Лекция №1 Введение. Основные понятия.
Пример1. Мария Иванова. Профессиональный маляр, владеет и управляет небольшой компанией состоящей из нее самой и, когда это необходимо, наемных работников. Она занимается этим уже 10 лет. Однажды Марии позвонил Петр и говорит: «Здравствуйте Мария, вы красили мой дом три года назад!» Мария была в ужасе. Она красит по 50 домов в год, к тому же иногда занимается покраской дворовых территорий, рисует в детских садах и делает ремонты в подъезде. Но Петр продолжил: «Моя соседка хочет, чтобы вы сделали в ее доме что-то подобное». Для того, чтобы разгрузить свою память и организовать учет своей деятельности, Мария наняла консультанта для разработки БД, чтобы она могла хранить ее на своем компьютере.
Записью и получением этих данных занимается специальная программа, называемая системой управления базами данных (СУБД). К сожалению, эти данные представлены в форме таблиц и не слишком полезны и понятны Марии. Ей хотелось бы знать кому, когда и что она выполняла, какие материалы использовала, где заказывала и т.п. Для этого разработчик создает для нее прикладную программу, которая обрабатывает формы ввода-вывода и формирует необходимые отчеты.
База Марии является однопользовательской, поскольку в каждый конкретный момент времени к ней обращается один человек. Иногда этого недостаточно, требуется, чтобы одновременно к базе могли обращаться несколько человек.
Пример2. Бюро проката инструментов использует БД для учета сдаваемых в аренду строительных инструментов. В этой фирме работает несколько менеджеров, каждый из которых, в тот или иной момент времени занимается выдачей инструмента в прокат. Каждый менеджер должен иметь доступ к данным и не должен мешать выдавать инструмент другому менеджеру. Здесь потребуется многопользовательская БД. Бюро проката имеет локальную сеть, соединяющую несколько персональных компьютеров с сервером на котором находится БД. У каждого из служащих есть доступ к прикладной программе, позволяющей работать с тремя видами форм: информация о клиентах, об инструментах и договор аренды.
Пример3. Рассмотрим еще более обширное приложение технологии баз данных – государственное бюро регистрации автомобилей и выдачи водительских удостоверений. В него входит 52 центра, где принимают экзамены и осуществляют выдачу и продление водительских удостоверений и 37 офисов, занимающиеся регистрацией транспорта. Персонал этих офисов использует в своей работе БД. Прежде чем конкретному лицу будут выданы права, в БД просматривается информация об этом лице на предмет наличия нарушений ПДД. Точно также просматриваются транспортные средства. У такой БД сотни пользователей. База является большой и сложной. Также есть несколько видов сотрудников, каждый из которых имеет различный доступ к информации, следовательно, прикладная программа содержит ряд интерфейсов.
Пример4. Небольшой курортный остров на западном побережье Канады. Для продвижения на мировой туристический рынок остров разработал сайт. Сайт преследует три цели: реклама острова, его достопримечательностей, мест отдыха и развлечений; регистрацию посетителей для последующей рассылки им рекламной информации; прием запросов на бронирование мест в гостиницах, отелях и т.п. Для поддержки этого сайта используются две БД. Одна БД рекламная – содержит фото, видео материалы, у этой базы два типа пользователей. Обычные посетители сайта имеют доступ к этой базе только для чтения, пользуясь стандартными браузерами, они могут исследовать сайт. В этом им помогает прикладная программа, извлекающая данные из рекламной БД. Другой тип пользователей рекламной БД – это сотрудники, которые осуществляют поддержку сайта. Кроме рекламной БД, прикладная программа также обращается к БД клиентов. В ней хранятся сведения о клиентах, их запросы на бронирование и обслуживание. Когда посетитель сайта вводит запрос на бронирование, прикладная программа отправляет этот запрос соответствующей фирме
Три аспекта отличают эту БД от всех остальных:
1. Хранение мультимедийных данных.
2. Использование браузера для отображения информации из БД.
3. Применение web-ориентированной технологии для передачи данных между браузером, приложением и БД.
Приведенные примеры демонстрируют возможные варианты использования технологий баз данных.
Итак, давайте подведем итоги. Что же такое база данных?
Можно сказать, что БД – это набор сведений, которые каким-то образом структурированы и где-то хранятся. Но мы можем то же самое сказать о библиотеке, например, или об обычном шкафе. Поэтому мы будем использовать данный термин в более конкретном значении.
База данных – это самодокументированное собрание интегрированных записей.
Что значит самодокументированность? Это значит, что БД хранит не только данные пользователя, но и также информацию о том, как эти данные хранятся, т.е. описание собственной структуры или метаданные.
Метаданные хранят информацию о том, какие объекты есть в БД, какого они типа данных, из чего они состоят, как они между собой взаимосвязаны.
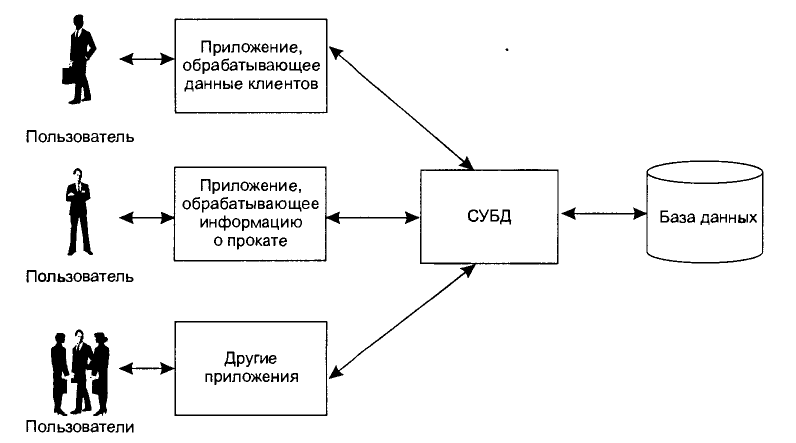 Все примеры, которые мы с вами рассмотрели, имеют общую структуру:
Все примеры, которые мы с вами рассмотрели, имеют общую структуру:
Пользователь взаимодействует с прикладной программой, которая взаимодействует с СУБД, которая обращается к БД.
На сегодняшний день возможности и функции многих СУБД расширились и они могут самостоятельно выполнять многие задачи прикладных программ.
СУБД – это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
 Характеристики и функции СУБД можно разделить на три подсистемы: подсистема средств проектирования, подсистему средств обработки и ядро СУБД.
Характеристики и функции СУБД можно разделить на три подсистемы: подсистема средств проектирования, подсистему средств обработки и ядро СУБД.
Подсистема средств проектирования – это набор инструментов, упрощающих проектирование и реализацию БД и их приложений. Как правило, это средства для создания таблиц, форм, запросов и отчетов. (Создание запроса)
Подсистема обработки занимается обработкой компонентов приложения, созданных с помощью средств проектирования. (Выполнение запроса)
Ядро СУБД – посредник между данными и подсистемами средств проектирования и обработки. Ядро преобразует запросы в команды операционной системы, выполняющие запись и чтение данных с физического носителя. Ядро также участвует в управлении блокировками, транзакциях, резервном копировании и восстановлении.
В настоящее время все СУБД делят на две большие категории: файл-серверные и клиент-серверные.

Дадим краткую характеристику этим системам.
MS SQL Server
Является программной системой, предназначенной не для разработки приложений, а для управления многопользовательскими БД с архитектурой клиент-сервер (объем базы – несколько Тбайт). Система позволяет управлять базами данных (тиражировать данные, вести их параллельную обработку, получать и передавать данные по ЛВС, Интернет), обеспечивает взаимодействие с клиентскими приложениями, функционирующими на разной технической платформе.
Oracle
Является программной системой, предназначенной для разработки корпоративных БД и информационных систем, объемы информации в которых превышают Тбайт. Основу системы составляет SQL. Для данной СУБД характерна высокая степень защиты данных.
СУБД MS Access
Является одной из самых популярных СУБД, предназначенная для создания систем управления реляционными данными с объемом сотни Мбайт. Ориентирована как на программиста, так и на конечного пользователя. Можно создавать многопользовательские БД. Отличается простотой и возможностью интеграции с MS SQL-Server. Неоспоримым преимуществом является возможность ее использования в качестве средства обучения процессу разработки БД.
Файловые системы.
Первые АИС появились в 60е гг. В основе лежали файловые системы.Файловые системы – набор программ, предназначенных для решения той или иной задачи. Со временем стали очевидны следующие недостатки файловых систем:
1) Разделение и изоляция данных. Данные изолированы в отдельных файлах, что требует значительных трудозатрат при извлечении информации, часто - выполнения синхронной обработки нескольких файлов.
2) Дублирование данных. Файлы разных систем могли пересекаться, т.е. содержать одни и те же данные. Это приводило к неэкономному использованию дисковой памяти или к нарушению целостности данных (например, сведения о сотруднике организации, формируемые в отделе кадров и в бухгалтерии могут стать противоречивыми).
3) Зависимость от данных. Программы на алгоритмическом языке содержат описание данных, то при изменении их структуры приходилось изменять исходные тексты программ
4) Несовместимость форматов файлов. Поскольку структура файлов определяется кодом приложений, она также зависит от языка программирования этого приложения. Например, структура файла, созданного программой на языке COBOL, может совершенно отличаться от структуры файла, создаваемого программой на языке С. Прямая несовместимость таких файлов затрудняет процесс их совместной обработки.
5) Фиксированные запросы и быстрое увеличение количества приложений. В процессе работы у пользователей постоянно возрастают требования к реализации новых запросов к данным, хранящимся в файлах. При этом реализация запросов осуществляется программистом в виде приложений, что, соответственно, ведет к увеличению их количества. В процессе реализации часто нарушаются меры по обеспечению безопасности или целостности данных, не предусматриваются средства восстановления в случае сбоя аппаратного или программного обеспечения, доступ к файлам часто ограничивается одним пользователем.
История развития.
Разработчики (и пользователи) поняли, что использовать только файлы очень накладно для производства, и стали искать пути решения появившихся проблем. Для этого была разработана сначала иерархическая модель данных. В середине 60-х годов корпорация IBM совместно с фирмой NAA (North American Aviation, в настоящее время - Rockwell International) разработали первую СУБД - иерархическую систему IMS (Information Management System). Суть иерархической системы заключалась в следующем: есть узел – совокупность данных, которые описывают какой-либо объект, все узлы связаны между собой строго в иерархическом порядке. У системы были свои преимущества (простота описания) и недостатки (дублирование данных).

Затем появилась сетевая модель данных. Основные понятия те же. Но появились более разнообразные связи.

В 1970 году британский ученый Эдгар Кодд выпустил работу «A Relational Model of Data for Large Shared Data Banks». Данная работа считается первым трудом по реляционному хранению данных. После ее выпуска начинаются активные работы по разработке данной системы хранения информации. В данное время активно разрабатываются Объектно-Ориентированные базы данных.
Функции СУБД
Непосредственное управление данными во внешней памяти.
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
Управление буферами оперативной памяти.
СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов. Заметим, что существует отдельное направление СУБД, которое ориентировано на постоянное присутствие в оперативной памяти всей БД. Это направление основывается на предположении, что в будущем объем оперативной памяти компьютеров будет настолько велик, что позволит не беспокоиться о буферизации. Пока эти работы находятся в стадии исследований.
Управление транзакциями.
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД (если, конечно, такая система заслуживает названия СУБД). Но понятие транзакции гораздо более важно в многопользовательских СУБД. То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег). С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом). Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов БД. При использовании любого алгоритма сериализации возможны ситуации конфликтов между двумя или более транзакциями по доступу к объектам БД. В этом случае для поддержания сериализации необходимо выполнить откат (ликвидировать все изменения, произведенные в БД) одной или более транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
Журнализация.
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД. Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода. Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя. Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу). При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того, чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом. Более подробно мы рассмотрим это в соответствующей лекции. Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия - это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии). Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
Поддержка языков БД.
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). Перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL). Прежде всего, язык SQL сочетает средства SDL и DML, т.е. позволяет 25 определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов. Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код. Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне. Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне. Более точное описание возможных реализаций этих функций на основе языка SQL будет приведено в разделах, посвященных языку SQL и его реализации.
Телеобработка
 Традиционной архитектурой многопользовательских систем раньше считалась схема, получившая название телеобработки, при которой один компьютер с единственным процессором был соединен с несколькими терминалами.
Традиционной архитектурой многопользовательских систем раньше считалась схема, получившая название телеобработки, при которой один компьютер с единственным процессором был соединен с несколькими терминалами.
При этом вся обработка выполнялась с помощью единственного компьютера, а присоединенные к нему пользовательские терминалы были не способными функционировать самостоятельно. С центральным процессором терминалы были связаны с помощью кабелей, по которым они посылали сообщения пользовательским приложениям В свою очередь, пользовательские приложения обращались к необходимым службам СУБД. Таким же образом сообщения возвращались назад на пользовательский терминал. К сожалению, при такой архитектуре основная и чрезвычайно большая нагрузка возлагалась на центральный компьютер, который должен был выполнять не только действия прикладных программ и СУБД, но и значительную работу по обслуживанию терминалов (например, форматирование данных, выводимых на экраны терминалов).
Файловый сервер
 В среде файлового сервера обработка данных распределена в сети, обычно представляющей собой локальную вычислительную сеть (ЛВС). Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлам.
В среде файлового сервера обработка данных распределена в сети, обычно представляющей собой локальную вычислительную сеть (ЛВС). Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлам.
Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск. СУБД на каждой рабочей станции посылает запросы файловому серверу по всем необходимым ей данным, которые хранятся на диске файлового сервера. Такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы в целом. Поскольку файловый сервер не воспринимает команд на языке SQL, то СУБД должна запросить у файлового сервера файлы необходимые для совершения запроса. Таким образом, архитектура с использованием файлового сервера обладает следующими основными недостатками.
1. Большой объем сетевого трафика.
2. На каждой рабочей станции должна находиться полная копия СУБД.
3. Управление параллельной работой, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
Технология "клиент/сервер"
 Технология "клиент/сервер" была разработана с целью устранения недостатков, имеющихся в первых двух подходах.
Технология "клиент/сервер" была разработана с целью устранения недостатков, имеющихся в первых двух подходах.
Клиент принимает от пользователя запрос, проверяет синтаксис и генерирует запрос к базе данных на языке SQL или другом языке базы данных, который соответствует логике приложения. Затем он передает сообщение серверу, ожидает поступления ответа и форматирует полученные данные для представления их пользователю.
Сервер принимает и обрабатывает запросы к базе данных, а затем передает полученные результаты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, а также выполнение запроса и обновление данных. Помимо этого, поддерживается управление параллельной работой и восстановлением.
Выполняемые клиентом и сервером операции приведены в следующей таблице:

Этот тип архитектуры обладает приведенными ниже преимуществами:
Обеспечивается более широкий доступ к существующим базам данных.
Повышается общая производительность системы. Поскольку клиенты и сервер находятся на разных компьютерах, их процессоры способны выполнять приложения параллельно. При этом настройка производительности компьютера с сервером упрощается, если на нем выполняется только работа с базой данных.
Стоимость аппаратного обеспечения снижается. Достаточно мощный компьютер с большим устройством хранения нужен только серверу — для хранения и управления базой данных.
Сокращаются коммуникационные расходы. Приложения выполняют часть операций на клиентских компьютерах и посылают через сеть только запросы к базе данных, что позволяет существенно сократить объем пересылаемых по сети данных.
Повышается уровень непротиворечивости данных. Сервер может самостоятельно управлять проверкой целостности данных, поскольку все ограничения определяются и проверяются только в одном месте. При этом каждому приложению не приходится выполнять собственную проверку.
Существует дальнейшее расширение двухуровневой архитектуры "клиент/сервер", при котором функциональная часть прежнего, толстого клиента разделяется на две части.
Основные понятия ER-диаграмм
Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе.
Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная".
Каждая сущность в модели изображается в виде прямоугольника с наименованием:

Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности.
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность:

Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность.
Сущность может иметь несколько различных ключей.
Ключевые атрибуты изображаются на диаграмме подчеркиванием:

Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою.
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности:

Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи:

Рис. 5
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней. Характерный
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи:

Модальность " может " означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность " должен " означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
Связь может иметь разную модальность с разных концов.
Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
<Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>.
Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на Рис. 4 читается так:
Слева направо: "каждый сотрудник может иметь несколько детей".
Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику".
Пример разработки простой ER-модели
При разработке ER-моделей мы должны получить следующую информацию о предметной области:
- Список сущностей предметной области.
- Список атрибутов сущностей.
- Описание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что перед нами стоит задача разработать информационную систему по заказу некоторой оптовой торговой фирмы. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам, выяснилось, что он (менеджер) считает, что проектируемая система должна выполнять следующие действия:
- Хранить информацию о покупателях.
- Печатать накладные на отпущенные товары.
- Следить за наличием товаров на складе.
Выделим все существительные в этих предложениях - это будут потенциальные кандидаты на сущности и атрибуты, и проанализируем их (непонятные термины будем выделять знаком вопроса):
- Покупатель - явный кандидат на сущность.
- Накладная - явный кандидат на сущность.
- Товар - явный кандидат на сущность
- (?)Склад - а вообще, сколько складов имеет фирма? Если несколько, то это будет кандидатом на новую сущность.
- (?)Наличие товара – это, скорее всего, атрибут, но атрибут какой сущности?
Сразу возникает очевидная связь между сущностями - "пок





