В статистике различают функциональную связь и стохастическую зависимость.
Функциональной называют такую связь, при которой определенному значению факторного признака соответствует одно и только одно значение результативного признака.
Если причинная зависимость проявляется не в каждом отдельном случае, а в общем, среднем при большом числе наблюдений, то такая зависимость называется стохастической.
Частным случаем стохастической связи является корреляционная связь, при которой изменение среднего значения результативного признака обусловлено изменением факторных признаков.
По степени тесноты между факторными и результативными признаками связи подразделяются на сильные, умеренные и слабые.
По направлению действия различают прямую и обратную связи. При прямой связи с увеличением или уменьшением факторного признака происходит увеличение или уменьшение значений результативного. В случае обратной связи значение результативного признака изменяется под воздействием факторного, но в противоположном направлении по сравнению с изменением факторного признака.
По аналитическому выражению различают прямолинейные связи (или просто линейные) и нелинейные. Если статистическая связь между явлениями может быть приближенно выражена уравнением прямой линии, то ее называют линейной связью; если же она выражается уравнением какой – либо кривой линией (параболы, гиперболы, показательной, степенно и. т. д.) то такую связь называют нелинейной или криволинейной.
2. Качественные методы определения наличия связи
Для выявления наличия связи, ее характера и направления в статистике используются следующие качественные методы: приведения параллельных данных, аналитических группировок и графические методы.
Метод приведения параллельных данных основан на сопоставлении двух или нескольких рядов статистических величин. Такое сопоставление позволяет установить наличие связи и получить представление о ее характере.
Сравнивая изменение двух величин Х и У можно сделать вывод, что с увеличением величины Х величина У также возрастает. Поэтому связь между ними прямая, и описать ее можно либо уравнением прямой, либо параболы второго порядка.
Сущность метода аналитических группировок была рассмотрена на предыдущих занятиях.
Использование графических методов основывается на графическом построении поля корреляции. Для построения поля корреляции на оси абсцисс откладывается значение факторного признака, а на оси ординат – результативного. Каждое пересечение линий, проводимых через эти оси, обозначается точкой. При отсутствии тесных связей имеет место беспорядочное расположение точек на графике. Чем сильнее связь между признаками, тем теснее будут группироваться точки вокруг определенной линии, выражающей форму связи (рисунок 10).

Рисунок 10 – График корреляционного поля
Корреляционный анализ
Корреляционный метод анализа является составляющим элементом более общего метода количественного статистического анализа связей – корреляционно – регрессионного и имеет своей задачей количественное определение тесноты и направления связи между двумя признаками (при парной связи) и между результативным и множеством факторных признаков (при многофакторной связи).
В статистике принято различать следующие варианты зависимостей.
1. Парная корреляция – связь между двумя признаками (результативным и факторным или двумя признаками).
2. Частная корреляция – зависимость между результативным и одним факторным признаками при фиксированном значении других факторных признаков.
3. Множественная корреляция – зависимость результативного и двух или более факторных признаков, включенных в исследование.
Количественно оценить тесноту и направление связи между двумя признаками при парной линейной корреляции можно посредством расчета линейного коэффициент корреляции.
На практике применяются различные модификации формул для расчета, данного коэффициента. Наиболее простой из них является зависимость вида
 (48)
(48)
Физическая интерпретация значений линейного коэффициента корреляции приведена в таблице 24..
Таблица 24 - Количественные критерии оценки тесноты связи
| Величина коэффициента корреляции
| Характер связи
|
| До ½+ - 0,3½
½+ - 0,3½…½+ - 0,5½
½+ - 0,5½…½+ - 0,7½
½+ - 0,7½…½+ - 1,0½
| Практически отсутствует
Слабая
Умеренная
Сильная
|
Значимость линейного коэффициента корреляции проверяется на основе t- критерия Стьюдента. При этом выдвигается и проверяется нулевая гипотеза (Н0) о равенстве коэффициента корреляции нулю [Н0: r=0] При проверке этой гипотезы используется t-статистика.
 (49)
(49)
Если расчетное значение tр >tкр (табличное), то гипотеза Н0 отвергается, что свидетельствует о значимости линейного коэффициента корреляции, а, следовательно, и о статистической существенности зависимости между Х иУ. Данный критерий оценки значимости применяется для совокупностей n< 50.
При большем числе наблюдений (n>100) используется следующая формула для определения t - статистики
 . (50)
. (50)
Для статистически значимого линейного коэффициента корреляции определяют интервальные оценки с помощью z- распределения Фишера по формуле
 , (51)
, (51)
где tg - табулированные значения для нормального распределения, зависимые от g= 1-a (a - уровень значимости);
Z/ - табличные значения Z¢=f (r) – распределение.(Функция Z/ - нечетная, т. е. Z/ =f (-r) = - f (r).)
Пример. Порядок расчета линейного коэффициента корреляции. На основе выборочных данных о деловой активности однотипных коммерческих структур оценить тесноту связи между прибылью У (тыс. руб.) и затратами (Х) на 1 руб. произведенной продукции (таблица 25).
Алгоритм расчета.
1. Выполняем промежуточные расчеты (таблица 25).
2. Рассчитываем значения дисперсии
 = 632056,33 – (744,33)2 = 78029,3;
= 632056,33 – (744,33)2 = 78029,3;
 =7046,67 – (83,67)2 =46.
=7046,67 – (83,67)2 =46.
3.Рассчитываем значение коэффициента корреляции по формуле (48)
r= (60400,67 – 744,33*83,67)/(78029,3*46)0,5 = -0,98.
Таблица 25 -. Расчетная таблица для определения коэффициента корреляции
| №
п/п
| у
| х
| ух
| У2
| Х2
|
|
|
|
|
|
|
|
| Сумма
|
|
|
|
|
|
| Средняя
| 744,33
| 83,67
| 60400,67
| 632056,33
| 7046,67
|
4. Проверяем значимость коэффициента корреляции для этого рассчитываем t - статистику Стьюдента
 = (0,98/Ö1-(0,98)2)*Ö6-2 = 14,036.
= (0,98/Ö1-(0,98)2)*Ö6-2 = 14,036.
Сравниваем полученное значение с табличным при уровне значимости a=0,05 и числе степеней свободы k =6-2=4, которое равно t кр =2,776.
Вывод. Гипотеза Н0 отвергается так как | tр|>t кр =2,776, что свидетельствует о значимости данного коэффициента корреляции.
5. Рассчитываем доверительный интервал полученного коэффициента корреляции.
Так как предыдущий пункт расчета мы выполняли для уровня значимости a=0,05, то доверительная вероятность соответственно равна g = 1 -a = 1 – 0,05 = 0,95. Тогда по таблицам нормального закона распределения определяем значение стандартизованного отклонения tg = 1.96.
Так, как |r| = |-0,98| = 0,98, то по таблицам z- преобразования Фишера находим Z/ = 2,2976. Тогда
 ,
,
2,2976 - 1,96*((1/(6-3))0,5£ Z £ 2, 2976 + 1,96*((1/(6-3))0,5;
1,1659 £ Z £ 3.4292.
По таблице z- преобразования Фишера определяем r
0,83£ r£0,998
Примечание! Приведенные выше зависимости и результаты практических расчетов относятся к предположениям о наличии линейной связи между оцениваемыми параметрами. В случае если заранее известно, что связь нелинейная то можно воспользоваться эмпирическим корреляционным отношением.
Регрессионный анализ
.
Регрессионный анализ является составляющим элементом более общего метода количественного статистического анализа связей – корреляционно – регрессионного и заключается в определении аналитического выражения связи между двумя признаками (при парной связи) и между результативным и множеством факторных признаков (при многофакторной связи).
Целью регрессионного анализа является оценка функциональной зависимости условного среднего значения результативного признака (У) от факторных (х1, х2, …, хk).
Одним из важных вопросов построения моделей является их размерность. Практика выработала определенный критерий, позволяющий установить оптимальное соотношение между числом факторных признаков, включаемых в модель, и объемом исследуемой совокупности. Согласно данному критерию число факторных признаков k должно быть в 5.. 6 раз меньше объема изучаемой совокупности.
Остановимся более подробно на модели парной линейной регрессии.
Парная регрессия характеризует связь между двумя признаками: результативным и факторным. Аналитическая связь между ними может описывается следующими элементарными уравнениями:
· Прямой  =а0 + а1х;
=а0 + а1х;
· Гиперболы = а0 + а1./ х; (52)
· Параболы = а0 + а1х + а1х2; и т. д.
Оценка неизвестных параметров уравнения регрессии (а0, а1, …аn) осуществляется на основе метода наименьших квадратов.
Сущность метода наименьших квадратов заключается в нахождении параметров модели а0, а1, …аn, при которых минимизируется сумма квадратов отклонений эмпирических (фактических) значений результативного признака от теоретических, полученных по выбранному уравнению регрессии.
S = 
Для линейной зависимости имеем
 S =
S =  (53)
(53)
Производя частное дифференцирование зависимости (53) по параметрам а0, а1, …аn приходим к системе нормальных уравнений. Для линейной парной регрессии система нормальных уравнений имеет вид
 ;
;
 (54)
(54)
где n – объем исследуемой совокупности (число единиц наблюдения)
Пример. Имеются данные, характеризующие деловую активность акционерных обществ закрытого типа прибыль (тыс. рубл.) и затраты на 1 руб. произведенной продукции (коп.). Эти данные приведены в таблице 26 Предположим наличие линейной зависимости между рассматриваемыми признаками.
Таблица 26 - Расчет сумм для определения параметров парного линейного уравнения регрессии
| №
п/п
| Затраты на 1 руб. произведенной продукции, коп.
Х
| Прибыль, тыс. руб.,
У
| Х2
| ХУ
| 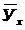
|
|
|
|
|
|
|
|
| Итого
|
|
|
|
|
|
Система нормальных уравнений для данного примера имеет вид (54) а в числовом варианте
6а0 + 502а1 = 4466;
502 а0 + 42280 а1 = 362 404
Откуда: а0 = 4153,88; а1 = - 40,75.
Следовательно, уравнение регрессии имеет вид
= 4153,88 – 40, 75х.
Оценка адекватности моделей построенных на основе уравнений регрессии начинается с проверки значимости коэффициентов регрессии.
Значимость коэффициентов регрессии осуществляется с помощью t - критерия Стьюдента
 , (55)
, (55)
где  - дисперсия коэффициента регрессии.
- дисперсия коэффициента регрессии.






