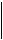Для спецификации концептуальной модели СУБД предоставляет язык определения данных (ЯОД), являющийся языком высокого уровня и позволяющий описывать концептуальную схему в терминах конкретной логической модели данных, которые используются в системах БД: реляционная, сетевая и иерархическая. Рассмотрим свойства этих моделей на примере БД “Футбол”. На рис.16. представлена диаграмма объектов - связей данной БД, где прямоугольники представляют наборы объектов, овалы - атрибуты, а ромбы - связи.
Место Дата
рождения рождения
Игры Сезон
Название место значение
позиции позиции оценки
Рис.16
РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
В основе реляционной модели лежит математическое понятие теоретико-множественного отношения, которое представляет собой подмножество декартова произведения списка доменов.
Домен -множество значений (например, множество целых чисел). Декартовым произведением доменов D1, D2,...,Dk (обозначается как D1*D2*...*Dk) называется множество всех кортежей (V1, V2,...,Vk) длины k, таких, что V1 принадлежит D1, V2 принадлежит D2 и т.д.
Например, если k=2, D1={0,1} и D2={a,b,c}, то D1*D2 есть{(0,a), (0,b), (0,c), (1,a), (1,b),(1,c)}. Отношением называется некоторое подмножество декартова произведения одного или более доменов. Например, {(0,a), (0,c), (1,b)} есть отношение, подмножество определенного выше D1*D2.
Элементы отношения называются кортежами. О каждом отношении, являющемся подмножеством декартова произведения D1*D2*...*Dk, говорят, что оно имеет арность k. Кортеж (V1,V2,...,Vk) имеет k компонентов, причем i-м компонентом является Vi. Отношение удобно представлять таблицей, где каждая строка есть кортеж и каждый столбец соответствует одному компоненту. Столбцы называются атрибутами, и им часто присваиваются имена. Список имен атрибутов отношения называется схемой отношения. Если отношение называется ИГРОКИ и его схема имеет атрибуты A1,A2,...,Ak, то такую схему будем записывать как ИГРОКИ (A1,A2,...,Ak).
Совокупность схем отношений называется схемой (реляционной) БД, а текущие значения соответствующих отношений - (реляционной) БД. Данные из диаграммы объектов-связей представляются двумя видами отношений:
Набор объектов может быть представлен отношением, содержащим все атрибуты данного набора объектов. Если объекты набораидентифицируются с помощью связи с другим объектом, то схема отношения содержит дополнительно атрибуты ключа второго набора.
Связь между наборами объектов E1,E2,...,Ek представляетсяотношением, схема которого состоит из атрибутов ключей каждого из этих наборов.
В качестве примера представим БД “Футбол” в виде реляционной модели (рис.17). Выберем схемы отношений, которые будут представлять наборы объектов и связи. Отношения для наборов объектов имеют следующий вид:
ИГРОКИ (ИМЯ, МЕСТО РОЖДЕНИЯ, ДАТА РОЖДЕНИЯ)
КОМАНДЫ (СПОРТКЛУБ, ГОРОД, ГОД)
ПОЗИЦИИ (НАЗВАНИЕ ПОЗИЦИИ, НОМЕР ПОЗИЦИИ)
Однокомпонентное (ударное) отношение СРЕДНЯЯ ОЦЕНКА не рассматривается, так как является просто множеством всех средних оценок.
Отношения для связей между объектами содержат ключевые атрибуты:
ИГРЫ (ИМЯ, НАЗВАНИЕ ПОЗИЦИИ)
СЕЗОН (ИМЯ, СПОРТКЛУБ, ГОД, ЗНАЧЕНИЕ ОЦЕНКИ)
Отношение ИГРОКИ
| Имя
| Место рождения
| Дата рождения
|
| Иванов Владимир Петрович
| Остров, Псковская область
| 18.1.1955
|
| Смирнов Виктор Павлович
| Валдай, Новгородская область
| 12.01.1957
|
| Тимофеев Юрий Иванович
| Рудня, Смоленская область
| 12.06.1960
|
| ...
| ...
| ...
|
Отношение КОМАНДЫ
| Спортклуб
| Город
| Год
|
| Звезда
| Каменск
|
|
| Торпедо
| Новогорск
|
|
| Трактор
| Холмск
|
|
| ...
| ...
| ...
|
Отношение ПОЗИЦИИ
| Название позиции
| Номер позиции
|
| Вратарь
|
|
| Правый защитник
|
|
| Центральный защитник
|
|
| ...
| ...
|
Отношение ИГРЫ
| Имя
| Название позиции
|
| Петров Сергей Юрьевич
| Центральный нападающий
|
| Смирнов Виктор Павлович
| Правый полузащитник
|
| Смирнов Виктор Павлович
| Правый защитник
|
| ...
| ...
|
Отношение СЕЗОН
| Имя
| Спортклуб
| Год
| Значение оценки
|
| Иванов Владимир Петрович
| Сокол
|
| 3,83
|
| Петров Сергей Юрьевич
| Торпедо
|
| 4,12
|
| Смирнов Виктор павлович
| Трактор
|
| 4,27
|
| Тимофеев Юрий Иванович
| Звезда
|
| 3,67
|
| ...
| ...
| ...
| ...
|
Рис.17
Основная задача при проектировании реляционных БД -формирование оптимальных отношений. Рассмотрим недостатки, присущие отношениям на примере БД объединения кооперативов. Возьмем отношение ПОСТАВЩИКИ (НАЗВАНИЕ ПОСТАВЩИКА, АДРЕС ПОСТАВЩИКА, ТОВАР, ЦЕНА). В связи с этой схемой возникают следующие проблемы:
Избыточность. Адрес поставщика повторяется для каждого повторяемого товара.
Потенциальная противоречивость (аномалия обновления). Вследствие избыточности можно обновить адрес поставщика в одном кортеже, оставив его неизменным в другом. При этом может оказаться, что для некоторых поставщиков нет единого адреса.
Аномалия удаления. При необходимости удаления всех товаров, поставляемых данным поставщиком, непреднамеренно можно утратить его адрес.
Аномалия включения. В БД может быть записан адрес поставщика, который в настоящее время не поставляет товар, можно поместить неопределенные значения компонент ТОВАР И ЦЕНА. Но если он начнет поставлять некоторый товар, можно забыть удалить кортеж с неопределенными значениями. ТОВАР и НАЗВАНИЕ ТОВАРА образуют ключ данного отношения, а поиск кортежей с неопределенными значениями может быть затруднен или невозможен.
Перечисленные проблемы исчезают, если заменить данное отношение двумя схемами отношений: ПА (НАЗВАНИЕ ПОСТАВЩИКА, АДРЕС ПОСТАВЩИКА) ПТЦ (НАЗВАНИЕ ПОСТАВЩИКА, ТОВАР, ЦЕНА).
Однако и в этом случае остаются некоторые недостатки. Например, в случае единственного отношения проще выполнить селекцию и проекцию.
Для формализации процесса построения оптимальной реляционной БД используется теория нормализации, основанная на том, что определенный набор отношений обладает лучшими свойствами при включении, модификации и удалении данных, чем все остальные наборы отношений, с помощью которых могут быть представлены те же данные.
Нормализация осуществляется последовательно с использованием пяти нормальных форм.
Ниже мы рассмотрим формы от первой до пятой, включая нормальную форму Бойса-Кодда. Для обозначения нормальных форм используются сокращения 1НФ, 2НФ, 3НФ, НФБК, 4НФ, 5НФ. Первая (1НФ), вторая (2НФ) и третья (3НФ) нормальные формы ограничивают зависимость непервичных атрибутов от ключей. Нормальная форма Бойса-Кодда (НФБК) ограничивает также зависимость первичных атрибутов. Четвертая нормальная форма (4НФ) формулирует ограничения на виды многозначных зависимостей, обсуждаемых ниже. Пятая нормальная форма (5НФ) вводит другие типы зависимостей, называемых зависимостями соединения.
Уровень нормализации отношения зависит от его семантики и не может быть однозначно определен из данных, содержащихся в текущий момент в базе данных. Это означает, что семантика должна быть задана с помощью функциональных зависимостей.
Первая нормальная форма (1НФ). Отношение находится в первой нормальной форме, если значения всех его атрибутов простые (атомарные), т.е. значение атрибута не должно быть множеством или повторяющейся группой. Ненормализованному отношению соответствует многоуровневая таблица (иерархия) в отличие от однородной табличной структуры нормализованного отношения.
Пример:
РЕЙСЫ (НОМЕР, ПУНКТ_ОТПРАВЛЕНИЯ, ПУНКТ_НАЗНАЧЕНИЯ, РАСПИСАНИЕ)
РАСПИСАНИЕ (ДЕНЬ, ВРЕМЯ_ВЫЛЕТА)
Пусть имеются следующие данные о рейсах:
TW 101 Чикаго Финикс пон 9.40
вт 9.40
пят 10.30
TW 800 Финикс Нью-Йорк пон 7.30
чет 7.30
пят 7.30
Для преобразования этого ненормализованного отношения в 1НФ необходимо в составном отношении РЕЙСЫ заменить отношение РАСПИСАНИЕ соответствующими атрибутами:
РЕЙС(НОМЕР,ПУНКТ_ОТПРАВЛЕНИЯ,ПУНКТ_НАЗНАЧЕНИЯ, ДЕНЬ, ВРЕМЯ_ВЫЛЕТА)
TW101 Чикаго Финикс пон 9.40
TW101 Чикаго Финикс вт 9.40
TW101 Чикаго Финикс пят 10.30
TW800 Финикс Нью-Йорк пон 7.30
TW800 Финикс Нью-Йорк чет 7.30
TW800 Финикс Нью-Йорк пят 7.30
Вторая нормальная форма (2НФ). Пусть имеется отношение ПОСТАВКИ, содержащие данные о поставщиках (идентифицируемых номером П#), поставляемых ими товарах и их ценах:
ПОСТАВКИ (П#, ТОВАР, ЦЕНА) Предположим, что поставщик может поставлять различные товары, а один и тот же товар могут поставлять разные поставщики. Таким образом, ключ отношения (выделенный полужирным шрифтом) будет состоять из атрибутов П# и ТОВАР. Известно, что цена любого товара зафиксирована (т.е. все поставщики поставляют товар по одной и той же цене). Семантика отношения включает следующие зависимости:
П#, ТОВАР-> ЦЕНА (по определению ключа)
ТОВАР-> ЦЕНА
Можно отметить неполную функциональную зависимость атрибута ЦЕНА от ключа. Это приводит к следующим аномалиям:
* Аномалия включения. Если у поставщика появляется новый товар, информация о товаре и его цене не может храниться в базе данных до тех пор, пока поставщик не начнет поставлять его.
* Аномалия удаления. Если поставки некоторого товара прекращаются, из базы данных придется удалить сведения о товаре и его цене, даже если он имеется в наличии у поставщиков.
* Аномалия обновления. При изменении цены товара необходим полный просмотр отношения с целью найти все поставки товара, чтобы изменение цены было отражено для всех поставщиков. Таким образом, изменение значения атрибута одного объекта влечет необходимость изменений в нескольких кортежах отношения: в противном случае база данных окажется несогласованной.
Причиной этих аномалий является неполная функциональная зависимость атрибута ЦЕНА от ключа, что обусловлено объединением в отношении ПОСТАВКИ двух семантических фактов в одной структуре. Разложение отношения ПОСТАВКИ на два отношения устраняет неполную функциональную зависимость. Отношение находится во второй нормальной форме, если оно находится в 1НФ и каждый непервичный атрибут функционально полно зависит от ключа (ключей). Следующее разложение приводит к отношению в 2НФ:
ПОСТАВКИ (П#, ТОВАР) ЦЕНА_ТОВАРА (ТОВАР, ЦЕНА)
Цену товара конкретной поставки можно определить путем соединения двух отношений по атрибуту ТОВАР. Изменение цены товара вызовет модификацию лишь одного кортежа второго отношения.
Третья нормальная форма. Рассмотрим транзитивную зависимость следующего типа:
Если А->В, В-/>А (В не является ключом) и В->С, то А->С. Пусть имеется отношение ХРАНЕНИЕ (ФИРМА, СКЛАД, ОБЪЕМ), которое содержит информацию о фирмах, получающих товары со складов, и объемах этих складов. В отношении имеются функциональные зависимости:
ФИРМА->СКЛАД (фирма получает товары только с одного склада)
СКЛАД->ОБЪЕМ
Аномалии. Если на данный момент отсутствует фирма, получающая товар со склада, то в базу данных нельзя ввести информацию об объеме склада (аномалия включения). Если последняя фирма перестает получать товар со склада, данные о складе и его объеме нельзя сохранить в базе данных (аномалия удаления). Если объем склада изменяется, необходимы просмотр всего отношения и изменение кортежей для фирм, связанных со складом (аномалия обновления). Транзитивная зависимость (аналогично неполной функциональной зависимости в предыдущем примере) вызвана наличием в отношении двух семантических различных фактов.
Преобразование отношения в 3НФ устраняет рассмотренные аномалии.
Отношение находится в 3НФ, если оно находится в 2НФ и в нем отсутствуют транзитивные зависимости непервичных атрибутов от ключа (ключей). Следующее разложение приводит к отношениям в 3НФ:
ХРАНЕНИЕ (ФИРМА, СКЛАД) С_ОБЪЕМ (СКЛАД, ОБЪЕМ)
Нормальная форма Бойса- Кодда (НФБК). Пусть имеется отношение
ПРОЕКТ (Д#, ПР#, П#), отражающее использование в проектах деталей, поставляемых поставщиками. В проекте используются несколько деталей, но каждая деталь проекта поставляется только одним поставщиком. Каждый поставщик обслуживает только один проект, но проекты могут обеспечиваться несколькими поставщиками (разных деталей). Детали, проекты, поставщики идентифицируются соответствующими номерами Д#, ПР#, П#. В отношении присутствуют следующие функциональные зависимости:
Д#, ПР#->П# (по определению ключа) П#->ПР#
Рассматриваемое отношение находится в 3НФ, так как в нем отсутствуют неполные функциональные зависимости и транзитивные зависимости непервичных атрибутов от ключей; при этом, однако, наблюдаются следующие аномалии:
Аномалии. Факт поставки поставщиком деталей для проекта не может быть занесен в базу данных до тех пор, пока в проекте действительно не начнут использоваться эти детали (аномалия включения). Если последний из типов деталей, поставляемых поставщиком для проекта, использован, данные о поставщике будут также удалены из базы данных (аномалия удаления). Если меняется поставщик некоторого типа деталей для проекта, необходим просмотр отношения для изменения всех кортежей, содержащих эти детали (аномалия обновления).
Разложение исходного отношения на отношения в НФБК устраняет перечисленные аномалии. Отношение находится в НФБК, если оно находится в 3НФ и в нем отсутствуют зависимости первичных атрибутов от непервичных. Эквивалентное определение требует, чтобы все детерминанты (т.е. домены функциональных зависимостей) были возможными ключами. Для этого необходимо устранить в данном отношении зависимость П#->ПР#.
Следующее разложение приводит к отношениям в НФБК:
ПРОЕКТ_ДЕТАЛЬ (Д#, ПР#) ПОСТАВКИ (П#, ПР#)
Многозначные зависимости. До сих пор речь шла лишь о функциональных зависимостях. В отношениях существуют и другие зависимости. Одним из видов зависимостей являются многозначные зависимости данного атрибута В от другого атрибута А в отношении R, содержащем и другие атрибуты. Говорят, что А многозначно определяет В и R (или что В многозначно зависит от А), обозначая указанную зависимость А->->В, если каждому значению А соответствует множество (возможно, пустое) значений В, никак не связанных с другими атрибутами R. Это можно проиллюстрировать на примере отношения ПРОФЕССОР (ИД#, ДЕТИ, КУРСЫ, ДОЛЖНОСТЬ), содержащего данные о детях профессора, читаемых им курсах и его должности. Между профессором и курсами связь М:N, если предположить, что некоторые курсы могут читать несколько преподавателей. Пусть экстенсионал отношения имеет следующий вид:
ИД# ДЕТИ КУРСЫ ДОЛЖНОСТЬ
525-111 Джон К410 Адъюнкт
525-111 Кэт К412 Адъюнкт
525-111 Джон К412 Адъюнкт
525-111 Кэт К410 Адъюнкт
340-055 Джек К410 Ассистент
Если объявляется многозначная зависимость атрибутов ДЕТИ или КУРСЫ от атрибута ИД#, каждому значению атрибута ИД# должно соответствовать фиксированное множество значений атрибутов ДЕТИ или КУРСЫ соответственно. Другими словами, возможно изменение значения эти атрибутов в любой строке отношения. Замена значения атрибута КУРСЫ в кортеже <525-111 Кэт К412 Адъюнкт> даст кортеж <525-111 Кэт К410 Адъюнкт>. Замена значения атрибута ДЕТИ на Джон даст кортеж <525-111 Джон К412 Адъюнкт>. (Порядок замены следует порядку предшествующего утверждения.) Оба полученных кортежа уже имеются в отношении. Таким образом, другие значения кортежей никак не связаны со значениями многозначных атрибутов. Следовательно, имеет место ИД#->->ДЕТИ и ИД#->->КУРСЫ. Для наличия в отношении многозначной зависимости необходимо иметь минимум три атрибута: ключ и независимые атрибуты, которых не может быть меньше двух (чтобы быть независимыми друг от друга!).
Аксиомы (правила вывода) для многозначных зависимостей. Введение многозначных зависимостей приводит к расширению рассмотренного выше множества правил вывода. Предположим, что X,Y и Z являются атрибутами отношения R, а U обозначает множество всех атрибутов R. Двумя наиболее важными правилами для многозначных зависимостей являются следующие:
Дополнение. Если X->->Y, то X->->U-X-Y. Это правило не имеет аналога для функциональных зависимостей.
Транзитивность. Если X->->Y и Y->->Z, то X->->Z-Y. Это более ограниченный вариант транзитивности по сравнению с правилом для функциональных зависимостей.
Более полный перечень дополнительных аксиом и других форм многозначных зависимостей можно найти в работе [228]. Читатель может проверить правило дополнения на рассмотренном нами примере. Если учесть, что функциональная зависимость является многозначной, можно вывести связь между атрибутами ИД# и ДОЛЖНОСТЬ.
Четвертая нормальная форма (4НФ). Отношение находится в 4НФ, если оно находится в НФБК, но в нем отсутствуют многозначные зависимости, которые не являются функциональными. По другому определению 4НФ требуется, чтобы в отношении для любой нетривиальной многозначной зависимости, т.е. X->->Y (X->->0 или X->->U-X-Y являются тривиальными). X обязательно содержал ключ отношения. Следующие отношения находятся в 4НФ:
R1 (ИД#, ДЕТИ)
R2 (ИД#, КУРСЫ)
R3 (ИД#, ДОЛЖНОСТЬ)
Четвертая нормальная форма показывает, что отношение может находиться в НФБК и тем не менее могут существовать некоторые аномалии, особенно при обновлениях. Например, если у профессора появится еще один ребенок, в отношение необходимо добавить не один кортеж, а столько, сколько профессор читает курсов. (Аналогичная ситуация возникает при появлении нового курса, читаемого профессором.)
Эти многочисленные модификации необходимы для сохранения независимости между всеми возможными значениями атрибутов.
Пятая нормальная форма 5НФ (проекция/соединение). Тот факт, что отношение может быть восстановлено без потерь соединением некоторых его проекций, известен как зависимость по соединению. Говорят, что отношение находится в 5НФ тогда и только тогда, когда любая зависимость по соединению в R определяется возможными ключами R[81].
Другими словами, каждая проекция R содержит не менее одного возможного ключа и по крайней мере один непервичный атрибут. Различие 5НФ и 4НФ можно показать на примере. Пусть имеются отношения: R1(П#, Д#, ОТД) R2(П#, Д#) R3(Д#, ОТД) R3(П#, ОТД)
П1 Д1 А П1 Д1 Д1 А П1 А
П1 Д1 В П2 Д1 Д1 В П1 В
П2 Д1 А П2 Д2 Д2 А П2 А
П2 Д2 В П3 Д1 Д2 В П2 В
П3 Д1 А П3 Д2 П3 А
П3 Д1 В П3 В
П3 Д2 А
П3 Д2 В
В отношении R1 отсутствуют независимые многозначные зависимости, и оно состоит только из первичных атрибутов (является “полностью ключевым”); следовательно, оно находится в 4НФ. Отношения R2, R3 и R4 находятся в 5НФ, так как R1 удовлетворяет зависимости по соединению R2, R3 и R4. Преимущество схемы с R2, R3 и R4 над R1 состоит в том, что она устраняет избыточность, а вместе с ней аномалии обновления.
СЕТЕВАЯ МОДЕЛЬ ДАННЫХ
Сетевые модели данных базируются на использовании графовой формы представления данных. Вершины графа используются для интерпретации типов сущностей, а дуги - для интерпретации типов связей между сущностями. При различных способах реализации сетевых моделей наибольшее распространение получила модель КОДАСИЛ (CODASYL - Conference on Data Systems Language - Ассоциация по языкам систем обработки данных), предложенная Рабочей группой по базам данных (DTBG - Data Base Task Group). Эта модель считается наиболее развитой сетевой моделью данных, постоянно развивается, поддерживается и сопровождается, являясь как бы стандартом. Основные типы структур данных модели КОДАСИЛ представлены на рис.18.
Рис.18
Элемент данных - наименьшая поименованная единица данных (аналог поля в файловых системах). Элемент данных - это минимальная единица данных, к которой может СУБД адресоваться непосредственно и с помощью которой осуществляется построение всех остальных структур. Примеры элементов данных: ТАБЕЛЬНЫЙ-НОМЕР, ШИФР-ДЕТАЛИ, ГОД-РОЖДЕНИЯ. Имя элемента данных используется для его идентификации в схеме структуры данных более высокого уровня. Значение элемента данных может быть числовым (целым, вещественным), нечисловым (символьным, логическим. В некоторых приложениях может использоваться “неопределенное” значение элемента данных и говорит о том, что значение соответствующего свойства объекта не определено в БД.
Агрегат данных - поименованная совокупность элементов данных внутри записи, которую можно рассматривать как единое целое. Имя агрегата используется для его идентификации в схеме структуры данного более высокого уровня. Агрегат данных может быть простым (рис19.),если состоит только из элементов данных, и составным (рис.20.), если включает в свой состав другие агрегаты.
Рис.19
| Предприятие
|
| Название
| Адрес
|

| Почто-вый индекс
| Город
| Улица_номер дома
|
Рис.20
Различают агрегаты типа “вектор” и типа “повторяющаяся группа”. Агрегат, повторяющаяся компонента которого является простым элементом данных, называется “вектором”. Например агрегат ЗАРАБОТНАЯ-ПЛАТА, в котором экземпляр элемента данных может повторяться до 12 раз (за каждый месяц года). Агрегат, повторяющаяся компонента которого представлена совокупностью данных, называется повторяющейся группой. В повторяющуюся группу могут входить отдельные элементы данных, векторы, агрегаты или повторяющиеся группы. На рис.21 представлен агрегат ЗАКАЗ-НА-ПОКУПКУ, имеющий в своем составе повторяющуюся группу ПАРТИЯ-ТОВАРА.
| Заказ_на_покупку
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Номер_за-каза
| Дата_заказа
| Партия_товара
|
|
|
|
|
|
|
|
|
|
|
|
|

| Ч
и
с
л
о
| М
е
с
я
ц
| Г
о
д
| Ш
и
ф
р
т
о
в
а
р
а
| К
о
л
и
ч
е
с
т
в
о
| Ц
е
н
а
| Ш
и
ф
р
т
о
в
а
р
а
| К
о
л
и
ч
е
с
т
в
о
| Ц
е
н
а
| ...
| Ш
и
ф
р
т
о
в
а
р
а
| К
о
л
и
ч
е
с
т
в
о
| Ц
е
н
а
|
|
| | | | | | | | | | | | | | | | | | | | | | | | | | | | |
Рис.21
Максимальное количество экземпляров для вектора и повторяющейся группы ограничено и задается при спецификации схемы записи.
Запись - поименованная совокупность элементов данных или элементов данных и агрегатов. Имя записи используется для идентификации типа записи в схемах типов структур более высокого уровня. Запись - это агрегат, не входящий в состав никакого другого агрегата. Запись может иметь сложную иерархическую структуру, поскольку допускается многократное применение агрегации.
Набор - поименованная совокупность записей, образующая двухуровневую иерархическую структуру. Каждый тип набора представляет собой отношение (связь) между двумя или несколькими типами записей. Для каждого типа набора один тип записи может быть объявлен “владельцем”, тогда остальные типы записей - его “члены”, т.е. различают “запись - владелец” и “запись - член набора”. Каждый экземпляр набора должен содержать один экземпляр записи, имеющий тип “запись - владелец”, и может содержать любое количество экземпляров записей типа “запись - член”.
Основное назначение набора - представление связей между записями. Если запись используется для представления сущности, то набор - для представления связей между рассматриваемыми сущностями. Термин набор не является аналогом набора файлов.
На графической диаграмме схемы БД тип набора изображается поименованной дугой между соответствующими типами записей. Дуга исходит из типа записи-владельца набора и заходит в тип записи-член набора. Тип набора - это основной структурный элемент, с помощью которого выполняется построение структуры базы данных. Структуры БД строятся на основании следующих основных композиционных правил:
База данных может содержать любое количество типов записей и типов наборов;
Между двумя типами записи может быть определено любое количество типов наборов;
Тип записи может быть владельцем и одновременно членом нескольких типов наборов.
В модели КОДАСИЛ основным внутренним ограничением целостности является функциональность связей, т.е. с помощью наборов можно реализовать непосредственно связи типа 1:1, 1:М, М:1. В модели это внутреннее ограничение выражается утверждением: в конкретном экземпляре набора экземпляр записи-члена набора может иметь не более одного экземпляра записи-владельца набора. Следовательно, число экземпляров набора некоторого типа в точности равно числу экземпляров записей-владельцев этого типа набора в БД. При этом экземпляр набора может быть и пустым, т.е. состоять из экземпляра записи-владельца (экземпляры записей-членов могут отсутствовать в некоторые моменты времени при функционировании системы). Из функционального характера реализуемых в МД связей следует второе внутреннее ограничение целостности - экземпляр записи может быть членом только одного экземпляра среди всех экземпляров набора одного типа (он может входить в состав двух и более экземпляров наборов, но различных типов).
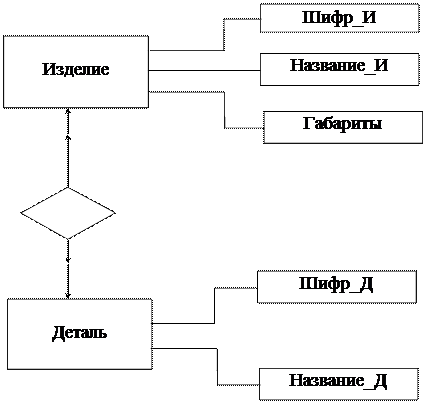
Функциональный характер реализуемых связей не позволяет непосредственно представлять в модели связи типа “многие-ко-многим” (рис.22). Для представления связи типа М:N вводят вспомогательный тип записи и две функциональные связи типа 1:М. На рис. 23 это показано для связи СПЕЦИФИКАЦИЯ между сущностями ИЗДЕЛИЕ и ДЕТАЛЬ. Каждый экземпляр вспомогательной записи типа ИЗДЕЛИЕ-ДЕТАЛЬ имеет по одному экземпляру записей-владельцев типа ИЗДЕЛИЕ и типа ДЕТАЛЬ в одном экземпляре набора типа ИМЕЕТ-В-СОСТАВЕ и в одном экземпляре набора типа ВХОДИТ-В-СОСТАВ. Введение вспомогательной записи позволяет при необходимости ввести данные, характеризующие рассматриваемую связь. В запись типа ИЗДЕЛИЕ-ДЕТАЛЬ можно добавить, например, элемент данных типа КОЛИЧЕСТВО-ТРЕБУЕМЫХ-ДЕТАЛЕЙ, которые характеризует связь между сущностями ИЗДЕЛИЕ и ДЕТАЛЬ.
Специфи-
кация
Рис.22
Невозможность непосредственного представления данных, описывающих рассматриваемые связи между сущностями, выступает в качестве еще одного внутреннего ограничения модели. В модели непосредственно с помощью наборов можно представить типы связей (между сущностями), не имеющие собственных атрибутов. Если необходимо представлять связи, имеющие атрибуты, то при конструировании схемы базы данных требуется вводить вспомогательный тип записи, с помощью которого и представляются совокупности атрибутов, описывающих связь. Пример такого представления показан на рис. 12,а,б.
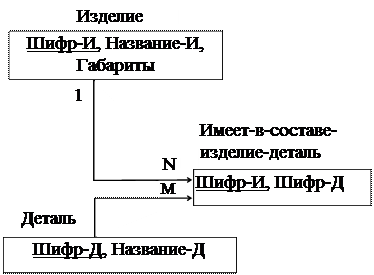
Рис.23.
Обычно тип набора задается между двумя типами записей. Однако в модели можно представлять типы связей, заданных между несколькими типами сущностей. Для этого используют многочленные наборы, которые представляют собой отношение между тремя или более типами записей, один из которых назначается владельцем набора, а остальные - членами набора. На рис. 24 показан пример многочленного набора НАУЧНЫЕ-ТРУДЫ, владельцем которого является запись типа НАУЧНЫЙ-СОТРУДНИК, а членами-записи типа НАУЧНЫЙ-ОТЧЕТ, ДОКЛАД-НА-КОНФЕРЕНЦИИ, СТАТЬЯ В ЖУРНАЛЕ, МОНОГРАФИЯ. Экземпляр некоторого типа многочленного набора включает в себя один экземпляр записи-владельца и все связанные с ним экземпляры записей-членов заданных типов. В конкретных СУБД концепция многочленного набора может быть не реализована.
Кроме указанных видов наборов в модели КОДАСИЛ существуют сингулярные наборы. Сингулярный набор - это особый набор, поскольку владельцем его является система. При его реализации возможен только один экземпляр этого типа. Это тип набора без записи-владельца. Пример сингулярного набора приведен на рис. 25 Сингулярный набор можно использовать для создания традиционного файла, состоящего из однотипных записей. Количество объявляемых сингулярных наборов произвольно. Один и тот же тип записи может быть объявлен членом сингулярного набора и одновременно владельцем либо членом других наборов.
Рис.24.
Рис.25.
Представим в виде сетевой модели БД “Футбол”. Создадим типы логических записей ИГРОКИ, КОМАНДЫ и ПОЗИЦИИ. - По причинам, указанным ниже, при рассмотрении связи СЕЗОН не существует типа логической связи, соответствующего набору объектов СРЕДНЯЯ ОЦЕНКА.
Для представления связи “многие ко многим” ИГРЫ между наборами объектов ИГРОКИ и ПОЗИЦИИ необходим новый тип записи, который назовем ИП (ИГРОКИ ПОЗИЦИИ). Формат записи типа ИП состоит из порядкового номера ИП ИД. Существует две связи в сетевой модели - связь ИП ИГРОКИ от типа записей ИП к типу записи ИГРОКИ и связь ИП ПОЗИЦИИ от типа записей ИП к типу записей ПОЗИЦИИ.
Для представления связи СЕЗОН между наборами объектов ИГРОКИ, КОМАНДЫ, СРЕДНЯЯ ОЦЕНКА создадим новый тип логической записи ИКС (ИГРОКИ КОМАНДЫ СРЕДНЯЯ ОЦЕНКА) с полем порядкового номера ИКС ИД, а также связь ИКС ИГРОКИ от типа записи ИКС к типу записи ИГРОКИ и связь ИКС КОМАНДЫ от типа записи ИКС к типу записи КОМАНДЫ. Связь СЕЗОНА однозначно определяет среднюю оценку для каждого игрока, можно включить атрибут ЗНАЧЕНИЕ ОЦЕНКИ в формат записи ИКС, что позволяет обойтись без типа записи СРЕДНЯЯ ОЦЕНКА.
Перечислим определенные выше типы логических записей, обозначив тип записи R с форматом A1, Aa,..., Ak как для схем отношения R(A1, Aa,..., Ak):
ИГРОКИ (ИМЯ, МЕСТО РОЖДЕНИЯ, ДАТА РОЖДЕНИЯ)
КОМАНДЫ (СПОРТКЛУБ, ГОРОД, ГОД)
ПОЗИЦИИ (НАЗНАЧЕНИЕ ПОЗИЦИИ, НОМЕР ПОЗИЦИИ) ИП (ИП ИД)
ИКС (ИКС ИД, НАЗНАЧЕНИЕ ОЦЕНКИ)
Кроме того, для данной БД имеем связи: ИП ИГРОКИ - от ИП к ИГРОКИ ИП ПОЗИЦИИ - от ИП к ПОЗИЦИИ ИКС ИГРОКИ - от ИКС к ИГРОКИ ИКС КОМАНДЫ - от ИКС к КОМАНДЫ
На рис.26 представлена полученная сетевая модель.
Рис.26
На рис.27 показаны некоторые экземпляры логических записей.
 Торпедо Торпедо
| Новогорск
|
|
 Трактор Трактор
| Холмск
|
|



1 4,12 2 4,27 3 3,67...


 Петров Сергей Юрьевич Петров Сергей Юрьевич
| Павлово, Горьковская область
| 23.03.1954
|
 Смирнов Виктор Павлович Смирнов Виктор Павлович
| Валжай, Новгородская область
| 31.01.1957
|
| Тимофеев Юрий Иванович
| Рудня, Смоленская область
| 12.06.1960
|





1 2 3 4...

| Правый полузащитник
|
|
| Правый защитник
|
|
 Центральный нападающий Центральный нападающий
|
|
Рис.27
ИЕРАРХИЧЕСКАЯ МОДЕЛЬ ДАННЫХ
Древовидные иерархические структуры широко используются в повседневной человеческой деятельности. Это всевозможные классификаторы, ускоряющие поиск требуемой информации, иерархические функциональные структуры управления и т.п. Иерархические модели данных, так же как и сетевые, базируются на использовании графовой формы представления данных. В графической диаграмме схемы базы данных вершины графа также используются для интерпретации типов сущностей, а дуги - типов связей между типами сущностей. При реализации каждая вершина графа представляется совокупностью описаний экземпляров сущности соответствующего типа.
Однако в иерархической модели данных действуют более жесткие внутренние ограничения на представление связей между сущностями, чем в сетевой модели. Основные внутренние ограничения иерархической модели данных:
Все типы связей функциональные, т.е. 1:1, 1:М, М:1;
Структура связей древовидная.
Результатом действия этих ограничений является ряд особенностей процесса структуризации данных в иерархической модели.
Древовидная структура, или дерево, - это связный неориентированный граф, который не содержит циклов, т.е. петель из замкнутых путей. Обычно при работе с деревом выделяют какую-то конкретную вершину, определяют ее как корень дерева и рассматривают особо - в эту вершину не заходит ни одно ребро. В этом случае дерево становится ориентированным. Ориентация на корневом дереве определяется либо от корня, либо к корню. На рисунках корень дерева указывают либо с помощью стрелок, либо с помощью наглядного расположения (самая верхняя вершина рисунка). Корневое дерево как ори