Как только мы выделили на изображении некоторые объекты, линейные или площадные, мы можем выполнить растрово-векторное преобразование, и на этом, собственно, анализ растровых изображений заканчивается. Начинается распознавание объектов и структур, которые, вообще говоря, могут быть получены не только при анализе изображений, но и какими-то другими способами. Естественно, если мы имеем дело с ограниченным количеством простых структурных конфигураций, то нам ничего не стоит описать каждый класс набором эталонов. Но каков же должен быть принцип сравнения, если мы имеем дело не с отдельной картинкой, а с какой-то более сложной и многообразной структурой, например, речной сетью? Или же в рассматриваемом типе структур встречаются элементы разной толщины, но толщина не имеет значения для описания общей формы. Стоит ли тогда «очищать» образ или можно обойтись его упрощенной схемой без дополнительных процедур? Обратимся к нашей речи. Если мы говорим на одном языке, для понимания, о чем идет речь, нам неважен ни тембр голоса, ни интонации, ни даже правильность произношения. Все упирается в саму конструкцию, то есть в употребляемые слова и их организацию в определенную языковую структуру. То есть существуют какие-то закономерности формирования языка, благодаря которым мы понимаем друг друга. Специалисты обратили на это внимание еще на заре развития вычислительной техники и создали теорию формальных грамматик, которая легла в основу всех языков программирования высокого уровня. Почти сразу же этот аппарат начал использоваться в теории искусственного интеллекта, в частности, в распознавании образов [4,25]. 61 Что же такое формальная грамматика? В начале курса мы определяли алгоритм распознавания как формальную систему. Подобным образом можно определить и грамматику.


В синтаксическом распознавании класс образов – это множество предложений языка L(G), порождаемого некоторой грамматикой G. Ясно, что такой подход к распознаванию основан на принципе общности свойств.
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 11
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 11
1 Теоретическое обоснование байесовского классификатора (на примере двух классов и одного признака).
-Вспомним принцип принятия решения на примере двух классов и одного признака. В случае, если признак x распределен в классе 1 и в классе 2 по нормальному закону (рис.14), области решения в пользу каждого из классов определены разделяющей точкой x0. Слева от x0 решение принимается в пользу класса 1, справа – в пользу класса 2.

Если гистограмма имеет более одного пика, может возникнуть ситуация, когда в результате аппроксимации такого распределения нормальным, положение разделяющей точки между классами изменится настолько, что значительная часть точек попадет в чужой класс (ошибка первого рода). Такая ситуация показана на рис.15. Штрихами показана ожидаемая ошибка первого рода, сплошным цветом – ошибка, которая может возникнуть в результате используемой аппроксимации.

Может случиться и наоборот, в «провале» между пиками наш класс «захватит» точки чужого класса, хотя эта ситуация менее вероятна и, возможно, менее критична.
На практике описанные ситуации возникают довольно часто. На рис. 16 показана гистограмма для одного из кластеров, выделенных в результате неконтролируемой классификации «подмножества» {2,3,4} тестового изображения (то есть в данном случае канал 2 соответствует каналу 3 исходного изображения). Аналогичная картина наблюдается для гистограмм этого класса и в других каналах.
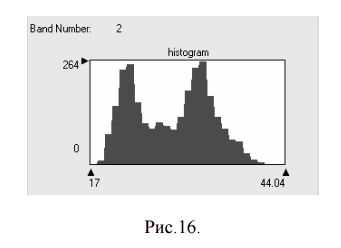
Как же поступать в подобных ситуациях? Во-первых, нужно выяснить, насколько представителен такой класс на изображении. Если он занимает большие площади, то и его вклад в ошибки будет велик. В этом случае целесообразно заменить его несколькими классами, посмотрев, на какие значения в каналах приходятся пики гистограммы, и создать сигнатуры с соответствующими им центрами непосредственно в пространстве признаков (например, нарисовав эллипсы с такими центрами). Если же класс занимает незначительную площадь и не представляет практического интереса, можно вообще отказаться от этой сигнатуры. В целом не следует забывать, что классификация на более однородные (т.е. узкодисперсные) классы позволяет существенно уменьшить ошибки и получить более четкие границы между объектами. Уже после классификации можно провести необходимую перекодировку непосредственно на классифицированном изображении, чтобы сохранить эти границы.
2. Расчет матрицы корреляции признаков по заданному набору образов.
-Корреляционная мера сходства двух векторов a и b определяется как косинус угла между этими векторами:
 , (7.2)
, (7.2)
где (a,b) - скалярное произведение векторов, ||×|| - норма (длина) вектора.
Ясно, что величина r будет принимать значения на отрезке [-1,1], при этом она будет положительна при одинаковых знаках соответствующих координат векторов a и b и отрицательна при противоположных. При конечном числе образов N эта величина есть ни что иное, как выборочный коэффициент корреляции по наборам из i=1,...,N реализаций случайных величин xj и xk.
При значении меры корреляции rjk, близкой по модулю к 1, в некоторых случаях можно практически без потери информации использовать при распознавании только один из признаков xi или xj. Тем не менее, перед этим все-таки целесообразно проверить, какие классы разделяются по этому признаку и не является ли наличие данного измерения принципиально важным для нашей конкретной задачи.
Матрица R ={rjk}, j=1,...,n, k=1,...,n размерности n x n называется корреляционной матрицей. Из определения коэффициента корреляции ясно, что корреляционная матрица R - симметрическая положительно полуопределенная, с диагональными элементами rjj =1, j=1,...,n.
Наиболее удобным формализованным способом расчета корреляции между признаками-измерениями по выборке образов является использование так называемой стандартизованной матрицы данных [5]. Эта схема удобна и при расчете корреляции между атрибутивными описаниями объектов в ГИС, например, при решении некоторых задач картографической генерализации.
Стандартизованная матрица данных. Пусть у нас имеется N образов, представляющих собой векторы в n-мерном пространстве измеряемых признаков - реализаций n-мерной случайной величины x. Представим полученные данные в виде матрицы размерности n x N.
 , (7.3)
, (7.3)
i=1,...,N, j=1,...,n.
Заметим, что каждый столбец матрицы - это вектор в пространстве размерности N, где N –число наблюдений (образов). В таком N-мерном пространстве задачу выделения наиболее информативных признаков (снижения размерности) можно рассматривать как задачу кластеризации по корреляционной мере сходства(о чем уже упоминалось в разделе 6). Для решения этой задачи приведем матрицу данных Х0 к стандартизованному виду.
1. Рассчитаем выборочные средние по каждой компоненте (столбцу) j=1,...,n:
 , (7.4).
, (7.4).
2. Вычислим выборочную дисперсию по каждой компоненте:
 , (7.5).
, (7.5).
Дисперсия, рассчитанная по (7.3), является смещенной оценкой с точки зрения математической статистики, но здесь она рассматривается скорее как среднее внутригрупповое расстояние, подобно тому, как это делалось в алгоритмах кластеризации. Элементы стандартизованной матрицы данных X={xij} вычисляются по формуле:
 , (7.6)
, (7.6)
Стандартизованную матрицу данных Х иначе называют нормированной матрицей. В результате проведенных операций мы перемещаем начало координат пространства признаков в точку с координатами m1,...,mn и нормируем шкалу по каждой координате на значение s. Полученная таким образом стандартизованная матрица данных обладает следующими свойствами:
1.mj=0, для всех j=1,…,n.
2. 
3. 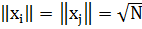
Мера корреляции (7.2) между двумя измеряемыми параметрами j и k, представленными вектор-столбцами матрицы Х, тогда принимает вид:
 (1/N)(xj,xk), (7.7).
(1/N)(xj,xk), (7.7).
Заметим, что rjk=σij/(σiσj), где σij - выборочная ковариация между случайными величинами xj и xk. Именно поэтому при выполнении ортогонального преобразования к главным компонентам иногда пользуются не корреляционной, а ковариационной матрицей (7.1)( ij=M[(xij-mi)(xij-mj)], i=1,…,n, j=1,…,n.). Тем не менее, не следует путать эти два понятия
ij=M[(xij-mi)(xij-mj)], i=1,…,n, j=1,…,n.). Тем не менее, не следует путать эти два понятия
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 12
.
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 12
1. Классификация по максимуму правдоподобия. Формула Байеса. Матрица ошибок.
-Классификацию по максимуму правдоподобия (режим Maximum Likelihood в Parametric Rule) иначе называют байесовским решающим правилом. В этом подходе используется вероятность появления каждого класса Wk для точки с данным набором значений признака xi, которая определяется по известной формуле Байеса:
 /xi)=
/xi)=  .
.
Выбирается тот класс, для которого эта вероятность максимальна, отсюда и название метода. Кроме вероятности появления точки в классе, здесь используется еще и вероятность появления такого класса на данной территории p(Wk) - априорная вероятность класса. Она определенным образом масштабирует вероятность появления точки в классе относительно таких же вероятностей для других классов, что приводит к смещению разделяющих границ. Однако на практике этим пользуются редко. Чаще априорные вероятности считают одинаковыми (так называемая нуль- единичная байесовская стратегия).
При использовании гипотезы о нормальном распределении значений признаков метод максимума правдоподобия отличается от классификации по расстоянию Махаланобиса только наличием априорных вероятностей появления классов в соответствии с формулой Байеса. Если же в максимуме правдоподобия используются равные априорные вероятности, то эти два метода ничем не отличаются. На рис. 13 показано тематическое признаковое пространство для результата классификации подмножества каналов {2,3,4} изображения tm_860516.img на 5 классов, сигнатуры которых отображены в левом окне. Слева – классификация по максимуму правдоподобия, справа – по расстоянию Махаланобиса.
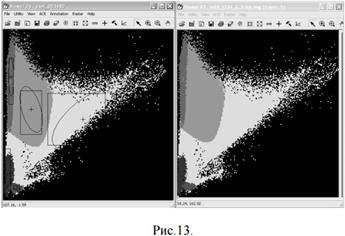
В целом метод максимума правдоподобия наиболее универсален. Единственная проблема состоит в том, что далеко не всегда сигнатуры выделяемых классов могут быть аппроксимированы нормальным распределением. В случае, когда гистограмма сигнатуры класса одномодальна и ее ассиметрия невелика, такая гипотеза работает достаточно хорошо. Однако при наличии в гистограмме нескольких мод в процессе классификации могут возникнуть дополнительные ошибки.
В редакторе сигнатур пакета ERDAS Imagine для этих целей предназначена функция Evaluate -> Contingency. Результат классификации эталонов выдается в виде матрицы ошибок, в процентах или в количестве точек. Если выборки содержат более ста точек, вариант в процентах, несомненно, удобнее. Для К классов матрица ошибок A={aij} имеет размерность K´K. Элемент матрицы aij показывает долю (или количество) точек, попавших из i-го класса в j- й класс. Таким образом, диагональные элементы aii матрицы A показывают долю правильно классифицированных точек, то есть точность классификации. Сумма всех остальных элементов по i-й строке – это количество точек, попавших из i-го класса в другие, то есть ошибка первого рода для i-го класса. Сумма всех, кроме диагонального, элементов i-го столбца – это точки, попавшие в i-й класс из других классов, то есть ошибка второго рода для i-го класса. В идеале матрица ошибок должна быть диагональной, поскольку оценки точности классификации на эталонах всегда завышены по отношению к изображению в целом. Метод, который обеспечивает 100% или близкую к таковой точность классификации на эталонах, и является наиболее подходящим. Если 100% точности добиться не удается, в выборе метода следует ориентироваться на те классы, которые желательно выделить наиболее точно.
2. Распознавание объектов на изображении с использованием функции взаимной корреляции.






