Исходные данные для даталогического проектирования
Любая СУБД оперирует с допустимыми для нее логическими единицами данных, а также допускает использование определенных правил композиции логических структур более высокого уровня из составляющих информационных единиц более низкого уровня. Кроме того, многие СУБД накладывают количественные и иные ограничения на структуру базы данных. Поэтому прежде чем приступить к построению даталогической модели, необходимо детально изучить особенности СУБД, определить факторы, влияющие на выбор проектного решения, ознакомиться с существующими методиками проектирования, а также провести анализ имеющихся средств автоматизации проектирования, возможности и целесообразности их использования.
Хотя даталогическое проектирование является проектированием логической структуры базы данных, на него оказывают влияние возможности физической организации данных, предоставляемые конкретной СУБД. Поэтому знание особенностей физической организации данных является полезным при проектировании логической структуры.
Логическая структура базы данных, а также сама заполненная данными база данных являются отображением реальной предметной области. Поэтому на выбор проектных решений самое непосредственное влияние оказывает специфика отображаемой предметной области, отраженная в инфологической модели
7. Примеры даталогического моделирования.

8. Особенности проектирования реляционной базу данных.
Концепция реляционной модели данных была предложена в 1969 году Эдгаром Коддом, известным специалистом в области баз данных, а в 1970 году она была им опубликованы. Реляционная модель представляет собой совокупность данных, состоящую из набора двумерных таблиц. В теории множеств таблице соответствует термин отношение (relation), физическим представлением которого является таблица, отсюда и название модели – реляционная. Реляционная модель является удобной и наиболее привычной формой представления данных.
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах.
Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.


9. Применение реляционной алгебры и исчислений при создании реляционных БД.
Для реляционной модели данных имеется развитый математический аппарат – реляционная алгебра. В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Например, в таблице, приведенной на рисунке 1, кортежи – это di1, di2,…,din (i=1,2,…m); а домены – d1к, d2к,…,dmk (k=1,2,…n). Количество атрибутов, содержащихся в отношении, определяет его степень, а количество кортежей – кардинальность отношения.

Один или несколько атрибутов, значения которых однозначно определяют кортеж отношения, называется его ключом, или первичным ключом, или ключевым полем. То есть ключевое поле – это такое поле, значения которого в данной таблице не повторяется.
операций обработки, то они позаимствованы из реляционной алгебры. Существует несколько подходов к определению реляционной алгебры. Они отличаются набором операций и их интерпретацией. Рассмотрим набор операций, который предложил Э. Кодд. Согласно его подходу реляционная алгебра включает восемь операций, пять из которых являются базовыми: Выборка, Проекция, Умножение, Объединение, Вычитание.
Операция Выборка позволяет выбрать из отношения только те кортежи, которые удовлетворяют заданному условию.
При Проекции отношения на заданный набор его атрибутов получается новое отношение, создаваемое посредством извлечения из исходного отношения кортежей, содержащих указанные атрибуты.
При Умножении (декартовом произведении) двух отношений получается новое отношение, кортежи которого являются сцеплением (конкатенацией) кортежей первого и второго отношений.
В результате Объединения двух отношений получается третье, включающее кортежи, входящие хотя бы в одно отношение, то есть содержащее все элементы исходных отношений.
При Вычитании выдаются лишь те кортежи первого отношения, которые остались от вычитания второго отношения, то есть из первого отношения выбрасываются все кортежи второго.
10. Изучение основных действий в конструкторе для создания базы данных некоторой предметной области.
11. Создание таблиц базы данных.
12. Создание индексных файлов (различных типов).
13. Установление отношений между таблицами в конструкторе базы данных.
14. Настройка переменной окружения экранной формы, в том числе установление подчинённости таблиц базы данных.
15. Элементы реляционных СУБД.
| Элемент реляционной модели
| Форма представления
|
| Отношение
| Таблица
|
| Заголовок (схема) отношения
| Заголовок таблицы
|
| Кортеж
| Строка таблицы
|
| Сущность
| Описание свойств объекта
|
| Атрибут
| Заголовок столбца таблицы
|
| Домен
| Множество допустимых значений
|
| Значение атрибута
| Значение поля в записи
|
| Первичный ключ
| Один или несколько атрибутов
|
| Тип данных
| Тип значений элементов таблицы
|
16. Менеджер проекта: основные принципы работы.
17. Основные принципы реализации технологии «клиент-сервер».
18. Установка и настройка клиентской и серверной части СУБД.
19. Установка и настройка утилит для обслуживания базы данных на стороне сервера.
20. Разработка программ, основанных на технологии «клиент-сервер».
21. Процедуры, правила (триггеры) и события в базах данных.
1. В базе данных определяются так называемые события (database events), связанные с изменениями данных - добавление новой записи (ей) в определенную таблицу, изменение записи(ей), удаление записи (ей).* Для реализации механизма событий в языке SQL введены специальные конструкции (Create DBEvent «Имя» - создать событие, Exec SQL Get DBEvent - получить событие и т.д.);
2. Для каждого события в базе данных определяются правила (triggers) по проверке определенных условий состояния данных. Соответственно в SQL введены конструкции для описания правил (Create Rule «Имя» - создать правило);
3. В зависимости от результатов проверки правил в базе данных запускаются на выполнение предварительно определенные процедуры. Процедуры представляют собой последовательности команд по обработке данных, имеющие отдельное смысловое значение, и могут реализовываться на упрощенном макроязыке (последовательность команд запуска запросов или выполнения других действий, например по открытию-закрытию форм, таблиц и т. п.) или на языке 4GL, встроенном в СУБД.

22. Механизмы реализации транзакций в различных СУБД.
Первые коммерческие СУБД (к примеру, IBM DB2), пользовались исключительно блокировкой доступа к данным.
Но большое количество блокировок приводит к существенному уменьшению производительности. Есть два популярных семейства решений этой проблемы, которые снижают количество блокировок:
· журнализация изменений (write ahead logging, WAL);
· механизм теневых страниц (shadow paging)[3].
В обоих случаях блокировки должны быть расставлены на всю информацию, которая обновляется. В зависимости от уровня изоляции и имплементации, блокировки записи также расставляются на информацию, которая была прочитана транзакцией.
При упреждающей журнализации все изменения записываются в журнал, и только после успешного завершения — в базу данных. Это позволяет СУБД вернуться в рабочее состояние после неожиданного падения системы. Теневые страницы содержат копии тех страниц базы данных на начало транзакции, в которых происходят изменения. Эти копии активизируются после успешного завершения. Хотя теневые страницы легче реализуются, упреждающая журнализация более эффективна
Дальнейшее развитие технологий управления базами данных привело к появлению безблокировочных технологий. Идея контроля над параллельным доступом с помощью временных меток (timestamp-based concurrency control) была развита и привела к появлению многоверсионной архитектуры MVCC. Эти технологии не нуждаются ни в журнализации изменений, ни в теневых страницах. Архитектура записывает старые версии страниц в специальный сегмент отката, но они все ещё доступны для чтения. Если транзакция при чтении попадает на страницу, временная метка которой новее начала чтения, данные берутся из сегмента отката (то есть используется «старая» версия). Для поддержки такой работы ведётся журнал транзакций, но в отличие от «упреждающей журнализации», он не содержит данных. Работа с ним состоит из трёх логических шагов:
1. Записать намерение произвести некоторые операции
2. Выполнить задание, копируя оригиналы изменяемых страниц в сегмент отката
3. Записать, что всё сделано без ошибок
Журнал транзакций в сочетании с сегментом отката (область, в которой хранится копия всех изменяемых в ходе транзакции данных) гарантирует целостность данных. В случае сбоя запускается процедура восстановления, которая просматривает отдельные его записи следующим образом:
· Если повреждена запись, то сбой произошёл во время проставления отметки в журнале. Значит, ничего важного не потерялось, игнорируем эту ошибку.
· Если все записи помечены как успешно выполненные, то сбой произошёл между транзакциями, здесь также нет потерь.
· Если в журнале есть незавершённая транзакция, то сбой произошёл во время записи на диск. В этом случае мы восстанавливаем старую версию данных из сегмента отката.
23. Проблемы многопользовательского режима.
При параллельном выполнении транзакций возможны следующие проблемы:
1) Потерянное обновление (англ. lost update)
При одновременном изменении одного блока данных разными транзакциями, одно из изменений теряется;
Имеются две транзакции, выполняемые одновременно:
| Транзакция 1
| Транзакция 2
|
| UPDATE tbl1 SET f2=f2+20 WHERE f1=1;
| UPDATE tbl1 SET f2=f2+25 WHERE f1=1;
|
В обеих транзакциях изменяется значение поля f2, при этом одно из изменений теряется. Так что, f2 будет увеличено не на 45, а только на 20 или 25.
Причина:
1. Первая транзакция прочитала текущее состояние поля.
2. Вторая транзакция сделала свои изменения, основываясь на своих сохраненных в память данных.
3. Первая делает обновление поля, используя свои «старые» данные.
2) «Грязное» чтение (англ. dirty read)
Чтение данных, добавленных или изменённых транзакцией, которая впоследствии не подтвердится (откатится);
| Транзакция 1
| Транзакция 2
|
| SELECT f2 FROM tbl1 WHERE f1=1;
| |
| UPDATE tbl1 SET f2=f2+1 WHERE f1=1;
| |
| | SELECT f2 FROM tbl1 WHERE f1=1;
|
| ROLLBACK WORK;
| |
В транзакции 1 изменяется значение поля f2, а затем в транзакции 2 выбирается значение этого поля. После этого происходит откат транзакции 1. В результате значение, полученное второй транзакцией, будет отличаться от значения, хранимого в базе данных.
3) Неповторяющееся чтение (англ. non-repeatable read)
При повторном чтении в рамках одной транзакции, ранее прочитанные данные оказываются изменёнными.
Предположим, имеются две транзакции, открытые различными приложениями, в которых выполнены следующие SQL-операторы:
| Транзакция 1
| Транзакция 2
|
| SELECT f2 FROM tbl1 WHERE f1=1;
| SELECT f2 FROM tbl1 WHERE f1=1;
|
| UPDATE tbl1 SET f2=f2+1 WHERE f1=1;
| |
| COMMIT;
| |
| | SELECT f2 FROM tbl1 WHERE f1=1;
|
В транзакции 2 выбирается значение поля f2, затем в транзакции 1 изменяется значение поля f2. При повторной попытке выбора значения из поля f2 в транзакции 2 будет получен другой результат. Эта ситуация особенно неприемлема, когда данные считываются с целью их частичного изменения и обратной записи в базу данных.
По области действия
Строчная блокировка — действуют только на одну строку таблицы базы данных, не ограничивая манипуляции над другими строками таблицы.
Гранулярная блокировка — действует на всю таблицу или всю страницу и все строки. Блокировка, ограничивающая манипуляции со страницей данных в таблице (набор строк, объединённый признаком совместного хранения) иногда называется страничной (англ. page locking).
Предикатные блокировки действуют на область, ограниченную предикатами
По строгости
Совместная блокировка накладывается транзакцией на объект в случае, если выполняемая ей операция безопасна, то есть не изменяет никаких данных и не имеет побочных эффектов. При этом, все транзакции могут выполнять операцию того же типа над объектом, если на него наложена совместная блокировка, обычно такая блокировка используется для операций чтения.
Исключительная блокировка накладывается транзакцией на объект в случае, если выполняемая ей операция изменяет данные. Только одна транзакция может выполнять подобную операцию над объектом, если на него наложена эксклюзивная блокировка. Блокировка не может быть наложена на объект, если на него уже наложена совместная блокировка.
По логике реализации
Пессимистическая блокировка накладывается перед предполагаемой модификацией данных на все строки, которые такая модификация предположительно затрагивает. Всё время действия такой блокировки исключена модификация данных из сторонних сессий, данные из блокированных строк доступны согласно уровню изолированности транзакции. По завершению предполагаемой модификации гарантируется непротиворечивая запись результатов.
Оптимистическая блокировка не ограничивает модификацию обрабатываемых данных сторонними сессиями, однако перед началом предполагаемой модификации запрашивает значение некоторого выделенного атрибута каждой из строк данных (обычно используется наименование VERSION и целочисленный тип с инициальным значением 0). Перед записью модификаций в базу данных перепроверяется значение выделенного атрибута, и если оно изменилось, то транзакция откатывается или применяются различные схемы разрешения коллизий. Если значение выделенного атрибута не изменилось — производится фиксация модификаций с одновременным изменением значения выделенного атрибута (например, инкрементом) для сигнализации другим сессиям о том, что данные изменились.
25. Механизм временный меток.
Основная идея метода (у которого существует множество разновидностей) состоит в следующем: если транзакция T1 началась раньше транзакции T2, то система обеспечивает такой режим выполнения, как если бы T1 была целиком выполнена до начала T2.
Для этого каждой транзакции T предписывается временная метка t, соответствующая времени начала T. При выполнении операции над объектом r транзакция T помечает его своей временной меткой и типом операции (чтение или изменение).
Перед выполнением операции над объектом r транзакция T1 выполняет следующие действия:
Проверяет, не закончилась ли транзакция T, пометившая этот объект. Если T закончилась, T1 помечает объект r и выполняет свою операцию.
Если транзакция T не завершилась, то T1 проверяет конфликтность операций. Если операции неконфликтны, при объекте r остается или проставляется временная метка с меньшим значением, и транзакция T1 выполняет свою операцию.
Если операции T1 и T конфликтуют, то если t(T) > t(T1) (т.е. транзакция T является более "молодой", чем T), производится откат T и T1 продолжает работу.
Если же t(T) < t(T1) (T "старше" T1), то T1 получает новую временную метку и начинается заново.
К недостаткам метода временных меток относятся потенциально более частые откаты транзакций, чем в случае использования синхронизационных захватов. Это связано с тем, что конфликтность транзакций определяется более грубо. Кроме того, в распределенных системах не очень просто вырабатывать глобальные временные метки с отношением полного порядка (это отдельная большая наука).
Но в распределенных системах эти недостатки окупаются тем, что не нужно распознавать тупики, а как мы уже отмечали, построение графа ожидания в распределенных системах стоит очень дорого.
26. Синхронизационные захваты.
Наиболее распространенным в централизованных СУБД (включающих системы, основанные на архитектуре "клиент-сервер") является подход, основанный на соблюдении двухфазного протокола синхронизационных захватов объектов БД. В общих чертах протокол состоит в том, что перед выполнением любой операции в транзакции T над объектом базы данных r от имени транзакции T запрашивается синхронизационный захват объекта r в соответствующем режиме (в зависимости от вида операции).
Основными режимами синхронизационных захватов являются:
· совместный режим - S (Shared), означающий разделяемый захват объекта и требуемый для выполнения операции чтения объекта;
· монопольный режим - X (eXclusive), означающий монопольный захват объекта и требуемый для выполнения операций занесения, удаления и модификации.
Захваты объектов несколькими транзакциями по чтению совместимы, т.е. нескольким транзакциям допускается читать один и тот же объект, захват объекта одной транзакцией по чтению не совместим с захватом другой транзакцией того же объекта по записи, и захваты одного объекта разными транзакциями по записи не совместимы.
Достаточно легко убедиться, что при соблюдении двухфазного протокола синхронизационных захватов действительно обеспечивается сериализация транзакций на третьем уровне изолированности. Основная проблема состоит в том, что следует считать объектом для синхронизационного захвата?
В контексте реляционных баз данных возможны следующие альтернативы:
· файл - физический (с точки зрения базы данных) объект, область хранения нескольких отношений и, возможно, индексов;
· отношение - логический объект, соответствующий множеству кортежей данного отношения;
· страница данных - физический объект, хранящий кортежи одного или нескольких отношений, индексную или служебную информацию;
· кортеж - элементарный физический объект базы данных.
На самом деле, когда мы говорим про операции над объектами базы данных, то любая операция над кортежем, фактически, является и операцией над страницей, в которой этот кортеж хранится, и над соответствующим отношением, и над файлом, содержащем отношение. Поэтому действительно имеется выбор уровня объекта захвата.
27. Поиск данных с применением индексных файлов.
Индексирование баз данных - механизм ускоренного поиска данных. Для индексирования создаются индексные файлы. Размер индексного файла сравним с объёмом дискового пространства, занимаемого полем БД, по которому было проведено индексирование.
Типы индексных файлов:
1 Одноиндексные “IDX” - компактные и обычные.
2 Мультииндексные “CDX” - всегда компактные:
Структурные (имя совпадает с именем БД)
Обычные (произвольное имя)
Тэг - отдельный ключ в мультииндексном файле.
Структурный индексный файл всегда открыт для своей БД и не указывается в списке индексов.
Один из открытых IDX -файлов задаёт ведущий индекс, которого может и не быть.
Приоритеты (если не указано особо): “IDX”, структурный, “CDX”.
SEEK<выражение> - быстрый поиск по ведущему индексу. По этой команде будет найдена первая в БД запись, удовлетворяющая выражению. Если поиск удачен функция RECNO() выдаст номер соответствующей записи, а функция FOUND() принимает значение.T.
Существует модификация функции указания номера записи: RECNO(0), которая в случае неудачного поиска возвращает номер записи имеющий самое близкое значение к ключу.
Функция SEEK (<выражение>,[<область>]) - выполняет поиск записи в индексном файле и устанавливает на неё указатель, возвращая.T., если поиск удачен, и.F. в противном случае.
Выражение для поиска должно по типу совпадать с индексным выражением!
Суть индексного поиска - метод деления пополам упорядоченного списка (k=0.67).
28. Поиск данных с помощью SQL-запросов.
С помощью оператора Select мы можем делать выборку из БД, удовлетворяющую данному условию
В большинстве случаев, выборка осуществляется из одной или нескольких таблиц. В последнем случае говорят об операции слияния — JOIN.
При формировании запроса SELECT пользователь описывает ожидаемый набор данных: его вид (набор столбцов) и его содержимое (критерий попадания записи в набор, группировка значений, порядок вывода записей и т. п.).
Запрос выполняется следующим образом: сначала извлекаются все записи из таблицы, а затем для каждой записи набора проверяется её соответствие заданному критерию. Если осуществляется слияние из нескольких таблиц, то сначала составляется произведение таблиц, а уже затем из полученного набора отбираются требуемые записи.
Формат запроса с использованием данного оператора:
SELECT список полей FROM список таблиц WHERE условия…
Основные ключевые слова, относящиеся к запросу SELECT:
· WHERE — используется для определения, какие строки должны быть выбраны или включены в GROUP BY.
· GROUP BY — используется для объединения строк с общими значениями в элементы меньшего набора строк.
· HAVING — используется для определения, какие строки после GROUP BY должны быть выбраны.
· ORDER BY — используется для определения, какие столбцы используются для сортировки результирующего набора данных.
29. Создание запросов с помощью конструктора запросов.
Для создания запроса в окне конструктора запросов выполните следующие действия:
На вкладке Data (Данные) конструктора проекта выберите группу Queries (Запросы).
Нажмите кнопку New (Новый).
В открывшемся диалоговом окне New Query (Новый запрос) нажмите кнопку New Query (Новый запрос). Открывается диалоговое окно выбора таблиц Add Table or View (Добавить таблицу или представление данных).
В этом диалоговом окне выберите таблицы, данные из которых хотите использовать в запросе, и с помощью кнопки Add (Добавить) перенесите их в окно конструктора запросов.
Завершив выбор таблиц, нажмите кнопку Close (Закрыть).
На экране появляется окно конструктора запросов, которое содержит названия выбранных таблиц, а в основном меню появляется пункт Query (Запрос). Можно приступать к формированию условий запроса.
Далее, открывая в конструкторе запросов необходимые вкладки, вы выполняете следующие действия:
выбираете поля результирующей таблицы запроса;
формируете вычисляемые поля;
указываете критерии для выборки, группировки и упорядочения данных;
задаете, куда выводить результат выборки.
30. Технологии объектного связывания данных.
Технология объектного связывания данных – технология, которая решает задачу обеспечения доступа из одной локальной БД, открытой одним локальным пользователем, к данным в другой локальной БД, возможно находящейся на другой вычислительной установке и открытой другим пользователем. Технология основана на протоколе ODBC, который принят за стандарт доступа к любым данным не только в Клиент-серверных системах, но в любых реляционных СУБД.
Современные настольные СУБД обеспечивают возможность доступа к объектам внешних БД своих форматов. В открытую в текущем сеансе работы БД пользователь может вставить ссылки и оперировать с данными из внешней БД. Объекты из внешней БД, называются связанными, при этом сами данные физически в файл текущей БД не помещаются, а остаются в файлах своих БД. Для пользователя связанные объекты ничем не отличаются от внутренних объектов.
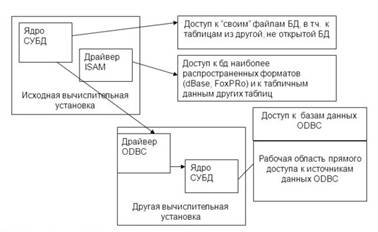
ядро СУБД при обращении к данным связанного объекта по системному каталогу текущей БД находит сведения о месте нахождения файла внешней БД и невидимо для пользователя открывает этот файл. В тот же момент времени с этим же файлом внешней БД может работать и другой пользователь.
31. Технологии реплицирования данных.
Во многих случаях узким местом распределенных систем, построенных на основе технологий «Клиент-сервер» или объектного связывания данных, является недостаточно высокая производительность из-за необходимости передачи по сети большого количества данных. Определенную альтернативу построения быстродействующих распределенных систем предоставляют технологии реплицирования данных.
Репликой называют особую копию базы данных для размещения на другом компьютере сети с целью автономной работы пользователей с одинаковыми (согласованными) данными общего пользования.
Основная идея реплицирования заключается в том, что пользователи работают автономно с одинаковыми (общими) данными, растиражированными по локальным базам данных, обеспечивая с учетом отсутствия необходимости передачи и обмена данными по сети максимальную для своих вычислительных установок производительность. Программное обеспечение СУБД для реализации такого подхода соответственно дополняется функциями тиражирования (реплицирования) баз данных, включая тиражирование как самих данных и их структуры, так и системного каталога с информацией о размещении реплик, иначе говоря, с информацией о конфигурировании построенной таким образом распределенной системы.
При этом, однако, возникают две проблемы обеспечения одного из основополагающих принципов построения и функционирования распределенных систем, а именно - непрерывности согласованного состояния данных:
• обеспечение согласованного состояния во всех репликах количества и значений общих данных;
• обеспечение согласованного состояния во всех репликах структуры данных.
Обеспечение согласованного состояния общих данных, в свою очередь, основывается на реализации одного из двух принципов:
• принципа непрерывного размножения обновлений (любое обновление данных в любой реплике должно быть немедленно размножено);
• принципа отложенных обновлений (обновления реплик могут быть отложены до специальной команды или ситуации).
Принцип непрерывного размножения обновлений является основополагающим при построении так называемых «систем реального времени», таких, например, как системы управления воздушным движением, системы бронирования билетов пассажирского транспорта и т. п., где требуется непрерывное и точное соответствие реплик или других растиражированных данных во всех узлах и компонентах подобных распределенных систем.
Реализация принципа непрерывного размножения обновлений состоит по сути в том, что любая транзакция считается успешно завершенной, в случае если она успешно завершена на всех репликах системы. На практике реализация этого принципа встречает существенные затруднения
В целом ряде предметных областей распределенных информационных систем режим реального времени с точки зрения непрерывности согласования данных не требуется. Такие системы автоматизируют те организационно-технологические структуры, в которых информационные процессы не столь динамичны. В этом случае обновление реплик распределенной информационной системы, в случае если она будет построена на технологии реплицирования, требуется, скажем, только лишь один раз за каждый рабочий час, или за каждый рабочий день.
Такого рода информационные системы строятся на базе принципа отложенных обновлений. Накопленные в какой-либо реплике изменения данных специальной командой пользователя направляются для обновления всех остальных реплик систем. Такая операция принято называть синхронизацией реплик.
32. Разработка информационных массивов, информационных хранилищ и складов данных. (Тут всё нипанятна)
Информационный массив - совокупность зафиксированной информации, предназначенная для хранения и использования и рассматриваемая как единое целое
Храни́лище да́нных (англ. Data Warehouse) — предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации. Строится на базе систем управления базами данных и систем поддержки принятия решений. Данные, поступающие в хранилище данных, как правило, доступны только для чтения.
Данные из транзакционной системы копируются в хранилище данных таким образом, чтобы при построении отчётов и анализе не использовались ресурсы транзакционной системы и не нарушалась её стабильность. Есть два варианта обновления данных в хранилище:
· полное обновление данных в хранилище. Сначала старые данные удаляются, потом происходит загрузка новых данных. Процесс происходит с определённой периодичностью, при этом актуальность данных может несколько отставать от OLTP-системы;
· инкрементальное обновление — обновляются только те данные, которые изменились в OLTP-системе.
Склад данных – это логически интегрированный источник данных для систем поддержки принятия решений и для информационных систем руководителя.
Данные поступившие на склад, приобретают статус постоянной информации, т.е. вносимые изменения носят характер «пополнения» (путем регулярных плановых выборок из информационных баз), а не произвольных поэлементных модификаций, как в операционных базах данных.
33. Журнализация изменений БД.
Общей целью журнализации изменений баз данных является обеспечение возможности восстановления согласованного состояния базы данных после любого сбоя. Поскольку основой поддержания целостного состояния базы данных является механизм транзакций, журнализация и восстановление тесно связаны с понятием транзакции. Общими принципами восстановления являются следующие:
· результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных;
· результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных.
Это, собственно, и означает, что восстанавливается последнее по времени согласованное состояние базы данных.
Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных:
· Индивидуальный откат транзакции. Тривиальной ситуацией отката транзакции является ее явное завершение оператором ROLLBACK. Возможны также ситуации, когда откат транзакции инициируется системой. (например, деление на ноль) Для восстановления согласованного состояния базы данных при индивидуальном откате транзакции нужно устранить последствия операторов модификации базы данных, которые выполнялись в этой транзакции.
· Восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой). Такая ситуация может возникнуть при аварийном выключении электрического питания, при возникновении неустранимого сбоя процессора (например, срабатывании контроля оперативной памяти) и т.д. Ситуация характеризуется потерей той части базы данных, которая к моменту сбоя содержалась в буферах оперативной памяти.
· Восстановление после поломки основного внешнего носителя базы данных (жесткий сбой). Эта ситуация при достаточно высокой надежности современных устройств внешней памяти может возникать сравнительно редко, но тем не менее, СУБД должна быть в состоянии восстановить базу данных даже и в этом случае. Основой восстановления является архивная копия и журнал изменений базы данных.
Во всех трех случаях основой восстановления является избыточное хранение данных. Эти избыточные данные хранятся в журнале, содержащем последовательность записей об изменении базы данных.
Возможны два основных варианта ведения журнальной информации. В первом варианте для каждой транзакции поддерживается отдельный локальный журнал изменений базы данных этой транзакцией. Эти локальные журналы используются для индивидуальных откатов транзакций и могут поддерживаться в оперативной (правильнее сказать, в виртуальной) памяти. Кроме того, поддерживается общий журнал изменений базы данных, используемый для восстановления состояния базы данных после мягких и жестких сбоев.
34. Информационные документационные системы.
В отличие от фактографических информационных систем, единичным элементом данных в документальных [информационных системах] является неструктурированный на более мелкие элементы документ. В качестве неструктурированных документов в подавляющем большинстве случаев выступают, прежде всего, текстовые документы, представленные в виде текстовых файлов, хотя к классу неструктурированных документированных данных могут также относиться звуковые и графические файлы.
Основной задачей документальных информационных систем является накопление и предоставление пользователю документов, содержание, тематика, реквизиты и т. п. которых адекватны его информационным потребностям.
Поэтому можно дать следующее определение документальной информационной системы — единое хранилище документов с инструментарием поиска и отбора необходимых документов. Поисковый характер документальных информационных систем исторически определил еще одно их название — информационно-поисковые системы (ИПС)
Соответствие найденных документов информационным потребностям пользователя называется пертинентностью.
В силу теоретических и практических сложностей с формализацией смыслового содержания документов пертинентность относится скорее к качественным понятиям, хотя, как будет рассмотрено ниже, может выражаться определенными количественными показателями.
В зависимости от особенностей реализации хранилища документов и механизмов поиска документальные ИПС можно разделить на две группы:
§ системы на основе индексирования;
§ семантически-навигационные системы.
В семантически-навигационных системах документы, помещаемые в хранилище (в базу) документов, оснащаются специальными навигационными конструкциями, соответствующими смысловым связям (отсылкам) между различными документами или отдельными фрагментами одного документа. Такие конструкции реализуют некоторую семантическую* (смысловую) сеть в базе документов. Способ и механизм выражения информационных потребностей в подобных системах заключаются в явной навигации пользователя по смысловым отсылкам между документами. В настоящее время такой подход реализуется в гипертекстовых ИПС.
В системах на основе индексирования исходные документы помещаются в базу без какого-либо дополнительного преобразования, но при этом смысловое содержание каждого документа отображается в некоторое поисковое пространство. Процесс отображения документа в поисковое пространство называется индексированием и заключается в присвоении каждому документу некоторого индекса-координаты в поисковом пространстве. Формализованное представление (опи






