Коды Шеннона-Фано, Хафмана, Лемпела-Зива.
Методы сжатия делятся на статистические и словарные. Словарные методы заключаются в том, чтобы в случае встречи подстроки, которая уже была найдена раньше, кодировать ссылку, которая занимает меньше места, чем сама подстрока. Классическим словарным методом является метод Лемпела-Зива (LZ). Все используемые на сегодняшний день словарные методы являются лишь модификациями LZ.
Статистическое кодирование заключается в том, чтобы кодировать каждый символ, но использовать коды переменной длины. Примером таких методов служит метод Хаффмана (Huffman). Обычно словарные и статистические методы комбинируются, поскольку у каждого свои преимущества.
Метод Шеннона-Фано.
Кодирование Шеннона-Фано - алгоритм префиксного неоднородного кодирования. Относится к вероятностным методам сжатия.
Данный метод выделяется своей простотой. Берутся исходные сообщения m(i) и их вероятности появления P(m(i)). Этот список делится на две группы с примерно равной интегральной вероятностью. Каждому сообщению из группы 1 присваивается 0 в качестве первой цифры кода. Сообщениям из второй группы ставятся в соответствие коды, начинающиеся с 1. Каждая из этих групп делится на две аналогичным образом и добавляется еще одна цифра кода. Процесс продолжается до тех пор, пока не будут получены группы, содержащие лишь одно сообщение. Каждому сообщению в результате будет присвоен код x c длиной –lg(P(x)). Это справедливо, если возможно деление на подгруппы с совершенно равной суммарной вероятностью. Если же это невозможно, некоторые коды будут иметь длину –lg(P(x))+1. На шаге делеения алфавита существует неоднозначность, так как разность суммарных вероятностей p 0 − p 1 может быть одинакова для двух вариантов разделения (учитывая, что все символы первичного алфавита имеют вероятность, большую нуля). Алгоритм Шеннона-Фано не гарантирует оптимального кодирования.
Код Хаффмана — жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. В настоящее время используется во многих программах сжатия данных.
Идея, лежащая в основе кода Хаффмана, достаточно проста. Вместо того чтобы кодировать все символы одинаковым числом бит, будем кодировать символы, которые встречаются чаще, меньшим числом бит, чем те, которые встречаются реже. Более того, потребуем, чтобы код был оптимален.
В отличие от алгоритма Шеннона-Фано, алгоритм Хаффмана остаётся всегда оптимальным и для вторичных алфавитов m2 с более чем двумя символами.
Этот метод кодирования состоит из двух основных этапов:
1. Построение оптимального кодового дерева.
2. Построение отображения код-символ на основе построенного дерева.
Алгоритм
1. Составим список кодируемых символов (при этом будем рассматривать каждый символ как одноэлементное бинарное дерево, вес которого равен весу символа).
2. Символы первичного алфавита m1 выписывают в порядке убывания вероятностей.
3.Последние n0 символов объединяют в новый символ, вероятность которого равна суммарной вероятности этих символов, удаляют эти символы и вставляют новый символ в список остальных на соответствующее место (по вероятности). n0 вычисляется из системы:
 ,
,
где a — целое число, m1 и m2 — мощность первичного и вторичного алфавита соответственно.
4. Последние m2 символов снова объединяют в один и вставляют его в соответствующей позиции, предварительно удалив символы, вошедшие в объединение.
5. Предыдущий шаг повторяют до тех пор, пока сумма всех m2 символов не станет равной 1.
Этот процесс можно представить как построение дерева, корень которого — символ с вероятностью 1, получившийся при объединении символов из последнего шага, его m2 потомков — символы из предыдущего шага и т.д.
Каждые m2 элементов, стоящих на одном уровне, нумеруются от 0 до m2-1. Коды получаются из путей (от первого потомка корня и до листка). При декодировании можно использовать то же самое дерево, считывается по одной цифре и делается шаг по дереву, пока не достигается лист — тогда выводится символ, стоящий в листе и производится возврат в корень.
Для того чтобы закодированное сообщение удалось декодировать, декодеру необходимо иметь такое же кодовое дерево (в той или иной форме), какое использовалось при кодировании. Поэтому вместе с закодированными данными мы вынуждены сохранять соответствующее кодовое дерево. Ясно, что чем компактнее оно будет, тем лучше.
Алгори́тм Ле́мпеля — Зи́ва -это универсальный алгоритм сжатия данных без потерь. Алгоритм разработан так, чтобы его можно было быстро реализовать, но он не обязательно оптимален, поскольку он не проводит никакого анализа входных данных.
Схема сжатия без потерь Лемпела-Зива позволяет работать с данными любого типа, обеспечивая достаточно быстрое сжатие и распаковку данных. На основе входного потока данных алгоритм формирует словарь данных (его также называют переводной таблицей или таблицей строк). Образцы новых данных сравниваются с записями словаря. Если они там не представлены, то создается новая кодовая фраза. Если строка повторно встречается во входном потоке, то в выходной поток записывается ссылка на соответствующую строку словаря, которая имеет меньшую величину, чем исходный фрагмент данных. Таким образом реализуется сжатие информации.
Декодирование LZW-данных производится в обратном порядке. Декомпрессор читает код из потока данных и, если этого кода еще нет в словаре, добавляет его туда. Затем этот код переводится в строку, которую он представляет, и заносится в выходной поток несжатых данных.
/** Данный алгоритм при сжатии (кодировании) динамически создаёт таблицу преобразования строк: определённым последовательностям символов (словам) ставятся в соответствие группы бит фиксированной длины (обычно 12-битные). Таблица инициализируется всеми 1-символьными строками. По мере кодирования, алгоритм просматривает текст символ за символом, и сохраняет каждую новую, уникальную 2-символьную строку в таблицу в виде пары код/символ, где код ссылается на соответствующий первый символ. После того как новая 2-символьная строка сохранена в таблице, на выход передаётся код первого символа. Когда на входе читается очередной символ, для него по таблице находится уже встречавшаяся строка максимальной длины, после чего в таблице сохраняется код этой строки со следующим символом на входе; на выход выдаётся код этой строки, а следующий символ используется в качестве начала следующей строки.
Алгоритму декодирования на входе требуется только закодированный текст, поскольку он может воссоздать соответствующую таблицу преобразования непосредственно по закодированному тексту. **/
5 .Коды Хэмминга, свойство оптимальности
Коды Хэмминга
Помехоустойчивый код - двоичный код, позволяющий обнаруживать и корректировать ошибки при передаче данных. Код Хэмминга обнаруживает ошибки в двух битах и позволяет корректировать один бит. Контрольные разряды занимают позиции с номерами i = 2^j, j=0,1,2,.... Значения контрольных разрядов равно сумме разрядов, номера которых больше номера контрольного разряда и таких, что двоичное представление номера содержит единицу в разряде j начиная с младших разрядов.
B2 = B3 + B6 + B7 + B10 + B11 (если длина исходного слова 7 бит)
Если слово полученное после подстановки контрольных разрядов передано правильно, то выражение полученное в результате сложения контрольных разрядов и суммы, вычисленной по вышеуказнному правилу, будет равно 0.
S2= B2 + B3 + B6 + B7 + B10 + B11 (если длина исходного слова 7 бит)
Если какой-то разряд исказился, некоторые значения выражений будут равны 1. Пусть исказился Bi, тогда первое значение (S1) станет равно 1, если двоичное представление i содержит 1 в младшем разряде. Второе значение (S2), если во втором и т.д. Величина..,S3,S2,S1 - номер искажённого разряда.
entity Hamming is
port(Ic: in std_ulogic_vector(6 downto 0);
Id: in std_ulogic_vector(10 downto 0);
Oc: in std_ulogic_vector(10 downto 0);
Od: in std_ulogic_vector(6 downto 0);
end Hammaing;
Ic - вход для кодирования
Id - вход для декодирования
Oc - закодированное слово Ic
Od - декодированное слово Id
Коды БЧХ.
I. Введение. Для направления независимых ошибок более высокой кратности l ³2 используются циклические коды БЧХ (первые буквы фамилий Боуз, Чоудхури, Хоквинхем – авторов методики построения циклических кодов с dmin ³5).
В н.в. это одни из наиболее распространенных и эффективных корректирующих кодов.
II. Методика построения БЧХ. Методика построения кодов БЧХ аналогична общей методике построения ц. к. и отличается в основном выбором образующего многочлена.
Последовательность построения P(x) для кодов БЧХ тоже, что и для обычных ц.к., однако образующий полином является произведением t неприводимых полиномов,
G(x) = M1(x)*M2(x)…Mt(x), где t – кратность ошибки.
Методика выбора (построения) образующего полинома основана на понятии корня двоичного многочлена и теоремы БЧХ.
Понятие корня двоичного многочлена.
1. Элемент aявляется корнем двоичного полинома f(x), если f(a)=0.
2. Количество корней многочлена равно степени полинома.
Если f(x)=q0+q1x+q2x2+…+qnxn;
qn¹0; тогда a1, a2, a3...an при которых f(ai)=0, i=1,2,n.
Для построения полинома кодов БЧХ используется теорема БЧХ: (без доказательств)
Если образующий полином содержит непрерывную цепь из m корней, то данный порождающий полином обладает корректирующими свойствами кода с d min =m+1.
При этом ц.к., исправляющие одиночные ошибки являются частным случаем (m=2) из общей теоремы БЧХ.
Методика выбора порождающего полинома для кодов БЧХ.
1. Определение количества информационных разрядов:
k = [log2N].
2. Определение количества проверочных разрядов:
n = k + r = k + t * h £ 2h – 1;
t – кратность ошибки.
Длины кодовой комбинации n = k + r и степени бинома xn + 1.
3. Разложение (представление) xn + 1 в виде произведения неприводимых сомножителей (по таблице Питерсона).
4. Выбор неприводимых многочленов в качестве сомножителей образующего полинома т.о., чтобы
набор корней содержал непрерывную цепь корней длиной не менее чем m=dmin-1=2t;
5. Представление в виде произведения неприводимых сомножителей.
Этап декодирования аналогичен ц.к. При этом l >1.
одом Рида-Соломона (РС-кодом) называют циклический (N, K)-код, при N = q –1, множество кодовых комбинаций которого представляется многочленами степени N–1 и менее с коэффициентами из поля GF (q), где q > 2 и является степенью простого числа, а корнями порождающего многочлена являются N – K последовательных степеней: a, a2, a3, …, aD–1, некоторого элемента a Î GF (q), где D – минимальное кодовое расстояние (N, K)-кода.
Из определения вытекает, что РС-код является подклассом БЧХ-кодов с m 0 = 1 [1]. Обычно считают элемент a примитивным элементом поля GF (q), т. е. все степени a от 1-й до (q –1)-й являются всеми различными ненулевыми элементами поля GF (q). Порождающий многочлен РС-кода имеет степень N – K = D–1 и по теореме Безу может быть найден в виде произведения
 .
.
В соответствии с теорией циклических кодов, порождающий многочлен g (x)является делителем xN–1 над GF (q).
Таким образом, РС-код над полем GF (q) имеет длину кодовой комбинации N = q –1, число избыточных элементов в ней N – K = D–1 и минимальное кодовое расстояние D = N – K +1.
Коды с подобным значением минимального кодового расстояния в теории кодирования получили название максимальных.
При фиксированных N и K не существует кода, у которого минимальное кодовое расстояние больше, чем у РС-кода. Этот факт часто является веским основанием для использования РС-кодов. В то же время РС-коды всегда оказываются короче всех других циклических кодов над тем же алфавитом. РС-коды длины N < q –1 называют укороченными, а коды длины q (или q +1) – расширенными (удлиненными) на один (или два) символа. В РС-коде может быть выбрано и другое значение m 0, если это оправдано.
11. Отечественные радиорелейные системы передачи прямой видимости
Радиорелейная линия – это цепочка из приемопередающих радиостанций, антенны которых находятся в прямой видимости друг от друга. Радиосвязь осуществляется на дециметровых и сантиметровых волнах. На таких частотах низкий уровень шума и радиоволны распространяются практически прямолинейно, что при использовании узконаправленных антенн позволяет осуществлять надежную радиосвязь при малой мощности передатчиков. Дальность прямой видимости зависит от высоты приемо-передающих антенн двух станций и на ровной местности может быть вычислена по формуле: 
где D – дальность прямой связи, м.;
H1 и H2, – высоты приемо-передающих антенн радиостанций, м.
Если расстояние между оконечным оборудованием больше прямой видимости, устанавливают дополнительные промежуточные станции – ретрансляторы.
Формат цифрового передаваемого сигнала, передаваемого ЦРРС может быть SDH емкостью 155 Мбит/с, PDH емкостью 2, 4, 8, 16, 34, 140 Мбит/с, а также для связи по протоколу Ethernet 10/100 Base T. Некоторые радиорелейные станции позволяют передавать несколько форматов, выбор нужного производится при конфигурировании оборудования.
В последнее время в России тоже началось производство ЦРРС для передачи сигнала STM-1. Это фирма "Микран"(Томск), разработавшая аппаратуру цифровых радиорелейных станций SDH иерархии МИК-РЛ4С - МИК-РЛ40С14pt; Широкое применение интегральных СВЧ - схем, программируемых СБИС и специализированных микросхем позволило создать компактную аппаратуру с высокими эксплуатационными характеристиками. Современные способы модуляции и кодирования (многоуровневая квадратурная модуляция QAM16/64/128, кодирование Рида-Соломона, турбокодирование) обеспечили высокую помехоустойчивость и эффективность использования частотного спектра.
Другая область применения – это оборудование внутризоновой сети. Его основное назначение – доставка оконечных цифровых потоков от магистральных оптоволоконных или РРЛ линий связи до потребителей. Особенно это актуально в условиях городской застройки, где нет возможности прокладки кабельных или оптоволоконных линий связи, а также при значительном удалении потребителя от магистрали. Кроме того, это оборудование активно используют компании сотовой связи для организации связи между базовыми станциями, а также провайдеры интернета. Оборудование такого класса обеспечивает передачу сигнала PDH 2, 4, 8, 34 Мбит/с. В этом секторе сейчас идет максимальное развитие РРЛ связи, что заметно по номенклатуре выпускаемого оборудования. Если лет пятнадцать назад подобные станции производились в основном за рубежом, то теперь в России имеются свои разработки в этой области, не уступающие по эксплуатационным характеристикам оборудованию европейских фирм.
Существуют также цифровые радиорелейные системы, имеющие возможность передачи сигнала не только 2-х мегабитные PDH потоки, но и в формате компьютерных сетей Ethernet 10 Base T. Применение таких РРЛ оправдано при использовании в корпоративных ведомственных сетях, особенно при территориальной разбросанности подразделений таких предприятий. Здесь следует выделить недавно выпущенную станцию "WOCCOM AS-40", которая позволяет передавать сигнал Ethernet 100 Base T. Частоты этой станции предполагают использование на небольших расстояниях, а физические размеры позволяют разместить ее даже на очень маленькой площади. Торговая марка WOCCOM объединила ряд российских предприятий с целью разработки и производства оборудования связи. Такие же характеристики, как "WOCCOM E1", "WOCCOM 4Е1", "WOCCOM Ethernet 10BaseT имеет аппаратура ООО РМ Телеком (www.rrs.ru) с названием "Астра Е1", "Астра 4Е1", "Астра Ethernet 10BaseT".
Особого упоминания заслуживают ЦРРС МИК-РЛ150М и МИК-РЛ400М уже упоминавшейся фирмы "Микран", которые предназначены для организации местных и технологических линий связи. Данные станции работают на частотах 150 и 400 МГц и используют антенны "волновой канал". Высокие технические параметры аппаратуры в сочетании со свойствами низкочастотных диапазонов радиоволн позволяют строить интервалы большой протяженности, в том числе на полузакрытых трассах. На базе аппаратуры МИК-РЛ150М и МИК-РЛ400М возможно создание быстро развертываемых мобильных комплексов для оперативной организации радиосетей. МИК-РЛ400М позволяет передавать один 2-х мегабитный поток, а МИК-РЛ150М цифровой поток емкостью 256 кбит/с. Подобными характеристиками обладают радиорелейные комплексы "АЗИД" и "Трасса" Омского радиозавода им. А.С.Попова.
Практически у каждого из вышеописанного оборудования есть свое программное обеспечение для контроля и управления оборудованием на всей протяженности трассы. Недостатком можно назвать отсутствие стандартов на систему управления оборудованием ЦРРЛ, что не дает возможности одной управляющей программой управлять оборудованием разных производителей. Поэтому при проектировании разветвленной сети ЦРРС следует отдать предпочтение производителям оборудования, у которых есть оборудование для передачи сигналов всех форматов, которые предполагается использовать.
Методы расширения спектра
При расширеннии спектра информационного сигнала, ширина полосы частот полученного сигнала становится во много раз шире, чем полоса исходного сигнала.
- FHSS (Frequency Hopping Spread Spectrum) — расширение спектра со скачкообразной перестройкой частоты. Метод формирования сигнала, основанный на использовании широкополосных сигналов со скачкообразной перестройкой частоты.
- DSSS (Direct Sequence Spread Spectrum) — расширение спектра методом прямой последовательности. Метод формирования широкополосного сигнала, при котором исходный двоичный сигнал преобразуется в псевдослучайную последовательность для манипуляции несущей. В эфир передается шумоподобный сигнал, обладающий всеми свойствами аддитивного белого шума.
Методы DSSS и FHSS
Обе технологии расширения спектра DSSS и FHSS основаны на применении двухэтапной модуляции несущей.
По методу DSSS каждый бит исходного сообщения представляется специальными 11-разрядными кодовыми комбинациями (путем выполнения логической операции "исключающее ИЛИ") и уже результирующая последовательность модулирует передаваемый в эфир радиосигнал (при этом используется фазовая модуляция несущей PSK: при каждом изменении логического уровня из 0 в 1 или из 1 в 0 происходит смещение фазы снусоидального колебания). Псевдослучайные кодовые комбинации, придают радиосигналу характер шума, в 11 раз увеличивая спектр частот исходного узкополосного сигнала и распределяя его мощность по всему диапазону. Для выделения полезной информации приемная сторона использует ту же кодовую последовательность. Поддержание синхронности фазы несущего колебания в приемнике и передатчике осуществляется последним посредством формирования через определенные промежутки времени специального синхросигнала.
Согласно методу FHSS модулирование несущего радиосигнала выполняется непосредственно исходным сообщением с использованием частотной модуляции, при которой передача логических уровней 0 и 1 осуществляется на частотах, расположенных несколько выше или ниже центральной. Расширение спектра производится периодическим, в соответствии с заданной последовательностью, используемой и передатчиком и приемником, изменением значения самой центральной частоты (стандартом IEEE 802.11 предусмотрены 79 возможных значений несущего колебания), причем длительность удержания частоты на каждом уровне (dwell time) составляет 20 мс. Строго говоря, сигнал FHSS можно считать широкополосным только на достаточно большом интервале времени, включающем много периодов удержания, поскольку на каждом из последних диапазон частот передаваемого радиосигнала определяется спектром исходного сообщения, т.е. фактически является узкополосным.
Помехоустойчивость
Узкополосные помехи
В системах DSSS энергия полезного сигнала распределена по всему диапазону радиоволн (для обеспечения максимальной скорости передачи данных 11 Мбит/с, предусмотренной стандартом IEEE 802.11, требуется полоса частот примерно 22 МГц), поэтому во входных цепях приемных устройств используются широкополосные фильтры. Наличие узкополосных помех небольшой интенсивности на любой из частот диапазона не приводит к сбоям (информация восстанавливается в приемнике из "неповрежденных" участков спектра), однако если по энергии помеха сопоставима с полезным сигналом, то работа системы может быть полностью заблокирована. В системах FHSS вероятность появления помех повышается за счет более широкого диапазона используемых частот (83,5 МГц), однако если паразитный сигнал занимает узкий участок спектра, то его воздействие скажется только на отдельных скачках с близким значением несущей. Результатом будет лишь некоторое снижение производительности системы (из-за необходимости повторения испорченного фрагмента сообщения на следующем скачке).
Широкополосные помехи
Активность нескольких радиосистем, расположенных по-соседству, может приводить к повышению общего уровня зашумленности эфира на достаточно протяженных участках спектра. И хотя, в принципе, применяемая в системах DSSS фазовая модуляция радиосигнала позволяет работать при более высоком отношении сигнал/шум, чем частотная модуляция несущей, используемая в устройствах FHSS, вероятность появления помехи, охватывающей полосу в 20 МГц значительно выше, чем весь 80-МГц диапазон. Поэтому на практике системы FHSS оказываются более устойчивыми к широкополосным помехам и могут продолжать работать (хотя и с пониженной пропускной способностью) в условиях, когда системы DSSS уже не способны нормально воспринимать полезный сигнал.
Интерференционные помехи
Интерференционные помехи, возникающие из-за многократного отражения радиоволн от окружающих предметов, проявляются в одновременном поступлении в приемник множества "копий" полезного сигнала со смещеными фазами, что может приводить к его ослаблению или даже полному исчезновению на отдельных участках спектра (так называемый "фединг"). При одних и тех же внешних условиях системы DSSS оказываются более устойчивыми к федингу, чем FHSS (как и в случае узкополосных помех, полезный сигнал оказывается искаженным только на отдельных частотах), однако они гораздо чувствительнее к смещению во времени продетектированного двоичного сигнала - из-за значительно более короткой (примерно в десять раз) длительности импульсов возрастает вероятность неправильной интерпретации уровней 0 или 1 при стробировании.
Пропускная способность
Для систем DSSS и FHSS, основанных на спецификациях базового стандарта IEEE 802.11, определена скорость передачи данных 1 и 2 Мбит/с. Поскольку здесь имеются ввиду все биты сообщения, а полезная информация составляет лишь часть кадра, включающего также служебные разряды (например, контрольные), то реальная пропускная способность системы оказывается меньше. Дополнительные "накладные расходы" вносят и сами протоколы передачи данных (процедуры обмена служебными кадрами при "опознавании" рабочих станций, для целей синхронизации, повторной передачи информационных кадров при обнаружении ошибок и т.д.)
В среднем системы DSSS, работающие на скорости 2 Мбит/с, имеют пропускную способность 1,4 Мбит/с. Для систем FHSS этот показатель несколько ниже из-за дополнительных потерь на синхронизацию передатчика и приемника после каждого переключения на новую частоту.
Увеличение общей пропускной способности можно получить за счет развертывания в одной зоне нескольких систем. В случае DSSS это можно было бы сделать на основе технологии кодового разделения каналов CDMA, т.е. применяя в них различные, некоррелированные между собой (так называемые ортогональные) кодовые последовательности. Свойство ортогональности позволяет приемным устройствам надежно выделять предназначенную им информацию, восприннимая радиосигналы от других систем как шум. Однако практическому использованию метода CDMA препятствует быстрый рост длины ортогональных последовательностей с увеличением их числа. Так, например, для развертывания 6 независимых систем DSSS потребовалось бы использовать 31-разрядные последовательности (представляющие каждый бит информационного сообщения) и необходимая полоса частот для обеспечения максимальной скорости передачи данных в 11 Мбит/с превысила бы весь отведенный для таких систем диапазон.
Коды Рида-Малера
Код является линейным блочным кодом и задается двумя целыми числами. Параметр 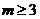 определяет длину кодовых комбинаций
определяет длину кодовых комбинаций
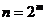 . .
| (3.30)
|
И параметр р – это порядок кода ( ). Тогда количество информационных символов
). Тогда количество информационных символов
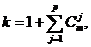
|
(3.31)
|
а кодовое расстояние равно

| (3.32)
|
Код Рида-Малера в общем случае не является систематическим. Если р принимает максимальное значение р = m -1, то 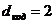 , и он эквивалентен коду с поверкой на чётность. В другом крайнем случае р =1 имеем
, и он эквивалентен коду с поверкой на чётность. В другом крайнем случае р =1 имеем
k =1+ m, 
| (3.33)
|
Производящая матрица G кода первого порядка строится следующим образом. Сначала записывают строку, состоящую из n единиц. Чтобы получить остальные m строк, в качестве столбцов записывают всевозможные m -разрядные двоичные числа, включая нулевое (полученные таким образом m строк  называются базисными векторами первого порядка).
называются базисными векторами первого порядка).
Чтобы получить матрицу G кода второго порядка, дописывают ещё 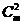 строк, называемых базисными векторами второго порядка. Каждый из этих векторов получаем путём попарного поэлементного перемножения базисных векторов первого порядка (всего имеем различных пар).
строк, называемых базисными векторами второго порядка. Каждый из этих векторов получаем путём попарного поэлементного перемножения базисных векторов первого порядка (всего имеем различных пар).
Для кода третьего порядка дописываем 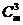 базисных векторов третьего порядка путём такого же перемножения различных троек векторов gj и т.д., пока не сформируем матрицу G нужного порядка.
базисных векторов третьего порядка путём такого же перемножения различных троек векторов gj и т.д., пока не сформируем матрицу G нужного порядка.
Пример. Построить матрицу G для кода Рида-Малера первого порядка с параметрами m =3, р =1. Получаем
 . .
|
(3.34)
|
Код Рида-Малера первого порядка обладает одним примечательным свойством. Если два возможных значения каждого символа обозначить как +1 и -1, то это лучше соответствует случаю, когда их передача производится импульсами различных полярностей. Затем возьмём из кодовой таблицы два вектора-строки a и b и вычислим их скалярное произведение (суммирование обычное). В итоге получим один из двух результатов
 . .
|
(3.35)
|
Это значит, что для каждой кодовой комбинации в таблице есть одна комбинация, противоположная первой (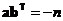 ), а остальные комбинации ортогональны ей, то есть удалены от неё на одно и то же расстояние, равное n /2 (по Xэммингу) или
), а остальные комбинации ортогональны ей, то есть удалены от неё на одно и то же расстояние, равное n /2 (по Xэммингу) или  (по Евклиду). Система сигналов, обладающих таким свойством, называется биортогональной.
(по Евклиду). Система сигналов, обладающих таким свойством, называется биортогональной.
При большом значении m и малом р коды Рида-Малера имеют очень большую корректирующую способность ( ) и, соответственно, очень большую избыточность. Например, при m =8, р =1 кодовая комбинация, состоящая их 256 символов, содержит всего 9 информационных и 247 проверочных символов. Для этого кода
) и, соответственно, очень большую избыточность. Например, при m =8, р =1 кодовая комбинация, состоящая их 256 символов, содержит всего 9 информационных и 247 проверочных символов. Для этого кода 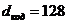 , значит, он способен обнаруживать любые ошибки до 127-кратных и исправлять до 63-кратных. Такая способность является явно излишней в обычных условиях, поэтому коды малого порядка имеет смысл использовать лишь в экстремальных ситуациях, при очень малом отношении сигнал/помеха.
, значит, он способен обнаруживать любые ошибки до 127-кратных и исправлять до 63-кратных. Такая способность является явно излишней в обычных условиях, поэтому коды малого порядка имеет смысл использовать лишь в экстремальных ситуациях, при очень малом отношении сигнал/помеха.
Кодирование кодом Рида-Малера удобно проводить по формуле (3.21), при этом строки матрицы G не обязательно хранить в памяти кодера. Их можно генерировать в процессе кодирования очередной кодовой комбинации при помощи m -разрядного двоичного счётчика, если на его выход подать последовательность тактовых импульсов.
Декодирование кода Рида-Малера – это зачастую довольно трудоёмкая операция. Если 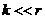 , то вполне возможно, что более экономным окажется способ декодирования по минимуму расстояния.
, то вполне возможно, что более экономным окажется способ декодирования по минимуму расстояния.
Кодирование видеоизображения, MPEG-2.
Существует две группы методов сжатия видеоизображений: без потерь и с потерями. В первом случае полностью восстанавливается вся исходная информация, в том числе, цветовой оттенок каждого отдельного пикселя. Во втором же - часть информации теряется, т. е. изображение становится несколько менее качественным, некоторые мелкие его детали утрачиваются. Во многих случаях это вполне допустимо, так как человеческий глаз различает, в лучшем случае, лишь несколько тысяч оттенков цвета и не реагирует на мел кие детали изображения.
Видеоданные по своей природе занимают чрезвычайно большой объем. Над задачей возможно более эффективного сжатия видео уже много лет бьются специалисты в этой области. В начале третьего тысячелетия в связи с острой необходимостью передавать большие объемы видео по различным сетям, задача оптимального по соотношению качество/объем способа кодирования видео стала еще более актуальной.
Концепция сжатия видео в MPEG очень проста - определить, какая именно информация в потоке повторяется хотя бы в течении какого-то отрезка времени и принять меры к избежанию дублирования этой информации. Наиболее ценное достоинство MPEG кодирования, особенно удобное для передачи по различным сетям - возможность гибкой настройки качества изображения в зависимости от пропускной способности сети. Это и сделало MPEG-2 фактическим стандартом для приема/передачи цифрового телевидения по различным сетям.
MPEG
Основы разработки стандарта MPEG были заложены группой ученых из MPEG (Motion Picture Experts Group) еще в 80х годах прошлого века. Основной принцип MPEG сжатия это сравнение двух последовательных образов и передача по сети только небольшого количества кадров (так называемые I-frame или ключевые кадры), содержащих полную информацию об изображении. Остальные кадры (промежуточные кадры, P-frame) содержат только отличия этого кадра от предыдущего. Иногда применяют двунаправленные кадры (B-frame), информация в которых кодируется на основании предыдущего и последующего кадров, что позволяет дополнительно повысить степень сжатия видео. Во всех форматах MPEG используетсят метод компенсации движения.
Несмотря на большую сложность при кодировании/декодировании видео сигнала, MPEG сжатие позволяет значительно снизить (в разы) объемы передаваемой по сети информации по сравнению с MotionJPEG.
Основа кодирования у группы алгоритмов MPEG общая. Основные идеи, применяемые в ходе сжатия видеоданных с ее помощью, следующие:
- устранение временной избыточности видео, учитывающее тот факт, что в пределах коротких интервалов времени большинство фрагментов сцены оказываются неподвижными или незначительно смещаются по полю.
- устранение пространственной избыточности изображений путем подавления мелких деталей сцены, несущественных для визуального восприятия человеком.
- использование более низкого цветового разрешения при yuv-предеставлении изображений (y — яркость, u и v — цветоразностные сигналы) — установлено, что глаз менее чувствителен к пространственным изменениям оттенков цвета по сравнению с изменениями яркости.
- повышение информационной плотности результирующего цифрового потока путем выбора оптимального математического кода для его описания (например, использование более коротких кодовых слов для наиболее часто повторяемых значений).
На данный момент существует три стандарта MPEG для передачи видео информации.
MPEG-1 был стандартизован и начал использоваться в 1993. Он был предназначен сжатия и хранения видео на компакт дисках. Большинство кодирующих устройств MPEG-1 и декодеров разработаны для скорости передачи данных порядка 1.5Mbit/s при разрешении CIF. Основной упор при его разработке делался на сохранении постоянной скорости передачи, при переменном качестве видео изображения, сравнимым с качеством VHS. При кодировании используется дискретно-косинусное преобразование - выполняется апроксимация внутри блока 8х8 пикселей волновыми функциями. Скорость передачи видео изображения в MPEG-1 ограничена 25 кадрами в секунду в стандарте PAL и 30 в NTSC. В данный момент этот стандарт практически не используется.
MPEG-2 был принят в качестве стандарта в 1994 для применения в высококачественном цифровом видео (DVD), цифровом телевидении высокого качества (HDTV), интерактивных носителях информации (ISM), цифровом радиовещательном видео (DBV) и кабельном телевидении (CATV). При разработке MPEG-2 усилия были сосредоточены на расширении техники сжатия MPEG-1, позволяющей обрабатывать большие изображения с более высоким качеством при более низкой степени сжатия и более высокой скорости побитной передачи данных.. Так же, как и в MPEG-1 при кодировании используется дискретно-косинусное преобразование, но обрабатываемые блоки увеличены в 4 раза - 16х16 пикселей. Скорость передачи видео изображения ограничена 25 кадрами в секунду в стандарте PAL и 30 в NTSC, так же, как в MPEG-1.
MPEG-4 – дальнейшее развитие стандарта MPEG-2. Основы разработки стандарта MPEG-4 были заложены группой ученых из MPEG еще в 1993 году, и уже к концу 1998 года произошло утверждение первого стандарта. Впоследствии стандарт неоднократно дорабатывался, в 1999 году получил официальный статус и затем был стандартизован со стороны ISO/IEC.
Целью создания MPEG-4 была выработка стандарта кодирования, который обеспечил бы разработчиков универсальным средством сжатия видеоданных, позволяющим обрабатывать аудио- и видеоданные как естественного (снятого с помощью видеокамеры или записанного с помощью микрофона), так и искусственного (синтезированного или сгенерированного на компьютере) происхождения. Это обстоятельство кардинальным образом отличает MPEG-4 как видеостандарт от его предшественников MPEG-1 и MPEG-2, в которых эффективное сжатие данных достигается лишь применительно к естественному видео и аудио.
MPEG-4 обеспечивает необходимые средства для описания взаимного расположения объектов (элементов) сцены в пространстве и времени с целью их последующего представления потенциальным зрителям в ходе воспроизведения. Разумеется, такая трактовка предполагает разделение сцены на составляющие ее объекты, что само по себе является весьма трудоемкой задачей, к которой по сути и сводится MPEG-4-кодирование. Кроме того, при разработке стандарта MPEG-4 решались проблемы обеспечения воспроизведения объектов сцены в различных условиях пропускной способности сетей передачи данных. Был разработан формат, допускающий «





