

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Топ:
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Техника безопасности при работе на пароконвектомате: К обслуживанию пароконвектомата допускаются лица, прошедшие технический минимум по эксплуатации оборудования...
Процедура выполнения команд. Рабочий цикл процессора: Функционирование процессора в основном состоит из повторяющихся рабочих циклов, каждый из которых соответствует...
Интересное:
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Искусственное повышение поверхности территории: Варианты искусственного повышения поверхности территории необходимо выбирать на основе анализа следующих характеристик защищаемой территории...
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Базовые понятия реляционных баз данных
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации:

Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как «деньги»), а также специальных «темпоральных» данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных. В примере показаны данные трех типов: строки символов, целые числа и «деньги».
Домен
Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат «истина», то элемент данных является элементом домена.
Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен «Имена» в примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака).
|
|
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В примере значения доменов «Номера пропусков» и «Номера групп» относятся к типу целых чисел, но не являются сравнимыми.
Схема отношения, схема базы данных
Схема отношения – это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Степень или «арность» схемы отношения – мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, то есть оно является 4-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута).
Схема БД (в структурном смысле) – это набор именованных схем отношений.
Кортеж, отношение
Кортеж, соответствующий данной схеме отношения, – это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. «Значение» является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или «арность» кортежа, т.е. число элементов в нем, совпадает с «арностью» соответствующей схемы отношения. Попросту говоря, кортеж – это набор именованных значений заданного типа.
Отношение – это множество кортежей, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят «отношение-схема» и «отношение-экземпляр», иногда схему отношения называют заголовком отношения, а отношение как набор кортежей – телом отношения. На самом деле, понятие схемы отношения ближе всего к понятию структурного типа данных в языках программирования. Было бы вполне логично разрешать отдельно определять схему отношения, а затем одно или несколько отношений с данной схемой.
|
|
Однако в реляционных базах данных это не принято. Имя схемы отношения в таких базах данных всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных.
Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками – кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят «столбец таблицы», имея в виду «атрибут отношения». Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД.
Реляционная база данных – это набор отношений, имена которых совпадают с именами схем отношений в схеме БД.
Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
Реляционная модель данных
Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n -арное отношение.
В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД – реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй – на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
|
|
В целостной части реляционной моделиданных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Например, представим, что требуется представить в реляционной базе данных сущность ОТДЕЛ с атрибутамиОТД_НОМЕР (номер отдела), ОТД_КОЛ (количество сотрудников) и ОТД_СОТР (набор сотрудников отдела). Для каждого сотрудника нужно хранить СОТР_НОМЕР (номер сотрудника), СОТР_ИМЯ (имя сотрудника) и СОТР_ЗАРП (заработная плата сотрудника). При правильном проектировании соответствующей БД в ней появятся два отношения: ОТДЕЛЫ (ОТД_НОМЕР, ОТД_КОЛ) (первичный ключ – ОТД_НОМЕР) и СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ, СОТР_ЗАРП, СОТР_ОТД_НОМ) (первичный ключ – СОТР_НОМЕР).
Как видно, атрибут СОТР_ОТД_НОМ появляется в отношении СОТРУДНИКИ не потому, что номер отдела является собственным свойством сотрудника, а лишь для того, чтобы иметь возможность восстановить при необходимости полную сущность ОТДЕЛ. Значение атрибута СОТР_ОТД_НОМ в любом кортеже отношения СОТРУДНИКИ должно соответствовать значению атрибута ОТД_НОМ в некотором кортеже отношения ОТДЕЛЫ. Атрибут такого рода называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения (т.е. задают значения их первичного ключа). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом.
|
|
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать). Для примера это означает, что если для сотрудника указан номер отдела, то этот отдел должен существовать.
Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа. С целостностью по ссылкам дела обстоят несколько более сложно.
Понятно, что при обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но как быть при удалении кортежа из отношения, на которое ведет ссылка?
Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам:
1. Запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа).
2. При удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным.
3. При удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи(каскадное удаление).
В развитых реляционных СУБД обычно можно выбрать способ поддержания целостности по ссылкам для каждой отдельной ситуации определения внешнего ключа. Конечно, для принятия такого решения необходимо анализировать требования конкретной прикладной области.
Модель «сущность-связь» также полезна для понимания и спецификации ограничений, направленных на поддержание целостности данных. В модели имеется три типа ограничений на значения:
· ограничения на допустимые значения в наборе значений (домене). Домен можно трактовать как область определения атрибута, которая может быть задана либо непрерывным или дискретным интервалом, либо фиксированным списком значений.
· ограничения на разрешенные значения для каждого атрибута. Например, возраст сотрудников может быть ограничен интервалом от 18 до 65 лет.
· ограничения на существующие значения в базе данных. Например, сумма отчислений с зарплаты сотрудника не должна превышать самой зарплаты.
|
|
К сожалению, указанные ограничения невозможно представить на диаграмме «сущность-связь».
Пример
Реляционные базы данных состоят из таблиц. Каждая таблица состоит из столбцов (их называют полями или атрибутами) и строк (их называют записями или кортежами). Таблицы в реляционных базах данных обладают рядом свойств. Основными являются следующие:
· В таблице не может быть двух одинаковых строк. В математике таблицы, обладающие таким свойством, называют отношениями (англ.relation), отсюда и название – реляционные.
· Столбцы располагаются в определенном порядке, который создается при создании таблицы. В таблице может не быть ни одной строки, но обязательно должен быть хотя бы один столбец.
· У каждого столбца есть уникальное имя (в пределах таблицы), и все значения в одном столбце имеют один тип (число, текст, дата...).
· На пересечении каждого столбца и строки может находиться только атомарное значение (одно значение, не состоящее из группы значений). Таблицы, удовлетворяющие этому условию, называют нормализованными.
Предположим, что необходимо создать базу данных для форума. У форума есть зарегистрированные пользователи, которые создают темы и оставляют сообщения в этих темах. Эта информация и должна храниться в базе данных. Теоретически (на бумаге) можно все это расположить в одной таблице, например, так:
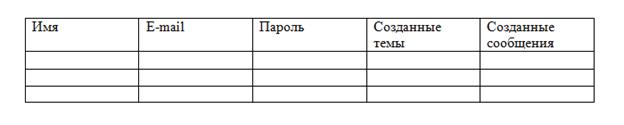
Но это противоречит свойству атомарности (одно значение в одной ячейке), а в столбцах Темы и Сообщения предполагается неограниченное количество значений. Значит, таблицу надо разбить на три: Пользователи, Темы и Сообщения.

Таблица Пользователи удовлетворяет всем условиям. А вот таблицы Темы и Сообщения – нет. Ведь в таблице не может быть двух одинаковых строк, а где гарантия, что один пользователь не оставит два одинаковых сообщения, например:

Кроме того известно, что каждое сообщение обязательно относится к какой-либо теме. А как это можно узнать из данных таблиц? Никак. Для решения этих проблем, в реляционных базах данных существуют ключи. Первичный ключ (РК – primarykey) – столбец, значения которого во всех строках различны. Первичные ключи могут быть логическими (естественными) и суррогатными (искусственными). Так, для таблицы Пользователи первичным ключом может стать столбец e-mail (ведь теоретически не может быть двух пользователей с одинаковым e-mail). На практике лучше использовать суррогатные ключи, т.к. их применение позволяет абстрагировать ключи от реальных данных. Кроме того, первичные ключи менять нельзя, а что если у пользователя сменится e-mail? Суррогатный ключ представляет собой дополнительное поле в базе данных. Как правило, это порядковый номер записи (хотя можно задавать их на свое усмотрение, контролируя, чтобы они были уникальны). Внесем поля первичных ключей в таблицы:


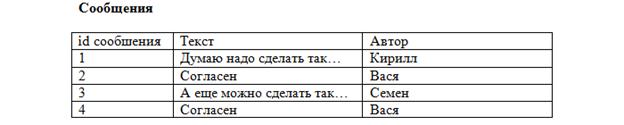
Теперь каждая запись в таблицах уникальна. Осталось установить соответствие между темами и сообщениями в них. Делается это также при помощи первичных ключей. В таблицу сообщения добавим еще одно поле:

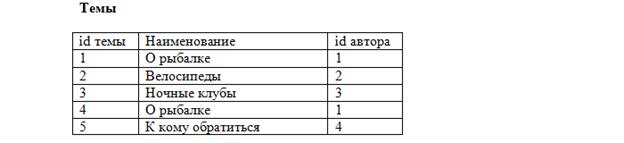
Теперь понятно, что сообщение с id = 2 принадлежит теме «О рыбалке» (id темы = 4), созданной Васей, а остальные сообщения принадлежать теме «О рыбалке» (id темы = 1), созданной Кириллом. Такое поле называется внешний ключ (FK – foreign key). Каждое значение этого поля соответствует какому-либо первичному ключу из таблицы «Темы». Так устанавливается однозначное соответствие между сообщениями и темами, к которым они относятся. Последний нюанс. Предположим, что добавился новый пользователь, и зовут его тоже Вася:

Как узнать, какой именно Вася оставил сообщения? Для этого поля «Автор» в таблицах «Темы» и «Сообщения»сделаем также внешними ключами:

База данных готова. Схематично ее можно представить так:
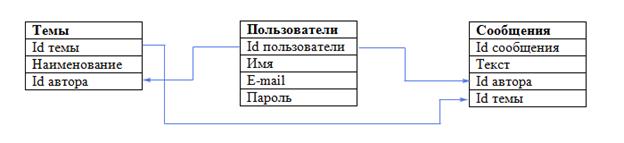
В данной маленькой базе данных всего три таблички, а если бы их было 10 или 100? Понятно, что сразу невозможно представить все таблицы, поля и связи, которые могут понадобиться. Именно поэтому проектирование базы данных начинается с ее концептуальной модели (ER-модели).
6. Преобразование концептуальной модели в реляционную
Преобразование концептуальной модели в реляционную состоит в следующем:
1. Построить набор предварительных таблиц и указать первичные ключи.
2. Провести процесс нормализации.
Первый пункт был рассмотрен ранее, со вторым ознакомимся на практике. Итак, надо построить набор таблиц. Сделать это несложно, т.к. таблицы – это объекты, а поля таблиц – атрибуты объектов.
Концептуальная модель имеет вид:

Набор предварительных таблиц, исходя из концептуальной модели, выглядит так:

Таким образом, определены таблицы, поля, первичные ключи (РК) и связи (FK). Обратите внимание, в таблицах «Журнал поставок» и «Журнал покупок» первичные ключи – составные, т.е. состоят из двух полей. Теоретически бывают таблицы, в которых все поля являются одним составным ключом. Переходим ко второму пункту, а именно к нормализации отношений (таблиц).
Нормализация – это пошаговый, обратимый процесс замены исходной схемы другой схемой, в которой таблицы имеют более простую и логичную структуру.
Для чего это нужно? Во-первых, для устранения избыточности данных. Например, в примере для форума (см. предыдущий раздел), осталась бы вот такая таблица:

В поле «Темы» часто повторяются одни и те же названия. Помимо того, что для их хранения потребуются дополнительные ресурсы памяти, при дублировании информации очень несложно допустить ошибку при вводе значений атрибута, в результате чего БД перейдет в несогласованное состояние. Кроме того, при работе с такими таблицами могут возникнуть так называемые аномалии обновления. Например, если удалить из этой таблицы четвертое сообщение, то вместе с ним пропадет и информация о теме. Такая ситуация представляет собой аномалию удаления. Если изменится название темы, то придется просмотреть все строки и в каждой заменить старую тему на новую. Это так называемая аномалия модификации. Существуют и другие виды аномалий. Далеко не всегда эти недостатки можно учесть сразу. Для их устранения и применяется процесс нормализации. Он включает ряд правил, используемых для проверки всех таблиц базы данных. Различают:
1НФ – первая нормальная форма
2НФ – вторая нормальная форма
3НФ – третья нормальная форма
НФБК – нормальная форма Бойса-Кодда
4НФ – четвертая нормальная форма
5НФ – пятая нормальная форма
Каждая нормальная форма налагает определенные ограничения на данные. Каждая нормальная форма более высокого уровня предполагает, что анализируемая таблица уже находится в нормальной форме на уровень ниже рассматриваемой. В ходе нормализации схема базы данных становится все более строгой, а ее таблицы все менее подвержены различного рода аномалиям. Для реляционных баз данных необходимо, чтобы ее таблицы находились в 1НФ. Нормальные формы более высоких уровней могут использоваться разработчиками по своему усмотрению. Однако грамотный специалист стремится к тому, чтобы довести уровень нормализации базы данных хотя бы до 3НФ, тем самым исключив избыточность данных и аномалии обновления. Надо сказать, что НФБК, 4НФ и 5НФ используются крайне редко. Поэтому рассмотрим только первые три.
Первая нормальная форма
Таблица находится в первой нормальной форме, если все ее поля имеют простые (атомарные) значения. Само понятие атомарности определить достаточно трудно. Значение, атомарное в одном случае, может быть неатомарным в другом. Общий принцип здесь такой: значение не атомарно, если оно используется по частям.
Пример: В таблице «Поставщики» есть поле «Адрес». Если магазин работает только с поставщиками из одного города, то значения поля «Адрес» можно считать атомарными, а саму таблицу –приведенной к 1НФ. Но что если поставщики находятся в разных городах? Тогда, посылая машину за товарами в определенный город, необходимо быть уверенными, что она заберет товары у всех поставщиков, находящихся в этом городе. Т.е. могут понадобиться сведения о поставщиках, находящихся в определенном городе. В этом случае значения в поле «Адрес» уже не являются атомарными (т.к. используется часть адреса), и для приведения таблицы к 1НФ надо выделить еще одно поле – Город:

Подобным образом надо проанализировать все таблицы базы данных. Так, в таблице «Покупатель» есть поле «ФИО». Если планируется, например, поздравлять покупателей с именинами (которые, как известно, зависят от имени), то это поле пришлось бы разбить на три: Фамилию, Имя и Отчество. Данный магазин этого делать не собирается, поэтому поле ФИО можно считать атомарным, а таблицу – приведенной к 1НФ. Для запросов магазина все остальные таблицы приведены к 1НФ.
Вторая нормальная форма
Эта форма применяется к таблицам с составными ключами. Таблица, у которой первичный ключ включает только одно поле, всегда находится во 2НФ. Таблица находится во второй нормальной форме, если она находится в первой нормальной форме, а каждое неключевое поле функционально полно зависит от составного ключа.
В базе данных в примере две таблицы имеют составной ключ –«Журнал покупок» и «Журнал поставок». Значение поля «Количество» зависит как от «Поставки» («Покупки»), так и от «Товара». Значит, данные таблицы находятся во 2НФ. Но предположим, что на этапе концептуального моделирования базы данных не были выделены объекты «Поставка» и «Покупка». Тогда таблицы могли бы выглядеть так:
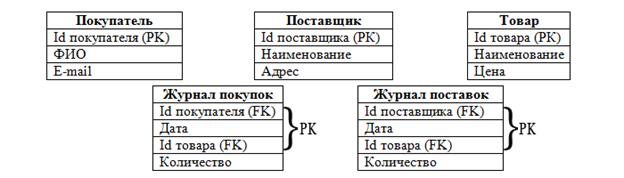
Посмотрим теперь на таблицу «Журнал поставок»: поле «Количество» зависит от «Наименования товара» и от «Даты поставки», но не зависит от того, кто поставил товар (поле «Поставщик»), т.е. таблица не находится во 2НФ. Если бы на этапе концептуального моделирования базы данных не были выделены объекты «Поставка» и «Покупка», необходимо было бы это сделать сейчас. Но поскольку они были выделены, все таблицы находятся во 2НФ.
Третья нормальная форма
Таблица находится в третьей нормальной форме, если она находится во второй нормальной форме, и каждое неключевое поле нетранзитивно зависит от первичного ключа. Транзитивная зависимость наблюдается в том случае, если одно из двух неключевых полей зависит от первичного ключа, а другое зависит от первого неключевого поля.
Пример: Рассмотрим таблицу «Товар». В ней есть поле «Цена», но цены, как известно, имеют свойство меняться. Если мы будем их менять прямо здесь, то будет пропадать вся информация о предыдущих ценах. Чтобы не терять эту информацию, надо добавить поле «Дата» (когда изменилась цена). Тогда таблица будет выглядеть так:

Даже не прибегая к 3НФ видно, что такая таблица будет содержать избыточную информацию. Но посмотрим на ее поля: поля «Наименование» и «Дата» зависят от id товара, а поле «Цена» зависит также и от «Даты», т.е. таблица не находится в 3НФ. Для устранения транзитивной зависимости необходимо провести «расщепление» объекта на два:

Все остальные таблицы базы данных находятся в 3НФ. Кстати, в таблице «Товар» можно было и не вводить поле «id товара», а сделать первичным ключом поле «Наименование», но как уже говорилось ранее суррогатные ключи все-таки предпочтительнее.
Подведем итог. Схема базы данных после нормализации несколько изменилась и выглядит теперь так:
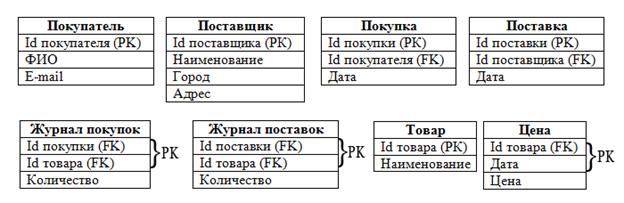
Таким образом, мы преобразовали концептуальную модель в реляционную. Дальше необходимо эту модель реализовать в конкретной СУБД. Для этого нам понадобится сама СУБД и знание языка SQL.
Выводы
Проектирование БД процесс, как правило, трудоемкий и небыстрый. Ведь нужно очень хорошо изучить предметную область, чтобы учесть все нюансы, пожелания и требования пользователей. Затем всю собранную информацию изобразить в виде объектов, атрибутов и связей. Причем сделать это надо наиболее рационально. Да, база данных – это всего лишь хранилище данных, но от того насколько грамотно организовано это хранилище, будет зависеть работа приложения, использующего данные.
Предположим, что необходимо организовать на сайте регистрацию пользователей с тем, чтобы обеспечить им доступ к закрытым материалам сайта. Для реализации этого вопроса потребуется создать БД, которая будет хранить информацию о пользователях, их логинах и паролях. А также сделать html-формы регистрации и входа в закрытый раздел. Когда пользователь регистрируется, эти данные программными средствами (например, с помощью языка PHP) заносятся в созданную БД. Когда пользователь вводит логин и пароль в форме входа в закрытый раздел, к базе данных отправляется запрос (на языке SQL), есть ли пользователь с такими данными. И если ответ положительный, то пользователю посылается запрашиваемая страница (разумеется, тоже с помощью программы на PHP). Таким образом, чтобы реализовывать такие приложения необходимо уметь создавать БД, строить запросы на языке SQL к БД и знать какой-нибудь язык программирования, применимый для разработки динамических web-страниц (например, PHP).
Базовые понятия реляционных баз данных
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации:
Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как «деньги»), а также специальных «темпоральных» данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных. В примере показаны данные трех типов: строки символов, целые числа и «деньги».
Домен
Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат «истина», то элемент данных является элементом домена.
Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен «Имена» в примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака).
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В примере значения доменов «Номера пропусков» и «Номера групп» относятся к типу целых чисел, но не являются сравнимыми.
|
|
|

История развития хранилищ для нефти: Первые склады нефти появились в XVII веке. Они представляли собой землянные ямы-амбара глубиной 4…5 м...

Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!