где: hwnd – это хэндл ID родительского окна. Хэндл можно считать числом представляющим окно, к которому вы обращаетесь. Когда будет необходимость сделать что-либо с этим окном, необходимо будет обратиться к нему, используя его хэндл;
- lpText – это указатель на текст, который необходимо отобразить в клиентской части окна сообщения. Указатель – это адрес чего-либо. Указатель на текстовую строку - это адрес этой строки;
- lpCaption – это указатель на заголовок окна сообщения;
- uType – устанавливает иконку, число и вид кнопок.
Давайте теперь изменим код нашей программы так, чтобы она выводила сообщение с текстом “Hello World” и заголовком “Моя первая программа” окна – на экран (рис 6.):
Рисунок 6 – Примерный листинг программы, выводящей сообщение с текстом “Hello World” и заголовком “Моя первая программа” окна – на экран
Функция MessageBox приостанавливает выполнение программы и ожидает действия пользователя. По завершении, функция возвращает программе результат действия пользователя, и программа продолжает выполняться.
Перевод текста на следующую строку осуществляется следующим образом:
13 – это код символа “возврата каретки”, в Windows.
db – резервирование памяти для данных размеров 1 байт (числа в диапазоне -128…+127. Для чисел без знака 0 … 255).
dw – резервирование памяти для данных размеров 2 байта (числа в диапазоне -31 768…+32 767. Для чисел без знака 0 … 65 535).
dd – резервирование памяти для данных размеров 4 байта (числа в диапазоне -2147483648…+2 147 483 647. Для чисел без знака 0 …4 294 967 295).
dq – резервирование памяти для данных размеров 8 байт (числа в диапазоне -2 147 483 648…+2 147 483 647. Для чисел без знака 0 …4 294 967 295).
В данном случае память резервируется для переменных lpText и lpCaption.
Скомпилируйте и запустите.
 В результате выполнения программы появится окошко с сообщение “Hello world“ (рис 7).
В результате выполнения программы появится окошко с сообщение “Hello world“ (рис 7).
Рисунок 7 – Результат выполнения программы
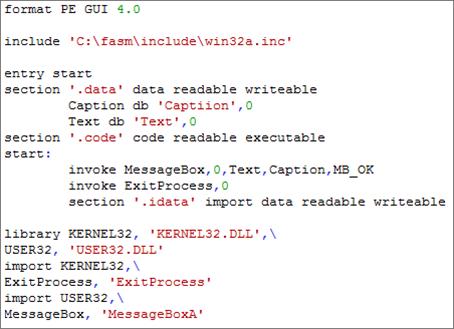
Чтобы лучше понять, на сколько, важно использовать макро вставки – внимательно изучите эквивалентный код (рис. 8):
Рисунок 8 – Код приложения без использования макроинструкций
Для компилятора он практически идентичен предыдущему примеру, но для нас этот текст выглядит уже другой программой.
Попробуем разобраться в отличиях. Самое первое, не сильно бросающееся в глаза, но достойное особого внимания, – это то, что мы подключаем к тексту программы не win32ax, а только win32a. Мы отказались от большого набора и ограничиваемся малым. Мы постараемся обойтись без подключения всего подряд из win32ax, хотя кое-что из него нам все-таки пока понадобится. Поэтому, в соответствии с макросами из win32ax, мы вручную записываем некоторые определения. Например, макрос из файла win32ax:
macro.data{section ‘.data’ data readable writeable}
Компилятор во время компиляции автоматически заменяет .data на section ‘ .data ’ data readable writeable.
Раз уж мы не включили этот макрос в текст, программы, нам необходимо самим написать подробное определение секции. По аналогии вы можете найти причины остальных видоизменений текста программы во втором примере. Макросы помогают избежать рутины при написании больших программ.
Компиляция программы в Fasm состоит из 2 стадий: препроцессирование и ассемблирование.
Препроцессирование. На стадии препроцессорараскрываются все макросы, символические константы, обрабатываются директивы препроцессора. В отличие от ассемблирования - препроцессирование выполняется только 1 раз.
Ассемблирование. На стадии ассемблирования определяются адреса меток, обрабатываются условные директивы, раскрываются циклы и генерируется собственно программа. Fasm – многопроходной ассемблер, что позволяет делать ему некоторую оптимизацию, например, генерирование короткого перехода на метку вместо длинного.
Типы данных
При программировании на языке ассемблера используются данные следующих типов:
1. Непосредственные данные, представляющие собой числовые или символьные значения, являющиеся частью команды.
Непосредственные данные формируются программистом в процессе написания программы для конкретной команды ассемблера.
2. Данные простого типа, описываемые с помощью ограниченного набора директив резервирования памяти, позволяющих выполнить самые элементарные операции по размещению и инициализации числовой и символьной информации. При обработке этих директив ассемблер сохраняет в своей таблице символов информацию о местоположении данных (значения сегментной составляющей адреса и смещения) и типе данных, то есть единицах памяти, выделяемых для размещения данных в соответствии с директивой резервирования и инициализации данных.
Эти два типа данных являются элементарными, или базовыми; работа с ними поддерживается на уровне системы команд микропроцессора. Используя данные этих типов, можно формализовать и запрограммировать практически любую задачу. Но насколько это будет удобно — вот вопрос.
3. Данные сложного типа, которые были введены в язык ассемблера с целью облегчения разработки программ. Сложные типы данных строятся на основе базовых типов, которые являются как бы кирпичиками для их построения. Введение сложных типов данных позволяет несколько сгладить различия между языками высокого уровня и ассемблером. У программиста появляется возможность сочетания преимуществ языка ассемблера и языков высокого уровня (в направлении абстракции данных), что в конечном итоге повышает эффективность конечной программы.
Обработка информации, в общем случае, процесс очень сложный. Это косвенно подтверждает популярность языков высокого уровня. Одно из несомненных достоинств языков высокого уровня — поддержка развитых структур данных. При их использовании программист освобождается от решения конкретных проблем, связанных с представлением числовых или символьных данных, и получает возможность оперировать информацией, структура которой в большей степени отражает особенности предметной области решаемой задачи. В то же самое время, чем выше уровень такой абстракции данных от конкретного их представления в компьютере, тем большая нагрузка ложится на компилятор с целью создания действительно эффективного кода. Ведь нам уже известно, что в конечном итоге все написанное на языке высокого уровня в компьютере будет представлено на уровне машинных команд, работающих только с базовыми типами данных. Таким образом, самая эффективная программа — программа, написанная в машинных кодах, но писать сегодня большую программу в машинных кодах — занятие не имеющее слишком большого смысла.
Синтаксис ассемблера
Предложения, составляющие программу, могут представлять собой синтаксическую конструкцию, соответствующую команде, макрокоманде, директиве или комментарию. Для того чтобы транслятор ассемблера мог распознать их, они должны формироваться по определенным синтаксическим правилам. Для этого лучше всего использовать формальное описание синтаксиса языка наподобие правил грамматики. Наиболее распространенные способы подобного описания языка программирования — синтаксические диаграммы и расширенные формы Бэкуса—Наура. Для практического использования более удобны синтаксические диаграммы. К примеру, синтаксис предложений ассемблера можно описать с помощью синтаксических диаграмм, показанных на следующих рисунках.

Рис. 9 - Формат предложения ассемблера

Рис. 10 - Формат директив

Рис. 11 - Формат команд и макрокоманд
На этих рисунках:
· имя метки — идентификатор, значением которого является адрес первого байта того предложения исходного текста программы, которое он обозначает;
· имя — идентификатор, отличающий данную директиву от других одноименных директив. В результате обработки ассемблером определенной директивы этому имени могут быть присвоены определенные характеристики;
· код операции (КОП) и директива — это мнемонические обозначения соответствующей машинной команды, макрокоманды или директивы транслятора;
· операнды — части команды, макрокоманды или директивы ассемблера, обозначающие объекты, над которыми производятся действия. Операнды ассемблера описываются выражениями с числовыми и текстовыми константами, метками и идентификаторами переменных с использованием знаков операций и некоторых зарезервированных слов.
Как использовать синтаксические диаграммы?
Очень просто: для этого нужно всего лишь найти и затем пройти путь от входа диаграммы (слева) к ее выходу (направо). Если такой путь существует, то предложение или конструкция синтаксически правильны. Если такого пути нет, значит эту конструкцию компилятор не примет. При работе с синтаксическими диаграммами обращайте внимание на направление обхода, указываемое стрелками, так как среди путей могут быть и такие, по которым можно идти справа налево. По сути, синтаксические диаграммы отражают логику работы транслятора при разборе входных предложений программы.
Допустимыми символами при написании текста программ являются:
1. все латинские буквы: A—Z, a—z. При этом заглавные и строчные буквы считаются эквивалентными;
2. цифры от 0 до 9;
3. знаки?, @, $, _, &;
4. разделители,. [ ] () < > { } + / * %! ' "? \ = # ^.
Предложения ассемблера формируются из лексем, представляющих собой синтаксически неразделимые последовательности допустимых символов языка, имеющие смысл для транслятора.
Лексемами являются:
· идентификаторы — последовательности допустимых символов, использующиеся для обозначения таких объектов программы, как коды операций, имена переменных и названия меток. Правило записи идентификаторов заключается в следующем: идентификатор может состоять из одного или нескольких символов. В качестве символов можно использовать буквы латинского алфавита, цифры и некоторые специальные знаки — _,?, $, @. Идентификатор не может начинаться символом цифры. Длина идентификатора может быть до 255 символов, хотя транслятор воспринимает лишь первые 32, а остальные игнорирует. Регулировать длину возможных идентификаторов можно с использованием опции командной строки mv. Кроме этого существует возможность указать транслятору на то, чтобы он различал прописные и строчные буквы либо игнорировал их различие (что и делается по умолчанию). Для этого применяются опции командной строки /mu, /ml, /mx;
· цепочки символов — последовательности символов, заключенные в одинарные или двойные кавычки;
· целые числа в одной из следующих систем счисления: двоичной, десятичной, шестнадцатеричной. Отождествление чисел при записи их в программах на ассемблере производится по определенным правилам:
§ Десятичные числа не требуют для своего отождествления указания каких-либо дополнительных символов, например 25 или 139.
§ Для отождествления в исходном тексте программы двоичных чисел необходимо после записи нулей и единиц, входящих в их состав, поставить латинское “b”, например 10010101b.
§ Шестнадцатеричные числа имеют больше условностей при своей записи:
· Во-первых, они состоят из цифр 0...9, строчных и прописных букв латинского алфавита a, b, c, d, e, f или A, B, C, D, E, F.
· Во-вторых, у транслятора могут возникнуть трудности с распознаванием шестнадцатеричных чисел из-за того, что они могут состоять как из одних цифр 0...9 (например 190845), так и начинаться с буквы латинского алфавита (например ef15). Для того чтобы "объяснить" транслятору, что данная лексема не является десятичным числом или идентификатором, программист должен специальным образом выделять шестнадцатеричное число. Для этого на конце последовательности шестнадцатеричных цифр, составляющих шестнадцатеричное число, записывают латинскую букву “h”. Это обязательное условие. Если шестнадцатеричное число начинается с буквы, то перед ним записывается ведущий ноль: 0ef15h.
Таким образом, мы разобрались с тем, как конструируются предложения программы ассемблера. Но это лишь самый поверхностный взгляд.
Практически каждое предложение содержит описание объекта, над которым или при помощи которого выполняется некоторое действие. Эти объекты называются операндами.
Их можно определить так:
операнды — это объекты (некоторые значения, регистры или ячейки памяти), на которые действуют инструкции или директивы, либо это объекты, которые определяют или уточняют действие инструкций или директив.
Операнды могут комбинироваться с арифметическими, логическими, побитовыми и атрибутивными операторами для расчета некоторого значения или определения ячейки памяти, на которую будет воздействовать данная команда или директива.








