

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Топ:
Теоретическая значимость работы: Описание теоретической значимости (ценности) результатов исследования должно присутствовать во введении...
Особенности труда и отдыха в условиях низких температур: К работам при низких температурах на открытом воздухе и в не отапливаемых помещениях допускаются лица не моложе 18 лет, прошедшие...
Методика измерений сопротивления растеканию тока анодного заземления: Анодный заземлитель (анод) – проводник, погруженный в электролитическую среду (грунт, раствор электролита) и подключенный к положительному...
Интересное:
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является...
Принципы управления денежными потоками: одним из методов контроля за состоянием денежной наличности является...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Еще одним алгоритмом, реализованным на ассемблере, был алгоритм Кнута-Морриса-Пратта. В этом алгоритме сравнение строки y с образцом х происходит по байтам с использованием команды cmpsb. При сравнении строк если какой-либо символ y [ j ] не совпадает с x [ i ], где 0 < i < m, то следующими будут сравниваться символы y [ j ] и x [ k ], где 0 < k < i, при этом значение индекса k берется из таблицы смещений table, которая формируется на основе строки х перед началом поиска. Если полученное из таблицы значение k равно 0, то следующими сравниваются не y [ j ] и x [ k ], а y [ j+1 ] и x [ 0 ].
Таблица table формируется при сравнении строки x с собой. При этом в метод формирования таблицы, по сравнению с классическим алгоритмом, были внесены изменения. Так предполагается формирование таблицы длиной m+1, а не m. При этом в позицию table[ 0 ] всегда записывается 0, а остальные позиции формируются на основании зависимости
table[ i ] = f (x [ i-1 ]). Таким образом данная таблица смещена относительно оригинальной на один символ вправо (рис. 2.7), а следовательно k будет равно table[ i ].

Рисунок 2.7. Модификация таблицы смещений.
На формирование таблицы заранее выделяется память в объеме 256 байт, следовательно, данный алгоритм функционирует для поиска строки x, имеющей длину не более 255 символов. В данном алгоритме также предполагается вычисление длины строки x. Исходный код реализации алгоритма Кнута-Морриса-Пратта на ассемблере имеет следующий вид:
.text
.globl mystrstr
.type mystrstr, @function
mystrstr:
.cfi_startproc
pushl %ebp
movl %esp, %ebp
pushl %esi
pushl %edi
pushl %ebx
lea table, %ebx
cld
movl 12(%ebp), %edi
xorl %eax, %eax
movl $254, %edx
movl $0xff, %ecx
repne scasb
jcxz.Ltmp1
jmp.Ltmp2
.Ltmp1: jmp.Lexit
.Ltmp2: subl %ecx, %edx
movl %edx, %ecx
lea table, %ebx
movb %al, (%ebx)
inc %ebx
movb %al, (%ebx)
|
|
inc %ebx
movl 12(%ebp), %edi
movl 12(%ebp), %esi
inc %edi
.Lloop: cmpsb
jne.Le3
.Le1: inc %al
.Le2: movb %al, (%ebx)
inc %ebx
loop.Lloop
jmp.Lwork
.Le3: dec %esi
subl 12(%ebp), %esi
movb table(%esi), %al
movl 12(%ebp), %esi
addl %eax, %esi
dec %edi
cmpsb
je.Le1
testb %al, %al
jne.Le3
movl 12(%ebp), %esi
jmp.Le2
.Lwork: xorl %eax, %eax
movl %edx, %ebx
xorl %edx, %edx
movl 8(%ebp), %edi
.Lstad: movl 12(%ebp), %esi
addl %eax, %esi
movl %ebx, %ecx
subl %eax, %ecx
.Lcmp: cmp (%edi), %dl
je.Lexit
cmpsb
jne.Lcmp1
dec %ecx
jcxz.Lexit1
jmp.Lcmp
.Lcmp1: dec %esi
subl 12(%ebp), %esi
movb table(%esi), %al
cmp $0, %esi
je.Lstad
dec %edi
jmp.Lstad
.Lexit1:movl %edi, %eax
subl %ebx, %eax
jmp.Lexit2
.Lexit: xorl %eax, %eax
.Lexit2:popl %ebx
popl %edi
popl %esi
popl %ebp
ret
.cfi_endproc
.bss
table:
.space 256
Алгоритм Бойера-Мура
Данный алгоритм разработанный двумя учеными Робертом Бойером и Джем Муром в 1977 году, считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке [29]. Преимущество этого алгоритма в том, что ценой некоторого количества предварительных вычислений над шаблоном (но не над строкой, в которой ведётся поиск) шаблон сравнивается с исходным текстом не во всех позициях - часть проверок пропускаются как заведомо не дающие результата.
Данный алгоритм совершает 3n сравнений в худшем случае при поиске первого совпадения с непериодничным образцом и O(n*m) при поиске всех вхождений. В алгоритме Бойера-Мура образец движется вдоль строки текста слева направо, однако фактические сравнения символов выполняются справа налево. В случае несовпадения (или, наоборот, полного попадания) используются две заранее вычисляемые функции: функция плохого символа и функция хорошего суффикса.
Первыми, таким образом, сравниваются символы x [ m-1 ] и y [ m-1 ]. Если они не совпадают и y [ m-1 ] не встречается нигде в подстроке x, мы можем спокойно сдвинуть образец на m символов вправо, так как можем быть уверены, что ни одна из начинающихся с одной из первых m позиций подстрок не совпадает с образцом. Следующими сравниваются x [ m-1 ] и y [ 2*m-1 ].
Пусть отвергающими оказались символы x [ m-1 ] и y[ i ]. Как уже говорилось, если y [ i ] не содержится нигде в образце, шаблон можно сдвинуть на m позиций вправо. С другой стороны, если y [ i ] присутствует в образце, и x [ m-s-1 ] – его самое правое вхождение, то образец можно сдвинуть лишь на s позиций вправо, совмещая x[ m-s-1 ] с y [ i ]. Проверку можно продолжить сравнением x [ m-1 ] с y [ i+s ], то есть текстовый индекс мы увеличиваем на s.
|
|
Если x [ m-1 ] и y [ i ] совпадают, нужно сравнивать предшествующие им символы в образце и тексте, пока вся подстрока текста не будет сопоставлена с образцом или пока не встретится несовпадение. Предположим, что несовпадение произошло между символом образца x [ j ] = b и символом текста y [ i+j ] = a на позиции i, то мы знаем, что y [ i+j+1, i+m-1 ] = x [ j+1, m-1 ] = u и y [ i+j ] ≠ x [ j ].
Теперь, если самым правым вхождением y [ i+j ] в образец снова является, скажем, x [ m-s-1 ], образец можно сдвинуть на j-m+s позиций вправо, так что x [ m-s-1 ] окажется на одной позиции с y [ i+j ]. Процедуру можно продолжить сравнением x [ m-1 ] с соответствующим символом, в данном случае с y [ i+j+s ]. Приращение индекса текста с позиции несовпадения до следующей пробной позиции равно, таким образом, [ i+j+s ] - [ i+j ] = s.
Если x [ m-s-1 ] находится правее x [ j ], то значение j-m+s отрицательно, так что совмещение x [ m-s-1 ] с y [ i+j-s ] ничего не даст, поскольку повлечет за собой шаг назад. В этих обстоятельствах образец лучше сдвинуть на одно место вправо и сравнивать x [ m-1 ] с y [ i+1 ]. Для этого нужно увеличить индекс текста на [ i+1 ] - [ i+j-m ] = j-m+1.
Таким образом, функция плохого символа выравнивает символ текста y [ i + j ] по его самому правому появлению в x [ 0... m-s-1 ]. Если его там нет - сдвигаем на всю длину образца: левый конец теперь - y [ i + j + m ].
Приращения s, используемые в эвристике вхождения, вычисляются заранее и хранятся в таблице bmBc. В процессе поиска таблица индексируется отвергающими символами текста, поэтому требуется таблица размером с используемый алфавит символов, то есть SIGMA. Вход для символа w равен m-j, где x[ j ] – самое правое вхождение w в x, и равен m-1, если w не содержится в x, то есть:
bmBc[ w ] = min { s: s = m или (0 ≤ s < m и x [ m-s-1 ] = w)}Если, как в описанном выше случае, несовпадение встречено уже после того, как найдено частичное совпадение, иногда можно продвинуться дальше, чем позволяет эвристика вхождения. Если это так, лучше взять больший сдвиг, определяемый эвристикой сопоставления. При этом используется таблица, похожая на используемую в алгоритме Кнута-Морриса-Пратта. Идея состоит в том, что в результате сдвига символы образца должны быть равны всем тем символам текста, с которыми они совпадали перед этим, а на месте отвергающего символа должен оказаться другой.
|
|
Как уже говорилось, особый интерес представляет ситуация, когда часть образца содержится в текущей части текста, то есть x [ j+1, m-1 ] = y [ i+j+1, i+m-1 ] и x [ j ] ≠ y [ i+j ]. Если суффикс x [ j+1, m-1 ] входит также в x как подстрока x [ j+1-t, m-t-1 ], причем x [ j-t ] ≠ x [ j ], и это самое правое из подобных вхождений, то образец можно сдвинуть на t мест вправо. При этом мы совмещаем x [ j+1-t, m-t-1 ] с y [ i+j+1, i+m-1 ] и процесс поиска можно возобновить, сравнивая x[ m-1 ] с y[ i+t ]. Таблица bmGs, содержащая информацию о сдвиге t, вычисляется заранее на основании образца и индексируется той позицией образца, в которой встретилось несовпадение. Значение bmGs[ j ] равняется сдвигу t образца плюс дополнительный сдвиг, требуемый для того, чтобы возобновить сравнение от правого края образца. Значение i+m-1 – это минимум, такой что, если x [ j ] ≠ y [ i+j ], то x [ j+1-t, m-t-1 ] совпадет с y [ i+j+1, i+m-1 ]. Итак, входы таблицы bmGs определяются следующим выражением:
bmGs [ j ] = min{ t + m - j: t ≥ 1 и (t ≥ j или x [ j-t ] ≠ x [ j ]) и ((t ≥ k или x [ k-t ] = x [ k ]) для j < k ≤ m)}
Таким образом, значение bmGs [ j ] равно требуемому приращению для индекса текста с текущей позиции y[ i+j ] до позиции следующего сравнения y[ i+t ], то есть [ i+t ] - [ i+j ] = t-j.
Следовательно функция хорошего суффикса состоит в выравнивании сегмента y [ i+j+1, i+m-1 ] = x [ j+1, m-1 ] = u по его самому правому появлению в x, так чтобы ему предшествовал символ, несовпадающий с x [ j ] (рис. 2.8.). Если такого сегмента нет, то сдвиг выравнивает наибольший суффикс v отрезка y [ i+j+1,i+m-1 ] по совпадающему префиксу x.
Из определения bmGs [ j ] можно углядеть, что bmGs [ j ] ≥ [ m-j ]. Так, в указанном выше случае, где индекс текста следует увеличить на m-j , вместо соответствующего значения bmGs, так как последнее вызывает сдвиг образца назад. Таким образом, в случае несовпадения следует использовать максимальное из двух значений, взятых из описанных выше таблиц.

Рисунок 2.8. Осуществление сдвига в алгоритме Бойера-Мура.
Исходный код реализации алгоритма Бойера-Мура имеет следующий вид:
|
|
/*Построение таблицы для сдвига по функции плохого символа*/
void preBmBc(unsigned char *x, int m, int bmBc[]) {
int i;
for (i = 0; i < SIGMA; ++i)
bmBc[i] = m;
for (i = 0; i < m - 1; ++i)
bmBc[x[i]] = m - i - 1;
}
void suffixes(unsigned char *x, int m, int *suff) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && x[g] == x[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}
/*Построение таблицы для сдвига по функции хорошего суффикса*/
void preBmGs(unsigned char *x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
char * search(unsigned char *y, unsigned char *x, int m) {
int i, j, bmGs[XSIZE], bmBc[SIGMA], n;
char * yy;
yy=y;
n=strlen(y);
/*Подготовительные вычисления*/
preBmGs(x, m, bmGs);
preBmBc(x, m, bmBc);
/*Поиск*/
j = 0;
while (j <= n - m) {
for (i = m - 1; i >= 0 && x[i] == y[i + j]; --i);
if (i < 0)
return yy+j;
else
j += MAX(bmGs[i], bmBc[y[i + j]] - m + 1 + i);
}
return NULL;
}
Турбо-алгоритм Бойера-Мура
Данный алгоритм был разработан в 1994 году [34] и представляет собой дальнейшее улучшение алгоритма Бойера-Мура, не дающего значительной регрессии при использовании коротких алфавитов. Этот алгоритм позволяет запоминать сегмент текста, который сошелся с суффиксом образца во время прошлой попытки, что, в случае если произошел сдвиг по хорошему суффиксу, дает два преимущества:
· возможность перескочить через этот сегмент;
· возможность применения «турбо-сдвига» (рис 2.9.).
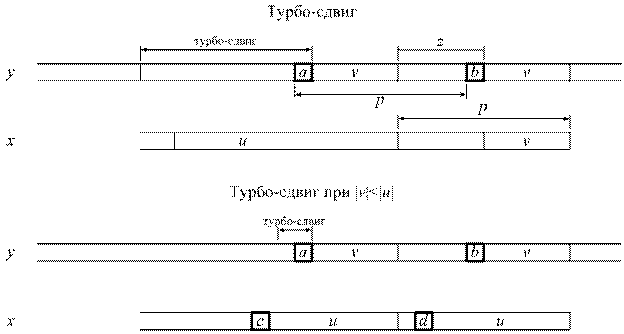
Рисунок 2.9. Осуществление турбо-сдвига.
Турбо-сдвиг может произойти, если мы обнаружим, что суффикс образца, который сходится с текстом, короче, чем тот, который был запомнен ранее.
Пусть u - запомненный сегмент, а v – суффикс, совпавший во время текущей попытки, такой что uzv - суффикс x. Предположим два символа а и b встречаются на расстоянии p в тексте, и суффикс x длины | uzv | имеет период длины p, а значит не может перекрыть оба появления символов а и b в тексте. Наименьший возможный сдвиг имеет длину | u | - | v |, который и получил название турбо-сдвига.
При | v | < | u |, если сдвиг по плохому символу больше, то совершаемый сдвиг будет больше либо равен | u | + 1. В этом случае символы c и d различны, так как мы предположили, что предыдущий сдвиг был сдвигом хорошего суффикса. Тогда сдвиг больший, чем турбо-сдвиг, но меньший | u | + 1 совместит c и d с одним и тем же символом v. Значит, если сдвиг плохого символа больше, то мы можем применить сдвиг больший, либо равный | u | + 1. Исходный код реализации турбо-алгоритма Бойера-Мура имеет следующий вид:
/*Построение таблицы для сдвига по функции плохого символа*/
void preBmBc(unsigned char *x, int m, int bmBc[]) {
int i;
for (i = 0; i < SIGMA; ++i)
bmBc[i] = m;
for (i = 0; i < m - 1; ++i)
bmBc[x[i]] = m - i - 1;
|
|
}
void suffixes(unsigned char *x, int m, int *suff) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && x[g] == x[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}
/*Построение таблицы для сдвига по функции хорошего суффикса*/
void preBmGs(unsigned char *x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
char * search(unsigned char *y, unsigned char *x, int m) {
int bcShift, i, j, shift, u, v, turboShift, bmGs[XSIZE], bmBc[SIGMA], n;
char * yy;
yy=y;
n=strlen(y);
/*Подготовительные вычисления*/
preBmGs(x, m, bmGs);
preBmBc(x, m, bmBc);
/*Поиск*/
j = u = 0;
shift = m;
while (j <= n - m) {
i = m - 1;
while (i >= 0 && x[i] == y[i + j]) {
--i;
if (u!= 0 && i == m - 1 - shift)
i -= u;
}
if (i < 0)
return yy+j;
else {
v = m - 1 - i;
turboShift = u - v;
bcShift = bmBc[y[i + j]] - m + 1 + i;
shift = MAX(turboShift, bcShift);
shift = MAX(shift, bmGs[i]);
if (shift == bmGs[i])
u = MIN(m - shift, v);
else {
if (turboShift < bcShift)
shift = MAX(shift, u + 1);
u = 0;
}
}
j += shift;
}
return NULL;
}
Алгоритм Чжу-Такаоки
Этот алгоритм, разработанный в 1987 году [73], представляет собой еще одну реализацию алгоритма Бойера-Мура, специально оптимизированную под короткие алфавиты. Эго основной целью было улучшение эвристики функции плохого символа, которая у обычного алгоритма Бойера-Мура при использовании таких алфавитов отказывала уже на коротких суффиксах. При этом улучшение эвристики достигается благодаря тому, что вместо таблицы для одного плохого символа, этот алгоритм строит таблицы для пары символов, несовпавшего и идущего перед ним. Данная таблица представляется в виде матрицы ztBc размера [SIGMA] * [SIGMA]. Исходный код реализации алгоритма Чжу-Такаоки имеет следующий вид:
void suffixes(unsigned char *x, int m, int *suff) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && x[g] == x[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}
/*Построение таблицы для сдвига по функции хорошего суффикса*/
void preBmGs(unsigned char *x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
/*Построение таблицы для сдвига по функции плохого символа*/
void preZtBc(unsigned char *x, int m, int ztBc[SIGMA][SIGMA]) {
int i, j;
for (i = 0; i < SIGMA; ++i)
for (j = 0; j < SIGMA; ++j)
ztBc[i][j] = m;
for (i = 0; i < SIGMA; ++i)
ztBc[i][x[0]] = m - 1;
for (i = 1; i < m - 1; ++i)
ztBc[x[i - 1]][x[i]] = m - 1 - i;
}
char * search(unsigned char *y, unsigned char *x, int m) {
int i, j, ztBc[SIGMA][SIGMA], bmGs[XSIZE], n;
char * yy;
yy=y;
n=strlen(y);
/*Подготовительные вычисления*/
preZtBc(x, m, ztBc);
preBmGs(x, m, bmGs);
/*Поиск*/
j = 0;
while (j <= n - m) {
i = m - 1;
while (i >=0 && x[i] == y[i + j])
--i;
if (i < 0)
return yy+j;
else
j += MAX(bmGs[i],ztBc[y[j + m - 2]][y[j + m - 1]]);
}
return NULL;
}
Алгоритм GRASPM
Genomic Rapid Algorithm for String Pattern Matching (GRASPM) – алгоритм разработанный Серхио Диосдадо и Пауло Карвальо в 2009 году [35], специально для анализа геномных последовательностей. Этот алгоритм основан на использовании перекрывающегося 2-грамм частотного анализа, который позволяет улучшать эвристику сдвига. Алгоритм ориентирован на быстрый поиск коротких строк (последовательностей до 30 символов) в тексте, состоящем из ограниченного набора часто-повторяющихся символов. Исходный код реализации алгоритма GRASPM имеет следующий вид:
typedef struct GRASPmList {
int k;
struct GRASPmList *next;
} GList;
void ADD_LIST(GList **l, int e) {
GList *t = (GList *)malloc(sizeof(GList));
t->k = e;
t->next = *l;
*l = t;
}
char * search(unsigned char *t, unsigned char *p, int m) {
GList *pos, *z[SIGMA];
int i, j, k, first, hbc[SIGMA], n;
char * yy;
yy=t;
n=strlen(t);
/*Подготовительные вычисления*/
for(i=0; i<SIGMA; i++)
z[i]=NULL;
if (p[0] == p[m-1])
for(i=0; i<SIGMA; i++)
ADD_LIST(&z[i], 0);
for(i=0; i<m-1;i++)
if (p[i+1] == p[m-1])
ADD_LIST(&z[p[i]],(i+1));
for(i=0;i<SIGMA;i++)
hbc[i]=m;
for(i=0;i<m;i++)
hbc[p[i]]=m-i-1;
/*Поиск*/
j = m-1;
while (j<n) {
while (k=hbc[t[j]]) j += k; {
pos = z[t[j-1]];
while(pos!=NULL) {
k = pos->k;
i = 0;
first = j-k;
while(i<m && p[i]==t[first+i])
i++;
if(i==m && first<=n-m)
return yy+first;
pos = pos->next;
}
}
j+=m;
}
return NULL;
}
Алгоритм быстрого поиска
На основании анализа работы алгоритма Бойера-Мура, Даниэль Сандей в 1990 разработал несколько алгоритмов точного поиска подстроки в строке, один из которых назвал алгоритмом быстрого поиска [60]. Он обнаружил, что в алгоритме Бойера-Мура при обнаружении несовпадения, когда x[ m-1 ]совмещен с i-м символом текста, для обращения к таблице эвристики сопоставления вместо y[ i ] можно использовать следующий символ, то есть y[ i+1 ]. Основанием для этого является то, что при минимальном сдвиге образца, то есть на один символ вправо, y[ i+1 ] является частью следующей проверяемой подстроки текста. Сандей утверждал, что на практике в среднем это дает сдвиг, больший или равный сдвигу на значение, полученное из таблицы bmBc плохих символов алгоритма Бойера-Мура плюс один. Однако, такое преимущество в скорости уменьшается с увеличением длины образца.
Сандей отметил также, что символы образца и текущей подстроки текста можно сравнивать в любом порядке и использовал этот факт для улучшения общей эффективности. В алгоритме быстрого поиска, в отличае от алгоритма Бойера-Мура, сравнения выполняются строго слева направо и применяется только эвристика сопоставления. Исходный код реализации алгоритма быстрого поиска имеет следующий вид:
/*Построение таблицы смещений*/
void preQsBc(unsigned char *x, int m, int qbc[]) {
int i;
for(i=0;i<SIGMA;i++)
qbc[i]=m+1;
for(i=0;i<m;i++)
qbc[x[i]]=m-i;
}
char * search(unsigned char *y, unsigned char *x, int m) {
int i, s, qsbc[SIGMA], n;
char * yy;
yy=y;
n=strlen(y);
/*Подготовительные вычисления*/
preQsBc(x, m, qsbc);
/*Поиск*/
s = 0;
while(s<=n-m) {
i=0;
while(i<m && x[i]==y[s+i])
i++;
if(i==m)
return yy+s;
s+=qsbc[y[s+m]];
}
return NULL;
}
Алгоритм сдвига-или
Алгоритм сдвига-или (shift or), известный также как двоичный алгоритм (bitap algorithm) впервые был успешно применен для поиска подстроки в строке Рикардо Баэза-Ятесом и Гастоном Гоннета в 1992 году [28]. Он основан на том, что в современных компьютерах битовый сдвиг и побитовое ״ИЛИ״ является атомарной операцией. Таким образом, принцип функционирования данного алгоритма можно следующим образом.
Пусть R - битовый массив размера m, тогда вектор R [ i ] - значение массива R после обработки очередного символа. Он содержит информацию обо всех совпадениях префиксов образца х, которые оканчиваются на позиции i в тексте [ 0 ≤ j ≤ m-1 ], таким образом, что R [ i ] = 0, если x [ 0, j ] = y [ i-j, i ], или R [ i ]= 1, в противоположном случае. Тогда вектор R [ i+1 ] может быть вычислен по R [ i ]следующим образом. Для всех R [ i ][ j ] = 0: R [ i+1 ][ j+1 ] = 0, если x [ j+1 ] = y [ i+1 ], или R [ i+1 ][ j+1 ] = 1 в противоположном случае. И: R [ i+1 ][ 0 ] = 0, если x [ 0 ] = y [ i+1 ], или R [ i+1 ][ 0 ] = 1 в противоположном случае. Если R [ i+1 ][ m-1 ] = 0, тогда мы нашли совпадение.
Переход от вектора R [ i ] к вектору R [ i+1 ] можно очень быстро вычислить следующим образом. Для каждого символа a из S, пусть S [ a ]- битовый массив размера m такой, что для 0 ≤ j ≤ m-1, S [ a ]= 0 при x [ j ] = a. Тогда массив S [ a ] обозначает позиции символа a в образце x. Каждый такой массив S [ a ] может быть вычислен перед процессом поиска. Тогда процесс вычисления R[ i+1 ] укорачивается до двух операций ״СДВИГА״ и ״ИЛИ״: R [ i+1 ] = SHIFT(R [ i ]) OR S [ y ][ i+1 ]. Считая длину образца меньше длины компьютерного слова, можно уложиться в O(s+m) для предобработки и O(n) для поиска, независимо от длины алфавита и образца. При длине образца больше длины слова используется модифицированный алгоритм.
Таким образом, алгоритм сдвига-или по сути, он является примитивным алгоритмом поиска с небольшой оптимизацией, благодаря которой за одну операцию производится до 32 сравнений одновременно (или до 64, в зависимости от архитектуры процессора). Исходный код реализации алгоритма сдвига-или имеет следующий вид:
int preSo(unsigned char *x, int m, unsigned int S[]) {
unsigned int j, lim;
int i;
for (i = 0; i < SIGMA; ++i)
S[i] = ~0;
for (lim = i = 0, j = 1; i < m; ++i, j <<= 1) {
S[x[i]] &= ~j;
lim |= j;
}
lim = ~(lim>>1);
return(lim);
}
char * search_large(unsigned char *y, unsigned char *x, int m) {
unsigned int lim, D, k, h, p_len;
unsigned int S[SIGMA];
int j, n;
char *yy;
yy=y;
n=strlen(y);
p_len = m;
m=32;
/*Подготовительные вычисления*/
lim = preSo(x, m, S);
/*Поиск*/
for (D = ~0, j = 0; j < n; ++j) {
D = (D<<1) | S[y[j]];
if (D < lim) {
k = 0;
h = j-m+1;
while(k<p_len && x[k]==y[h+k])
k++;
if(k==p_len)
return yy+j-m+1;
}
}
return NULL;
}
char * search(unsigned char *y, unsigned char *x, int m) {
unsigned int lim, D;
unsigned int S[SIGMA];
int j, n;
if (m > WORD) return search_large(y, x, m);
char *yy;
yy=y;
n=strlen(y);
/*Подготовительные вычисления*/
lim = preSo(x, m, S);
/*Поиск*/
for (D = ~0, j = 0; j < n; ++j) {
D = (D<<1) | S[y[j]];
if (D < lim)
return yy+j-m+1;
}
return NULL;
}
Алгоритм Карпа-Рабина
Данный алгоритм был разработан Ричардом Карпом и Майклом Рабином в 1987 году [45]. В алгоритме Карпа-Рабина, как и в наивном методе, с образцом сопоставляются m-символьные подстроки текста, y[ i, i+m-1 ], для 0 ≤ i < n-m+1. Отличие состоит в том, что вместо того, чтобы сравнивать строки x[ 0, m-1 ] и y[ i, i+m-1 ], мы сравниваем два целых числа. Этими целыми числами являются хеш-значения соответствующих m-символьных строк.
Хеширование может позволить нам избежать квадратичного количества сравнений символов в обычных ситуациях. Вместо того, чтобы проверять каждую позицию на предмет соответствия с образцом, мы можем проверять только те, которые в наибольшей степени ״напоминают״ образец x. Для того, чтобы легко устанавливать явное несоответствие, используется функция хеширования. Такая функция должна удовлетворять следующим требованиям:
· легко вычисляться;
· как можно лучше различать несовпадающие строки;
· hash(y [ i+1, i+m ]) должна легко вычисляться по hash(y [ i, i+m-1 ]), то есть hash(y [ i+1, i+m ]) = rehash(y [ i ], y [ i+m ], hash(y [ i, i+m-1 ]).
Для данного алгоритма используется следующая хеш-функция:
hash(w) = w mod q
где q – большое простое число. В вычислениях m-символьные строки трактуются как m-значные целые числа по основанию SIGMA, где SIGMA – алфавит. Составляющие их символы, таким образом, считаются цифрами этого целого числа. В позиционном представлении самая значимая цифра идет первой. Таким образом, хеш-функция определяется для слова w следующим образом:
hash(w [ 0, m-1 ]) = (w [ 0 ] * 2m-1 + w [ 1 ] * 2m-2 +... + w [ m-1 ] * 2m-m) mod q.
Тогда rehash(a, b, h) = ((h - a * 2m-1) * 2 + b) mod q. Во время поиска х будем сравнивать hash(x) с hash(y [ i, i+m-1 ]) для i от 0 до n-m включительно.
Так как значения хеш-функции не уникальны, равенство двух сигнатур оказывается необходимым, но не достаточным условием совпадения строк. Поэтому, когда выявлено потенциальное соответствие, две строки сравниваются напрямую, чтобы проверить, нет ли конфликта сигнатур. Для больших хеш-таблиц шансы такого конфликта невелики.
Для текста длины n и шаблона длины m, его среднее время исполнения и лучшее время исполнения это O(n), но в худшем случае этот алгоритм имеет производительность O(n*m). Исходный код реализации алгоритма Карпа-Рабина имеет следующий вид:
#define REHASH(a, b, h) ((((h) - (a)*d) << 1) + (b))
char * search(char *y, char *x, int m) {
int d, hx, hy, i, j, n;
char *yy;
yy=y;
n=strlen(y);
/*Подготовительные вычисления*/
for (d = i = 1; i < m; ++i)
d = (d<<1);
for (hy = hx = i = 0; i < m; ++i) {
hx = ((hx<<1) + x[i]);
hy = ((hy<<1) + y[i]);
}
/*Поиск*/
j = 0;
while (j <= n-m) {
if (hx == hy && memcmp(x, y + j, m) == 0)
return yy+j;
hy = REHASH(y[j], y[j + m], hy);
++j;
}
return NULL;
}
|
|
|

Биохимия спиртового брожения: Основу технологии получения пива составляет спиртовое брожение, - при котором сахар превращается...

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!