В предыдущей главе мы рассматривали ситуацию, когда период колебания равнялся целому числу m от периода дискретизации 1/T. Теперь рассмотрим ситуацию, когда это не так. Положим, что частота равна не m, а m+q, где 0 < q < 1. Воспользуемся формулой (35). Поскольку первые несколько условий для нецелого m+q не выполняются, то остается последняя, самая сложная формула, помеченная словами "Для остальных k":

Подставим в эту формулу m+q вместо m и выполним упрощения, воспользовавшись формулой (34) и введя обозначение ρ = 2πj.

Итого:
 , ρ = 2πj (37)
, ρ = 2πj (37)
Теперь построим график функции, чтобы понять, как она себя ведет. Ниже показана трехмерная поверхность. По горизонтальной оси отложено k, по вертикальной |Xk| и по оси, уходящей вглубь плоскости, отложено q от 0.01 до 0.99.

Рис. 1.
На рисунке видно два ярко выраженных ребра. Первое из них всегда приходится на k = m и k = m + 1. Второе ребро получается в результате зеркального эффекта. Высота пика наименьшая в окрестности q = 0.5. А наибольшая в окрестности q = 1 и q = 0 - то есть при целочисленном m.
К сожалению, пик не является единственным ненулевым коэффициентом Фурье. Рядом с ним есть множество меньших, но не нулевых величин. Если при целочисленном m можно наблюдать единственную полоску, то при нецелом m + q эта полоска размазывется.

Рис. 2.
На рисунке приведена практическая ситуация. Это - ДПФ для звука, содержащегося в обычном WAV-файле. Черный цвет соответствует |Xk|, а синий - Arg(Xk). Исходный сигнал содержал ноту "ля" второй октавы с частотой 440 гц и фазой в 90 градусов. ДПФ было выполнено для N = 1000. Однако частота дискретизации звука в WAV-файле составляла 44100 Гц, так что период дискретизации был равен T = 1000/44100 секунд и m = 440*1000/44100 = 9.97, то есть, не целое. В результате ярко выраженный пик окружают дополнительные ненулевые значения.
На следующем рисунке:

Рис. 3.
показана "хорошая" ситуация, когда частота исходного звука составляла 441 Гц, и m = 441*1000/44100 = 10, то есть целое. Вы видите только один ненулевой отсчет.
Этот эффект будем называть эффектом размазывания. Вы видите, что он определяет погрешность, с которой можно найти период исходного колебания. Погрешность равна 1/T. При достаточно большом отклонении от целого m эффект может быть очень заметен. Например ниже вы видите ДПФ для сигнала, соответствующего ноте "ля-бемоль":

Рис. 4.
Точнее можно попытаться определить параметры m, A и φ численными методами.
Для поиска φ следует учесть, что изменение A не повлияет на комплексную фазу (аргумент) коэффициентов Xk. В самом деле, мы можем представить коэффициенты в виде:
Xk = (A/2)Z(m,φ)k,
где Z(m,φ)k - комплексное число, не зависящее от действительного числа A, но зависящее от m и φ:
Z(m,φ)k = 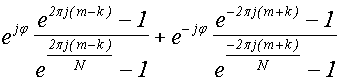
Также не зависит от A отношение коэффициентов Xk/Xl = Z(m,φ)k/Z(m,φ)l.
Это значит, что у нас есть две целевые функции, с помощью которых мы можем найти частоту m/T и фазу φ. Возьмем Xk, максимальное по модулю. Если соседние отсчеты Xk-1 и Xk+1 равны нулю, то у нас нет эффекта размазывания и параметры восстанавливаются так, как описано в предыдущей главе. На самом деле нам придется сравнивать не с нулем, а с некоторым малым числом, поскольку некоторая погрешность при вычислении ДПФ неизбежна.
Теперь, когда мы убедились в наличии эффекта размазывания, попробуем найти m и φ после чего восстановим A по формуле: A = |2Xk / Z(m,φ)k|.
Сначала найдем два максимальных отсчета Xk и Xk+1. Теперь мы знаем, что искомое m лежит на интервале (k, k+1).
Для нахождения m и φ нужно численно решить систему уравнений:
|Z(m,φ)k/Z(m,φ)k+1| = |Xk/Xk+1|
Arg(Z(m,φ)k) = Arg(Xk)
Здесь только две неизвестных - m и φ, неизвестная A исключена. Систему можно решить итерационно. Для этого сначала фиксируем φ и подбираем m, которое удовлетворяет первому уравнению системы. Потом - наоборот фиксируем найденное m и подбираем φ, которое удовлетворяет второму уравнению системы. Потом снова возавращаемся к первому уравнения - до тех пор, пока оба уравнения не окажутся сбалансированы с достаточной точностью.
Ранее мы рассмотрели случаи, когда число элементов преобразования равно степени двойки. К сожалению, на данный момент не существует столь же эффективного алгоритма вычисления ДПФ для произвольного N. Однако, существует алгоритм, который значительно лучше "лобового" решения задачи. Он требует, чтобы N было четным. Допустим, что N = M 2T = M L. Число L - целая степень двойки, числа M и T - положительные целые.
Сложность этого алгоритма равна N2 / L + Nlog2L. Как видите, этот алгоритм тем эффективнее, чем больше L, то есть, чем больше число элементов N "похоже" на степень двойки. В худшем случае, когда L = 2, он лишь немногим лучше "лобового" решения, которое имеет сложность N2.
Тем не менее, на практике нам часто полезен именно описанный алгоритм. Допустим, у нас имеется оцифрованный звуковой сигнал, длиной в 2001 отсчет, и мы хотим узнать его спектр. Если мы применим обычный алгоритм, то нам придется отрезать "лишний" кусок сигнала, размером почти в его половину, уменьшив число отсчетов до 1024. Но в таком случае мы потеряем гармоники, которые, возможно, возникли только ближе к концу сигнала. Другой вариант: дополнить исходный сигнал до 2048 отсчетов - тоже плох. В самом деле: чем его дополнить? Если нулями, то в результате мы приобретем множество лишних гармоник из-за резкого скачка сигнала вниз на 2001-м отсчете. Совершенно неясно, как интерполировать сигнал на дополнительные 47 отсчетов так, чтобы не появились новые, ненужные гармоники (шумы). И только новый алгоритм решает эту проблему. С помощью него мы можем "отрезать" совсем небольшой кусочек, в 1 отсчет, взяв L = 16 и получив ускорение в 16 раз! Либо мы можем пожертвовать кусочком чуть длиннее, взяв L еще больше. Для реальных сигналов невелика вероятность, что на этом маленьком отрезке спектр резко изменится, так что результат получится вполне удовлетворительный.
Теперь рассмотрим сам алгоритм. Его главной частью является уже знакомый нам алгоритм "fft" для N, равного степени двойки. Этот алгоритм лишь немного модифицирован. Из исходной последовательности длиной N выбирается L элементов, начиная от элемента с номером h (0 ≤ h < M) и с шагом M. В результате получается последовательность из L элементов. Так как L у нас - степень двойки, мы можем применить к полученной последовательности обычный алгоритм БПФ. Результаты преобразования записываются в те же ячейки, откуда были взяты. Изменение алгоритма заключается всего лишь в том, что каждый раз вместо g-го элемента берется элемент с номером h + gM, то есть, выполняется замена индексов по формуле:
g → h + gM (38)
Позднее мы еще дополнительно оптимизируем этот алгоритм, а пока выпишем его результат в виде формулы:
 (39)
(39)
Где g = 0, 1,..., L - 1. Как видите, по сравнению с формулой (1) мы выполнили замену переменных: k → g, n → l, N → L и сделали преобразование индексов по формуле (38).
На первом этапе модифицированный алгоритм БПФ применяется ко всем элементам исходной последовательности. Для этого вычисление по формуле (38) выполняется для h = 0, 1,..., M - 1. Каждое такое вычисление меняет L элементов с индексами h, h + M, h + 2M,..., h + (L - 1)M. Таким образом, вызвав M раз этот алгоритм, мы изменим все N = ML элементов заданной последовательности:
Шаг 0: элементы с номерами 0, M, 2M,... (L-1)M
Шаг 1: элементы с номерами 1, 1 + M, 1 + 2M,... 1 + (L-1)M
Шаг 2: элементы с номерами 2, 2 + M, 2 + 2M,... 2 + (L-1)M
...
Шаг M-1: элементы с номерами M - 1, M - 1 + M, M - 1 + 2M,... M - 1 + (L-1)M
На втором этапе заводится новый массив размером в N элементов, и к нему применяется формула:
 (40)
(40)
В двойном цикле величина s проходит значения 0..M - 1, а величина r проходит значения 0..L - 1. Общее число итераций, таким образом, равно ML = N. Каждая итерация требует суммирования M элементов. То есть, общее количество слагаемых равно NM. На предварительном этапе мы M раз применили обычный алгоритм БПФ для L элементов, который, как мы уже знаем, имеет сложность L log2L. Таким образом, общая сложность алгоритма равна:
NM + L log2L = N(N/L) + ML log2L = N2/L + N log2L.
Тем самым, мы доказали формулу сложности, приведенную в начале главы.
Теперь нам осталось доказать только то, что формула (40) действительно дает ДПФ. Для этого подставим формулу (39) в формулу (40):

... поскольку выражение 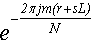 не зависит от l, то мы его можем внести под знак внутренней суммы:
не зависит от l, то мы его можем внести под знак внутренней суммы:

... теперь учтем, что L = N/M, чтобы привести выражение в показателе степени к общему знаменателю и упростить:

... теперь воспользуемся Теоремой 0, чтобы добавить полезный множитель, равный единице:

... теперь воспользуемся равенством N = ML, чтобы разбить сумму в числителе на множители:

... теперь выполним замену переменных r + sL → k, m + lM → n:

Эта сумма эквивалентна сумме (1), с точностью до перемены мест слагаемых. В самом деле, если n = m + lM, m = 0..M - 1, l = 0..L - 1, N = LM, то переменная n по мере суммирования принимает все значения от 0 до N - 1 ровно по одному разу. Что и требовалось доказать.
Настало время написать и оптимизировать алгоритм. Посмотрите на исходный алгоритм "fft" и на алгоритм для случая четного N "fft2".
Здесь мы рассмотрим листинг "fft2" сверху вниз, комментируя все детали.
Сверху вы видите фрагмент, совпадающий со старым листингом вплоть до #define M_2PI. Этот макрос определяет константу 2π.
Функция complex_mul выполняет умножение комплексных чисел z1 и z2 и записывает результат в ячейку z.
Мы собираемся вызывать алгоритм "fft" M раз для одного и того же числа элементов L. Для оптимизации мы должны вынести за пределы алгоритма "fft" те действия, которые не зависят от выбора конкретных элементов в массиве.
К таким действиям можно отнести выделение памяти для хранения поворачивающих множителей и освобождение ее. Деление результата на N также можно выполнить позже для всего массива сразу. А главное, мы можем всего лишь однажды вычислить все поворачивающие множители. Для решения этой задачи мы напишем отдельную функцию createWstore, которая и вычисляет множители, и выделает массив ячеек памяти для них. Позднее этот массив будет передаваться как параметр в новый вариант алгоритма "fft".
Функция createWstore представляет собой ту часть основного цикла "fft", которая отвечала за рассчет поворачивающих множителей. Однако, она оптимизирована. Число итераций меньше, чем в исходном алгоритме, поскольку не на всех итерациях выполнялось вычисление нового множителя, иногда происходило только копирование. Поэтому шаг приращений индекса в массиве вдвое больше: Skew2 вместо Skew. Переменная k для определения четности/нечетности нам больше не нужна, так что внутренний цикл останавливается при достижении границы массива WstoreEnd.
Порядок вычисления множителей  будет понятнее на примере. Если L = 32, то порядок изменения k такой (точкой с запятой разделены итерации внешнего цикла, а запятой - внутреннего):
будет понятнее на примере. Если L = 32, то порядок изменения k такой (точкой с запятой разделены итерации внешнего цикла, а запятой - внутреннего):
k = 0; 16; 8, 24; 4, 12, 20, 28; 2, 6, 10, 14, 18, 22, 26; 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23...31
Далее, вместо старого алгоритма "fft" мы напишем новый - "fft_step" с учетом того, что поворачивающие множители считать не надо, и не надо делить результат на N.
Сам алгоритм практически не изменился за исключением того, что все расстояния между элементами массива увеличились в M раз, согласно формуле (38). Приставка "M" перед именами новых переменных означает умножение на M.
На вход этой функции будет передаваться массив со смещением. Тем самым происходит коррекция индекса на +h элементов, согласно формуле (38).
В основной функции сначала анализируется параметр N. Если он нечетный, то мы вынуждены отсечь один элемент (последний) и уменьшить N на единицу. Таким образом, на входе алгоритма требуется N ≥ 2.
Далее вычисляется L как максимальная степень двойки, кратная N, сама эта степень T и величина M.
Затем вычисляются поворачивающие множители для "fft_step" и вызывается сам "fft_step" нужное число раз. Если оказывается, что N является степенью двойки, то сработает обычный "fft".
Следующим шагом мы вычисляем поворачивающие коэффициенты уже для формулы (40). Этот фрагмент алгоритма очень похож на createWstore, поэтому в дополнительных комментариях не нуждается. Результат оказывается в массиве mult.
Далее вычисляется формула (40). Смысл переменных: pX - указатель на Xr+sL; rpsL = r + sL; mprM = m + rM; one - очередное слагаемое суммы (40).
Величина widx равна остатку от деления m(r + sL) на N. Таким способом мы избегаем выхода за границы массива mult. Это можно делать, благодаря Теореме 1 - ведь поворачивающие множители как раз имеют период N.
Еще можно заметить, что в сумме (40) в первом множителе поворачивающий коэффициент всегда равен 1, благодаря чему мы экономим несколько умножений.
И наконец, происходит корректировка результатов для обратного ДПФ делением на N.
Функция БПФ для четного N называется "fft2".
Пусть N = PQ. Этот представляет собой более общий случай, чем рассмотренный в предыдущей главе. Теперь не требуется, чтобы P или Q были степенями двойки.
Напомним основную формулу:
 (1).
(1).
Рассмотрим формулу:
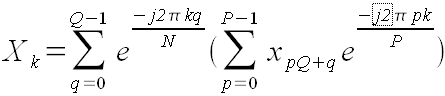 (41).
(41).
Эта формула эквивалентна формуле (1). В самом деле:
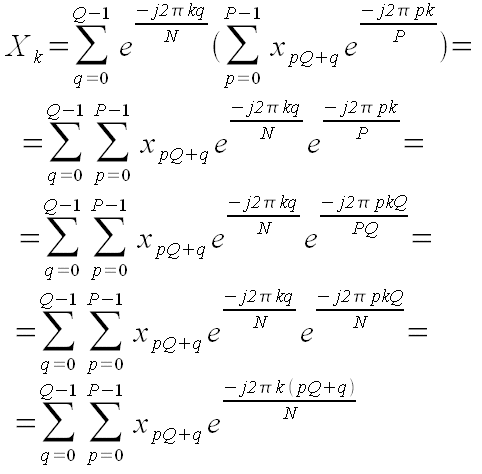
Двойная сумма по pQ + q - это все равно, что одинарная сумма по n, просто порядок слагаемых другой.
Вернемся к формуле (41). В скобках там стоит обычное прямое БПФ, только не для всех xn, а для последовательности из P штук, взятых с шагом Q. Количество последовательностей равно Q. Элементы последовательности выбираются формулой xpQ + q, где p - номер элемента, q - номер последовательности.
Пусть мы умеем вычислять БПФ для P элементов за время Z(P). Нам понадобится вычислить Q таких БПФ, на что потратим время O(QZ(P)). Тем самым мы получим все множители в скобках из формулы (41). После этого надо будет вычислить N элементов Xk, каждый из которых потребует O(Q) действий, итого потребуется еще O(NQ) действий, а в сумме - O(QZ(P) + QN) действий.
В предыдущем алгоритме P - было степенью двойки, а для такого числа элементов мы умеем вычислять БПФ за O(Plog2P) шагов, т.е. Z(P) = Plog2P, и получится O(QZ(P) + QN) = O(QPlog2P + QN) = O(Nlog2P + N2/P) действий. Тем самым, мы несколько более простым путем получим ту же оценку сложности алгоритма.
Если P - не степень двойки, мы умеем вычислять ПФ за O(P2) шагов, т.е. Z(P) = P2, и получится O(QZ(P) + QN) = O(QP2 + QN) = O(N2/Q + N2/P) действий. Если P и Q достаточно велики, это лучше, чем O(N2).
В "Википедии" нашелся алгоритм сложности O(Nlog2N)для произвольного N. Алгоритм основан на значительном увеличении числа элементов последовательности и дополнении ее нулями. Хотя такое расширение, естественно, будет компенсироваться высокой скоростью алгоритма.
Длина последовательности берется равной N', где N' - степень двойки ближайшая сверху к 2N. То есть, 4N > N' = 2T ≥ 2N. Т.е. число элементов новой последовательности в худшем случае может превышать число элементов исходной последовательности почти в 4 раза. Например, если N = 9, то N' = 32.
Обозначим

Представим формулу (1) в виде:
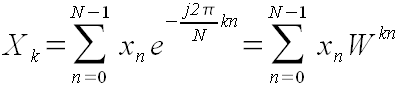
Преобразуем степень:
kn = 2kn/2 = (−k2 + k2 + 2kn + n2 − n2)/2 = (−k2 + (k + n)2 − n2)/2
Это используем для дальнейшего преобразования формулы (1):

Далее введем обозначения:
x'n = xnW −n2/2
X'k = XkW k2/2
Для n > N, полагаем xn = 0.
Тогда
 (42)
(42)
И далее авторы алгоритма выполняют виртуозный "финт ушами". Пусть:
zk = (2N − 2 − k)
wn = W zn2/2
И превращают формулу (42) в:
 (43)
(43)
Проверим:
wzk − n = W (zzk − n)2/2 = W (2N − 2 − (zk − n))2/2 = W (2N − 2 − zk + n)2/2 = W (2N − 2 − (2N − 2 − k) + n)2/2 = W (2N − 2 − 2N + 2 + k + n)2/2 = W (k + n)2/2
Правая часть формулы (43) является дискретной сверткой. В общем случае формула свертки имеет вид:
 (44)
(44)
где f и g - функции от целых переменных (т.е. дискретные функции). В данном случае роль таких функций играют x'n и wn, которые "зависят" от своих индексов как от целых переменных. Свертка обладает замечательным свойством:
F(f * g) = F(f) F(g) (45)
где F(f) - это дискретная функция, которая получается из дискретной функции f с помощью быстрого преобразования Фурье.
Дальнейший порядок вычисления таков. Сначала надо вычислить F(x'), то есть взять набор x'n и вычислить БПФ для n = 0...N' − 1. Затем вычислить F(w), для чего взять набор wn и вычислить БПФ для n = 0...N' − 1. Потом по формуле (45) простым перемножением получаем F(x' * w) = F(x') F(w). Просто берем i-й элемент, полученный после БПФ набора x'n, и умножаем на i-й элемент, полученный после БПФ набора wn. В результате получим БПФ свертки x' * w. Теперь у нас есть БПФ свертки, из него надо получить саму свертку. Для этого применяем обратное преобразование Фурье. Теперь нам надо найти X'k. Для этого используем формулу (43). k-й элемент набора Xk будет соответствовать zk-му элементу свертки. Наконец, останется перейти от X'k к Xk.
В процессе вычислений мы применяли алгоритмы порядка сложности N, N' и N'log2N' (когда делали три БПФ). Поскольку N' не может превышать N более, чем в 4 раза, то весь алгоритм имеет сложность O(Nlog2N)
Обратное преобразование требует величины W без минуса в показателе и в конце алгоритма - деления всех полученных элементов на N. Три алгоритма БПФ остаются в этом случае теми же: два прямых перобразования и одно обратное.
На следующей страничке приведен листинг программы, выполняющей прямое и обратное преобразования по этому алгоритму. Оптимизация выполнена примерно теми же способами, что и в предыдущем случае с незначительными модификациями. Переменные x' в алгоритме обозначаются как x_, 2N как N2, N' как N_, zk как N22, π/N (или −π/N при обратном преобразовании) как piN.






