Вернемся к данным выборов и сравним электоральную последовательность, которую мы создали ранее, относительно теоретической нормальной ИФР. Для создания нормальной ИФР из последовательности значений можно воспользоваться функциейsp.random.normalбиблиотеки SciPy, как уже было показано выше. Среднее значение и стандартное отклонение по умолчанию равны соответственно 0 и1, поэтому нам нужно предоставить измеренные среднеезначениеи стандартное отклонение, взятыеиз электоральных данных. Эти значения для наших электоральных данныхсоставляют соответственно 70150 и 7679.
Ранее в этой главе мы уже генерировали эмпирическую ИФР. Следующий ниже пример простосгенерирует обе ИФР и выведет их на одном двумерном графике:
defex_1_24():
'''Показать эмпирическую и подогнанную ИФР
электората Великобритании'''
emp = load_uk_scrubbed()['Electorate']
fitted = stats.norm.rvs(emp.mean(), emp.std(ddof=0), len(emp))
df =empirical_cdf(emp)
df2 = empirical_cdf(fitted)
ax =df.plot(0, 1, label='эмпирическая')
df2.plot(0, 1, label='подогнанная', grid=True, ax=ax)
plt.xlabel('Электорат')
plt.ylabel('Вероятность')
plt.legend(loc='best')
plt.show()
Приведенный выше пример создаст следующий график:

Несмотря на наличие незначительной асимметрии, близкая расположенность двух кривых друг к другу говорит о нормальностиисходных данных. Асимметрия выражена в противоположном направлении относительнопостроенной ранее кривой ИФР нечестного булочника, то есть наши данные об электорате слегка смещены влево.
Поскольку мы сравниваем наше распределение с теоретическим нормальным распределением, то можно воспользоватьсяквантильным графиком, которыйделает это по умолчанию:
defex_1_25():
'''Показать квантильный график
электората Великобритании'''
qqplot(load_uk_scrubbed()['Electorate'])
plt.show()
Следующий нижеквантильный график еще лучше показывает левую асимметрию, с очевидностью присутствующую в данных:
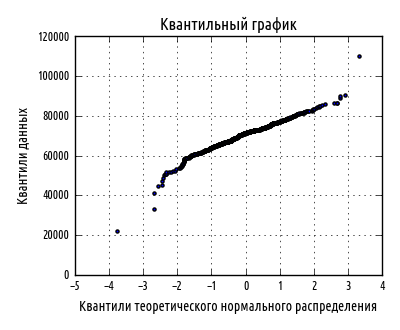
Как мы и ожидали, кривая изгибается в противоположном направлении по отношению к построенному ранее в этой главе квантильному графику нечестного булочника. Это свидетельствует о том, что числоболее мелких избирательных округов на самом деле больше, чем можно было бы ожидать, если бы данные были более тесно нормально распределены.
Обработка столбцов
До этого в этой главе мы уменьшили размер наших данных при помощи фильтрации строк и столбцов. Нередко напротив требуется добавить строки в набор данных. Библиотека Pandas обеспечивает эту функциональность несколькими способами.
Во-первых, мы можем заменить существующий столбец в наборе данных либо добавить еще один столбец. Во-вторых, мы можем передать в столбцы новые значениядлянепосредственной замены существующих, либо вычислить новые значения, применив функции к каждой строке данных.
В следующем примере приведены варианты действий, которые будут использоваться в дальнешем. Для иллюстрации сгенерируем синтетическую таблицу данных в форме 3 x 2:
'''Операции над столбцами таблицы данных'''
# сгенерировать синтетическую таблицу данных
sp.random.seed(0)
df = pd.DataFrame(sp.random.randn(3, 2), columns=['A', 'B'])
| | A
| B
|
|
| 1.764052
| 0.400157
|
|
| 0.978738
| 2.240893
|
|
| 1.867558
| -0.977278
|
# заменить все значения в столбценовым значением
df['A'] = 1
| | A
| B
|
|
|
| 0.400157
|
|
|
| 2.240893
|
|
|
| -0.977278
|
# заменить все значения в столбце новой последовательностью
df['A'] = pd.Series(sp.random.randn(5))
| | A
| B
|
|
| 0.950088
| 0.400157
|
|
| -0.151357
| 2.240893
|
|
| -0.103219
| -0.977278
|
# заменить все значения в столбце, применив функцию
df['A']=df.apply(lambda x: max(x['A'], x['B']), axis=1)
| | A
| B
|
|
| 0.950088
| 0.400157
|
|
| 2.240893
| 2.240893
|
|
| -0.103219
| -0.977278
|
# заменить значение в заданной позиции столбца
df['A'][2] = 1
| | A
| B
|
|
| 0.950088
| 0.400157
|
|
| 2.240893
| 2.240893
|
|
| 1.000000
| -0.977278
|
# добавить производный столбец на основе существующих
df['C'] = df['A'] + df['B']
| | A
| B
| C
|
|
| 0.950088
| 0.400157
| 1.350246
|
|
| 2.240893
| 2.240893
| 4.481786
|
|
| 1.000000
| -0.977278
| 0.022722
|
# добавить производный столбец, применив функцию
df['D']=df.apply(lambda x: min(x['A'], x['B']), axis=1)
| | A
| B
| C
| D
|
|
| 0.950088
| 0.400157
| 1.350246
| 0.400157
|
|
| 2.240893
| 2.240893
| 4.481786
| 2.240893
|
|
| 1.000000
| -0.977278
| 0.022722
| -0.977278
|
Именованный аргумент axis=1назначает для выполняемых операций вертикальную ось, т.е. они применяются к столбцу.
Далее мы покажем, как добавлять производный столбец на реальном примере. В 2010 г.всеобщие выборы в Великобритании привели к "подвисшему" парламенту, в котором ни одна из партий не получила абсолютного большинства. В результате была образована коалиция между Консервативной и Либерально-демократической партиями. В следующем разделе мы узнаем, сколько людей проголосовало за обе партии, и какой процент от проголосовавших они составили.





