Рекурсивные алгоритмы
В программировании рекурсия — вызов функции (процедуры) из неё же самой, непосредственно (простая рекурсия) или через другие функции (сложная рекурсия), например, функция A вызывает функцию B, а функция B — функцию A. Количество вложенных вызовов функции или процедуры называется глубиной рекурсии.
Преимущество рекурсивного определения объекта заключается в том, что такое конечное определение теоретически способно описывать бесконечно большое число объектов. С помощью рекурсивной программы же возможно описать бесконечное вычисление, причём без явных повторений частей программы.
Реализация рекурсивных вызовов функций в практически применяемых языках и средах программирования, как правило, опирается на механизм стека вызовов — адрес возврата и локальные переменные функции записываются в стек, благодаря чему каждый следующий рекурсивный вызов этой функции пользуется своим набором локальных переменных и за счёт этого работает корректно. Оборотной стороной этого довольно простого по структуре механизма является то, что на каждый рекурсивный вызов требуется некоторое количество оперативной памяти компьютера, и при чрезмерно большой глубине рекурсии может наступить переполнение стека вызовов. Вследствие этого, обычно рекомендуется избегать рекурсивных программ, которые приводят (или в некоторых условиях могут приводить) к слишком большой глубине рекурсии.
Алгоритмы поиска и сортировки.
Сортировка
Пусть есть последовательность a0, a1... an и функция сравнения, которая на любых двух элементах последовательности принимает одно из трех значений: меньше, больше или равно. Задача сортировки состоит в перестановке членов последовательности таким образом, чтобы выполнялось условие: ai <= ai+1, для всех i от 0 до n.
Возможна ситуация, когда элементы состоят из нескольких полей:

| struct element { field x; field y; } |
Если значение функции сравнения зависит только от поля x, то x называют ключом, по которому производится сортировка. На практике, в качестве x часто выступает число, а поле y хранит какие-либо данные, никак не влияющие на работу алгоритма.
Пожалуй, никакая другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Существует ли некий "универсальный", наилучший алгоритм? Вообще говоря, нет. Однако, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом.
Для того, чтобы обоснованно сделать такой выбор, рассмотрим параметры, по которым будет производиться оценка алгоритмов.
- Время сортировки - основной параметр, характеризующий быстродействие алгоритма.
- Память - ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
- Устойчивость - устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, как на рис. 1, а сортировка происходит по одному из них, например, по x.
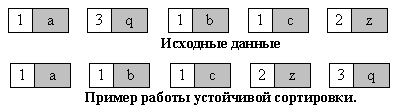
Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" осталось прежним: элемент с полем "a", затем - с "b", затем - с "c".

Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" изменилось.
- Естественность поведения - эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведет себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Еще одним важным свойством алгоритма является его сфера применения. Здесь основных позиций две:
- внутренние сортировки работают с данным в оперативной памяти с произвольным доступом;
- внешние сортировки упорядочивают информацию, расположенную на внешних носителях. Это накладывает некоторые дополнительные ограничения на алгоритм:
- доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим
- объем данных не позволяет им разместиться в ОЗУ
Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью.
Данный класс алгоритмов делится на два основных подкласса:
Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
Внешняя сортировка оперирует с запоминающими устройствами большого объема, но с доступом не произвольным, а последовательным (сортировка файлов), т.е в данный момент мы 'видим' только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство.
Основные методы сортировки 

Статьи ниже являются частями одной большой, так что в последующих может использоваться информация из предыдущих. В программах используются переопределения:
typedef double real;typedef unsigned long ulong;typedef unsigned short ushort;typedef unsigned char uchar;
Под переменной size принимается количество элементов в массиве, а для обозначения индекса последнего элемента используется N. Очевидно, size=N+1.
Простой выбор
Это очень естественный способ сортировки, обычно он первым приходит на ум человеку, столкнувшемуся с необходимостью упорядочения таблицы. Идея его такова. Найдем в таблице элемент с наименьшим значением и поменяем его местами с первым элементом. После этого те же действия проделаем с оставшимися (без первого) N-1 элементами таблицы, затем с N-2 элементами и т. д., пока не останется один элемент - последний. Он будет наибольшим.
На Рис. 2 этот метод отображен для последовательности прямоугольников разной высоты. Два первых элемента уже упорядочены. Затем отыскивается минимальный среди остальных. Если элементы в последовательности могут быть равными, то отыскивается первый (I) среди минимальных (таким образом достигается устойчивость сортировки). Он меняется местами с третьим.
Для составления алгоритма решения этой задачи воспользуемся, как обычно, методом пошаговой детализации. Обратим внимание на то, что для получения результата нам нужно N-1 раз находить минимальное значение в таблице, длина которой уменьшается и определяется тем, в который раз мы приступили к поиску минимума. Так, в 1-й раз мы ищем минимум среди элементов A1, A2,..., AN, во 2-й - среди A2,..., AN, в i-й - среди Ai,...,AN. И еще один важный момент. Поскольку после нахождения минимального элемента его нужно будет поменять местами с другим элементом таблицы, то нужно запомнить номер минимального. Следовательно, первый шаг детализации можно представить таким оператором цикла:
I:= 1
пока I<=N-1
нц найти минимальный элемент и его номер в таблице Ai,..., АN (1)
поменять местами Аi и минимальный элемент (2)
I:= I+1
кц
Еще раз приведем разработанный ранее алгоритм поиска минимума.
1. K:= I; X:= A[I]; J:= I+1
пока J<=N
нцесли A[J]<X
то X:= A[J];K:= J
все
кц
После выполнения этих действий значением переменной Х будет значение минимального среди элементов Ai,...,AN, а значением К - номер этого элемента. Следовательно, пункт 2 можно записать конкретнее:
поменять местами элементы A1 и AK (2)
Известно, что в общем случае для взаимной перестановки в памяти двух переменных нужда третья, вспомогательная:
2. C:= A[I]; A[I]:= A[K]; A[K]:= C.
Заметим, однако, что в нашей конкретной ситуации эта третья переменная не нужна, так как ее роль играет переменная Х из пункта 1:
2. A[K]:= A[I]; A[I]:= X.
Мы сэкономили одно присваивание, но это немало, так как действия выполняются в цикле многократно.
Теперь можно записать полностью алгоритм сортировки простым выбором.
алг ВЫБОР(цел N, вещтаб A[1:N])
арг A, N
рез A
начвещ X, цел I, J, К
I:= 1
пока I<=N-1
нц K:= I; X:= A[I]; J:= I+1
пока J<=N
нцесли A[J]<X
то X:= a[J];K:= J
все
J:= J+1
кц
A[K]:= A[I]; A[I]:= X;
I:= I+1
кц
кон
На языке Паскаль оформим этот алгоритм в виде процедуры. Параметрами ее будут массив и его длина.
const m = 10;type mass = array [l..m] of real;procedure selec(n:integer; var a:mass);var i,j,k: integer; x: real;beginfor i:= 1 to n-1 dobegin k:= i; x:= a[i]; for j:= i+l to n do if a[j] < x then begin x:= a[j]; k:= j end; a[k]:= a[i]; a[i]:= xendend;
Простой обмен
Любой метод сортировки так или иначе связан с обменом, т. е. с перестановкой двух элементов в памяти. Но если для других методов это действие является вспомогательным, то для обменной сортировки это основная характеристика процесса.
Идея сортировки простым обменом заключается в многократных попарных сравнениях рядом стоящих элементов таблицы и перестановке этих элементов в заданном порядке. Пусть нам задана таблица:
| Номер элемента
|
|
|
|
|
|
| Значение элемента
|
|
|
|
|
|
Будем просматривать ее от конца к началу (в принципе это не обязательно, можно организовать и обычный просмотр от начала к концу). Сравним 4-й и 5-й элементы. Они расположены не в порядке возрастания, поменяем их местами. Теперь значением 4-го элемента будет 3, а 5-го - 12. Сравним далее 3-й и 4-й элементы. Их оставим на месте. Сравнение 2-го и 3-го элементов показывает, что их нужно переставить. Теперь значение 2-го элемента - 1. И, наконец, сравним 1-й и 2-й элементы. Их тоже нужно поменять местами. Таким образом, получим:
| Номер элемента
|
|
|
|
|
|
| Значение элемента
|
|
|
|
|
|
Мы видим, что в результате наших действий минимальный элемент переместился на первое место в таблице. Очевидно, в дальнейшие просмотры таблицы его уже не нужно включать. Очевидно также, что каждый следующий просмотр будет приводить к постановке очередного минимального элемента в левый конец рассматриваемой части таблицы. В результате N-1 просмотра мы получим упорядоченную таблицу.
Если вообразить себе, что элементы таблицы - это пузырьки в резервуаре с водой, каждый весом, равным своему значению (что и изображено на Рис. 2), то каждый проход с обменами по таблице приводит к "всплыванию пузырька" на соответствующий его весу уровень. Благодаря такой аналогии сортировка простым обменом получила название сортировки методом "пузырька". В примере на Рис. 2 первые два элемента последовательности уже упорядочены и "всплывает" третий элемент. Знак <= (а не <) показывает условие прекращения сравнений, именноэтим достигается устойчивость сортировки "пузырьком".
Составим алгоритм решения данной задачи. Ясно, что основой алгоритма будет цикл, выполняющийся N-1 раз. Выбор границ (1 и N-1или 2 и N) повлияет затем на задание индексов сравниваемых элементов, и только. Остановимся на второй паре границ.
I:= 2
пока I <= N
нц сравнить попарно элементы АN, АN-1,..., АI,АI-1 1
I:= I+1
кц
Разберем более детально пункт 1. Для попарного сравнения элементов нужен оператор цикла с границей, зависящей от I, так как при каждом новом проходе по таблице длина ее будет уменьшаться.
J:= N
пока J<=I
нц сравнить aj и aj-iи при необходимости поменять их местами 1.1
J:= J-1
кц
Пункт 1.1. уже легко записать в виде условного оператора:
1.1 если A[J-1]>A[J]
то X:= A[J-l]; A[J-1]:= A[J];A[J]:= X
все
Объединим теперь все шаги детализации в законченный алгоритм.
алг ОБМЕН(цел N, вещтаб A[1:N])
арг N, А
рез А
начцел I, J, вещ Х
I:= 2
пока I<=N
нц J:= N
пока J>=I
нцесли A[J-1]>A[J]
то X:= A[J-1]
A[J-1]:= A[J]
A[J]:= X
все
J:= J-1
кц
I:= I+1
кц
кон
В паскале
const m = 10;type mass = array [l..m] of real;procedure bubble(var a:mass; n:integer);var i,j: integer; x: real;begin for i:= 2 to n do for j:= n downto 1 do if a[j - 1] > a[j] then begin x:= a[j - 1]; a[j - 1]:= a[j]; a[j]:= x endend;
Простые вставки
Пусть в заданной последовательности а1, А2,..., АN первые I-1 элементов уже отсортированы. Найдем в этой части последовательности место для I-го элемента. Для этого будем сравнивать его по порядку со всеми элементами, стоящими левее, до тех пор пока не окажется, что некоторый АK<= аI. Затем сдвинем часть последовательности АK+1, АK+2,..., АI-1 на один элемент вправо и освободимтаким образом место АK+1для элемента АI, куда его и поставим. Эта последовательность действий отображена на Рис. 2 при упорядочивании последовательности треугольников разной высоты. Считая, что первые три элементауже упорядочены, ищем место для четвертого по вышеизложенному правилу. Знак <= (а не <) показывает, когда нужно прекратить сравнения, т. е. движение влево по последовательности. При этом достигается устойчивость сортировки вставками.
После того как мы проделаем подобные действия для всех элементов от 2-го до N-го, мы получим отсортированную последовательность.Отметим очень важную деталь в наших действиях. Когда мы проводим сравнение I-го элемента со всеми, стоящими левее него, может оказаться, что не найдется такого Ак, что АK<= аI; это произойдет, если АI меньше всех левых элементов. На Рис. 2 эта ситуация отмечена дорожным знаком "Прочие опасности". В этом случае нужно закончить просмотр (по достижении первого элемента последовательности) и осуществить сдвиг A1,..., AI-1 вправо, а элемент AI поставить на первое место.
Составим алгоритм решения этой задачи. Как и в предыдущих случаях, основным оператором здесь будет цикл, определяющий, для какого элемента последовательности мы ищем место в упорядоченной левой части.
I:= 2;
пока I <= N
нц найти место Ак для АI, в упорядоченной части последовательности (1)
сдвинуть элементы Ак+1, Ак+2,:, Ai-1 вправо (2)
поставить элемент АI на нужное место (3)
I:= I+1
кц
В результате действия 1 мы должны получить номер К, индекс элемента, рядом с которым справа нужно поставить АI.
Чтобы найти место для АI, нужно сравнивать его последовательно со всеми левыми соседями до элемента АK<= аI и, если такового не окажется, остановиться на первом элементе. Действия эти - циклические, причем удобнее оформить цикл по текущему номеру элемента. Получим:
1 инициализация цикла (1.1)
пока J>0
нц сравнить элементы аI и aJ (1.2)
кц
Обдумывая пункт 1.1 - инициализацию цикла, мы должны предусмотреть три момента. Во-первых, значение элемента аI; нужно запомнить, так как иначе при сдвиге оно может потеряться. Во-вторых, нужно зафиксировать номер I-1 - с этого элемента начнется сравнение. В-третьих, нужно позаботиться о том, чтобы в ситуации, когда аI, меньше A1, A2..., AI-1, он смог встать на первое место. Следовательно, получаем:
1.1 X:= A[I]; J:= I-1; K:= 1
Далее, по результатам сравнения аI, и aJ мы должны сделать вывод о том, продолжать сравнение или нужный элемент уже найден и пора закончить цикл. Закончить цикл можно присваиванием переменной J нулевого значения. Имеем:
1.2 если A[I] >= A[J]
то K:= J+1; J:= 0
иначе J:= J-1
все
Перейдем к детализации пункта 2. Для сдвига последовательности вправо нужно просматривать ее из конца в начало и последовательно сдвигать элементы.
2. J:= I
пока J>K
нц A[J]:= A[J-1]
J:= J-1
кц
Пункт 3 - это один оператор присваивания:
3. A[K]:= X
И наконец, законченный алгоритм сортировки простыми вставками.
алг ВСТАВКА (цел N, вещтаб A[1:N])
арг A, N
рез A
начцел I, J, K, вещ X
I:= 2
пока I <= N
нц X:= A[I]; J:= I-1; K:= 1
пока J>0
нцесли A[I] >= A[J]
то K:= J+1; J:= 0
иначе J:= J-1
все
кц
J:= I
пока J>K
нц A[J]:= A[J-1]
J:= J-1
кц
A[K]:= X;
I:= I+1
кц
кон
На паскале
Program SortByVstavka;var A: array of Integer;i, j, key: Integer;begin//Заполняем массив Afor i:= 0 to Length(A) - 1 dobegin key:= A[i]; j:= i - 1; while (j >= 0) and (A[j] > key) do begin A[j + 1]:= A[j]; j:= j - 1; A[j + 1]:= key; end;end;End.
Найти номер минимального элемента последовательности (все элементы разные). const m = 10;type mass = array [1..m] of real;procedure nommin (x:mass; n:integer; var nom:integer);var i: integer; min: real;begin min:= x[i]; nom:= 1;for i:= 2 to n do if min > x[i] then begin min:= x[i]; nom:= i endend;
Отсортированный массив
алг ДИХ (цел N, целтаб X[1:N], цел P,K)
арг X, N, P
рез K
начцел A, B, C
A:= 1; B:= N
пока A<B
нц C:= INT((A+B)/2)
если X[С]<P
то A:= C+1
иначе B:= C
все
кц
если X[A]=P
то K:= A
иначе K:= 0
все
кон
Begin
{$I-}
Rewrite(f); // создать новый файл
{$I+}
if IOResult<>0 then // ошибка создания файла
Begin
ShowMessage('Ошибка создания файла C:\1.TXT');
Exit;
end;
end;
WriteLn(f,'Привет'); // запись в файл строки с символами перевода строки
CloseFile(f); // закрыть файл
end;
Процедура Append(Файл) открывает файл для записи и устанавливает указатель записи в конец файла, т.е. все добавляемые к файлу строки будут записаны в конец файла.
В нашем случае в самом начале файла 1.txt может не оказаться на диске, поэтому команда открытия файла для добавления вызовет ошибку. В этом случае срабатывает наш собственный контроль ошибок и выполняется команда создания файла.
Поиск созданных файлов
Поиск файлов в Delphi поможет найти файлы, подходящие по выбранным программистом критериям - имени, размеру, дате создания и т.д. Поиск файлов может производиться как по всему выбранному диску, так и ограничиться отдельным каталогом. Поиск файлов в Delphi выполняется в три этапа.
- Сначала находится первый файл, удовлетворяющий заданной маске. Этот поиск осуществляется с помощью функции
function FindFirst(const Path: String; Attr: Integer; var F: TSearchRec): Integer;
Параметр Path задаёт адрес каталога (директории), в котором производится поиск. Он должен завершаться маской имён искомых файлов, например:
'C:\Temp\*.*', '*.txt'.
Символ '*' означает любое количество допустимых в имени файла символов. Если необходимо указать, что символ должен быть только один, то в маске используется символ '?'. Например, маска a*.txt определяет текстовые файлы с именем любой длины начинающиеся на a, а маска a?.txt ограничивает длину имени файлов двумя символами. Если в маске описан только файл, то поиск осуществляется только в текущем каталоге.
Параметр Attr содержит набор атрибутов, которые могут учитываться при отборе файлов: - faReadOnly = $01 - файл только для чтения;
- faHidden = $02 - скрытый файл;
- faSysFile = $04 - системный файл;
- faVolumeID = $08 - метка диска;
- faDirectory = $10 - каталог (директория);
- faArchive = $20 - архивный файл;
- faAnyFile = $3F - произвольный файл.
Эти атрибуты имеют значение отдельных битов в результирующем числе Attr. Для задания искомому файлу набора атрибутов их нужно просто просуммировать:
Attr:= faReadOnly + faSysFile + faHidden;
Такой набор атрибутов заставит функцию искать только скрытые системные файлы с характеристикой "только для чтения".
Результат поиска содержится в переменной F, имеющей тип TSearchRec:
type TSearchRec = record
Time: Integer;
Size: Integer;
Attr: Integer;
Name: TFileName;
ExcludeAttr: Integer;
FindHandle: THandle;
FindData: TWin32FindData;
end;
Наиболее важными среди полей этой записи являются:
- Name - имя файла;
- Size - Размер файла в байтах;
- Time - время создания файла в формате DOS.
Чтобы определить, имеет ли найденный файл нужный атрибут, используется поразрядное логическое умножение:
if (F.Attr and faDyrectory)=F.Attr
then S:='Это каталог';
То есть, имеющая нужный атрибут переменная F.Attr при поразрядном логическом умножении на него не изменяется.
- Когда первый файл, удовлетворяющий условиям поиска, найден, вызывается функция
function FindNext(var F: TSearchRec): Integer;
Переменная F, в которой первая функция сохранила результат поиска, передаётся функции FindNext в качестве параметра. На основании записанной в неё информации будет продолжен поиск следующего подходящего файла. - Процесс поиска завершается вызовом процедуры:
procedure FindClose(var F: TSearchRec);
Эта процедура освобождает память, которая была выделена системой для проведения процесса поиска.
Функции FindFirst и FindNext возвращают значение 0, если при поиске не возникло ошибок и очередной файл был найден.
Чтение из текстового файла
На прошлых уроках мы как, в компоненте Memo процесс загрузки и записи текстового файла делался следующим образом:
Memo1.Lines.LoadFromFile(Имя_файла); // загрузка
Memo1.Lines.SaveToFile(Имя_файла); // сохранение
Все это благодаря свойству Lines, в котором хранятся строки.
Но на практике иногда необходимо прочитать только определенную строку или совершить операцию добавления строки в уже существующий файл.
Следующий пример обработки текстового файла очень похож на аналогичную на языке Pascal.
Знающие люди могут ощутить разницу, поскольку есть некоторые отличия.
procedureTForm1.Button1Click(Sender: TObject);
Varf:TextFile; // объявление файловой переменной
st: String; // строковая переменная
begin
AssignFile(f,'c:\1.txt'); // привязка названия файла к файловой переменной
{$I-} // отключение контроля ошибок ввода-вывода
Reset(f); // открытие файла для чтения
{$I+} // включение контроля ошибок ввода-вывода
ifIOResult<>0 then // если есть ошибка открытия, то
Begin
ShowMessage('Ошибка открытия файла C:\1.TXT');
Exit; // выход из процедуры при ошибке открытия файла
end;
While not EOF(f) do // пока не конец файла делать цикл:
Begin
ReadLn(f,st); // читать из файла строку
ShowMessage(st); // выводить строку пользователю
end;
CloseFile(f); // закрыть файл
end;
Прокомментирую некоторые строки этого примера.
Команда AssignFile осуществляет привязку строки пути файла к файловой переменной. Все дальнейшие операции с файловой переменной автоматически осуществляются с указанным файлом. Для избежания путаниц, указывайте полный путь к файлу.
{$I-} и {$I+} являются директивами компилятору, что в этом месту соответственно следует отключить и включить контроль ошибок ввода-вывода. В данном случае при неудачной попытке открытия файла c:\1.txt (файл отсутствует или открыт для записи другой программой) наша программа не выдаст аварийной ошибки и продолжит выполнение данной процедуры. Это свойство полезно для обработки всех возможных случаев в работе программы.
IOResult – переменная, которая хранит в себе код ошибки последней операции ввода-вывода. Если она равна нулю, то последняя операция была успешно выполнена.
EOF(Файл) – функция, возвращающая признак конца файла. Т.е. она показывает, достигнут или нет конец открытого файла.
ReadLn(Файл,Переменная) – процедура считывания переменной из файла. В отличие от команды Read производит считывание строки с завершающимся символом перевода строки под кодами 13 и 10 (клавиша Enter).
CloseFile(Файл) – процедура закрытия ранее открытого файла.
Рекурсивные алгоритмы
В программировании рекурсия — вызов функции (процедуры) из неё же самой, непосредственно (простая рекурсия) или через другие функции (сложная рекурсия), например, функция A вызывает функцию B, а функция B — функцию A. Количество вложенных вызовов функции или процедуры называется глубиной рекурсии.
Преимущество рекурсивного определения объекта заключается в том, что такое конечное определение теоретически способно описывать бесконечно большое число объектов. С помощью рекурсивной программы же возможно описать бесконечное вычисление, причём без явных повторений частей программы.
Реализация рекурсивных вызовов функций в практически применяемых языках и средах программирования, как правило, опирается на механизм стека вызовов — адрес возврата и локальные переменные функции записываются в стек, благодаря чему каждый следующий рекурсивный вызов этой функции пользуется своим набором локальных переменных и за счёт этого работает корректно. Оборотной стороной этого довольно простого по структуре механизма является то, что на каждый рекурсивный вызов требуется некоторое количество оперативной памяти компьютера, и при чрезмерно большой глубине рекурсии может наступить переполнение стека вызовов. Вследствие этого, обычно рекомендуется избегать рекурсивных программ, которые приводят (или в некоторых условиях могут приводить) к слишком большой глубине рекурсии.
Алгоритмы поиска и сортировки.
Сортировка
Пусть есть последовательность a0, a1... an и функция сравнения, которая на любых двух элементах последовательности принимает одно из трех значений: меньше, больше или равно. Задача сортировки состоит в перестановке членов последовательности таким образом, чтобы выполнялось условие: ai <= ai+1, для всех i от 0 до n.
Возможна ситуация, когда элементы состоят из нескольких полей:
|
| struct element { field x; field y; } |
Если значение функции сравнения зависит только от поля x, то x называют ключом, по которому производится сортировка. На практике, в качестве x часто выступает число, а поле y хранит какие-либо данные, никак не влияющие на работу алгоритма.
Пожалуй, никакая другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Существует ли некий "универсальный", наилучший алгоритм? Вообще говоря, нет. Однако, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом.
Для того, чтобы обоснованно сделать такой выбор, рассмотрим параметры, по которым будет производиться оценка алгоритмов.
- Время сортировки - основной параметр, характеризующий быстродействие алгоритма.
- Память - ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
- Устойчивость - устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, как на рис. 1, а сортировка происходит по одному из них, например, по x.
Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" осталось прежним: элемент с полем "a", затем - с "b", затем - с "c".
Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" изменилось.
- Естественность поведения - эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведет себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Еще одним важным свойством алгоритма является его сфера применения. Здесь основных позиций две:
- внутренние сортировки работают с данным в оперативной памяти с произвольным доступом;
- внешние сортировки упорядочивают информацию, расположенную на внешних носителях. Это накладывает некоторые дополнительные ограничения на алгоритм:
- доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим
- объем данных не позволяет им разместиться в ОЗУ
Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью.
Данный класс алгоритмов делится на два основных подкласса:
Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
Внешняя сортировка оперирует с запоминающими устройствами большого объема, но с доступом не произвольным, а последовательным (сортировка файлов), т.е в данный момент мы 'видим' только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство.
Основные методы сортировки
Статьи ниже являются частями одной большой, так что в последующих может использоваться информация из предыдущих. В программах используются переопределения:
typedef double real;typedef unsigned long ulong;typedef unsigned short ushort;typedef unsigned char uchar;
Под переменной size принимается количество элементов в массиве, а для обозначения индекса последнего элемента используется N. Очевидно, size=N+1.






