

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...
Топ:
Марксистская теория происхождения государства: По мнению Маркса и Энгельса, в основе развития общества, происходящих в нем изменений лежит...
История развития методов оптимизации: теорема Куна-Таккера, метод Лагранжа, роль выпуклости в оптимизации...
Устройство и оснащение процедурного кабинета: Решающая роль в обеспечении правильного лечения пациентов отводится процедурной медсестре...
Интересное:
Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является...
Влияние предпринимательской среды на эффективное функционирование предприятия: Предпринимательская среда – это совокупность внешних и внутренних факторов, оказывающих влияние на функционирование фирмы...
Принципы управления денежными потоками: одним из методов контроля за состоянием денежной наличности является...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Вопрос 1. Архитектуры системы команд.
На настоящее время существует три базовых архитектуры системы команд:
- архитектурасполнымнаборомкоманд: CISC (ComplexInstructionSetComputer);
- архитектурассокращеннымнаборомкоманд: RISC (ReducedInstructionSetComputer);
- архитектураскоманднымисловамисверхбольшойдлины: VLIW (VeryLongInstructionWord).
В CISC-архитектуре реализовано аппаратное выполнение системы команд. Основоположником CISC-архитектуры считается компания IBM, которая начала применять данный подход с семейства машин IBM 360 и продолжает его в своих мощных современных универсальных ВМ (мэйнфреймах). Аналогичный подход характерен и для компании Intel в ее микропроцессорах серии x86.
Для CISC-архитектуры типичны:
• наличие в процессоре сравнительно небольшого числа регистров общего назначения;
• большое количество машинных команд, часть из которых аппаратно реализуют сложные операторы ЯВУ;
• разнообразие способов адресации операндов;
• множество форматов команд различной разрядности;
• наличие команд, где обработка совмещается с обращением к памяти.
Идея архитектуры RISC заключается в ограничении списка команд ВМ наиболее часто используемыми простейшими командами, оперирующими данными, размещенными только в регистрах процессорах. Обращение к памяти допускается лишь с помощью специальных команд чтения и записи. Резко уменьшено количество форматов команд и способов указания адресов операндов. Эти меры позволили существенно упростить аппаратные средства ВМ и повысить их быстродействие.
Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ компании CrayResearch.
В последнее время в микропроцессорах компаний Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.
|
|
Концепция VLIW базируется на RISC-архитектуре, но в ней несколько простых RISC-команд объединяются в одну сверхдлинную команду и выполняются параллельно. В плане АСК архитектура VLIW сравнительно мало отличается от RISC.
Появился лишь дополнительный уровень параллелизма вычислений, в силу чего архитектуру VLIW логичнее адресовать не к вычислительным машинам, а к вычислительным системам.
Вопрос 4. Устройства управления.
Устройство управления (УУ) вычислительной машины реализует функции управления ходом вычислительного процесса, обеспечивая автоматическое выполнение команд программы. Процесс выполнения программы в ВМ представляет собой последовательность машинных циклов. Детализируем основные целевые функции, реализуемые устройством управления в ходе типового машинного цикла. Для простоты примем, что ВМ обеспечивает одноадресную систему команд. При этом, в частности, полагается, что до начала выполнения двухоперандной арифметической команды второй операнд уже находится в процессоре.
Первым этапом в машинном цикле является выборка команды из памяти (этап ВК). Целевую функцию этого этапа будем обозначать как ЦФ - ВК.
За выборкой команды следует этап декодирования ее операционной части (кода операции). Для простоты пока будем рассматривать этот этап в качестве составной части этапа ВК.
Вторая целевая функция — формирование адреса следующей команды. На это выделяется специальный такт работы — этап ФАСК, которому соответствует целевая функция ЦФ-ФАСК.
Далее следует этап формирования исполнительного адреса операнда или адреса перехода, ( этап ФИА), на котором УУ реализует функцию ЦФ-ФИА. Функция имеет столько модификации, сколько способов адресации (СА) предусмотрено в системе команд ВМ.
На четвертом этапе реализуется целевая функция выборки операнда (ЦФ-ВО) из памяти по исполнительному адресу, сформированному на предыдущем этапе.
|
|
Наконец на последнем этапе машинного цикла действия задаются целевой функцией исполнения операции - ЦФ-ИО. Очевидно, что количество модификаций ЦФ-ИО равно количеству операций, имеющихся в системе команд ВМ.
Порядок следования целевых функций полностью определяет динамику работы устройства управления и всей ВМ в целом.
Вопрос 11.Кэш-память.
В большинстве ВМ основная память строится на базе микросхем динамических ОЗУ, на порядок уступающих по быстродействию центральному процессору. Замена динамических запоминающих устройств на статические ведет к весьма существенному удорожанию ОП. Экономически приемлемое решение этой проблемы, предложенное М. Уилксом, заключается в том, что между ОП и процессором размещается небольшая, но быстродействующая буферная память, куда в процессе работы копируются те участки ОП, к которым производится обращение со стороны процессора. Выигрыш достигается за счет ранее рассмотренного свойства локальности – если скопировать содержимое участка ОП в более быстродействующую буферную память и переадресовать на нее все обращения в пределах скопированного участка, то можно существенно сократить среднее время доступа к информации. Упомянутая буферная память получила название кэш-память (от английского слова cache — убежище, тайник), поскольку она обычно скрыта от программиста в том смысле, что он не может ее адресовать и может даже вообще не знать о ее существовании.
В общем виде использование кэш-памяти (КП) поясним следующим образом. Когда ЦП пытается прочитать слово из основной памяти, сначала осуществляется поиск копии этого слова в КП. Если такая копия существует, обращение к ОП не производится, а в ЦП передается слово, извлеченное из кэш-памяти. Данную ситуацию принято называть успешным обращением или попаданием (hit). При отсутствии слова в кэш-памяти, то есть при неуспешном обращении (промахе miss), блок данных, содержащий это слово, сначала пересылается из ОП в кэш-память, а затем уже из КП затребованное слово передается в ЦП.

На рис. 4.14 приведена структура системы памяти, включающая как основную, так и кэш-память. ОП емкостью 2n слов при взаимодействии с кэш-памятью рассматривается как состоящее из M блоков фиксированной длины по K слов в каждом(M = 2n/ K). Кэш-память также условно разбивается на C блоков аналогичного размера, причем С << M. При обращении к какой-либо ячейке ОП блок, содержащий данную ячейку, копируется в какой-то из блоков кэш-памяти, и все последующие обращения к блоку переадресовываются на его копию в КП. Ввиду малой емкости в кэш-памяти в разное время могут находиться копии различных блоков ОП. По этой причине каждую копию необходимо снабдить так называемым тегом (признаком), указывающим на то, копия какого блока ОП в настоящий момент хранится в данном блоке КП. В результате кэш-память представляет собой совокупность двух ЗУ, одно из которых предназначено для хранения копий данных из ОП (память данных), а второе — для хранения тегов этих копий (память тегов). Каждому блоку в памяти данных соответствует одна ячейка в памяти тегов.
|
|
Эффективность применения кэш-памяти в иерархической системе памяти зависит от целого ряда факторов, к наиболее существенным из которых следует отнести:
- емкость кэш-памяти;
- размер блока;
- способ отображения основной памяти на кэш-память;
- алгоритм замещения информации в заполненной кэш-памяти;
- алгоритм согласования содержимого основной и кэш-памяти;
- число уровней кэш-памяти.
Емкость кэш-памяти. С одной стороны, кэш-память должна быть достаточно мала, чтобы ее стоимостные показатели были близки к величине, характерной для ОП. С другой — она должна быть достаточно большой, чтобы среднее время доступа в системе, состоящей из основной и кэш-памяти, определялось временем доступа к кэш-памяти.
Размер блока. Когда в кэш-память помещается блок, вместе с требуемым словом туда попадают и соседние слова. По мере увеличения размера блока вероятность промахов сначала падает, так как в кэш, согласно принципу локальности, попадает все больше данных, которые понадобятся в ближайшее время. Однако когда размер блока становится излишне большим, вероятность промахов начинает расти (рис. 4. 15). Объясняется это тем, что:
- большие размеры блока уменьшают общее количество блоков, которые можно загрузить в кэш-память, а малое число блоков приводит к необходимости частой их смены;
|
|
- по мере увеличения размера блока каждое дополнительное слово оказывается дальше от запрошенного, поэтому такое дополнительное слово менее вероятно понадобится в ближайшем будущем.
Способы отображения оперативной памяти на кэш-память. Сущность отображения блока основной памяти на кэш-память состоит в его копировании в какой-либо из блоков кэш-памяти, после чего все обращения к блоку в ОП должны переадресовываться на копию в кэш-памяти.
Прямое отображение. При прямом отображении множество блоков основной памяти условно представляется в виде матрицы, в которой количество строк равно числу блоков в кэш-памяти m (рис. 6.31). В блок кэш-памяти с номером i может быть помещен любой блок ОП, но только из i-й строки матрицы.
Номер строки (i) и столбца (k) матрицы, на пересечении которых располагается блок основной памяти с адресом j, определяются выражениями i = j mod m и k = j div m. В двоичной записи адреса блока основной памяти номер строки представлен log2 m младшими разрядами, а номер столбца — оставшимися старшими разрядами. Такая система позволяет по адресу блока основной памяти, поступившему из ЦП, сразу же однозначно определить адрес блока кэш-памяти, куда должен быть отображен данный блок ОП (если его копия в КП отсутствует) или где следует искать соответствующую копию (если она присутствует в КП).
В качестве указателя того, какой из блоков i-й строки отображен или должен быть отображен на i-й блок КП (тега), используется номер столбца матрицы, где расположен отображенный (отображаемый) блок ОП.
Прямое отображение — простой и недорогой в реализации способ отображения. К его достоинствам можно отнести малую разрядность тега (для нашего примера она равна 7 битам). Кроме того, при проверке наличия в КП нужной копии достаточно проверить лишь одну определенную ячейку памяти тегов.

Рис. 4.16. Организация кэш-памяти с прямым отображением
Основной его недостаток — жесткое закрепление за определенными блоками ОП одного блока в КП. Поэтому если программа поочередно обращается к словам из двух различных блоков, отображаемых на одну и тут же строку кэш-памяти, постоянно станет происходить обновление данной строки и вероятность попадания будет низкой.
Одноуровневая и многоуровневая кэш-память. Логично предположить, что с увеличением емкости кэш-памяти можно ожидать и соответствующего повышения быстродействия ВМ. Современные технологии позволяют разместить на общем с процессором кристалле кэш-память достаточно большой емкости. С другой стороны, попытки увеличения емкости обычно приводят к снижению быстродействия, главным образом из-за усложнения схем управления и дешифрации адреса. По этой причине общую емкость кэш-памяти ВМ увеличивают за счет иерархической организации, при которой кэш-память состоит из нескольких уровней запоминающих устройств, отличающихся емкостью и быстродействием. Каждый последующий уровень имеет большую емкость по сравнению с предыдущим, но и меньшее быстродействие. Первый уровень (L1) иерархии образует наиболее скоростная кэш-память сравнительно небольшой емкости (не более 128 Кбайт). На кристалле ее располагают по возможности ближе к процессору, чтобы минимизировать длину соединяющей их шины и тем самым способствовать ускорению обмена информацией. Этот уровень в перспективных микропроцессорах обычно строится по разделенной схеме. Так, в многоядерном процессоре Nehalem фирмы Intel каждому ядру (процессору) придается кэш-память команд емкостью 32 Кбайт (4-входовая, модульно-ассоциативная) и кэш-память данных емкостью 32 Кбайт (8-входовая, модульно-ассоциативная).
|
|
Вопрос 12.Понятие виртуальной памяти.
Понятие виртуальной памяти
Сегодня для компьютеров универсального назначения типична ситуация, когда объем виртуального адресного пространства превышает доступный объем оперативной памяти. Это достигается за счет отображения виртуального адресного пространства на физическую память посредством использования механизма виртуальной памяти.
Виртуальная память – картина памяти, формируемая операционной системой для процесса (вспомним, что одна из функций ОС – предоставление виртуальной машины; естественно предположить, что память такой машины тоже должна быть виртуальной). Деятельность ОС по созданию такой картины правомерно назвать виртуализацией памяти.
Поскольку виртуальная память – механизм управленияп амятью, а не предоставляемое ее пространство, корректнее говорить о памяти, предоставляемой процессу посредством этого механизма. Ее объем складывается из доступного объема оперативной памяти и объема разрешенной к использованию дисковой памяти. Тогда справедливо утверждение: объем памяти, предоставляемой процессу механизмом виртуальной памяти, потенциально позволяет адресовать все виртуальное адресное пространство данного процесса. Реально на взаимодействие процессов накладывается целый ряд различных ограничений, в силу которых процессы должны вести себя корректно друг по отношению к другу, и ни один процесс не должен претендовать на всю доступную память. На сегодня «правила хорошего тона» предписывают использовать не более 200 – 500 Мб памяти, самостоятельно организуя программным путем обмен с диском в случае наличия более громоздких структур данных (как, например, это делает AdobePhotoshop).
В зависимости от способа структуризации виртуального адресного пространства, определяющего преобразование виртуальных адресов в физические, выделяется три класса виртуальной памяти.
- Страничное распределение. Единицей перемещения между памятью и диском является страница – часть виртуального адресного пространства фиксированного и небольшого объема.
- Сегментное распределение. Единицей перемещения между памятью и диском является сегмент – часть виртуального адресного пространства произвольного объема, содержащая осмысленную с некоторой точки зрения совокупность данных (подпрограмму, массив и т.д.).
- Сегментно-страничное распределение. Объединяет элементы предыдущих классов. Виртуальное адресное пространство структурируется иерархически: делится на сегменты, а затем сегменты делятся на страницы. Единицей перемещения между памятью и диском является страница.
Для временного хранения вытесненных на диск сегментов и страниц отводится либо специальная область, либо специальный файл, обычно называемые страничным файлом (pagefile, pagingfile) или, по традиции, файлом свопинга.
Текущий размер страничного файла влияет на возможности работы ОС следующим образом: чем больше файл, тем больше одновременно работающих приложений, но тем медленнее их работа из-за многократной перекачки перемещаемых элементов на диск и обратно.
Размер страничного файла в современных ОС является настраиваемым параметром, который выбирается администратором системы для достижения компромисса между числом одновременно выполняемых приложений и быстродействием системы. Этот размер устанавливается в панели управления, пункт «система», вкладка «дополнительно» - «параметры быстродействия».
Оценка рисков
Диаграмма последовательности – основа анализа безопасности запроса к общей внешней памяти. Цель оценки безопасности состоит в том, чтобы определить риск утечки информации на каждом этапе технологического стека. Процесс оценки проводится в два этапа.
На первом этапе определяют границы сети для анализа и детальную конфигурацию сети.
На втором этапе проводится анализ рисков. Анализ риска разбивается на идентификацию ценностей, угроз и уязвимых мест, оценку вероятностей и измерение риска.
Показатели ресурсов, значимости угроз и уязвимостей, эффективности средств защиты могут быть определены количественными методами (например, при определении стоимостных характеристик) и качественными (например, учитывающими штатные или чрезвычайно опасные воздействия внешней среды).
Среди возможных угроз в отношении сетей хранения данных можно выделить следующие:
− уничтожение;
− хищение;
− несанкционированное искажение;
− нарушение подлинности;
− подмена;
− блокирование доступа.
Источники угроз могут быть как внешние, так и внутренние. Да и сама по себе угроза является следствием наличия уязвимостей в конкретных узлах сети хранения.
Возможные уязвимости определяют составляющие элементы и свойства архитектурных решений сетей хранения, а именно:
− элементы архитектуры;
− протоколы обмена;
− интерфейсы;
− аппаратные платформы;
− системное программное обеспечение;
− условия эксплуатации;
− территориальное размещение узлов сети хранения.
В интересах целостного понимания проблемы рассмотрение будет вестись по уровням предоставления необходимых служб. Всего выделим четыре уровня:
− уровень устройств;
− уровень данных;
− уровень сетевого взаимодействия;
− уровень управления и контроля.
Ниже качественно отображена степень угрозы для каждого из них в рамках задействованных служб применительно к архитектуре сети хранения данных (рис. 4. 30).

Рис. 4.30. Степени угрозы
Следует помнить, что рассматриваемая инфраструктура ограничивается лишь самой сетью хранения: системами хранения, коммутаторами, серверами и рабочими станциями. Как видно из рисунка, использование уязвимостей на уровне управления и контроля может представлять максимальную угрозу для хранимой информации в силу того, что при несанкционированном доступе злоумышленник получает контроль над всем окружением сети хранения, включая системы хранения данных, коммутирующие устройства, а в ряде случаев – серверы приложений и рабочие станции клиентов сети. Последствия от получения подобного доступа могут быть самыми катастрофичными: от компрометации и уничтожения информации до полного разрушения архитектурных взаимосвязей между конечными узлами и системами хранения данных.
Синхронный протокол
В синхронных шинах имеется центральный генератор тактовых импульсов (ГТИ), к импульсам которого «привязаны» все события на шине. Тактовые импульсы (ТИ) распространяются по специальной сигнальной линии и представляют собой регулярную последовательность чередующихся единиц и нулей. Один период такой последовательности называется тактовым периодом шины. Именно он определяет минимальный квант времени на шине (временной слот). Все подключенные к шине устройства могут считывать состояние тактовой линии, и все события на шине отсчитываются от начала тактового периода. Изменение управляющих сигналов на шине обычно совпадает с передним или задним фронтом тактового импульса, иными словами, момент смены состояния на синхронной шине известен заранее и определяется тактовыми импульсами.

Рис. 5.14. Чтение на синхронной шине
На рис. 5.14 показана транзакция чтения с использованием простого синхронного протокола шины (буквой «M» обозначены сигналы ведущего, а буквой «S» — ведомого). Моменты изменения сигналов на шине определяет нарастающий фронт тактового импульса. Задний фронт ТИ служит для указания момента, когда сигналы можно считать достоверными. Стартовый сигнал отмечает присутствие на линиях шины адресной или управляющей информации. Когда ведомое устройство распознает свой адрес и находит затребованные данные, оно помещает эти данные и информацию о состоянии на шину и сигнализирует об их присутствии на шине сигналом подтверждения.
Операция записи выглядит сходно. Отличие состоит в том, что данные выдаются ведущим в тактовом периоде, следующем за тактовым периодом выставления адреса, и остаются на шине до отправки ведомым сигнала подтверждения и информации состояния.
Отметим, что синхронные протоколы требуют меньше сигнальных линий, проще для понимания, реализации и тестирования. С другой стороны, они менее гибки, поскольку привязаны к конкретной максимальной тактовой частоте и, следовательно, к конкретному уровню технологии.
По синхронному протоколу обычно работают шины «процессор-память».
Вопрос 28.Фронтальные ВМ.
Фронтальная ВМ (ФВМ) соединяет матричную SIMD-систему с внешним миром, используя для этого какой-либо из сетевых интерфейсов, напримерEthernet, как это имеет место в системе MasPar MP-1. Фронтальная ВМ работает под управлением операционной системы, чаще всего UNIX-подобной. На ФВМ пользователи подготавливают, компилируют и отлаживают свои программы. Перед выполнением программы сначала загружаются из фронтальной ВМ в контроллер массива процессорных элементов, который исполняет последовательную часть программы и распределяет распараллеленные команды и данные по процессорным элементам массива. В некоторых ВС при создании, компиляции и отладке программ КМП и фронтальная ВМ используются совместно.
На роль ФВМ подходят различные вычислительные машины. Так, в системе CM-2 в этом качестве выступает рабочая станция SUN-4, а в системе MasPar — DECstation 3000.
Контроллер массива процессорных элементов выполняет последовательный программный код, реализует команды ветвления программы, транслирует команды и сигналы управления в процессорные элементы. Рисунок 8.11 иллюстрирует одну из возможных реализаций КМП, в частности принятую в устройстве управления матричной вычислительной системы PASM.
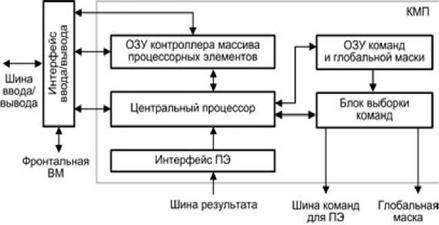
Рис. 8.11. Модель контроллера массива процессорных элементов
При загрузке из ФВМ программа через интерфейс ввода/вывода заносится в оперативное запоминающее устройство контроллера массива процессорных элементов (ОЗУ КМП). Команды для процессорных элементов и глобальная маска, формируемая на этапе компиляции, также через интерфейс ввода/вывода загружаются в ОЗУ команд и глобальной маски (ОЗУ КГМ). Затем контроллер начинает выполнять программу, извлекая либо одну скалярную команду из ОЗУ КМП, либо множественные команды из ОЗУ КГМ. Скалярные команды — команды, осуществляющие операции над хранящимися в КМП скалярными данными, выполняются центральным процессором (ЦП) контроллера. В свою очередь, команды, оперирующие параллельными переменными, хранящимися в каждом ПЭ, преобразуются в блоке выборки команд в более простые единицы выполнения — нано команды. Нано команды совместно с маской пересылаются через шину команд для ПЭ на исполнение в массив процессорных элементов. Например, команда сложения 32разрядных слов в КМП системы MPP преобразуется в 32 нано команды одноразрядного сложения, которые каждым ПЭ обрабатываются последовательно.
В большинстве алгоритмов дальнейший порядок вычислений зависит от результатов и/или флагов предшествующих операций. Для обеспечения такого режима в матричных системах статусная информация, хранящаяся в процессорных элементах, должна быть собрана в единое слово и передана в КМП для выработки решения о ветвлении программы. Например, в предложении IF ALL (условие A) THEN DO B оператор В будет выполнен, если условие А справедливо во всех ПЭ. Для корректного включения/отключения процессорных элементов КМП должен знать результат проверки условия А во всех ПЭ. Такая информация передается в КМП по однонаправленной шине результата. В системе CM-2 эта шина названа GLOBAL. В системе MPP для той же цели организована структура, называемая деревом SUM-OR. Каждый ПЭ помещает содержимое своего одноразрядного регистра признака на входы дерева, которое с помощью операции логического сложения комбинирует эту информацию и формирует слово результата, используемое в КМП для принятия решения.
Ассоциативные процессоры
Ассоциативным процессором называют специализированный процессор, реализованный на базе ассоциативного запоминающего устройства (АЗУ), где, как известно, доступ к информации осуществляется не по адресу операнда, а по отличительным признакам, содержащимся в самом операнде. От АЗУ традиционного применения ассоциативный процессор (АП) отличают две особенности: наличие средств обработки данных и возможность параллельной записи во все ячейки, для которых было зафиксировано совпадение с ассоциативным признаком. Последнее свойство АП известно как мульти запись.
Концепцию ассоциативной обработки поясним на примере упрощенной схемы ассоциативного процессора (рис. 8.14). Запоминающий массив (ЗМ) ассоциативного процессора состоит из n ячеек. Каждое из m + r-разрядных слов, хранящихся в ячейках запоминающего массива, состоит из двух частей: m-разрядного слова данных Д и r-разрядного признака (тега) T. Тег позволяет отличить данное слово от множества других слов. Так, если в ЗМ хранится вектор A, то теги ячеек, где расположены элементы этого вектора, в какой-то своей части будут одинаковыми, что обозначает принадлежность содержимого ячейки к вектору A. Остальные разряды тега могут содержать, например, индекс элемента вектора. Это позволяет в процессе ассоциативного поиска идентифицировать как все элементы вектора, так и его конкретный элемент. При доступе к ЗМ шаблон для поиска читаемого или записываемого слова (ассоциативный признак) заносится в регистр признака РгП, выходы которого поразрядно связаны со схемами сравнения СхСр^..., СхСря. По второму входу каждая из схем сравнения соединена с теговой частью запоминающего массива. При совпадении ассоциативного признака в РгП с теговой частью i-й ячейки вырабатывается сигнал с. Сигнал ci идентифицирует ячейку, для которой имело место совпадение, и разрешает выборку из нее данных, выполнение над ними в процессорном элементе ПЭi операции, определенной командой, поступающей из процессора управления, и занесение результата в i-ю ячейку. Процессорные элементы АП позволяют выполнять над данными арифметические и логические операции.
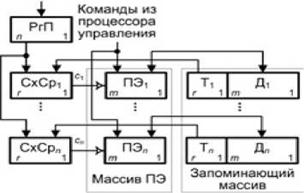
Рис. 8.14. Иллюстрации концепции ассоциативного процессора
Таким образом, идентификация ячеек, отвечающих признаку поиска, обработка содержащихся в них данных и занесение результатов в идентифицированные ячейки осуществляется параллельно по всем словам ЗМ. В упрощенной схеме не показаны связи между ПЭ, позволяющие взаимно обмениваться операндами и результатами. Способ выполнения операций над словами позволяет определить четыре класса ассоциативных процессоров:
- параллельные;
- поразрядно-последовательные;
- пословно-последовательные;
- блочно-ориентированные.
Два последних класса не слишком перспективны для универсальных вычислений, и ориентированы в основном на задачи информационного поиска. По этой причине основное внимание уделим параллельным и поразрядно-последовательным АП.
Вопрос 33. Понятие ядра.
Вопрос 1. Архитектуры системы команд.
На настоящее время существует три базовых архитектуры системы команд:
- архитектурасполнымнаборомкоманд: CISC (ComplexInstructionSetComputer);
- архитектурассокращеннымнаборомкоманд: RISC (ReducedInstructionSetComputer);
- архитектураскоманднымисловамисверхбольшойдлины: VLIW (VeryLongInstructionWord).
В CISC-архитектуре реализовано аппаратное выполнение системы команд. Основоположником CISC-архитектуры считается компания IBM, которая начала применять данный подход с семейства машин IBM 360 и продолжает его в своих мощных современных универсальных ВМ (мэйнфреймах). Аналогичный подход характерен и для компании Intel в ее микропроцессорах серии x86.
Для CISC-архитектуры типичны:
• наличие в процессоре сравнительно небольшого числа регистров общего назначения;
• большое количество машинных команд, часть из которых аппаратно реализуют сложные операторы ЯВУ;
• разнообразие способов адресации операндов;
• множество форматов команд различной разрядности;
• наличие команд, где обработка совмещается с обращением к памяти.
Идея архитектуры RISC заключается в ограничении списка команд ВМ наиболее часто используемыми простейшими командами, оперирующими данными, размещенными только в регистрах процессорах. Обращение к памяти допускается лишь с помощью специальных команд чтения и записи. Резко уменьшено количество форматов команд и способов указания адресов операндов. Эти меры позволили существенно упростить аппаратные средства ВМ и повысить их быстродействие.
Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ компании CrayResearch.
В последнее время в микропроцессорах компаний Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.
Концепция VLIW базируется на RISC-архитектуре, но в ней несколько простых RISC-команд объединяются в одну сверхдлинную команду и выполняются параллельно. В плане АСК архитектура VLIW сравнительно мало отличается от RISC.
Появился лишь дополнительный уровень параллелизма вычислений, в силу чего архитектуру VLIW логичнее адресовать не к вычислительным машинам, а к вычислительным системам.
|
|
|

Своеобразие русской архитектуры: Основной материал – дерево – быстрота постройки, но недолговечность и необходимость деления...

Архитектура электронного правительства: Единая архитектура – это методологический подход при создании системы управления государства, который строится...

Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого...

Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!