Таблица П1
| Год
|
|
|
|
|

|
|
|
|
|

|
|
|
|
|

Рис. 2
Можно считать, что аппроксимирующая функция (тренд) описывается линейной функцией (рис.2).
1. Определим коэффициенты прямой  по методу наименьших квадратов. Для этого вычислим ряд промежуточных значений и их суммы. Результаты занесены в табл.П2. Далее найдем:
по методу наименьших квадратов. Для этого вычислим ряд промежуточных значений и их суммы. Результаты занесены в табл.П2. Далее найдем:

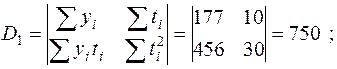
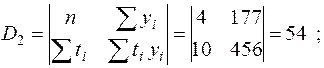
 .
.
Окончательно уравнение прямой имеет вид:  .
.
Подставив в него значения  , получим расчетные значения тренда (табл. П2).
, получим расчетные значения тренда (табл. П2).
Основная ошибка:  .
.
Таблица П2
| Год
| Период
| Фактическое
| Расчетные значения
|
|
| времени
| значение
| 
| 
| 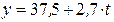
| 
|
|
|
|
|
|
| 40,2
| 0,2
|
|
|
|
|
|
| 42,9
| -0,1
|
|
|
|
|
|
| 45,6
| -0,4
|
|
|
|
|
|
| 48,3
| 0,3
|
| Итого
|
|
|
|
| -
| -
|
2. Параметр сглаживания  .
.
3. Начальные условия

 .
.
4. Для  вычислим экспоненциальные средние
вычислим экспоненциальные средние

значения коэффициентов

прогнозируемые значения 
отклонения от фактического значения 
Аналогичные вычисления выполним для =3 (1996 г.),
=4 (1997 г.), =5 (1998 г.).
Результаты представим в табл.П3
Таблица П3
Типовая таблица для построения прогноза по методу
экспоненциального сглаживания
| Год
| Период
| Фактическое
| Расчетные значения
|
|
| времени
| значение
| 
| 
| 
| 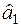
| 
| 
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2,6
| 42,6
| -0,4
|
|
|
|
| 38,6
| 34,6
| 42,6
| 2,7
| 45,3
| -0,7
|
|
|
|
| 41,6
| 37,4
| 45,8
| 2,8
| 48,6
| 0,6
|
|
| 
| -
| 44,2
| 40,1
| 48,3
| 2,7
|
| -
|
Для =3 (1996 г.)

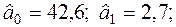

Для =4 (1997 г.):
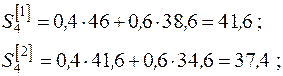


Для построения модели прогноза на 1998 г. ( =1)
=1)


Окончательная модель прогноза имеет вид:  ,
,
где =1, 2,... (что соответствует 1998, 1999... гг.)
Ошибка прогноза
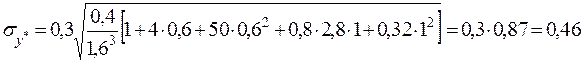
6. Выбор математической модели прогнозирования
Выбор моделей прогнозирования базируется на оценке их качества. Независимо от метода оценки параметров моделей экстраполяции (прогнозирования), их качество определяется на основе исследования свойств остаточной компоненты - ( ),
),  , т.е. величины расхождений на участке аппроксимации (построения модели) между фактическими уровнями и их расчетными значениями.
, т.е. величины расхождений на участке аппроксимации (построения модели) между фактическими уровнями и их расчетными значениями.
Качество модели определяется ее адекватностью исследуемому процессу и точностью. Адекватность характеризуется наличием и учетом определенных статистических свойств, а точность степенью близости к фактическим данным. Модель прогнозирования будет считаться лучшей со статистической точки зрения, если она является адекватной и более точно описывает исходный динамический ряд.
Модель прогнозирования считается адекватной, если она учитывает существенную закономерность исследуемого процесса, в ином случае ее нельзя применять для анализа и прогнозирования.
Закономерность исследуемого процесса находит отражение в наличии определенных статистических свойств остаточной компоненты, а именно: независимости уровней, их случайности, соответствия нормальному закону распределения и равенства нулю средней ошибки.
Независимость остаточной компоненты означает отсутствие автокорреляции между остатками ().
Перечислим последствия, вызываемые автокорреляцией остатков:
1. Недооценка дисперсии остатков функции регрессии.
2. Наличие ошибки при оценке выборочной дисперсии параметров регрессии. Ошибки в вычислении дисперсий - препятствие к корректному применению метода наименьших квадратов при построении модели исходного динамического ряда.
Очевидно, важно иметь критерий, позволяющий устанавливать наличие автокорреляции. Таким критерием является критерий Дарбина-Уотсона, в соответствии с которым вычисляется статистика  :
:
 , (37)
, (37)
где  - уровни фактического динамического ряда;
- уровни фактического динамического ряда;
 - теоретические (прогнозные) уровни динамического ряда;
- теоретические (прогнозные) уровни динамического ряда;
 - объем выборки.
- объем выборки.
Возможные значения статистики лежат в интервале  . Согласно методу Дарбина и Уотсона существует верхний
. Согласно методу Дарбина и Уотсона существует верхний  и нижний
и нижний  пределы значимости статистики . Эти критические значения зависят от уровня значимости
пределы значимости статистики . Эти критические значения зависят от уровня значимости  , объема выборки и числа объясняющих переменных
, объема выборки и числа объясняющих переменных  (для трендовых моделей =1). В табл.1 (приложение) приведены значения и для 5 % - го уровня значимости при от 15 до 100 и числе объясняющих переменных от 1 до 5.
(для трендовых моделей =1). В табл.1 (приложение) приведены значения и для 5 % - го уровня значимости при от 15 до 100 и числе объясняющих переменных от 1 до 5.
Вычисленное по ф-ле (37) значение сравнивается с и , найденными по табл.1 (приложение). При этом руководствуются правилами:
1. 
| принимается гипотеза: автокорреляция отсутствует;
|
2. 
| принимается гипотеза о существовании положительной автокорреляции остатков;
|

| при выбранном уровне значимости нельзя прийти к определенному выводу;
|
4. 
| принимается гипотеза о существовании отрицательной автокорреляции остатков.
|
Критерий Дарбина-Уотсона обладает двумя недостатками:
1. наличие области неопределенности, в которой с помощью данного критерия нельзя прийти ни к какому решению;
2. при объеме выборки меньше 15 для не существует критических значений и . В этом случае для оценки независимости уровней ряда можно использовать коэффициент автокорреляции  :
:
 , (38)
, (38)
где - статистика Дарбина-Уотсона.
Расчетное значение сравнивают с табличным  (табл.2 (приложение). Критическое значение коэффициента автокорреляции имеет одну степень свободы
(табл.2 (приложение). Критическое значение коэффициента автокорреляции имеет одну степень свободы  . Если
. Если  , то уровни динамического ряда независимы.
, то уровни динамического ряда независимы.
Для проверки случайности уровней ряда можно использовать критерий поворотных точек, который называется также критерием "пиков" и "впадин". В соответствии с этим критерием каждый уровень ряда сравнивается с двумя соединенными с ними. Если он больше или меньше их то эта точка считается поворотной. Далее подсчитывается сумма поворотных точек  . В случайном ряду чисел должно выполняться строгое неравенство:
. В случайном ряду чисел должно выполняться строгое неравенство:
 . (39)
. (39)
Соответствие ряда остатков нормальному закону распределения важно с точки зрения правомерности построения завершительных интервалов прогноза. Основными свойствами ряда остатков является их симметричность относительно тренда и преобладание малых по абсолютной величине ошибок над большими. В этой связи определяется близость к соответствующим параметрам нормального закона распределения коэффициентов асимметрии - 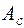 (мера "скошенности") и эксцесса -
(мера "скошенности") и эксцесса -  (мера "скученности") наблюдений около модели:
(мера "скученности") наблюдений около модели:
 ; (40)
; (40)
 ; (41)
; (41)
Если эти коэффициенты близки к нулю или равны нулю, то ряд остатков распределен в соответствии с нормальным законом. Для оценки степени их близости к нулю вычисляют среднеквадратические отклонения:
 ; (42)
; (42)
 . (43)
. (43)
Если выполняются соотношения:
 и
и  ,
,
то считается, что распределение ряда остатков не противоречит нормальному закону. В случае, когда
 или
или  ,
,
то распределение ряда не соответствует нормальному закону распределения, и построение доверительных интервалов прогноза неправомочно. В случае попадания и в зону неопределенности (между полутора и двумя среднеквадратическими отклонениями) может быть использован  - критерий:
- критерий:
 , (44)
, (44)
где  - максимальный уровень ряда остатков (), ;
- максимальный уровень ряда остатков (), ;
 - минимальный уровень ряда остатков (), ;
- минимальный уровень ряда остатков (), ;
 - среднеквадратическое отклонение остатков.
- среднеквадратическое отклонение остатков.
Если значение этого критерия попадает между табулированными границами с заданным уровнем значимости табл. 2 (приложение), то гипотеза о нормальном распределении ряда остатков принимается.
Равенство нулю средней ошибки (математическое ожидание случайной последовательности) проверяют с помощью критерия Стьюдента:
 . (45)
. (45)
Гипотеза равенства нулю средней ошибки отклоняется, если  больше табличного уровня -критерия с
больше табличного уровня -критерия с  степенями свободы и выбранным уровнем значимости табл. (приложение).
степенями свободы и выбранным уровнем значимости табл. (приложение).
После проверки всех моделей прогнозирования из выбранного массива на адекватность, необходимо выполнить оценку их точности.
В статистическом анализе известно большое число характеристик точности. Наиболее часто в практической работе встречаются:
1. Оценка стандартной ошибки: 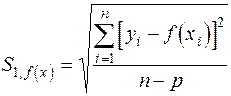 (46)
(46)
где - число наблюдений;
 - число определяемых коэффициентов модели.
- число определяемых коэффициентов модели.
2. Средняя относительная ошибка оценки:
 (47)
(47)
3. Среднее линейное отклонение  (48)
(48)
4. Ширина доверительного интервала в точке прогноза.
Для получения данной статистической оценки определим доверительный интервал в прогнозируемом периоде, т.е. возможные отклонения прогноза от основной тенденции протекания рассматриваемого процесса. Для решения этой задачи построим интервальные оценки параметров регрессии  и
и  в форме
в форме
 ,
,  . (49)
. (49)
Здесь серединами интервалов являются точечные оценки и , рассчитанные с помощью метода наименьших квадратов. Величина - теоретическое значение критерия Стьюдента при уровне значимости равном 5 % и числе степеней свободы равном  табл. (приложение).
табл. (приложение).
Стандартные ошибки коэффициентов регрессии  и
и  вычисляются по формулам
вычисляются по формулам
 ; (50)
; (50)
 (51)
(51)
Несмещенная оценка дисперсии случайной составляющей равна:
 (52)
(52)
где  - фактические значения динамических рядов
- фактические значения динамических рядов  и
и  ;
;
 - теоретическое значение, рассчитанное по уравнению регрессии;
- теоретическое значение, рассчитанное по уравнению регрессии;
 - среднее значение фактора .
- среднее значение фактора .
Верхняя 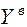 и нижняя
и нижняя  границы доверительного интервала в точке прогноза будут равны:
границы доверительного интервала в точке прогноза будут равны:
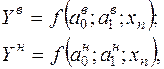 (53)
(53)
где  - верхнее и нижнее значения параметра модели прогноза;
- верхнее и нижнее значения параметра модели прогноза;
 - верхнее и нижнее значение параметра - модели прогноза;
- верхнее и нижнее значение параметра - модели прогноза;
 - значение фактора времени в точке прогноза.
- значение фактора времени в точке прогноза.
Ширина доверительного интервала в точке прогноза  :
:  (54)
(54)
Надо отметить, что ширина доверительного интервала зависит:
- от числа степеней свободы и, тем самым, от объема выборки, и чем больше объем выборки, тем меньше, при прочих равных условиях, значение критерия и, следовательно,  же доверительный интервал;
же доверительный интервал;
-от величины стандартной ошибки оценки параметра регрессии ( и ). Чем меньше и , тем меньше при равных условиях ширина доверительного интервала. Лучшей по точности считается та модель, у которой все перечисленные характеристики имеют меньшую величину. Однако эти показатели по-разному отражают степень точности модели и поэтому нередко дают противоречивые выводы. Для однозначного выбора лучшей модели исследователь должен воспользоваться либо одним основным показателем, либо обобщенным критерием.
Конечным итогом работ по выбору вида математической модели прогноза является формирование ее обобщенных характеристик: вид уравнения регрессии, значения его параметров, оценки точности и адекватности модели и сами прогнозные оценки, точечные и интервальные.
Общие сведения
Большинство явлений и процессов в экономике находятся в постоянной взаимной и всеохватывающей объективной связи. Исследование зависимостей и взаимосвязей между объективно существующими явлениями и процессами играет большую роль в экономике. Оно дает возможность глубже понять сложный механизм причинно-следственных отношений между явлениями. Для исследования интенсивности, вида и формы зависимостей широко применяется корреляционно-регрессионный анализ, который является методическим инструментарием при решении задач прогнозирования, планирования и анализа хозяйственной деятельности предприятий.
Различают два вида зависимостей между экономическими явлениями и процессами:
- функциональная - имеется однозначное отображение множества  на множество
на множество  . Множество называют областью определения функции, а - множеством значений функции. Функциональная зависимость встречается редко.
. Множество называют областью определения функции, а - множеством значений функции. Функциональная зависимость встречается редко.
- стохастическая (вероятностную, статистическую) - зависимость между случайными величинами, при которой изменение одной из величин влечет за собой изменение закона распределения другой величины.
В большинстве случаев функция (Y) или аргумент ( ) - случайные величины. и Y подвержены действию различных случайных факторов, среди которых могут быть факторы, общие для двух случайных величин. Если на случайную величину действуют факторы
) - случайные величины. и Y подвержены действию различных случайных факторов, среди которых могут быть факторы, общие для двух случайных величин. Если на случайную величину действуют факторы  ,
, 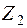 ,..., V 1, V 2, а на Y -
,..., V 1, V 2, а на Y -  , , V 1, V 3..., то наличие двух общих факторов и V 1 позволяет говорить о вероятностной или статистической зависимости между и Y.
, , V 1, V 3..., то наличие двух общих факторов и V 1 позволяет говорить о вероятностной или статистической зависимости между и Y.
В частном случае статистическая зависимость проявляется в том, что при изменении одной из величин изменяется математическое ожидание другой, в этом случае говорят о корреляции или корреляционной зависимости.
Статистическая зависимость проявляется только в массовом процессе, при большом числе единиц совокупности.
При стохастической закономерности для заданных значений зависимой переменной можно указать ряд значений объясняющей переменной, случайно рассеянных в интервале. Каждому фиксированному значению аргумента соответствует определенное статистическое распределение значений функции. Это обуславливается тем, что зависимая переменная, кроме выделенной переменной, подвержена влиянию ряда неконтролируемых или неучтенных факторов. Поскольку значения зависимой переменной подвержены случайному разбросу, они не могут быть предсказаны с достаточной точностью, а только указаны с определенной вероятностью. В экономике приходится иметь дело со многими явлениями, имеющими вероятностный характер. Например, к числу случайных величин можно отнести: стоимость продукции, доходы предприятия, межремонтный пробег автомобилей, время ремонта оборудования и т.д.
Односторонняя вероятностная зависимость между случайными величинами есть регрессия. Она устанавливает соответствие между этими величинами.
Односторонняя стохастическая зависимость выражается с помощью функции, которая называется регрессией.
Существуют различные виды регрессий:
1. Относительно числа переменных:
простая регрессия - регрессия между двумя переменными;
множественная - регрессия между зависимой переменной и несколькими объясняющими переменными  ,
,  ,...,
,...,  . Множественная линейная регрессия имеет следующий вид:
. Множественная линейная регрессия имеет следующий вид:
 , (1)
, (1)
где - функция регрессии;
 - независимые переменные;
- независимые переменные;
 - коэффициенты регрессии;
- коэффициенты регрессии;
- свободный член уравнения;
- число факторов, включаемых в модель.
2. Относительно формы зависимости:
линейная регрессия, выражаемая линейной функцией;
нелинейная регрессия, выражаемая нелинейной функцией.
3. В зависимости от характера регрессии различают следующие ее виды:
положительная - имеет место, если с увеличением (уменьшением) объясняющей переменной значения зависимой переменной также соответственно увеличиваются (уменьшаются).
отрицательная - с увеличением или уменьшением объясняющей переменной зависимая переменная уменьшается или увеличивается.
4. Относительно типа соединения явлений различают:
непосредственная - зависимая и объясняющая переменные связаны непосредственно друг с другом.
косвенная - объясняющая переменная действует на зависимую через ряд других переменных.
ложная - возникает при формальном подходе к исследуемым явлениям без уяснения того, какие причины обуславливают данную связь.
Задачи регрессионного анализа:
1.Установление формы зависимости (линейная или нелинейная; положительная или отрицательная и т.д.).
2.Определение функции регрессии и установление влияния факторов на зависимую переменную. Важно не только определить форму регрессии, указать общую тенденцию изменения зависимой переменной, но и выяснить, каково было бы действие на зависимую переменную главных факторов, если бы прочие не изменялись и если были бы исключены случайные элементы. Для этого определяют функцию регрессии в виде математического уравнения того или иного типа.
3. Оценка неизвестных значений зависимой переменной, т.е. решение задач экстраполяции и интерполяции. В ходе экстраполяции распространяются тенденции, установленные в прошлом, на будущий период. Экстраполяция широко используется в прогнозировании. В ходе интерполяции определяют недостающие значения, соответствующие моментам времени между известными моментами, т.е. определяют значения зависимой переменной внутри интервала заданных значений факторов.
Регрессия тесно связана с корреляцией. Корреляция в широком смысле слова означает связь, соотношение между объективно существующими явлениями. Связи между явлениями могут быть различны по силе. При измерении тесноты связи говорят о корреляции в узком смысле слова. Если случайные переменные причинно обусловлены и можно в вероятностном смысле высказаться об их связи, то имеется корреляция.
Корреляция, как и регрессия, имеет различные виды:
1.Относительно характера корреляции различают:
положительную;
отрицательную.
2.Относительно числа переменных:
простую;
множественную;
частную.
3.Относительно формы связи:
линейную;
нелинейную.
4.Относительно типа соединения:
непосредственную;
косвенную;
ложную.
Задачи корреляционного анализа:
1.Измерение степени связности (тесноты, силы) двух и более явлений. Здесь речь идет в основном о подтверждении уже известных связей.
2.Отбор факторов, оказывающих наиболее существенное влияние на результативный признак, на основании измерения тесноты связи между явлениями.
3.Обнаружение неизвестных причинных связей. Корреляция непосредственно не выявляет причинных связей между явлениями, но устанавливает степень необходимости этих связей и достоверность суждений об их наличии. Причинный характер связей выясняется с помощью логически-профессиональных рассуждений, раскрывающих механизм связей.
Понятия корреляции и регрессии тесно связаны между собой. В корреляционном анализе оценивается сила связи, а в регрессионном анализе исследуется ее форма.
Любое причинное влияние может выражаться либо функциональной, либо корреляционной связью. Но не каждая функция или корреляция соответствует причинной зависимости между явлениями. Поэтому требуется обязательное исследование причинно-следственных связей.
Исследование корреляционных связей мы называем корреляционным анализом, а исследование односторонних стохастических зависимостей - регрессионным анализом.
Линейная регрессия
Пусть задана система случайных величин и Y, и пусть случайные величины и Y зависимы.
Представим одну из случайных величин как линейную функцию другой случайной величины :
 , (6)
, (6)
где  - параметры, которые подлежат определению.
- параметры, которые подлежат определению.
В общем случае эти параметры могут быть определены различными способами, наиболее часто используется метод наименьших квадратов (МНК).
Функцию  называют наилучшим приближением в смысле МНК, если математическое ожидание
называют наилучшим приближением в смысле МНК, если математическое ожидание  принимает наименьшее возможное значение.
принимает наименьшее возможное значение.
В этом случае функцию называют среднеквадратической регрессией Y на . Можно доказать, что линейная среднеквадратическая регрессия имеет вид:
 , (7)
, (7)
где  - математические ожидания случайных величин
- математические ожидания случайных величин 
соответственно;
 - среднеквадратические отклонения случайных величин
- среднеквадратические отклонения случайных величин
соответственно;
 - коэффициент парной корреляции, который определяется:
- коэффициент парной корреляции, который определяется:
 , (8)
, (8)
где  - ковариация
- ковариация
 , (9)
, (9)
тогда  - коэффициент регрессии.
- коэффициент регрессии.
Возникает проблема определения параметров  на основе выборки.
на основе выборки.
Рассмотрим определение параметров выбранного уравнения прямой линии среднеквадратической регрессии по несгруппированным данным. Пусть изучается система количественных признаков (), т.е. ведутся наблюдения за двумерной случайной величиной (). Пусть в результате наблюдений получено пар чисел 
Требуется по полученным данным найти выборочное уравнение прямой линии среднеквадратической регрессии:
 .
.
Поскольку данные несгруппированные, т.е. каждая пара чисел встречается один раз, то можно перейти от условной средней к переменной . Угловой коэффициент 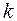 обозначим через
обозначим через  и назовем его выборочной оценкой коэффициента регрессии .
и назовем его выборочной оценкой коэффициента регрессии .
Итак, требуется найти:
 . (10)
. (10)
Очевидно, параметры  и
и  нужно подобрать так, чтобы точки
нужно подобрать так, чтобы точки  , построенные по исходным данным, лежали как можно ближе к прямой (10) (рис. 1).
, построенные по исходным данным, лежали как можно ближе к прямой (10) (рис. 1).




Уточним смысл этого требования. Для этого введем следующее понятие. Назовем отклонением разность вида:
 ,
,
где Yi - вычисляется по уравнению (10) и соответствует наблюдаемому
значению  ;
;
 - наблюдаемая ордината, соответствующая .
- наблюдаемая ордината, соответствующая .
Подберем параметры и так, чтобы сумма квадратов указанных отклонений была наименьшей:
 .
.
В этом состоит требование метода наименьших квадратов (МНК).
Эта сумма есть функция  отыскиваемых параметров и
отыскиваемых параметров и
 или
или  .
.
Для отыскания  найдем частные производные и приравняем к нулю:
найдем частные производные и приравняем к нулю:

Далее:

Для простоты вместо  будем писать
будем писать  (индекс
(индекс  - опускаем), тогда:
- опускаем), тогда:

Получили систему двух линейных уравнений относительно  и . Решая эту систему, получим:
и . Решая эту систему, получим:
 ; (11)
; (11)
 . (12)
. (12)
Метод наименьших квадратов применяется и для нахождения параметров множественной регрессии. В этом случае число линейных уравнений возрастает, и такие системы уравнений решаются с помощью ЭВМ.
Основные понятия корреляционно-регрессионного анализа
1. Среднее значение переменной:  , (13)
, (13)
где - эмпирическое значение переменной ;
- число наблюдений.
2. Дисперсия:  . (14)
. (14)
3. Ковариация:  (15)
(15)
4. Коэффициент корреляции:  . (16)
. (16)
Коэффициент корреляции характеризует тесноту или силу связи между переменными и .
Значения, принимаемые  , заключены в пределах от -1 до +1:
, заключены в пределах от -1 до +1:
- при положительном значении имеет место положительная корреляция, т.е. с увеличением (уменьшением) значений одной переменной () значение другой () соответственно увеличивается (уменьшается);
- при отрицательном значении имеет место отрицательная корреляция, т.е. с увеличением (уменьшением) значений значения соответственно уменьшаются (увеличиваются).
При изучении экономического явления, зависящего от многих факторов, строится множественная регрессионная зависимость. В этом случае для характеристики тесноты связи используется коэффициент множественной корреляции:
 , (17)
, (17)
где  - остаточная дисперсия зависимой переменной;
- остаточная дисперсия зависимой переменной;
 - общая дисперсия зависимой переменной.
- общая дисперсия зависимой переменной.
5. Общая дисперсия - характеризует разброс наблюдений фактических значений от среднего значения  :
:
 . (18)
. (18)
6. Остаточная дисперсия характеризует ту часть рассеяния переменной , которая возникает из-за всякого рода случайностей и влияния неучтенных факторов:
 , (19)
, (19)
где  - теоретические значения переменной , полученные по уравнению
- теоретические значения переменной , полученные по уравнению
регрессии (фор-ла 1) при подстановке в него наблюдаемых фактических значений .
7. Коэффициент детерминации с






