С появлением SQL-89 стало подразумеваться, что по умолчанию используется правило UNIQUE. Это случилось еще до того, как кто-либо успел предложить или обсудить другие варианты. Но такие предложения появились уже во время разработки SQL-92. Кто-то упорно предпочитал правила PARTIAL и считал, что они должны быть единственными. С этой точки зрения правила SQL-89 (UNIQUE) были настолько нежелательны, что рассматривались как ошибка, которую необходимо исправить с помощью правил PARTIAL. Были и те, кому больше нравились правила UNIQUE, а правила PARTIAL для них были непонятными, двусмысленными и неэффективными. Впрочем, были и те, кто предпочитал еще более строгие правила FULL. В конце концов этот спор был решен следующим образом: пользователи получили в свое распоряжение все три ключевых слова и теперь могли выбирать тот подход, который им нужен. А потом, с появлением SQL: 1999, добавились еще и правила SIMPLE. Впрочем, рост числа правил делает работу с неопределенными значениями какой угодно, но только не простой (simple). Итак, если не указаны ключевые слова SIMPLE, PARTIAL или FULL, то будут выполняться правила SIMPLE.
Логические связки
Как видно из массы предыдущих примеров, чтобы из таблицы получить нужные строки, одного условия в запросе часто бывает недостаточно. В некоторых случаях условий, которым должны удовлетворять строки, должно быть не меньше двух. В других же случаях, чтобы быть выбранной, строка должна удовлетворять одному из нескольких условий. А иногда нужно получить только те строки, которые указанному условию не удовлетворяют. Для выполнения этих требований в SQL имеются логические связки AND, OR и NOT.
AND
Если для получения строки необходимо, чтобы все условия из какого-либо их набора имели значение True, используйте логическую связку AND (и). Проанализируйте следующий пример, в нем используются поля InvoiceNo (номер счета-фактуры), SaleDate (дата продажи), Salesperson (продавец), TotalSale (всего продано) из таблицы SALES (продажи):
SELECT InvoiceNo, SaleDate, Salesperson, TotalSaleFROM SALESWHERE SaleDate >= '2003-05-18'AND SaleDate <= '2003-05-24';
Предложение WHERE (где) должно соответствовать следующим двум условиям.
· Дата SaleDate должна была наступить не раньше 18 мая 2003 года.
· Дата SaleDate должна была наступить не позже 24 мая 2003 года.
Таким образом, обоим условиям будут одновременно соответствовать только те строки, в которых записаны данные о продажах в течение недели, прошедшей с 18 мая. Запрос возвратит именно эти строки.
Внимание:
Обратите внимание, что связка AND (и) имеет чисто логическое значение. Такое ограничение иногда может привести к путанице, потому что союз "и" люди обычно используют в более широком смысле. Предположим, например, что ваш босс говорит: "Мне нужны данные о продажах, проведенных Фергюсоном и Фордом". А раз он сказал о "Фергюсоне и Форде", то вы, возможно, напишете следующий запрос SQL:
SELECT *FROM SALESWHERE Salesperson = 'Ferguson'AND Salesperson = 'Ford';
Только не несите его результаты своему боссу. Ладно? Тому, что он имел в виду, больше соответствует другой запрос:
SELECT *FROM SALESWHERE Salesperson IN ('Ferguson', 'Ford');
Первый запрос будет безрезультатным, потому что ни одну из продаж, отмеченных в таблице SALES, Фергюсон и Форд не провели вместе. Второй же запрос вернет информацию обо всех продажах, сделанных или Фергюсоном, или Фордом. Скорее всего, она-то и требовалась вашему боссу.
OR
Если для возвращения строки необходимо, чтобы из нескольких условий для этой строки было верно хотя бы одно, используйте логическую связку OR (или):
SELECT invoiceNo, SaleDate, Salesperson, TotalSaleFROM SALESWHERE Salesperson = 'Ford'OR TotalSale > '200';
В результате выполнения этого запроса будут получены данные обо всех продажах, которые были сделаны на любую сумму, но только Фордом, или были сделаны кем угодно, но при этом превышали 200 долларов.
NOT
Для отрицания условия служит связка NOT (не). Если к условию, которое возвращает значение True, добавить NOT, то после этого условие будет возвращать значение False. А если до изменения условие возвращало False, то после добавления к нему NOT оно будет возвращать True. Посмотрите на следующий пример:
SELECT InvoiceNo, SaleDate, Salesperson, TotalSaleFROM SALESWHERE NOT (Salesperson = 'Ford');
Этот запрос возвращает строки для всех сделок по продажам, совершенных всеми продавцами, кроме Форда.
Внимание:
Иногда при использовании связки (AND, OR или NOT) бывает неясно, какая у нее область действия. Чтобы гарантировать применение связки именно к нужному предикату, заключите его в круглые скобки. В последнем примере связка NOT применяется как раз к целому предикату (Salesperson = Ford'), а не к какой-либо его части.
Предложения GROUP BY
Иногда вместо того, чтобы получить отдельные записи, вам может понадобиться узнать что-либо о группе записей. В этом случае вам поможет предложение GROUP BY (группировать по).
Предположим, что вы менеджер по продажам и хотите посмотреть эффективность ваших продаж. Для этого вы можете воспользоваться оператором SELECT, как показано в следующем примере:
SELECT InvoiceNo, SaleDate, Salesperson, TotalSaleFROM SALES;
Полученный результат приведен на рис. 9.1.
Рис. 9.1. Результат выбора информации о продажах с 07.01.2001 по 07.07.2001
Этот результат дает вам лишь некоторое представление о том, как работают ваши продавцы, поскольку здесь выводится информация о небольшом количестве продаж. Однако в реальной жизни продажи компаний очень велики, и в этом случае уже непросто будет определить, как были достигнуты результаты. Чтобы проверить, была ли коммерчески эффективной работа продавцов, вы можете скомбинировать предложение GROUP BY с одной из функций агрегирования (также называемыми итоговыми функциями), чтобы получить количественную картину о выполнении продаж. К примеру, вы можете просмотреть, кто из продавцов работает с более дорогостоящими и прибыльными позициями, используя функцию среднего значения (AVG):
SELECT Salesperson, AVG(TotalSale)FROM SALESGROUP BY Salesperson;
Полученный результат приведен на рис. 9.2.

Рис. 9.2. Средний уровень продаж по каждому продавцу
Как видно из рис. 9.2, средние продажи Фергюсона значительно выше, чем у двух других продавцов. Чтобы сравнить общие продажи по каждому продавцу, выполните следующий запрос:
SELECT Salesperson, SUM(TotalSale)FROM SALESGROUP BY Salesperson;
Результат этого запроса приведен на рис. 9.3.
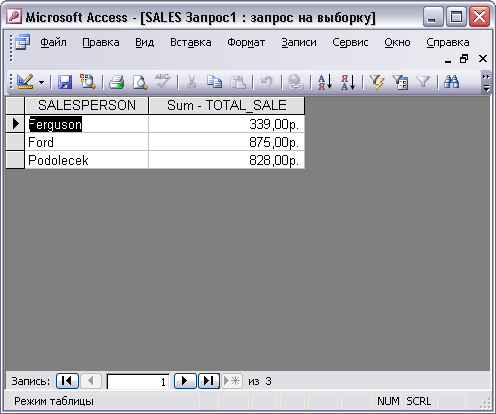
Рис. 9.3. Общие продажи по каждому продавцу
Как и в случае среднего уровня продаж, Фергюсон имеет также самый высокий уровень общих продаж.
Предложение HAVING
Предложение HAVING позволяет еще лучше анализировать сгруппированные данные. Предложение HAVING (при условии) – это фильтр, который по своему действию похож на предложение WHERE, но, в отличие от предложения WHERE, HAVING работает не с отдельными строками, а с их группами. Проиллюстрируем действие предложения HAVING, используя следующий пример. Предположим, что менеджеру по продажам нужно сосредоточиться на работе других продавцов. Для этого ему необходимо исключить из общих данных количество продаж Фергюсона, поскольку его продажи находятся "в другой весовой категории". Чтобы сделать это, воспользуемся предложением HAVING:
SELECT Salesperson, SUM(TotalSale)FROM SALESGROUP BY SalespersonHAVING Salesperson <> 'Ferguson';
Результат этого запроса приведен на рис. 9.4. Строки, которые относятся к продавцу по фамилии Фергюсон, на экран не выводятся.

Рис. 9.4. Общие продажи по каждому продавцу за исключением Фергюсона
Чтобы показать таблицу, выводимую запросом, в алфавитном порядке или в обратном алфавитном порядке, используйте предложение ORDER BY (по порядку). В то время как предложение GROUP BY собирает строки в группы и сортирует группы по алфавиту, ORDER BY сортирует отдельные строки. ORDER BY должно быть последним предложением в запросе. Если в запросе также имеется и предложение GROUP BY, то оно вначале собирает строки вывода в группы. Затем предложение ORDER BY сортирует строки, находящиеся внутри каждой группы. А если предложения GROUP BY нет, то оператор рассматривает всю таблицу как группу и предложение ORDER BY сортирует все ее строки таким образом, чтобы были упорядочены значения в столбцах, указанных в этом предложении.
Это можно проиллюстрировать с помощью данных из таблицы SALES (продажи). В ней имеются столбцы InvoiceNo (номер счета-фактуры), SaleDate (дата продажи), Salesperson (продавец), TotalSale (всего продано). Все данные SALES можно увидеть, но в произвольном порядке, если воспользоваться следующим простым примером:
SELECT * FROM SALES;
В одних реализациях это порядок, в котором строки вставлялись в таблицу, а в других реализациях строки могут быть выстроены в зависимости от времени самого последнего обновления каждой из них. Кроме того, порядок может неожиданно измениться, если кто-то физически реорганизует базу данных. В большинстве случаев порядок расположения получаемых строк приходится указывать. Возможно, вам нужно увидеть строки, которые расположены по порядку, задаваемому значениями из столбца SaleDate:
SELECT * FROM SALES ORDER BY SaleDate;
При выполнении этого примера все строки таблицы SALES будут возвращены именно втом порядке, который задан значениями SaleDate.
А порядок расположения тех строк, у которых в столбце SaleDate одинаковые значения, зависит от используемой реализации. Впрочем, и для строк с одинаковыми значениями Sale-Date можно также указать порядок сортировки. Возможно, вам, например, нужно для каждого значения SaleDate видеть строки таблицы SALES, расположенные по порядку, которые заданы значениями InvoiceNo:
SELECT * FROM SALES ORDER BY SaleDate, InvoiceNo;
В этом примере таблица SALES вначале упорядочивается по значениям SaleDate; затем для каждого такого значения строки этой таблицы располагаются по порядку, задаваемому InvoiceNo. Однако не путайте этот пример со следующим запросом:
SELECT * FROM SALES ORDER BY InvoiceNo, SaleDate;
При выполнении этого запроса SALES упорядочивается по столбцу InvoiceNo. Затем для каждого значения InvoiceNo строки таблицы SALES располагаются по порядку, задаваемому столбцом SaleDate. Скорее всего, нужный вам результат вы не получите, потому что мало вероятно, чтобы для одного номера счета-фактуры было множество дат продажи.
Следующий запрос является очередным примером того, как SQL может возвращать данные:
SELECT * FROM SALES ORDER BY Salesperson, SaleDate;
В этом примере упорядочивание сначала идет по столбцу Salesperson, а затем – по SaleDate. Просмотрев данные, расположенные в таком порядке, вы, возможно, захотите его изменить:
SELECT * FROM SALES ORDER BY SaleDate, Salesperson;
Теперь упорядочивание сначала идет по столбцу SaleDate, а затем – по Salesperson.
Во всех этих примерах упорядочивание идет в порядке возрастания (ASC), который является порядком сортировки по умолчанию. Последний оператор SELECT вначале показывает самые ранние продажи (строки таблицы SALES), а в пределах определенной даты ставит продажи, проведенные Адамсом, перед продажами, проведенными Бейкером. А если вы предпочитаете порядок убывания (DESC), можете указать его для одного или множества столбцов из предложения ORDER BY:
SELECT * FROM SALESORDER BY SaleDate DESC, Salesperson ASC;
В этом примере для данных продаж указывается порядок убывания дат, в результате чего записи о самых недавних продажах будут показаны первыми, но для продавцов указывается порядок возрастания, т.е. их фамилии будут располагаться в обычном алфавитном порядке.
Реляционные операторы
В этой главе…
· Объединение таблиц, имеющих похожую структуру
· Объединение таблиц, имеющих разную структуру
· Получение нужных данных из множества таблиц
SQL – это язык запросов, используемый в реляционных базах данных. Почти во всех примерах предыдущих глав рассматривались простые базы данных с одной таблицей. Теперь настало время показать, в чем же состоит реляционность реляционной базы. Вообще говоря, эти базы называются "реляционными" потому, что состоят из множества связанных друг с другом таблиц (а "связанные друг с другом" – это по-английски "related").
Так как данные, хранящиеся в реляционной базе, распределены по множеству таблиц, то запрос обычно извлекает данные из более чем одной таблицы. В SQL:2003 имеются операторы, которые объединяют данные из множества исходных таблиц в одну. Это операторы UNION, INTERSECTION и EXCEPT, а также семейство операторов объединения JOIN. Причем каждый из них объединяет данные своим особым способом.
UNION
Оператор UNION (объединение) – это реализация в языке SQL оператора объединения из реляционной алгебры. Оператор UNION дает возможность получать информацию из нескольких таблиц, имеющих одинаковую структуру. Одинаковая структура означает следующее.
· Во всех таблицах имеется одинаковое количество столбцов.
· У всех соответствующих столбцов должны быть идентичный тип данных и одинаковая длина.
При соблюдении этих критериев таблицы являются совместимыми для объединения. В результате объединения двух таблиц возвращаются все строки, имеющиеся в каждой из них. Не возвращаются только повторяющиеся строки.
Скажем, вы создаете базу данных по бейсбольной статистике (см. главу 9). Она состоит из двух таблиц, совместимых для объединения, которые называются AMERICAN (Американская лига) и NATIONAL (Национальная лига). В каждой из них имеются по три столбца, и типы у всех соответствующих столбцов совпадают. На самом деле даже имена у таких столбцов одинаковые, хотя для объединения это условие не является обязательным.
В таблице NATIONAL перечислены имена, фамилии питчеров Национальной лиги и количество тех игр, в которых они все время были на подаче. Эти данные находятся в столбцах FirstName (имя), LastName (фамилия) и CompleteGames (полностью сыгранные игры). Та же информация, но только о питчерах Американской лиги, содержится в таблице AMERICAN. Если объединить таблицы NATIONAL и AMERICAN с помощью оператора UNION, то в результате получится виртуальная таблица со всеми строками из первой и второй таблиц. В этом примере, чтобы показать работу оператора UNION, я вставил в каждую таблицу всего лишь по несколько строк:
| SELECT * FROM NATIONAL;
|
| FirstName
| LastName
| СompleteGames
|
| -----------
| -----------
| ------------------
|
| Sal
| Maglie
| 11
|
| Don
| Newcombe
| 9
|
| Sandy
| Koufax
| 13
|
| Don
| Drysdale
| 12
|
| SELECT * FROM AMERICAN;
|
| FirstName
| LastName
| СompleteGames
|
| -----------
| -----------
| ------------------
|
| Whitey
| Ford
| 12
|
| Don
| Larson
| 10
|
| Bob
| Turley
| 8
|
| Allie
| Reynolds
| 14
|
| SELECT * FROM NATIONAL
|
| UNION
|
| SELECT * FROM AMERICAN;
|
| FirstName
| LastName
| СompleteGames
|
| -----------
| -----------
| ------------------
|
| Allie
| Reynolds
| 14
|
| Bob
| Turley
| 8
|
| Don
| Drysdale
| 12
|
| Don
| Larson
| 10
|
| Don
| Newcombe
| 9
|
| Sal
| Maglie
| 11
|
| Sandy
| Koufax
| 13
|
| Whitey
| Ford
| 12
|
Оператор UNION DISTINCT работает так же, как и оператор UNION без ключевого слова DISTINCT. В обоих случаях дублирующие строки удаляются из конечной совокупности.
Внимание:
Звездочка ('*') используется для обозначения всех столбцов, имеющихся в таблице. Это сокращенное обозначение работает в большинстве случаев прекрасно, но если реляционные операторы используются во встроенном или модульном коде SQL, то это обозначение может доставить массу неприятностей. Что если в одну из таблиц или сразу во все будут добавлены дополнительные столбцы? Тогда эти таблицы больше не будут совместимыми для объединения, и программа перестанет работать. И даже если во все таблицы, для обеспечения совместимости по операции объединения, будут добавлены одни и те же столбцы, то программа скорее всего не будет готова работать с этими дополнительными данными. Таким образом, лучше явно перечислять нужные столбцы, а не полагаться на сокращение '*'. Но при вводе с консоли "одноразовой" команды SQL звездочка работает прекрасно. Если вдруг запрос не сработает, всегда можно быстро вывести структуру таблицы.
Операция UNION обычно убирает любые повторяющиеся строки, которые появляются в результате ее выполнения. В большинстве случаев это желаемый результат. Впрочем, иногда повторяющиеся строки требуется сохранять. В таких случаях используйте UNION ALL (объединение всех).
Обратимся к нашему примеру и предположим, что Боб Тарли по кличке "Буллит" ("пуля") был "продан" в середине сезона из команды "Нью-Йорк Янкиз", входящей в Американскую лигу, в "Бруклин Доджерс" из Национальной лиги. А теперь предположим, что в каждой команде за сезон у этого питчера было по восемь игр, в течение которых он бессменно подавал мяч. Обычный оператор UNION, показанный в примере, отбросит одну из двух строк с данными об этом игроке. И хотя будет казаться, что за сезон он полностью провел на подаче мяча только восемь игр, но ведь на самом деле таких игр – замечательный результат – было 16. Корректные данные можно получить с помощью следующего запроса:
SELECT * FROM NATIONALUNION ALLSELECT * FROM AMERICAN;
Иногда оператор UNION можно применять и к двум таблицам, которые не являются совместимыми для объединения. Если в таблицу, которая должна получиться, войдут столбцы, имеющиеся в обеих исходных таблицах и являющиеся совместимыми, то можно использовать оператор UNION CORRESPONDING (объединение соответствующих). В этом случае учитываются только указанные столбцы, и только они войдут в получившуюся таблицу.
Полностью отличаются друг от друга данные, которые бейсбольные статистики собирают по питчерам и игрокам в дальней части поля. Однако каждый раз и в том и в другом случае записываются имя (first name), фамилия (last name) игрока, выходы на поле (putouts), ошибки (errors) и доля принятых мячей (fielding percentage). Конечно, по игрокам в дальней части поля не собирают данные о выигрышах/проигрышах (won/lost record), остановленных мячах (saves) или другие сведения, относящиеся только к подаче мяча. Но все равно, чтобы получить некоторую общую информацию об умении играть в защите, можно выполнять оператор UNION, который будет брать данные из двух таблиц – OUTFIELDER (игрок в дальней части поля) и PITCHER (питчер):
SELECT *FROM OUTFIELDERUNION CORRESPONDING(FirstName, LastName, Putouts, Errors, FieldPct)SELECT *FROM PITCHER;
В результате получается таблица, где для каждого питчера или игрока в дальней части поля указаны имя и фамилия, а также количество выходов на поле, ошибок и доля принятых мячей. Здесь, как и при использовании простого оператора UNION, повторяющиеся строки удалены. Таким образом, если игрок некоторое время играл в дальней части поля, а также был питчером, то при выполнении оператора UNION CORRESPONDING часть статистики этого игрока будет потеряна. Чтобы этого не случилось, используйте UNION ALL CORRESPONDING (объединение всех соответствующих).
Совет:
В списке, находящемся сразу за ключевым словом CORRESPONDING (соответствующие), должны быть только те имена столбцов, которые имеются во всех объединяемых таблицах. Если этот список имен будет пропущен, то будет неявно использован полный список имен. Однако, если в одну или несколько таблиц будут добавлены новые столбцы, этот неявный список может измениться. Так что имена столбцов лучше не пропускать, а указывать явно.
INTERSECT
В результате выполнения оператора UNION создается таблица, где появляются все строки, которые могут находиться в какой-либо из исходных таблиц. А если нужны только те строки, каждая из которых находится одновременно во всех исходных таблицах, то можно использовать оператор INTERSECT (пересечь). Он является реализацией в SQL оператора пересечения из реляционной алгебры. Выполнение INTERSECT будет показано на примере из воображаемого мира, в котором Боб Тарли был в середине сезона "продан" команде "Доджерс".
| SELECT * FROM NATIONAL;
|
| FirstName
| LastName
| СompleteGames
|
| -----------
| -----------
| ------------------
|
| Sal
| Maglie
| 11
|
| Don
| Newcombe
| 9
|
| Sandy
| Koufax
| 13
|
| Don
| Drysdale
| 12
|
| Bob
| Turley
| 8
|
| SELECT * FROM AMERICAN;
|
| FirstName
| LastName
| СompleteGames
|
| -----------
| -----------
| ------------------
|
| Whitey
| Ford
| 12
|
| Don
| Larson
| 10
|
| Bob
| Turley
| 8
|
| Allie
| Reynolds
| 14
|
В таблице, полученной в результате выполнения оператора INTERSECT, будут показаны только те строки, которые находятся одновременно во всех исходных таблицах:
SELECT *
FROM NATIONAL
INTERSECT
SELECT *
FROM AMERICAN;
| FirstName
| LastName
| СompleteGames
|
| -----------
| -----------
| ------------------
|
| Bob
| Turley
| 8
|
В полученной таким образом таблице сообщается, что Боб Тарли был единственным питчером, который и в той и в другой лиге бессменно подавал мяч в течение одного и того же количества игр. Обратите внимание, что, как и в случае с UNION, INTERSECT DISTINCT выдает тот же результат, что и оператор INTERSECT, используемый без ключевого слова. В этом примере возвращается только одна строка с именем Боба Тарли.
Роль ключевых слов ALL и CORRESPONDING в операторе INTERSECT такая же, как и в операторе UNION. Если используется ALL, то получится таблица, в которой повторяющиеся строки остаются. А когда используется CORRESPONDING, то исходные таблицы не обязательно должны быть совместимыми для объединения, хотя у соответствующих столбцов должны быть одинаковые тип и длина.
Проанализируем следующий пример. В муниципалитете хранят данные о пейджерах, используемых полицейскими, пожарниками, уборщиками улиц и другими работниками городского хозяйства. Данные обо всех ныне используемых пейджерах находятся в таблице PAGERS (пейджеры) из базы данных. А данные обо всех пейджерах, которыми по той или иной причине не пользуются, находятся в другой таблице, OUT (вышедший из строя), имеющей такую же структуру, что и PAGERS. Информация ни по одному из пейджеров не может одновременно быть в двух таблицах. Выполнив оператор INTERSECT, можно проверить, не произошло ли такое ненужное дублирование строк:
SELECT *
FROM PAGERS
INTERSECT CORRESPONDING (PagerlD)
SELECT *
FROM OUT;
В результате появляется таблица, и если в ней будут находиться какие-либо строки, то это будет означать, что база данных обновлена некорректно. Необходимо проверить все значения, которые появляются в этой таблице в столбце PagerlD (идентификатор пейджера). Ведь пейджер, соответствующий этому идентификатору, либо используется, либо не работает. Одновременно и того и другого не бывает. Обнаружив противоречивые данные, можно провести работы по восстановлению целостности базы данных – выполнить в одной из двух таблиц операцию DELETE (удалить).
EXCEPT
Оператор UNION выполняется с двумя таблицами и возвращает все строки, которые имеются как минимум в одной из них. Другой же оператор, INTERSECT, возвращает все те строки, которые имеются одновременно в первой и второй таблицах. А оператор EXCEPT (за исключением), наоборот, возвращает все строки, которые имеются в первой таблице, но не имеются во второй.
Теперь вернемся к примеру с базой данных, в которой находится информация о муниципальных пейджерах. Скажем, группа пейджеров, объявленных неработающими, была возвращена поставщику для ремонта, но к настоящему времени эти пейджеры уже исправлены и используются снова. В таблицу PAGERS данные о возвращенных пейджерах уже занесены, но из таблицы OUT их данные по некоторой причине не удалены, хотя это надо было сделать. С помощью оператора EXCEPT можно вывести все номера пейджеров, находящиеся в столбце PagerlD таблицы OUT, за исключением тех номеров, которые принадлежат уже исправленным пейджерам:
SELECT *
FROM OUT
EXCEPT CORRESPONDING (PagerlD)
SELECT *
FROM PAGERS;
При выполнении этого запроса возвращаются все строки из таблицы OUT, у которых значения PageiTD не находятся в таблице PAGERS.
Операторы объединения
Операторы UNION, INTERSECT и EXCEPT представляют ценность в тех многотабличных базах данных, таблицы которых являются совместимыми. Однако во многих случаях приходится брать данные из наборов таблиц, имеющих между собой мало общего. Мощными реляционными операторами являются операторы объединения JOIN, в результате выполнения которых данные, взятые из множества таблиц, объединяются в одну. Таблицы из этого множества могут иметь мало общего друг с другом.
Стандарт SQL:2003 поддерживает разные типы операторов объединения. Какой из них лучше всего подходит в конкретной ситуации – это зависит от того результата, который требуется получить.






