Высокие цифровые скорости кодеков с кодированием формы сигнала, которые практически не учитывают свойства артикуляционного аппарата человека и особенности его слухового восприятия, не приемлемы для систем сотовой связи. Но именно в свойствах артикуляционного аппарата человека и особенностях его слухового восприятия заключен значительный ресурс избыточности PC. На использовании этого ресурса избыточности основывается широко распространенный метод кодирования источника сигнала, реализующий параметрическое представление PC [26].
Озвученная речь, представляющая большую трудность для сжатия, образуется с помощью голосовых связок человека. Скорость их периодических колебаний задает частоту ОТ – периодическую подпитку энергией голосового тракта человека, который представляет собой объемный резонатор – фактически синтезирующий фильтр. Голосовой тракт формирует спектральную окраску речи, т. е. ее формантную структуру.
На первом этапе кодирования РС подвергается дискретизации и квантованию, а затем обрабатывается для получения параметров модели речеобразования. Параметры модели обычно разделяются на параметры возбуждения (относящиеся к источнику РС и отвечающие за основной тон, т. е. за возбуждение фильтра) и параметры голосового тракта (относящиеся непосредственно к отдельным звукам речи и определяющие формантную структуру сигнала), при этом отрезки глухой речи при моделировании заменяют шумом [26]. В настоящее время большинство используемых алгоритмов так или иначе решают один вопрос: как наиболее эффективно выделить и сокращенно описать обе составляющие?
В соответствии с таким подходом, сжатие PC осуществляется на передающем конце канала в анализаторе, выделяющем из сигнала сравнительно медленно меняющиеся параметры выбранной модели. Затем эти параметры передаются по каналу связи. На приемном конце с помощью местных источников сигналов, управляемых принятыми параметрами (согласно модели речеобразования), синтезируется РС.
Настоящим прорывом в кодировании речи стали кодеки на базе линейного предсказания (LPC), которое является одним из наиболее эффективных методов анализа РС и до сих пор остающиеся основным способом сжатия речи. Основной принцип этого метода состоит в том, что текущий отсчет PC можно аппроксимировать линейной комбинацией предшествующих отсчетов. Коэффициенты предсказания, как весовые коэффициенты, используемые в линейной комбинации, однозначно определяются минимизацией среднего квадрата разности между отсчетами PC и их предсказанными значениями на конечном интервале. Метод LPC весьма эффективен при оценке основных параметров PC, таких, как период основного тона, форманты, спектр, а также при компактном представлении речи [27].
Характерной чертой кодеков источника, по сравнению с кодеками формы сигнала, является еще и то, что они производят все операции анализа, кодирования, декодирования сразу для целого сегмента отсчетов, а не для каждого отсчета в отдельности. Поэтому используемый в них LPC-предсказатель адаптируется не под каждый речевой отсчет (как это осуществляется в ДИКМ и АДИКМ), а под целую последовательность отсчетов. Длительность таких последовательностей выбирается в пределах 20...30 мс, что приблизительно равно периоду локальной стационарности РС [26].
Основные положения метода LPC хорошо согласуются с моделью речеобразования, в соответствии с которой PC можно представить в виде сигнала на выходе линейной системы с переменными во времени параметрами, возбуждаемой квазипериодическими импульсами (вокализованный сегмент) или шумом (невокализованный сегмент).
Метод анализа на основе LPC заключается в том, что очередная выборка PC с определенной степенью точности предсказывается линейной комбинацией (суммирование с определенным весом) некоторого числа предшествующих выборок сигнала аналогично ДИКМ.
Порядок предсказания и его точность зависит от выбранного числа обрабатываемых предшествующих выборок.
Разность между истинным и предсказанным значениями выборки определяет ошибку (погрешность) предсказания, которая называется остатком предсказания. Эта величина может интерпретироваться как выходной сигнал фильтра-анализатора [27].
Фильтр-анализатор является инверсным, поскольку АЧХ такого фильтра должна быть обратна АЧХ голосового тракта (а значит, обратна огибающей спектра входного сигнала).
При подаче РС на вход инверсного фильтра с оптимально подобранными параметрами его выходной сигнал будет представлять собой сигнал возбуждения, подобный (с точностью до ошибок, определяемых конечностью порядка предсказания и погрешностью оценки коэффициентов предсказания) сигналу возбуждения на входе фильтра голосового тракта. При этом на выходе инверсного фильтра остается только периодическая составляющая PC, соответствующая основному тону.
Передаточная функция синтезирующего фильтра будет обратна передаточной характеристике фильтра-анализатора с точностью до скалярного коэффициента усиления. Фильтр-анализатор и фильтр-синтезатор являются рекурсивными, поскольку значение сигнала на их выходах определяется лишь предшествующими выходными выборками PC.
Фильтр-синтезатор – это линейная система с переменными параметрами (фактически – модель фильтра голосового тракта), которая возбуждается импульсной последовательностью для вокализованных звуков и шумом для невокализованных. Такая модель имеет следующие входные параметры: классификатор вокализованных и невокализованных звуков, период основного тона для вокализованных сегментов, коэффициент усиления и коэффициенты цифрового фильтра.
Все эти параметры медленно изменяются во времени.
Основная задача анализа на основе LPC заключается в непосредственном определении коэффициентов предсказания по РС с целью получения оценок его спектральных характеристик. Вследствие изменения свойств PC во времени коэффициенты предсказания должны оцениваться на коротких сегментах речи путем минимизации среднеквадратического значения остатка предсказания. Для определения коэффициентов предсказания необходимо решать систему линейных уравнений относительнонеизвестных коэффициентами предсказания [26].
Кодирование речи на основе метода LPC заключается в том, что по линии связи передаются не параметры PC, а параметры некоторого фильтра, в определенном смысле эквивалентного голосовому тракту, и параметры сигнала возбуждения этого фильтра. В качестве такого фильтра используется фильтр линейного предсказания (ФЛП), названный ранее фильтром-анализатором с передаточной функцией 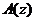 (рис. 7.1).
(рис. 7.1).
При кодировании (на передаче) производится оценка параметров ФЛП и параметров сигнала возбуждения, а при декодировании (на приеме) – сигнал возбуждения пропускается через фильтр-синтезатор, на выходе которого получается восстановленный сигнал речи [27].
Различные варианты алгоритмов кодирования отличаются набором передаваемых параметров фильтра, методом формирования сигнала возбуждения и рядом других деталей, а процедура кодирования речи сводится к следующему (рис. 7.1):
• оцифрованный сигнал речи «нарезается» на сегменты длительностью 20 мс (160 выборок по 8 бит в каждом сегменте);
• для каждого сегмента оцениваются параметры ФЛП и параметры сигнала возбуждения; в качестве сигнала возбуждения в простейшем случае может выступать остаток предсказания, получаемый при пропускании сегмента речи через фильтр с параметрами, полученными из оценки для данного сегмента;
• параметры фильтра и параметры сигнала возбуждения кодируются по определенному закону и передаются в канал связи.

Рис. 7.1. Кодирование речи на основе метода линейного предсказания:
1 – параметры фильтра линейного предсказания;
2 – сигнал возбуждения (остаток предсказания)
Таким образом, процедура декодирования речи заключается в пропускании принятого сигнала возбуждения через синтезирующий фильтр известной структуры, параметры которого переданы одновременно с сигналом возбуждения. Как анализирующий, так и синтезирующий фильтры являются цифровыми, и процедуры кодирования и декодирования речи реализуются в соответствующих вычислителях. Сигнал на вход анализирующего фильтра поступает непосредственно с выхода АЦП, а выходной сигнал синтезирующего фильтра попадает на вход ЦАП.
Приведенное описание процессов кодирования и декодирования речи не является исчерпывающим, оно объясняет лишь принцип действия кодека. Практические схемы заметно сложнее, и это связано в основном со следующими двумя моментами.
Во-первых, РС обладает двумя видами внутренних корреляционных связей, кратковременной и долговременной избыточностью, поэтому в подавляющем большинстве современных речевых кодеков используется два предсказателя: кратковременный и долговременный.
Первый предсказатель (STP), учитывающий кратковременную избыточность PC, связан с корреляциями между близко расположенными отсчетами сигнала и определяет огибающую спектра. Его порядок обычно выбирается в пределах 6 – 10.
Второй предсказатель (LTP) является долговременным, определяет тонкую структуру PC и связан с корреляцией двух отрезков сигнала между собой: обычно двух соседних периодов ОТ. Сочетание двух предсказателей с разными характеристиками позволяет в значительной мере устранить остаточную избыточность и приблизить остаток предсказания по своим статистическим характеристикам к белому шуму. При этом на приемную сторону передаются остаток предсказания и коэффициенты обоих (STP и LTP) предсказаний [26].
Во-вторых, использование остатка предсказания в качестве сигнала возбуждения оказывается недостаточно эффективным, так как требует для кодирования слишком большого числа бит. Поэтому практическое применение находят более экономичные (по загрузке канала связи, но отнюдь не по вычислительным затратам) методы формирования сигнала возбуждения.
Так, в начале 1980-х годов была предложена модель многоимпульсного возбуждения (МРЕ), не использующая классификацию сегментов речи по признаку вокализованный – невокализованный. С этой моделью связано значительное улучшение качества кодеков LPC, и в настоящее время используются исключительно различные варианты многоимпульсного возбуждения. Для оценки параметров последовательности импульсов сигнала возбуждения существует несколько методов.
В методе МРЕ оптимизируется как положение, так и амплитуды импульсов. В методе возбуждения регулярной последовательностью импульсов (RPE) взаимное расположение импульсов предопределено заранее – используется сетка равноотстоящих импульсов (обычно 10 импульсов на интервале 5 мс), а оптимизируется расположение этой сетки в пределах кадра возбуждения и амплитуды импульсов. В этом случае требуется определить положение и амплитуду первого импульса и амплитуды всех остальных импульсов.
Рассмотрим блок-схему кодека RPE–LTP, принятого в 1992 г. в качестве европейского стандарта GSM (см. рис. 7.2).
Блок предварительной обработки кодераосуществляет предыскажение входного сигнала при помощи цифрового фильтра восприятия, подчеркивающего верхние частоты, разбиение сигнала на сегменты по 160 выборок (20 миллисекунд) и взвешивание каждого из сегментов окном Хэмминга. Сигнал с выхода блока предварительной обработки фильтруется решетчатым фильтром-анализатором STP (порядок предсказания 8), а по остатку предсказания оцениваются параметры LTP:коэффициент предсказания и задержка. Сигнал  фильтруется фильтром-анализатором LTP, а выходной сигнал последнего фильтруется сглаживающим фильтром, и по нему формируются параметры сигнала возбуждения. Сигнал возбуждения состоит из 13 импульсов, следующих через равные промежутки времени и имеющих различные амплитуды.
фильтруется фильтром-анализатором LTP, а выходной сигнал последнего фильтруется сглаживающим фильтром, и по нему формируются параметры сигнала возбуждения. Сигнал возбуждения состоит из 13 импульсов, следующих через равные промежутки времени и имеющих различные амплитуды.


Рис. 7.2. Упрощенная блок-схема кодека RPE–LTP
Таким образом, выходная информация кодера речи включает параметры фильтра STP(8 коэффициентов), параметры фильтра LTP (коэффициент предсказания и задержка) и параметры сигнала возбуждения. Всего для одного 20-миллисекундного сегмента речи передается 260 бит информации, т. е. здесь кодер речи осуществляет сжатие информации почти в 5 раз (1280:260), что обеспечивает скорость передачи 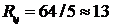 кбит/с.
кбит/с.
В декодереблок формирования сигнала возбуждения, используя принятые параметры сигнала возбуждения, восстанавливает 13-импульсную последовательность сигнала возбуждения, включая амплитуды импульсов и их расположение во времени. Сигнал возбуждения обрабатывается фильтром-синтезатором LTP, на выходе которого получается восстановленный остаток предсказания фильтра-анализатора STP. Последний фильтруется решетчатым фильтром-синтезатором STP, выходной сигнал которого восстанавливается в блоке постфильтрации цифровым фильтром, компенсирующим предыскажения, внесенные входным фильтром восприятия [26].
В противоположность субоптимальной процедуре метода RPE, при использовании векторного кодирования (VQ) кодируется одновременно группа параметров, характеризующих позиции импульсов и их амплитуды. Другими словами, кодируется вектор параметров, который представляет собой образец РС. Каждому вектору параметров приписывается кодовое слово, индекс. Множество векторов параметров образуют кодовую книгу.
Входной вектор, представляющий собой образец входного PC, сравнивается с векторами, находящимися в кодовой книге, и находится вектор, наиболее близкий к входному. Снижение скорости в результате использования VQ достигается путем передачи на прием только номера (индекса) вектора с масштабным коэффициентом. На приеме по этому индексу определяется вектор в кодовой книге, которая является точной копией кодовой книги на передаче. Так восстанавливается исходный PC.
Если кодовая книга образуется из большого количества реальных речевых образцов, то она называется детерминированной. Процесс образования такой кодовой книги (процесс «обучения») производится автоматически – векторы параметров извлекаются из случайной разговорной речи длительностью 30...40 мин, состоящей из нескольких мужских и женских голосов. В отличие от детерминированных, стохастические книги не требуют обучения. Они заполняются случайными гауссовскими последовательностями. Основанием для использования такой книги в качестве возбуждающей является то, что в системах LPCв сигнале остатка на выходе предсказателей практически устранены все корреляционные связи, и он имеет случайный характер.
Векторное кодирование лежит в основе метода стохастического кодирования, или метода линейного предсказания с кодовым возбуждением(CELP), с разновидностью возбуждения векторной суммой (VSELP).
В CELP-кодере наиболее подходящий вектор возбуждения выбирается из заранее составленной кодовой книги, содержащей обычно  , N = 7...10, квазислучайных векторов заданной длины с элементами, нормированными по амплитуде; амплитуда вектора возбуждения кодируется отдельно в соответствии с громкостью передаваемого элемента речи.
, N = 7...10, квазислучайных векторов заданной длины с элементами, нормированными по амплитуде; амплитуда вектора возбуждения кодируется отдельно в соответствии с громкостью передаваемого элемента речи.
В качестве примера рассмотрим метод кодирования VSELP, применяемый в американском стандарте D–AMPS, упрощенная блок-схема кодека которого представлена на рис. 7.3 [26].
В отличие от кодека RPE–LTP(рис. 7.2) в этой системе сигнал возбуждения представляется в виде вектора, которому присваиваются определенный индекс (образ сигнала), т.е. код и усиление (масштабный коэффициент). Выбор оптимального вектора производится из большого множества векторов-кандидатов, которые образуют кодовую книгу.
Сигнал возбуждения фильтра-синтезатора STPявляется суммой векторов возбуждения из двух кодовых книг и вектора с выхода фильтра-синтезатора LTP(отсюда и название метода – «с возбуждением векторной суммой»). Параметры сигнала возбуждения – номера векторов возбуждения из первой и второй кодовых книг и соответствующие коэффициенты усиления – определяются по критерию минимума среднеквадратической ошибки на выходе фильтра-синтезатора STP, входящего в состав кодера.
Таким образом, выходная информация кодера речи, помимо параметров фильтров STF и LTP, включает параметры сигнала возбуждения в виде двух векторов возбуждения из двух кодовых книг и соответствующие коэффициенты усиления. Всего для одного 20-миллисекундного сегмента речи передается 159 бит информации, т. е. здесь кодер речи осуществляет сжатие информации более чем в 8 раз (1280:159), что обеспечивает цифровую скорость передачи  кбит/с.
кбит/с.

Рис. 7.3. Упрошенная блок-схема кодека VSELP
В декодере сигнал возбуждения фильтра-синтезатора STP формируется таким же образом, как и в синтезирующей схеме кодера, а именно: по номерам из кодовых книг выбираются векторы возбуждения, которые умножаются соответственно на коэффициенты усиления и складываются с выходным вектором фильтра-синтезатора LTP. Далее сигнал возбуждения фильтруетсяфильтром-синтезатором STP.Для улучшения субъективного качества синтезированной речи выходной сигнал фильтра-синтезатораподвергается цифровой адаптивной постфильтрации. В процессе этой процедуры происходиттакое изменение спектра PC, в результате которого субъективно уменьшается восприятие шума квантования [26].
Классической реализацией метода линейного предсказания с кодовым возбуждением является кодек CELP–4,8, принятый в качестве федерального стандарта США (рис. 7.4). В нем используются LPC-синтезатор (долговременный и кратковременный предикторы), стохастическая кодовая книга и применяется процедура «анализа через синтез», обеспечивающая нахождение оптимальных значений параметров, участвующих в синтезе речи, методом перебора (внутри заданного заранее множества их значений).

Рис. 7.4. Структура передающей части CELP- кодера
Работа СELP-кодера заключается в следующем. Выход кодовой книги расчленяется на блоки по L отсчетов. Каждому блоку приписывается определенный индекс вектора возбуждения  – сигнал возбуждения
– сигнал возбуждения  .
.
Вектор масштабируется посредством коэффициента усиления  .
.
Полученный сигнал возбуждения  фильтруется спомощью двух адаптивных фильтров предсказания
фильтруется спомощью двух адаптивных фильтров предсказания  и
и 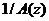 , представляющих собой LPС-синтезатор. При этом фильтр осуществляет формирование огибающей спектра PC, а фильтр определяет период основного тона PC в диапазоне от 2 до 17,5 мс, что соответствует изменению частоты основного тона от 500 до 57 Гц. На выходе предикторов формируется синтезированный PC
, представляющих собой LPС-синтезатор. При этом фильтр осуществляет формирование огибающей спектра PC, а фильтр определяет период основного тона PC в диапазоне от 2 до 17,5 мс, что соответствует изменению частоты основного тона от 500 до 57 Гц. На выходе предикторов формируется синтезированный PC 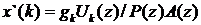 [26].
[26].
При оценке разности между синтезированным  и оригинальным
и оригинальным  сигналом так же, как и при многоимпульсном возбуждении, используется взвешивающий фильтр. Эта процедура повторяется со всеми сигналами возбуждения, и таким образом определяется то возбуждение, которое создает минимальную ошибку
сигналом так же, как и при многоимпульсном возбуждении, используется взвешивающий фильтр. Эта процедура повторяется со всеми сигналами возбуждения, и таким образом определяется то возбуждение, которое создает минимальную ошибку 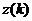 . Параметры этого возбуждения и вместе с параметрами двух фильтров предсказания передаются далее.
. Параметры этого возбуждения и вместе с параметрами двух фильтров предсказания передаются далее.
Одним из основных узлов СЕLP-кодера является стохастическая кодовая книга, содержащая последовательность векторов возбуждения – набор всевозможных сигналов возбуждения. Выбор сигнала возбуждения из кодовой книги состоит из выбора оптимального индекса возбуждения  и относящегося к нему такого усиления
и относящегося к нему такого усиления  , чтобы синтезированная речь в наибольшей степени соответствовала исходной речи и приводила бы к минимизации взвешенного остатка предсказания [27].
, чтобы синтезированная речь в наибольшей степени соответствовала исходной речи и приводила бы к минимизации взвешенного остатка предсказания [27].
Новые разработки в области речевых кодеков направлены на усовершенствование алгоритма линейного предсказания алгебраического CELP.Так, в алгоритме MP–MLQ повышение качества синтезированной речи обеспечивается трехкратным увеличением длины сглаживающего окна относительно длины анализируемого сегмента речи, более точным формированием сигнала возбуждения синтезирующего фильтра, а также более падежным, по сравнению с предшественниками, вычислением параметров ОТ.
В кодеке MELP (LPC-кодек со смешанным возбуждением) на скорость 2,4 кбит/с, разработанном на замену описанного выше кодека CFLP-4,8, использованы четырехполосный анализ речи и линейное предсказание.
Для связи с морскими судами был предложен кодек Inmarsat–M (система спутниковой радионавигации), работающий по алгоритму IMBE (улучшенное многополосное возбуждение). В этом алгоритме спектр речи делят фильтрами на несколько полос и в каждой полосе принимают отдельное решение «звонко-глухо». Благодаря подстройке фильтров к гармоникам частоты ОТ, достигается удовлетворительноекачество речи, несмотряна низкую скорость. Для лучшего выделения ОТ анализируют нескольких интервалов ОТ и формируют его интегральную оценку. Однако кодек IMBEотличает высокая сложностьи стоимость.
Из вышеизложенного ясно, что создание экономичного и совершенного кодека речи является сложным творческим процессом, при этом многие технические решения настолько разнородны, что их сопоставление оказывается непростой задачей. Для ее решении разработаны методы и критерии, позволяющие более или менее объективно сопоставлять и оценивать различные методы кодирования.
Список рекомендуемой литературы: [ 2, c. 83–103; 3, c. 16–18, 255–276, 310–366; 4, c. 267–288; 5, c. 77–79, 96–111, 122–135, 447–452; 8, c. 46–75; 10, c. 46–52, 205–210, 315–335; 13, c. 21–28, 158–165; 26 – 28 ].
Контрольные вопросы
1. Чем принципиально отличается кодирование формы речевого сигнала от его параметрического представления?
2. В чем состоит особенность применения линейного предсказания при параметрическом кодировании речевого сигнала?
3. Какие параметры модели речеобразования используются в системах кодирования с адаптивным предсказанием?
4. Из каких соображений выбирается порядок предсказания?
5. Как используются при кодировании речи кратковременное и долговременное предсказания?
6. Поясните основы метода многоимпульсного возбуждения.
7. В чем заключается основное назначение кодовой книги? Какие разновидности кодовых книг Вам известны?
8. Чем принципиально отличаются кодеки стандартов D-AMPS и GSM?
9. Сформулируйте основы метода линейного предсказания с кодовым возбуждением.
10. Сравните по важнейшим характеристикам основные способы кодирования речи.
11. В чем состоят трудности создания эффективных речевых кодеков?





