Кодирование текстовой информации
Всякий текст состоит из символов — букв, цифр, знаков препинания, которые человек различает по начертанию. Для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые (кодировочные) таблицы, в которых каждому коду ставится в соответствие изображение символа.
В программировании наиболее часто используются однобайтовые кодировки, в которых код каждого символа занимает ровно 1 байт (или 8 бит). Общее количество различных символов в таком случае составляет 256.
Кодировка ASCII
Наиболее распространенной системой байтового кодирования является система (таблица) ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией), созданная в 1963 году.
В своей первоначальной версии это система семибитного кодирования. Она ограничивалась одним естественным алфавитом (английским), цифрами и набором различных символов, включая «символы пишущей машинки» (привычные знаки препинания, знаки математических действий и др.) и «управляющие символы». В следующей версии фирма IBM перешла на расширенную 8-битную кодировку.
В таблице ASCII всего 256 позиций. Каждому двоичному коду от 0 до 255 в таблице ставится в соответствие один символ. Сама таблица делится на две части. Первая часть с 0-го по 127-й символ называется основной таблицей ASCII и является неизменной для всех стран. Первые 32 символа в основной таблице являются управляющими. Среди них есть символы, не имеющие изображения, например, «подача стандартного звукового сигнала» (код 7), «перевод строки» (код 10) и т.п. Другие символы основной таблицы являются «изображаемыми». Начиная с 33-его (пробела с кодом 32) по 127 символ в таблице закодированы знаки препинания, цифры и английские буквы – как строчные, так и заглавные.
Таблица ASCII — первая неизменная часть:


Вторая часть – до 255-го символа – называется расширенной таблицей ASCII, она уникальна для каждой страны, так как в этой части хранятся символы, специфичные для этой страны, например буквы национального алфавита. Причем даже в одной и той же стране расширенная часть кодировочной таблицы может быть разной, в зависимости от производителя программного обеспечения.
Пример второй части кодовой таблицы для русской кодировки СР-866:

Кодировка UNICODE
К концу 1980-х годов стандартом стали 8-битные коды, при этом существовало множество разных 8-битных кодировок и постоянно появлялись все новые. Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример — появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437). В результате появилась необходимость решения нескольких задач:
- Проблема «кракозябр» (отображения документов в неправильной кодировке).
- Проблема ограниченности набора символов.
- Проблема преобразования одной кодировки в другую.
Было признано необходимым создание единой «широкой» кодировки фиксированной ширины. Использование 32-битных кодов казалось слишком расточительным, поэтому было решено использовать 16-битные коды.
Первая версия «Юникода» представляла собой кодировку с фиксированным размером кода в 16 бит, общее число кодов в ней было 216 (65 536).
Полная 32-битная таблица «Юникод» включает символы практически всех современных письменностей. С академическими целями в эту кодировочную таблицу добавлены многие исторические письменности, в том числе: руны, древнегреческая письменность, египетские иероглифы, клинопись, письменность майя, этрусский алфавит. В «Юникоде» представлен широкий набор математических и музыкальных символов, а также пиктограмм.
RGB-модель
В компьютере для хранения изображений и вывода их на монитор используется цветовая RGB-модель (R ed – G reen – B lue; красный – зеленый – синий). Как известно из курса физики, смешением красного, зеленого и синего можно синтезировать все остальные цвета, поэтому эти три цвета принимаются в качестве базисных. Пространство цветовой модели RGB можно представить единичным кубом, где интенсивности (яркости) базовых цветов образуют оси координат и их значения – это вещественные числа в диапазоне от 0 до 1.
CMYK-модель
Базовыми цветами CMYK-модели (C yan – M agenta – Y ellow – blac K) являются голубой, пурпурный и желтый. Такая модель применяется в цветных принтерах и офсетной печати среднего и низкого качества. Если под микроскопом рассмотреть цветные иллюстрации в книге, то можно увидеть, что они напечатаны очень маленькими, частично перекрывающимися точками – офсетами. Офсеты хорошо видны на границах цветной печати и в местах с бледной краской.
Главной причиной появления CMYK-модели является различие в принципах формирования цвета при его воспроизведении на мониторах и при печати. Если вы возьмете краски и смешаете красную и зеленую краску, то в действительности получите темно-коричневую краску, а не желтую, как ожидалось (и как это предполагается в RGB-модели). Все дело в том, что когда мы смотрим на изображение на экране монитора, то видим излучаемый свет, а вот когда рассматриваем картинки на бумаге, то видим свет отраженный.
Основные цвета CMYK-модели подобраны так, чтобы соответствующие краски поглощали свет в достаточно узкой области спектра: голубая краска сильно поглощает красный цвет, пурпурная – зеленый, а желтая – синий.
В идеальном случае голубого, пурпурного и желтого цветов было бы достаточно для формирования на бумаге любого цвета. Однако реально существующие краски не идеальны, они не могут поглотить цветовые компоненты полностью. Если нанести все три краски на бумагу, то вместо чисто-черного получится темно-серый цвет. Поэтому, чтобы скорректировать цветовую гамму, используют четвертую краску – черную.
Пространство цветовой модели CMYK также можно представить единичным кубом, где плотность закраски (или яркость базовых цветов) – это вещественные числа в диапазоне от 0 до 1.

Цветовая модель HSB
Модель HSB (H ue – S aturation – B rightness) описывает цветовое пространство через такие характеристики цвета, как цветовой оттенок, насыщенность и яркость.
| Определение. Чистый цветовой фон – один из цветов спектрального разложения света. Цветовой оттенок – смесь чистого тона с серым цветом. Насыщенность цвета, или степень чистоты цвета, – доля чистого тона в цветовой смеси (чем больше серого, тем меньше насыщенность). Яркость характеризуется общей светлостью смешиваемых цветов (чем больше черного, тем меньше яркость).
|
В модели HSB цвет описывается тройкой чисел (цветовой оттенок, яркость, насыщенность). Рассмотрим ряд цветов: красный, темно-красный, красновато-черный, алый, розовый, бледно-розовый. В модели HSB эти цвета – производные от красного цвета и отличаются друг от друга только яркостью и насыщенностью красного оттенка. Такое описание цвета (в отличие от моделей RGB и CMYK) очень точно передают субъективное восприятие цвета человеком, а не технические особенности воспроизведения цветов.
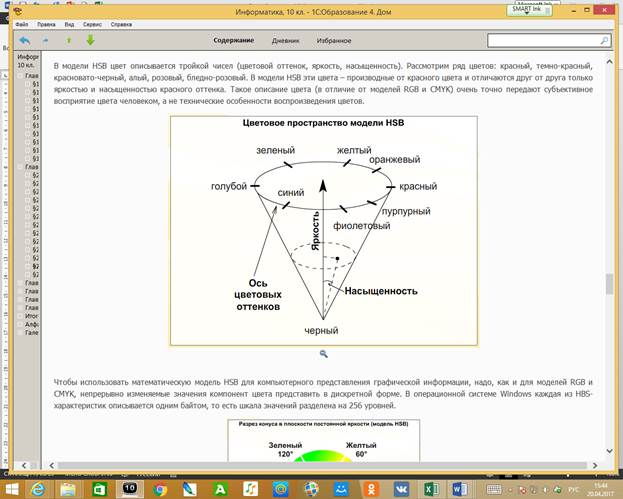
Чтобы использовать математическую модель HSB для компьютерного представления графической информации, надо, как и для моделей RGB и CMYK, непрерывно изменяемые значения компонент цвета представить в дискретной форме. В операционной системе Windows каждая из HBS-характеристик описывается одним байтом, то есть шкала значений разделена на 256 уровней.

Звук
| Определение. Звук – это волновые колебания в упругой среде (в воздухе, воде, металле и т.п.). Для обозначения звука часто используется термин звуковая волна.
|
Основными параметрами любой волны и звуковой в частности, является частота и амплитуда колебаний. Частота звука измеряется в герцах (Гц, количество колебаний в секунду). Человеческое ухо способно воспринимать звук в достаточно широком диапазоне частот: от 16 Гц до 20кГц. В нетехнических областях (например, в музыке) вместо термина частота используют термин тон.
Амплитуда звуковых колебаний характеризует воспринимаемую громкость звука и называется звуковым давлением или силой звука. Абсолютную величину звукового давления измеряют в единицах давления паскалях (Па).
Человеческое ухо может воспринимать огромный разброс значений амплитуды звуковой волны. Порог слышимости – самые слабые различимые человеческим ухом звуки – имеют амплитуду колебаний около 20 мкПа. Самые сильные звуки, которые еще не травмируют органы слуха, могут иметь амплитуду до 200 Па. Звуковая волна такой силы называется болевым порогом.
В силу строения человеческого уха увеличение амплитуды в десятки раз человеком воспринимается как незначительное увеличением силы звука. Поэтому на практике для измерения амплитуды звука обычно используется адаптированная для человека логарифмическая шкала децибелов.
Эта шкала работает с относительной силой звука, или уровнем звука. Уровень звука определяют как логарифм отношения абсолютной величины звукового давления к величине порога слышимости, скорректированный с помощью специального коэффициента: L = 20lg(Pзв/Pпс), где L – это величина звука, измеряемая в децибелах (дБ).
Приведем некоторые значения уровней звука:
| Порог слышимости
| 0 дБ
|
| Шорох листьев, шум слабого ветра
| 10–20 дБ
|
| Шепот (например, на задней парте)
| 20–30 дБ
|
| Разговор средней громкости
| 50–60 дБ
|
| Автомагистраль с интенсивным движением
| 80–90 дБ
|
| Авиадвигатели
| 120–130 дБ
|
| Болевой порог
| 140 дБ
|

Понятие звукозаписи
Люди давно научились записывать различные звуки и потом воспроизводить их. Сам процесс сохранения информации о параметрах звуковых волн называется звукозаписью. Сначала люди освоили аналоговые способы записи и хранения звуковой информации. При аналоговой записи на носителе размещается непрерывный «слепок» звуковой волны. Например, на музыкальные пластинки наносится непрерывная канавка, изгибы которой повторяют амплитуду и частоту звука, на магнитофонной ленте параметры звука сохраняются в виде намагниченности рабочей поверхности, намагниченность поверхности непрерывно изменяется, повторяя параметры звука.
С появлением компьютеров люди захотели хранить звук в компьютере и воспроизводить его с помощью ЭВМ. Однако аналоговая запись не подошла для такого хранения. В компьютере используется только цифровая форма записи звука. При цифровой записи звук необходимо подвергнуть подготовительным процедурам, а именно временной дискретизации и квантованию. Дискредитация выполняется для того, чтобы от бесконечного количества информации, которое содержит звук, перейти к конечному количеству информации.
При цифровой звукозаписи значения амплитуды звукового сигнала измеряются не непрерывно, а через равные небольшие промежутки времени (временная дискретизация) и записываются с некоторой точностью, то есть округляются до некоторого значения – уровня, на которые предварительно разбивается диапазон всех возможных значений (квантование). Из-за этих процедур цифровая запись, в отличие от аналоговой, несет двойное искажение. Во-первых, теряется информация о реальном значении амплитуд в моменты времени между замерами, а во-вторых, сами измеренные значения записываются с некоторой точностью.
В компьютер приходит не сам звук, а электрический сигнал, снимаемый с какого-либо устройства: микрофона, преобразующего звуковое давление в электрические колебания, магнитофона, радио, эхолота или любого другого устройства, вырабатывающего электрические сигналы. Электрические сигналы переводятся в цифровую запись способом импульсно-кодовой модуляции.

Импульсно-кодовая модуляция
Импульсно-кодовая модуляция (англ. P ulse C ode M odulation, PCM) заключается в том, что звуковая информация хранится в виде значений амплитуды, взятых в определенные моменты времени (измерения проводятся «импульсами»).
Процесс получения цифровой формы звука называют оцифровкой. Преобразование аналоговой информации, получаемой от различных источников, производится в специальных устройствах – аналого-цифровых преобразователях. Сигнал, полученный от микрофона или другого устройства, можно образно представить в виде графика кривой. Для преобразования кривая разбивается на несколько равных участков, и значение сигнала на границе каждого участка (в опорных точках) заносится в память компьютера.
При обратном преобразовании, которое реализуется в цифроаналоговом преобразователе (ЦАП), сигнал «восстанавливается» по тем значениям, которые зафиксированы в памяти компьютера. Качество восстановленного сигнала во многом зависит от способа разбиения. Чем чаще расположены опорные точки, тем меньше будет искажен восстановленный сигнал, но при этом выше затраты ресурсов памяти. Количество интервалов разбиения, размещенных на промежутке длительностью в одну секунду, характеризуется частотой дискретизации.
Второй причиной серьезного искажения сигнала может быть количество битов, отведенных для записи значения сигнала. Если для записи отведено только 4 бита, то можно записать только 16 уровней, для высококачественной записи необходимо использовать 1 байт (256 уровней) или 2 байта и выше. Этот параметр преобразования характеризуется разрядностью преобразования. Количество бит, которые используются для записи номеров подуровней, называется глубиной кодирования звука.
Импульсное кодирование по сути можно сравнить с растровым представлением изображения:
· структура звука при таком способе кодирования не анализируется, так же как и структура изображения при растровом представлении;
· время (в графических изображениях – пространство) изначально разбивается на небольшие области, и в пределах каждой области параметры звука (изображения) считаются постоянными.
Растровое представление изображений не требует хранения координат каждого пикселя. Аналогично при сохранении импульсного представления звука один раз сохраняются параметры оцифровки (глубина кодирования, частота дискретизации и длительность звукового фрагмента), а затем требуется сохранять только номера подуровней единым потоком.
Очевидно, что если увеличивать частоту дискретизации и глубину кодирования, то впоследствии можно будет более точно восстановить форму звукового сигнала. Однако, при повышении таким образом качества записи ее объем будет увеличиваться. Поэтому возникает вопрос, какими должны быть частота дискретизации и глубина кодирования, чтобы получить оптимальное соотношение объема файла и качества воспроизводимого звука.
В 1928 году американский инженер и ученый Гарри Найквист высказал утверждение, что частота дискретизации должна в два или более раз превышать максимальную частоту измеряемого сигнала. В 1933 году советский ученый В. А. Котельников и независимо от него Клод Шеннон сформулировали и доказали теорему о том, при каких условиях и как по дискретным значениям можно восстановить форму непрерывного сигнала. Эта теорема носит название всех трех ученых, или нейтрально называется Теоремой об отсчетах. Результат применения этой теоремы – частота дискретизации должна быть как минимум вдвое выше частоты сигнала. Теорема доказана для сигналов с непрерывными частотными характеристиками и бесконечной длительностью. Поэтому для оцифровки реальных звуковых сигналов (конечных по времени) частоту дискретизации выбирают с небольшим запасом.

Формат MIDI
В 80-х годах прошлого века появились электронные музыкальные инструменты – синтезаторы, способные воспроизводить не только звуки многих существующих музыкальных инструментов, но и абсолютно новые звуки. Было разработано соглашение о системе команд универсального синтезатора, получившее название стандарта MIDI (от англ. M usical I nstrument D igital I nterface). Запись музыкального произведения в формате MIDI – последовательность закодированных сообщений синтезатору. Сообщение может быть командой (нажать или отпустить определенную клавишу, изменить высоту или тембр звучания), описанием параметров воспроизведения (например, силы давления на клавиатуру) или управляющим сообщением (включение полифонического режима).
MIDI-команды делают запись музыкальной информации более компактной, чем испульсное кодирование. Если сравнить способы представления графической и звуковой информации, то запись звука в виде MIDI-команд соответствует векторному представлению изображения.
Записанные звуковые файлы можно редактировать, то есть вырезать, копировать и вставлять фрагменты из других файлов. Кроме того, можно увеличивать или уменьшать громкость, применять различные звуковые эффекты (эхо, уменьшение или увеличение скорости воспроизведения, воспроизведение в обратном направлении и другое), а также накладывать файлы друг на друга (микшировать).

Кодирование текстовой информации
Всякий текст состоит из символов — букв, цифр, знаков препинания, которые человек различает по начертанию. Для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые (кодировочные) таблицы, в которых каждому коду ставится в соответствие изображение символа.
В программировании наиболее часто используются однобайтовые кодировки, в которых код каждого символа занимает ровно 1 байт (или 8 бит). Общее количество различных символов в таком случае составляет 256.
Кодировка ASCII
Наиболее распространенной системой байтового кодирования является система (таблица) ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией), созданная в 1963 году.
В своей первоначальной версии это система семибитного кодирования. Она ограничивалась одним естественным алфавитом (английским), цифрами и набором различных символов, включая «символы пишущей машинки» (привычные знаки препинания, знаки математических действий и др.) и «управляющие символы». В следующей версии фирма IBM перешла на расширенную 8-битную кодировку.
В таблице ASCII всего 256 позиций. Каждому двоичному коду от 0 до 255 в таблице ставится в соответствие один символ. Сама таблица делится на две части. Первая часть с 0-го по 127-й символ называется основной таблицей ASCII и является неизменной для всех стран. Первые 32 символа в основной таблице являются управляющими. Среди них есть символы, не имеющие изображения, например, «подача стандартного звукового сигнала» (код 7), «перевод строки» (код 10) и т.п. Другие символы основной таблицы являются «изображаемыми». Начиная с 33-его (пробела с кодом 32) по 127 символ в таблице закодированы знаки препинания, цифры и английские буквы – как строчные, так и заглавные.
Таблица ASCII — первая неизменная часть:
Вторая часть – до 255-го символа – называется расширенной таблицей ASCII, она уникальна для каждой страны, так как в этой части хранятся символы, специфичные для этой страны, например буквы национального алфавита. Причем даже в одной и той же стране расширенная часть кодировочной таблицы может быть разной, в зависимости от производителя программного обеспечения.
Пример второй части кодовой таблицы для русской кодировки СР-866:






