoeptюn-модyлей и понижения размерности с помощью сверток 1 х 1, в работе [181] представлена еще одна важная идея. С учетом достаточно глубокой архитектуры сети — а в общей сложности GoogLeNet содержит порядка 100 различных слоев с общей глубиной в 22 параметризованных слоя, или 27 слоев с учетом субдискретизаций — эффективное распространение градиентов по ней вызывает сомнения. Чтобы решить эту проблему, авторы предложили добавить вспомогательные классифицирующие сети поверх некоторых промежуточных слоев.
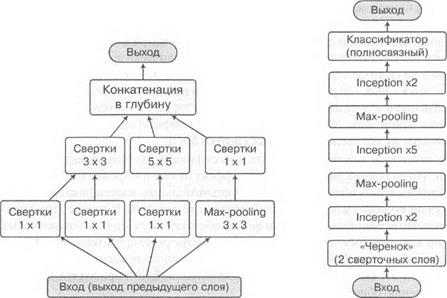
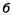
Рис. 5.7. Inception: а — схема одного Inception-модуля; б — общая схема сети GoogLeNet
Иначе говоря, мы добавляем две новые небольшие полносвязные сети, делающие предсказания на основе промежуточных признаков, выводим из них ту же функцию ошибки классификации и обучаем на той же задаче не только всю сеть, но и отдельно первую ее часть, а также первую и вторую. В архитектуре [181] присутствуют две такие дополнительные сети, состоящие из субдискретизации усреднением, свертки 1x1, полносвязного слоя, дропаута и линейного слоя с softmax в качестве функции ошибки классификатора. При обучении модели ошибка от этих подсетей добавляется к общей функции ошибки с понижающим коэффициентом 0,3. Потенциально этот трюк должен был ускорить обучение нижних слоев на ранних этапах обучения и привести к более быстрой сходимости, а в итоге оказалось, что сходимость не сильно ускорилась, но зато улучшилось окончательное решение.
Кстати, о следующей версии. Через год с небольшим практически та же команда авторов опубликовала следующую работу [448]. В ней в общую структуру Inception-модулей внесли новое важное изменение: заменили практически все «большие» свертки на композиции сверток размерности 3 х 3 и 1 х п. Выше мы уже обсуждали в контексте VGG, что свертку размера 5x5 можно заменить двумя последовательными сверточными слоями, каждый размера 3x3, при этом не потеряв в выразительной силе и сократив общее число весов. Однако авторы второй версии Inception пошли дальше и предложили заменить свертки произвольного размера п х п на два последовательных слоя размером п х 1 и 1 х п. Идейно (но не формально!) это соответствует сингулярному разложению матрицы весов свертки, то есть разложению в произведение двух прямоугольных матриц. Такой подход существенно сокращает вычислительную сложность модели даже по сравнению с факторизацией на свертки 3x3. Экспериментируя с такими слоями, авторы пришли к выводу, что в слоях, где размер карты признаков находится в пределах от 12 х 12 до 20 х 20 нейронов, декомпозиция в пары сверток 7 х 1 и 1 х 7 показывает хорошие результаты. Кроме того, свертка 5 х 5 из базовой конфигурации Inception-модуля была заменена на две последовательные свертки 3x3.
Были новости и о вспомогательных классификаторах. Новые эксперименты показали, что на ранних эпохах обучения эффект от них по-прежнему не заметен, однако ближе к концу обучения модель с дополнительным классификатором обучается лучше, попадает в более хороший локальный оптимум. В связи с этим представляется,. что вспомогательные сети не способствуют обучению низкоуровневых признаков как таковому, а скорее служат в качестве регуляризатора сети. Кроме того, во второй версии Inception выяснилось, что дополнительные слои нормализации по мини-батчам или дропаута во вспомогательной сети приводят к дальнейшему улучшению общего решения.
Можно сказать, что с сети VGG началась эпоха «по-настоящему глубокого» обучения. Наконец-то специалисты по машинному обучению смогли эффективно обучать модели глубже, чем «несколько слоев», и показывать результаты, сравнимые или существенно лучшие, чем на тех же датасетах способен показать человек. Так, например, задачу классификации изображений на датасете CIFAR-10 современные нейронные сети решают с точностью около 96.5 %, в то время как точность человеческих результатов составляет около 94 % [37, 272]. Однако для того, чтобы обучать еще более глубокие нейронные сети, потребовалось не только собрать воедино все идеи из главы 4 и этой главы, но и добавить еще один важный трюк.
После того как группа Хинтона нашла способ предобучать слой за слоем нейронные сети любой глубины, Ян ЛеКун [135] и Йошуа Бенджи совместно с Хавьером Глоро [179] предложили эффективные методы инициализации весов, а Иоффе и Сегеди добавили промежуточные слои, нормализующие выходы по мини- батчам [252], проблема затухающих градиентов, которая долгое время преследовала нейронные сети, наконец-то отошла на второй план.
Как показала практика, глубокие архитектуры стало возможно обучать эффективно, однако те решения, к которым сходились нейронные сети большой глубины, часто оказывались хуже, чем у менее глубоких моделей. И эта «деградация» не была связана с переобучением, как можно было бы предположить. Оказалось, что это более фундаментальная проблема: с добавлением новых слоев ошибка растет не только на тестовом, но и на тренировочном множестве. Хотя, казалось бы, более «мелкая» сеть — это частный случай более глубокой: мы ведь могли бы обучить менее глубокую сеть, а затем ее веса использовать для инициализации более глубокой; дополнительные слои при этом можно просто инициализировать так, чтобы

Рис. 5.8. Блоки сетей для остаточного обучения: а — базовый блок; б — такой же блок
с остаточной связью; в — простой блок с остаточной связью; г — блок с остаточной связью,
контролирующийся гейтом; д — блок с остаточной связью исходной сети ResNet [111];
е — более поздняя модификация [242]
они копировали вход в выход. Тогда ошибка более глубокой сети по определению не будет выше, чем ошибка ее подсети, а после обучения мы ожидаем улучшения. Но эксперименты показывают, что этого не происходит: более сложные модели сложнее обучать, и даже к такому тривиальному для нас решению современные методы обучения за разумное время не приводят.
Для решения проблемы деградации команда из Microsoft Research разработала новую идею: глубокое остаточное обучение (deep residual learning), которое легло в основу сети ResNet [111], а также многих последующих работ. В базовой структуре новой модели нет ничего нового: это слои, идущие последовательно друг за другом. Отдельные уровни, составные блоки сети тоже выглядят достаточно стандартно, это просто сверточные слои, обычно с дополнительной нормализацией по мини-батчам. Разница в том, что в остаточном блоке слой из нейронов можно «обойти»: есть специальная связь между выходом предыдущего слоя х W и следующего слоя х(К+!\ которая идет напрямую, не через вычисляющий что-то слой.
Базовый слой нейронной сети на рис. 5.8, а превращается в остаточный блок с обходным путем на рис. 5.8, б. Математически происходит очень простая вещь: когда два пути, «сложный» и «обходной», сливаются обратно, их результаты просто складываются друг с другом. И остаточный блок выражает такую функцию: где so _ — входной вектор слоя к, F(x) — функция, которую вычисляет слой нейронов, а у№ — выход остаточного блока, который потом станет входом следующего слоя
Получается, что если блок в целом должен апроксимировать функцию Н(х), то это достигается тогда, когда F(x) аппроксимирует остаток (residue) Н(х) - х, отсюда и название остаточные сети (residual networks). В остаточном блоке мы обучаем слой нейронов воспроизводить изменения входных значений, необходимые для получения итоговой функции.
Что в этом хорошего? Во-первых, часто получается, что обучить «остаточную» функцию проще, чем исходную; в [111] авторы приводят в пример тождественную функцию h(x) — х. Оказывается, что с помощью двухслойной нелинейной нейронной сети выучить тождественную функцию достаточно сложно; в то же время в остаточной форме от сети требуется просто заполнить все веса нулями, а «обходной путь» сделает всю работу сам.
Главная же причина состоит в том, что градиент во время обратного распространения может проходить через этот блок беспрепятственно, градиенты не будут затухать, ведь всегда есть возможность пропустить градиент напрямую:
ду№ _ dF(xWi)
дх(к) дхДХ
Это значит, что даже насыщенный и полностью обученный слой F, производные которого близки к нулю, не помешает обучению.
Примеры таких «обходных путей», которые использовались в разных вариантах сети ResNet и других исследованиях этой группы авторов, показаны на рис. 5.8. В работе [242] проводится подробное сравнение нескольких вариантов остаточных блоков. Результаты оказались любопытными: остаточные блоки, которые теоретически должны быть более выразительными, на практике оказываются хуже, чем самые простые варианты.
Для примера мы изобразили на рис. 5.8, в очень простой вариант остаточного блока, в котором у_ = + F(x®__ а на рис. 5.8, г — вариант посложнее:
y(f) = (l ®(*> +
где / — другая функция входа, реализованная через свертки 1x1. Это значит, что F(xW суммируются не с равными весами, а с весами, управляемыми допол
нительным «гейтом»[LX]. Казалось бы, простой вариант является частным случаем сложного: достаточно просто обучить гейты так, чтобы веса были равными, то есть чтобы всегда выполнялось f(x^k) = 0. Однако эксперименты в [242] показали, что простота в данном случае важнее выразительности и важно обеспечить максимально свободное и беспрепятственное течение градиентов. На рис. 5.8, д показан вариант остаточного блока, который использовался в исходной статье [111], а на рис. 5.8, е — улучшенный вариант из [242]. Обратите внимание, что разница, по сути, только в том, что из «обходного пути» убрали ReLU-нелинейность, последнее «препятствие» на пути значений с предыдущего слоя.
Архитектурно все это приводит к тому, что становится возможным обучать очень, очень глубокие сети. Каймин Хе называет это «революцией глубины»: в VSS было 19 уровней, в GoogLeNet — 22 уровня, в первом варианте ResNet — сразу 152, а в последних версиях сетей с остаточными связями без проблем обучаются сети до тысячи уровней в глубину!
Это, безусловно, самые глубокие из реально используемых нейронных сетей. И они действительно работают: большинство лучших результатов в современных нейронных сетях используют в качестве распознавателя объектов разные варианты ResNet. Если вам нужно что-то распознавать на картинках, скорее всего, вы будете пользоваться одной из этих архитектур.
Правда, в некоторых приложениях от них отказываются ради скорости и экономии ресурсов: большая сверточная сеть с остаточными связями никак не поместится в смартфон. Если ресурсы важны, стоит посмотреть в сторону моделей, которые показывают немного более слабые результаты в собственно распознавании, но имеют при этом на порядок меньше весов; выделим, в частности, MobileNets [371] и SqueezeNet [504].
Впрочем, в заключение этого раздела отметим, что идея ■ про гейт, управляющий остаточными блоками, как на рис. 5.8, г, все-таки оказалась довольно плодотворной. Именно она легла в основу так называемых магистральных сетей (highway networks)^ предложенных группой Юргена Шмидхубера [506].
Идея магистральных сетей именно такая, как мы показывали выше: мы представляем у(к\ выход слоя fc как линейную комбинацию входа этого слоя х^ и результата F(x №) веса которой управляются другими преобразованиями:
у(*) = C(xW)xW +T(xW)F(xW)),
где С — это гейт переноса (carry gate), а Т — гейт преобразования (transform gate); обычно комбинацию делают выпуклой, С = 1 - Т. Магистральные сети тоже позволили обучать очень глубокие сети с сотнями уровней [507], а затем эта конструкция была адаптирована для рекуррентных сетей [440].
Что здесь победит — простота или выразительность — вопрос пока открытый, но в любом случае варианты этих архитектур уже позволили сделать беспрецедентно глубокие сети, и останавливаться на достигнутом исследователи не собираются. А мы на этом завершаем краткий обзор современных сверточных архитектур. Пора двигаться дальше, к другой постановке задачи обучения — автокодировщикам.
5.5. Автокодировщики
А спросите, для чего я так сам себя коверкал и мучил? Ответ: затем, что скучно уж очень быию сложа руки сидеть; вот и пускался на выверты.
Ф. М. Достоевский. Записки из подполья В этом разделе мы познакомимся с одной из традиционные архитектур нейронных сетей, которая очень хорошо себя зарекомендовала в задачах извлечения признаков, когда нужно из сложных данных большой размерности выделить признаки, имеющие какой-то смысл с точки зрения того, что эти данные вообще собой представляют. Иными словами, мы будем решать задачу обучения без учителя: как извлечь из большого количества данных смысл, как найти закономерности, которые управляют этими данными, как понять, что в них общего, что они означают и как использовать их дальше?
Как и у многих других архитектур нейронных сетей, у автоксдаровщиков долгая и славная история. Впервые модель аатокодироащака была представлена еще в 1986 году в классической работе Дэвида Румельхарта[LXI], Джеффри Хинтона и Рональда Уильямса, Learning internal representations by error propagation [459, 460]; с тех пор появилась масса различных вариантов автокодировщиков, но основная идея остается той же самой, и автокодировщики в целом только набирают популярность благодаря своей простоте и гибкости.
Итак, предположим, что у нас есть некий набор данных, который мы хотели бы описать с помощью новых «умных» признаков, которые были бы лучше и «интереснее» (о том, что это такое, мы поговорим ниже), чем исходное описание. Например, мы бы хотели описать рукописные цифры не пиксел за пикселом, а с помощью каких-то признаков, из которых было бы достаточно просто выяснить, какая цифра написана, или чьим почерком, или каким цветом... в общем, признаков, которые были бы более информативными. Это выглядит как задача обучения без учителя, которую трудно решать нейрон^ши сетями: непонятно, как определить функцию ошибки для задачи «найти интересные признаки».
Основная идея автокодировщиков столь же проста, сколь и гениальна: давайте превратим задачу обучения без учителя в задачу обучения с учителем, сами себе придумаем тестовые примеры с известными правильными ответами. И сделаем мы это так: попросим модель обучиться выдавать на выходе ровно тот же пример, который подавали ей на вход! При этом она будет обучаться сначала создавать некое внутреннее представление, кодировать вход какими-то признаками, а потом декодировать их обратно, чтобы восстановить исходный вектор входов. Мы изобразили
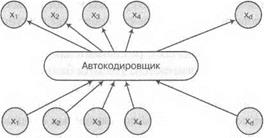
Рис. 5.9. Как работает автокодировщик
общую схему автокодировщика на рис. 5.9. Говоря чуть более формально, мы хотим обучить функцию /(ж; в) « ж, где в — это, как обычно, параметры нейронной сети.
Конечно, въедливый читатель спросит: в чем тут, собственно, проблема? Тоже мне бином Ньютона — скопировать вход в выход, для этого никакая оптимизация. не нужна, вполне достаточно взять сеть с единичными матрицами весов, скопировать вход на скрытый слой, а потом скопировать скрытый слой на выход. И это действительно так: если не накладывать дополнительных ограничений на представление, которое должно получиться на скрытом слое, ничего умного не получится, и сеть будет обучаться просто копировать вход в выход. Искусство построения автокодировщиков, и в целом практически все содержание этой главы, состоит в том, чтобы придумать, какие ограничения и каким образом наложить на нейронную сеть, чтобы получающиеся на скрытых слоях признаки действительно оказались «интересными».
В классическом автокодировщике, который и предлагался в исходных работах [459,460], дополнительное ограничение очень простое: чтобы на скрытом слое нельзя было просто скопировать вход, давайте уменьшим его размерность по сравнению с размерностью входа. Например, в разделе 3.6 мы кодировали рукописные цифры из датасета MNIST, которые представляют собой картинки размера 28 х 28 пикселов, в виде вектора длиной 784, по отдельной размерности для каждого пиксела. А теперь мы можем попробовать построить автокодировщик, у которого на скрытом слое будет, скажем, сто нейронов, попросив тем самым сеть представить каждую цифру из картинки 28 х 28 пикселов в виде вектора размерности 100.
Здесь, правда, возникает противоположный вопрос: почему это вообще может работать? Ведь отображение пространства большой размерности RD в пространство меньшей размерности Rd, d < D, не может быть взаимно однозначным, то есть мы всегда будем терять какую-то информацию; как же мы тогда будем восстанавливать исходные векторы ж е R D?
И действительно, если бы нам нужно было научить модель отображать все возможные картинки размера 28 х 28 пикселов в пространство М100, это была бы невозможная задача: случайный вектор из пространства R784 содержит гораздо больше информации, чем вектор из R100, и по сути мы не могли бы сделать ничего лучше, чем просто скопировать какие-нибудь сто координат исходного вектора, а остальные выбрать случайно.
К счастью, в реальных задачах с реальными данными кодировать случайные векторы не надо. Обычно оказывается, что хотя базовое пространство, в котором представлены данные, и имеет большую размерность, сами данные в нем лежат неподалеку от многообразия гораздо меньшей размерности. Нам вовсе не нужно кодировать любой белый шум из случайно зажженных 784 пикселов; нам нужно кодировать некие «осмысленные» изображения, которые обладают множеством очевидных для человека свойств: они выражают одну из десяти цифр, имеют определенную толщину линии, наклон, представляют собой обычно неразрывные, связные объекты или состоят из немногих штрихов. Все это очень сильно сужает множество возможных изображений цифр и позволяет надеяться на то, что существует представление рукописных цифр в пространстве меньшей размерности.
При таком подходе получается, что автокодировщик фактически решает задачу понижения размерности (dimensionality reduction): как отобразить большое пространство со сложными взаимосвязями в пространство более низкой размерности, где, будем надеяться, сложные взаимосвязи перейдут в зависимости попроще. Есть множество классических методов понижения размерности: анализ главных компонент[LXII] (principal component analysis, РСЛ) [1], сингулярное разложение матриц (singular value decomposition, SVD) [30], анализ независимых компонент (independent component analysis, ICA) [241] и многие другие.
Важное отличие того, что мы делаем сейчас, от классических методов понижения размерности в том, что нейронные сети могут выразить больше разных сложных многообразий, им не нужны настолько сильные предположения о структуре данных, как классическим моделям. Гибкость моделей, задаваемых нейронными сетями, часто позволяет выделить очень «интересные» признаки, и хотя модели становятся более сложными и хрупкими, очевидно, что именно это и требуется в реальной жизни: попробуйте-ка представить себе, как выглядит «многообразие рукописных цифр» в пространстве R784 или многообразие осмысленных текстов на русском языке в пространстве последовательностей букв...
На практике автокодировщики чаще используют для извлечения таких признаков из данных, которые в итоге позволяют уменьшить ошибку при последующем обучении с учителем. И оказывается, что в этом случае автокодировщики, в скрытом слое которых нейронов больше, чем во входном (их называют overcomplete autoencoders, а реально понижающие размерность — undercomplete), зачастую оказываются крайне полезными.
Кажется, что при такой архитектуре нейронной сети достаточно скопировать вход на произвольное подмножество нейронов скрытого слоя, а затем на выходные нейроны, но нелинейная функция активации и регуляризация делают это практически невозможным. Например, редкий автокодировщик в наше время обходится без дропаута, но дропаут сильно мешает идее простого копирования; приходится все-таки «честно» выделять признаки.
Конечно, автокодировщики за двадцать лет своего существования получили сразу несколько серьезных «апгрейдов». «Обычные» автокодировщики, которые мы рассматривали выше, пытаются восстановить вход по нему же самому, то есть пытаются обучить тождественную функцию /(ж) = х либо с помощью средств, недостаточных, чтобы это выразить, либо с дополнитель^ши ограничениями и целями, которые мешают просто взять и скопировать вход в выход. Тем не менее, по мере того как размерность скрытых слоев и выразительность модели будут расти — а мы ведь хотим, чтобы они росли, — мы будем все точнее восстанавливать вход по нему же самому, и справляться с потенциальным оверфиттингом будет все сложнее и сложнее.
Шумоподавляющий автокодировщик (demising auabencbeer) — это оригинальный и очень простой способ почти полностью избавиться от проблем оверфиттиа- га. Давайте будем восстанавливать не вход х по нему самому, а вход х по некоторому его зашумленному варианту ж. Например, давайте выберем 10% пикселов изображения и заменим их нулями (черными пикселами) или случайными значениями интенсивностей, но восстановить при этом попросим не искаженный вариант картинки, а исходный, в котором все пикселы стоят на своих местах. Таким образом, автокодировщик должен будет не просто сжать полученный пример, но еще и частично восстановить утраченные в процессе зашумления данные, обучить не тождественную функцию /(ж; в) — х, как мы делали в этой главе раньше, а довольно сложную функцию /(ж; в) = ж, которая уже неизбежно будет описывать многие интересные свойства поступающих на вход данных.
Кроме этого непосредственного преимущества появляются и другие. Во- первых, обратите внимание, что такой подход позволяет существенно увеличить объем обучающей выборки фактически бесплатно: мы ведь можем зашумлять один и тот же пример х по-разному, получая из него сразу много новых тренировочных примеров х\х 2,... ,хк с одним и тем же «правильным ответом» ж. Это, конечно, нельзя делать бесконечно: набор базовых тренировочных векторов все-таки не увеличивается, и если переборщить с генерацией их случайно зашумленных вариантов, получится тот же оверфиттааг; но в два-три раза датасет на практике обычно можно таким образом «увеличить». С другой стороны, зашумленность как регу- ляризатор заставляет автокодировщик пытаться выучивать независимые друг от друга признаки, ведь когда случайный шум ляжет по-другому, некоторых локальных признаков уже не будет, и придется по оставшимся восстанавливать утраченные.
Но пока это все были абстрактные рассуждения; как вносить случайный шум на практике? В реальных шупомодавляющих автокодировщиках почти всегда применяют один из двух способов зашумления входного сигнала:
• первый способ — это добавление ко входу случайного нормально распределенного шума с маленькой дисперсией, которая в данном случае и определяет уровень шум а; такой подход хорошо работает для некоторых типов данных, но относительно редко применяется в обработке изображений, так что сейчас мы не будем подробно на нем останавливаться и оставим читателю простор для экспериментов;
• второй способ зашумления заключается в том, что часть входных нейронов попросту обнуляется; уровень шума здесь определяется тем, какая именно это часть.
Во втором способе, самом популярном в задачах обработки изображений, нейронная сеть, прогоняя очередной зашумленны<