

Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Топ:
Эволюция кровеносной системы позвоночных животных: Биологическая эволюция – необратимый процесс исторического развития живой природы...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Характеристика АТП и сварочно-жестяницкого участка: Транспорт в настоящее время является одной из важнейших отраслей народного хозяйства...
Интересное:
Средства для ингаляционного наркоза: Наркоз наступает в результате вдыхания (ингаляции) средств, которое осуществляют или с помощью маски...
Что нужно делать при лейкемии: Прежде всего, необходимо выяснить, не страдаете ли вы каким-либо душевным недугом...
Наиболее распространенные виды рака: Раковая опухоль — это самостоятельное новообразование, которое может возникнуть и от повышенного давления...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Предпосылки создания и развитие Юникода
К концу 1980-х годов стандартом стали 8-битные символы, при этом существовало множество разных 8-битных кодировок, и постоянно появлялись всё новые. Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример — появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437). В результате появилось несколько проблем:
Наиболее удобным представлялось создание единой «широкой» кодировки. Она единообразно решала все указанные проблемы. Кодировки с переменной длиной, широко использующиеся в Восточной Азии, были признаны слишком сложными в использовании, поэтому было решено использовать коды фиксированной ширины. Использование 32-битных символов казалось слишком расточительным, поэтому было решено использовать 16-битные.
|
|
Таким образом, первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 216 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+04F0).
Юникод и UTF
http://softwaremaniacs.org/blog/2006/07/28/unicode-and-bytes/
Довольно быстро возникла необходимость кодировать гораздо больше, чем 65536 символов (чуть больше миллиона сейчас) и, что главное, появилась необходимость кодировать их по-разному. Поэтому в отличие от старых кодировок стандарт Юникода полностью разделяет две вещи:
Номера, присваиваемые символам, полностью абстрактны. Это не байты, не слова, а просто числа. Например символу "Заглавная кириллическая буква А" назначен номер 1040, он же — 410 в шестнадцатеричной системе. И формально в Юникоде это принято записывать как U+0410.
А вот способов представлять это число в памяти или записывать в файлы существует больше одного. Называются они " формы кодирования " (Unicode Transformation Format). Вот наиболее распространенные.
UTF-8
В этой форме символы кодируются одиночными байтами. Но поскольку одного байта для кодирования миллиона символов маловато, разные символы кодируются разным количеством байтов. Те, которые входят в старый код ASCII, кодируются одним байтом и их значения полностью с ASCII совпадают. Русские и, например, западноевропейские символы кодируются двумя байтами, японские катакана и хирагана — тремя, а есть еще всякая экзотика, где могут быть и четыре байта.
|
|
UTF-8 совместим со старым софтом и протоколами, потому что в такой строке не может встретиться байт 0x00, который бы ее обрывал. Также в большинстве текстов файлов конфигураций и исходников программ, которые традиционно состоят в основном из ASCII, он занимает не больше места, чем ASCII — тот же байт на символ. Еще один плюс — у него нет разных вариантов для разных платформ, он везде одинаковый.
Самый существенный его минус — это то, что по количеству байт в строке невозможно определить ее длину в символах.
Кратко об UTF-8 можно прочитать в http://blog.perlover.com/2009/11/10/easy-about-utf8/
UTF-8 изнутри
Поскольку вы знаете битовую систему кодирования, то вот вам краткая памятка, как кодируется UTF-8:
Первый байт Unicode символа в UTF-8 начинается с байта, где 7-ой бит всегда единица, и 6-ой бит всегда также единица. При этом в первом байте, если смотреть на биты слева направо (7-ой, 6-ой и так до нулевого), идет столько единиц, сколько байтов, включая первый, идет на кодирование одного Unicode символа. Заканчивается последовательность единиц нулем. А после этого идут биты самого Unicode символа. Остальные биты Unicode символа попадают во второй, или даже в третий байты (максимум три, почему — смотрите чуть ниже). Остальные байты, кроме первого, всегда идут с началом ’10′ и потом 6 битов следующей части Unicode символа.
Пример
Пусть, например, есть байт 11010000 и второй байт 10011110. Первый байт начинается с 110. Это значит, что символ кодируется двумя байтами, причем второй байт начинается с 10. А кодируют эти два байта символ Unicode, который состоит из двух кусков от первого и второго байтов, получается [10000][011110] -> 10000011110 -> 41E в 16-ричной системе, или U+041E в написании Unicode обозначений. Это большая русская О.
BOM
Byte Order Mark (BOM)(метка порядка байтов) - Unicode символ, используемый для индикации порядка байтов текстового файла. Его кодовый символ U+FEFF (ZERO WIDTH NON-BREAKING SPACE) неразрывный пробел с нулевой шириной, также именуемый меткой порядка байтов (англ. byte order mark, BOM). По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла. Помимо своего конкретного использования в качестве указателя порядка байтов, символ может также указать, какой кодировкой Unicode закодирован текст.
|
|
По наличию сигнатуры программы могут автоматически определить, является ли файл закодированным в UTF-8, однако файлы с такой сигнатурой могут некорректно обрабатываться старыми программами, в частности xml-анализаторами. Такие редакторы, как Notepad++, Notepad2 и Kate, позволяют явно указывать, следует ли добавлять сигнатуру при сохранении UTF-файлов.
Кодирование целых чисел
Прямойкод
При записи числа в прямом коде (sign-and-magnitude method) старший разряд (most significant bit) является знаковым разрядом (sign bit). Если его значение равно нулю, то число положительное, если единице — отрицательное. В остальных разрядах (которые называются цифровыми) записывается двоичное представление модуля числа. Например, число −5 в восьмибитовом типе данных, использующем прямой код, будет выглядеть так: 10000101.
| Рис. 1. Нумерация двоичных чисел в прямом представлении |
 Таким способом в
Таким способом в  -битовом типе данных можно представить диапазон чисел
-битовом типе данных можно представить диапазон чисел 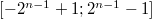 .
.
Достоинства метода:
получить прямой код числа достаточно просто.
Недостатки:
выполнение арифметических операций с отрицательными числами требует усложнения архитектуры центрального процессора (например, для вычитания невозможно использовать сумматор, необходима отдельная схема для этого);
существуют два нуля ("+0" и "−0"), из-за чего усложняется арифметическое сравнение.
Из-за этого прямой код используется очень редко.
Код со сдвигом
 При использовании кода со сдвигом (excess-
При использовании кода со сдвигом (excess- 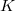 , где
, где  ; также говорят biased representation) целочисленный отрезок от нуля до
; также говорят biased representation) целочисленный отрезок от нуля до  ( — количество бит) сдвигается влево на
( — количество бит) сдвигается влево на 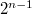 , а затем получившиеся на этом отрезке числа последовательно кодируются в порядке возрастания кодами от 000...0 до 111...1. Например, число −5 в восьмибитовом типе данных, использующем код со сдвигом, превратится в −5 + 128 = 123, то есть будет выглядеть так: 01111011.
, а затем получившиеся на этом отрезке числа последовательно кодируются в порядке возрастания кодами от 000...0 до 111...1. Например, число −5 в восьмибитовом типе данных, использующем код со сдвигом, превратится в −5 + 128 = 123, то есть будет выглядеть так: 01111011.
По сути, при таком кодировании:
к кодируемому числу прибавляют ;
переводят получившееся число в двоичную систему исчисления.
Можно получить диапазон значений  .
.
Достоинства метода:
|
|
не требуется усложнение архитектуры процессора;
нет проблемы двух нулей.
Недостатки:
| Рис. 2 Код со сдвигом. |
ряд положительных и отрицательных чисел несимметричен.
Из-за необходимости усложнять арифметические операции код со сдвигом для представления целых чисел используется не часто, но зато применяется для хранения порядка вещественного числа.
Дополнительный код (дополнение до единицы )
В качестве альтернативы представления целых чисел может использоваться код с дополнением до единицы (англ. Ones' complement).
Алгоритм получения кода числа:
если число положительное, то в старший разряд (который является знаковым) записывается ноль, а далее записывается само число;
| Рис. 3. Нумерация двоичных чисел в представлении c дополнением до единицы. В отличие от кода со сдвигом, нулю соответствуют коды 00...000 и 11...111 |
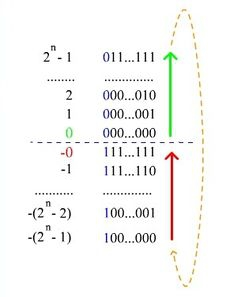 если число отрицательное, то код получается инвертированием представления модуля числа (получается обратный код)
если число отрицательное, то код получается инвертированием представления модуля числа (получается обратный код)
Пример: переведём число −13 в восьмибитовый код. Прямой код модуля −13 --- 00001101, инвертируем и получаем 11110010. Для получения из дополнительного кода самого числа достаточно инвертировать все разряды кода.
Таким способом можно получить диапазон значений .
Достоинства метода:
Простое получение кода отрицательных чисел
Недостатки метода:
выполнение арифметических операций с отрицательными числами требует усложнения архитектуры центрального процессора
существуют два нуля ("+0" и "−0")
Сложение и вычитание
Сложение и вычитание чисел без знака происходит по обычным для позиционных систем счисления алгоритмам.
Примеры (для k =3):
0012+1002= 1012;
1012-0102=0112.
Ситуации, когда уменьшаемое меньше вычитаемого или когда результат суммы не умещается в k разрядов, считаются ошибочными и должны отслеживаться устройством компьютера. Реакция на такие ошибки может быть различной в разных типах компьютеров.
Умножение и деление
Во многих компьютерах умножение производится как последовательность сложений и сдвигов. Для этого в АЛУ имеется регистр, называемый накапливающим сумматором, который до начала выполнения операции содержит число ноль. В процессе выполнения операции в нем поочередно размещаются множимое и результаты промежуточных сложений, а по завершении операции — окончательный результат. Другой регистр АЛУ, участвующий в выполнении этой операции, вначале содержит множитель. Затем по мере выполнения сложений содержащееся в нем число уменьшается, пока не достигнет нулевого значения.
|
|
Деление для компьютера является трудной операцией. Обычно оно реализуется путем многократного прибавления к делимому дополнительного кода делителя.
Предпосылки создания и развитие Юникода
К концу 1980-х годов стандартом стали 8-битные символы, при этом существовало множество разных 8-битных кодировок, и постоянно появлялись всё новые. Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример — появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437). В результате появилось несколько проблем:
Наиболее удобным представлялось создание единой «широкой» кодировки. Она единообразно решала все указанные проблемы. Кодировки с переменной длиной, широко использующиеся в Восточной Азии, были признаны слишком сложными в использовании, поэтому было решено использовать коды фиксированной ширины. Использование 32-битных символов казалось слишком расточительным, поэтому было решено использовать 16-битные.
Таким образом, первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 216 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+04F0).
Юникод и UTF
http://softwaremaniacs.org/blog/2006/07/28/unicode-and-bytes/
Довольно быстро возникла необходимость кодировать гораздо больше, чем 65536 символов (чуть больше миллиона сейчас) и, что главное, появилась необходимость кодировать их по-разному. Поэтому в отличие от старых кодировок стандарт Юникода полностью разделяет две вещи:
Номера, присваиваемые символам, полностью абстрактны. Это не байты, не слова, а просто числа. Например символу "Заглавная кириллическая буква А" назначен номер 1040, он же — 410 в шестнадцатеричной системе. И формально в Юникоде это принято записывать как U+0410.
А вот способов представлять это число в памяти или записывать в файлы существует больше одного. Называются они " формы кодирования " (Unicode Transformation Format). Вот наиболее распространенные.
UTF-8
В этой форме символы кодируются одиночными байтами. Но поскольку одного байта для кодирования миллиона символов маловато, разные символы кодируются разным количеством байтов. Те, которые входят в старый код ASCII, кодируются одним байтом и их значения полностью с ASCII совпадают. Русские и, например, западноевропейские символы кодируются двумя байтами, японские катакана и хирагана — тремя, а есть еще всякая экзотика, где могут быть и четыре байта.
UTF-8 совместим со старым софтом и протоколами, потому что в такой строке не может встретиться байт 0x00, который бы ее обрывал. Также в большинстве текстов файлов конфигураций и исходников программ, которые традиционно состоят в основном из ASCII, он занимает не больше места, чем ASCII — тот же байт на символ. Еще один плюс — у него нет разных вариантов для разных платформ, он везде одинаковый.
Самый существенный его минус — это то, что по количеству байт в строке невозможно определить ее длину в символах.
Кратко об UTF-8 можно прочитать в http://blog.perlover.com/2009/11/10/easy-about-utf8/
UTF-8 изнутри
Поскольку вы знаете битовую систему кодирования, то вот вам краткая памятка, как кодируется UTF-8:
Первый байт Unicode символа в UTF-8 начинается с байта, где 7-ой бит всегда единица, и 6-ой бит всегда также единица. При этом в первом байте, если смотреть на биты слева направо (7-ой, 6-ой и так до нулевого), идет столько единиц, сколько байтов, включая первый, идет на кодирование одного Unicode символа. Заканчивается последовательность единиц нулем. А после этого идут биты самого Unicode символа. Остальные биты Unicode символа попадают во второй, или даже в третий байты (максимум три, почему — смотрите чуть ниже). Остальные байты, кроме первого, всегда идут с началом ’10′ и потом 6 битов следующей части Unicode символа.
Пример
Пусть, например, есть байт 11010000 и второй байт 10011110. Первый байт начинается с 110. Это значит, что символ кодируется двумя байтами, причем второй байт начинается с 10. А кодируют эти два байта символ Unicode, который состоит из двух кусков от первого и второго байтов, получается [10000][011110] -> 10000011110 -> 41E в 16-ричной системе, или U+041E в написании Unicode обозначений. Это большая русская О.
|
|
|

Наброски и зарисовки растений, плодов, цветов: Освоить конструктивное построение структуры дерева через зарисовки отдельных деревьев, группы деревьев...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

Своеобразие русской архитектуры: Основной материал – дерево – быстрота постройки, но недолговечность и необходимость деления...

История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!