Матричная модель представляет собой таблицу, в заголовках строк и столбцов которой указаны соответственно источники и потребители информации (документы, подразделения), а на пересечении строк и столбцов (в графоклетках) – характер связи между ними.
В качестве примера матричных информационных моделей, рассмотрим матричную модель «Подразделение на подразделение» (рис. 2.3).
Подразделения
Рис. 2.3. Матричная модель «Подразделение на подразделение»
Эта матрица отражает документооборот между подразделениями.
Информационно-технологические схемы.
Эти схемы представляют технологические процессы обработки как в ручном варианте, так и в машинном с помощью специальных стандартных символов: носителей информации, процедур или устройств обработки, а также символов связи.
Использование этих символов рассмотрим на следующем примере.
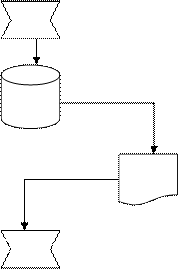
Пусть задача состоит в том, чтобы представить технологический процесс подготовки информации на машинном носителе в подразделении с передачей в ИВЦ, контрольной распечаткой и последующей сверкой в подразделении (рис. 2.4).
Операционные таблицы.
В операционной таблице представлена последовательность операций по обработке информации с разноской по подразделениям.
Пример на рис. 2.5 (взят из предыдущей задачи).
Применительно к понятию бизнес-процесса последовательность операций – это последовательность бизнес-функций, а операционную таблицу можно рассматривать как разновидность моделей бизнес-процессов.
По строкам таблицы указаны операции, а по столбцам – подразделения. В графоклетках с помощью стандартных символов показываются подлежащие обработке носители информации.

Рис. 2.4. Информационно-технологическая схема
|
Операции
| Подразделения
|
| Цех
| ИВЦ
| и т. д.
|
| 1. Регистрация
| 
|
|
|
| 2. Подготовка машинного носителя
|
|
|
|
| 3. Машинная обработка в ИВЦ
|
|
|
|
| 4. Сверка
|
|
|
|
Рис. 2.5. Операционная таблица
2.8. Описание постановки задачи
При каноническом проектировании основной единицей обработки данных является задача. Поэтому функциональная структура предметной области на стадии предпроектного обследования изучается в разрезе решаемых задач и их комплексов.
Описание постановки задачи предусматривает:
· содержательное описание задачи в словесной форме (экономическая сущность задачи, цели, эффективность, периодичность решения задачи, требования к достоверности и оперативности решения задачи, связь с другими экономическими задачами);
· составление информационно-технологической схемы с выделением этапов решения;
· описание входной информации (первичные документы и файлы баз данных);
· описание выходной информации (отчеты, справки);
· модель решения задачи (совокупность формул и логических переходов, показывающих преобразование исходных данных в выходные результаты);
· описание порядка работы пользователя с выходной информацией для принятия решения, а в случае диалогового режима решения – порядка участия пользователя в диалоге.
Структура описания постановки задачи представлена на рис. 2.6.
Рассмотрим пример постановки задачи формирования плана платежей.
Содержательная постановка задачи формирования плана платежей состоит в нахождении сроков платежей из заданного списка на предстоящий период. Установление сроков платежей должно быть синхронизировано с поступлениями денежных средств на расчетный счет предприятия с тем, чтобы выполнить договорные сроки платежей, а в случае отсутствия денежных средств найти приоритеты платежей, которые бы минимизировали финансовые потери предприятия.
Для решения поставленной задачи должны быть известны штрафные санкции, которые зависят от нарушения сроков платежей. Очевидно, что задача имеет решение, если в конце планового периода на расчетный счет предприятия поступит достаточное количество денежных средств. Однако в течение планового периода денежных средств может не хватать, и тогда возникает комбинаторная задача нахождения оптимального плана платежей.
Рис. 2.6. Структура описания постановки задачи
Решение поставленной задачи может быть получено на основе математического моделирования.
Рассматриваемая модель формирования оптимального плана платежей может быть использована как в оперативном, так и в тактическом финансовом планировании.
Отличительной особенностью модели является использование пошагового принципа анализа остатка денежных активов с учетом временной ценности денег в сочетании с требованиями постановки задачи линейного программирования с булевыми переменными.
Модель позволяет распределить заданное множество платежей по подпериодам планового периода в соответствии с поступлениями денежных средств таким образом, чтобы избежать овердрафта и при этом минимизировать потери, связанные с оттоком денег, штрафными санкциями, краткосрочным кредитованием и т. д.
Математическая постановка задачи имеет следующий вид:
 (2.1)
(2.1)
 (2.2)
(2.2)
 (2.3)
(2.3)
 (2.4)
(2.4)
Здесь приняты следующие обозначения: 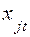 – двоичная переменная, принимающая значение «1», если
– двоичная переменная, принимающая значение «1», если  -й платеж предусматривается по плану произвести в
-й платеж предусматривается по плану произвести в  -й подпериод, и «0» – в противном случае;
-й подпериод, и «0» – в противном случае;  – суммарная величина потерь по всем платежам;
– суммарная величина потерь по всем платежам;  – сумма -го платежа;
– сумма -го платежа;  – множество платежей;
– множество платежей;  – количество подпериодов;
– количество подпериодов;  – ставка размещения, характеризующая реальные возможности по использования части временно свободных денежных средств;
– ставка размещения, характеризующая реальные возможности по использования части временно свободных денежных средств; 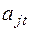 – относительная оценка потерь, связанных с задержкой платежа до -го подпериода (ставка штрафа, ставка по краткосрочному кредиту, экспертная оценка потерь);
– относительная оценка потерь, связанных с задержкой платежа до -го подпериода (ставка штрафа, ставка по краткосрочному кредиту, экспертная оценка потерь);  – сальдо накопленных денежных средств на начало первого подпериода;
– сальдо накопленных денежных средств на начало первого подпериода;  – величина притока денежных средств в -м подпериоде;
– величина притока денежных средств в -м подпериоде; 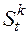 – сальдо накопленных денежных средств на конец -го подпериода;
– сальдо накопленных денежных средств на конец -го подпериода;  – допустимые остатки денежных активов на конец -го подпериода.
– допустимые остатки денежных активов на конец -го подпериода.
Целевая функция (2.1) содержит две группы слагаемых: первая группа отражает снижение потерь при «растягивании кредиторской задолженности»; вторая – нарастание штрафов из-за задержки платежей.
Ограничение (2.2) обеспечивает требуемую синхронизацию оттоков и притоков денежных средств.
Ограничение (2.3) отражает требование обязательности и однократности каждого платежа.
Использование коэффициентов наращения в выражениях (2.1) и (2.2) осуществляется с учетом приведения по времени денежных потоков внутри подпериода по принципу постнумерандо.
С учетом вероятностного характера притоков денежных средств 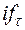 сальдо притоков
сальдо притоков  также представляет собой случайную величину
также представляет собой случайную величину

Если известна вероятность 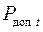 , с которой это значение будет достигнуто или превышено, то с этой же вероятностью будет выполняться ограничение (2.1) при переходе от детерминированной к стохастической постановке задачи.
, с которой это значение будет достигнуто или превышено, то с этой же вероятностью будет выполняться ограничение (2.1) при переходе от детерминированной к стохастической постановке задачи.
В качестве критерия эффективности рассматриваемой задачи, помимо минимизации потерь, могут использоваться: критерии минимизации колебаний сальдо накопленных денежных средств, критерий максимизации суммы свободных денежных средств к заданному сроку и т. д.
Метод решения поставленной задачи зависит от ее размерности и особенностей. В качестве возможных методов могут быть использованы: метод полного перебора вариантов, метод направленного перебора вариантов на основе подхода «ветвей и границ» с учетом особенностей задачи и стандартные методы решения задач линейного программирования с булевыми переменными (Балаша, Гомори и др.).
Для решения поставленной задачи могут использоваться инструментальные средства WinQSB и Lindo. Последнее инструментальное средство позволяет решать задачи большой размерности, содержащие до 300 булевых переменных.
2.9. Состав, содержание и принципы организации
информационного обеспечения ИС
Структура типовых компонент информационного обеспечения информационной системы представлено на рис. 2.7.
Организация информационного обеспечения предусматривает его разделение на внемашинное и внутримашинное.

Рис. 2.7. Структура информационного обеспечения
информационной системы
Внемашинное информационное обеспечение составляют системы классификации и кодирования информации, позволяющие представить реквизиты и показатели информации в соответствии с требованиями машинной обработки, и система документации, регламентирующая распределение показателей по входным и выходным документам информационной системы.
Внутримашинное информационное обеспечение представлено, прежде всего, базами данных.
Это – фактографические базы данных, содержащие структуризированную информацию в виде записей с определенным реквизитным составом и обеспечивающие поиск информации по ключевым реквизитам записей.
Это также документальные базы данных, содержащие неструктурированную информацию в виде документов и позволяющие осуществлять поиск документов по их поисковым образам в виде ключевых слов и связей между ними. В состав внутримашинного информационного обеспечения включается также пользовательский интерфейс: иерархическое меню, экранные формы для ввода информации, отчеты, содержащие решения задач.
Важным принципом формирования и ведения фактографической базы данных является ее разделение на файлы, содержащие:
· условно-постоянную информацию;
· переменную информацию.
По содержанию к условно-постоянной информации относится в основном нормативная и справочная информация.
К переменной относится информация оперативного учета. Файлы условно-постоянной информации должны быть сформированы до начала работы системы. А файлы переменной информации формируются во время ее работы.
2.10. Система классификации и кодирования информации
Существуют следующие системы кодирования.
1. Порядковая. Объекты кодируются числами натурального ряда. Используется для кодирования небольших и устойчивых номенклатур объектов. Например, код семейного положения: единица означает холост, двойка – женат, тройка – разведен, четверка – вдовец.
2. Серийная. Она является развитием предыдущей системы и предусматривает выделение серии номеров для кодирования каждого класса объектов. Перед присвоением номеров объекты подлежат укрупненной классификации. Например, сотрудники, работающие на предприятии постоянно, имеют первую серию табельных номеров, работающие по совместительству – вторую, а временно работающие – третью.
3. Повторений. По этой системе код представляет собой повторение какого-либо количественного признака объекта. Например, год 2012 может быть закодирован как 12.
4. Классификационная. Система основана на классификации объектов кодирования и записи в разрядах кодового обозначения значений признаков классификации. Различают две системы классификации объектов кодирования:
· последовательную (иерархическую),
· параллельную (фасетную).
В последовательной классификации различают классы, подклассы, группы, подгруппы, виды, подвиды и т. д. Схема последовательной классификации представлена на рис. 2.8.
Рис. 2.8. Схема последовательной классификации
a – признак классификации, в примере имеющий два значения: a1 и a2
При последовательной классификации количество объектов в классификационных группировках постепенно уменьшается на нижних уровнях.
Схема параллельной классификации представлена на рис. 2.9. При параллельной классификации каждый новый признак классификации обращается ко всему исходному множеству объектов. Следовательно, объектам должны быть присущи все признаки классификации, что не требовалось при последовательной классификации.
Рис. 2.9. Схема параллельной классификации.
В одну и ту же классификационную группировку даже нижнего уровня обычно попадает не один, а несколько объектов. Поэтому значений признаков классификации самих по себе недостаточно для придания однозначного соответствия между кодом и объектом. По этой причине прибегают к смешанным системам, в которых старшие разряды – значения признаков классификации, а младшие – это порядковая система кодирования для придания однозначного соответствия. Старшие разряды делают код семантическим.
Примером смешанных систем кодирования являются:
1) система кодирования готовой продукции по ОКП.
2) система кодирования деталей и сборочных единиц по ЕСКД.
Перечислим требования к системе кодирования.
1. Однозначное соответствие между кодом и объектом.
2. Семантичность, необходимая для алгоритмов машинной обработки.
3. Постоянная длина кода для всех обозначений (равномерность), поскольку поля в памяти имеют постоянную длину для реквизитов данного наименования.
4. Наличие резерва в разрядности кода для кодирования новых объектов.
5. Возможность стыковки локальной и глобальной систем кодирования, позволяющая осуществить переход от одной системы к другой.
6. Возможность легкого запоминания кодов человеком-оператором.
7. Возможность обнаружения и исправления ошибок.
После установления множества объектов, подлежащих кодированию, и выбора системы кодирования наступает этап собственно кодирования, т. е. присвоения объектам кодовых обозначений. Итоги этой работы представляются в кодификаторах (классификаторах).
2.11. Коды с обнаружением и исправлением ошибок
В рассматриваемых кодах к основным информационным разрядам добавляются контрольные разряды, т. е. вносится информационная избыточность, которая позволяет обнаружить ошибку, а иногда и исправить ее, не прибегая к повторению основных технологических операций.
Обнаружение и исправление ошибки основывается на том, что не все подряд сочетания символов образуют разрешенные кодовые обозначения. Обнаружение ошибки достигается тем, что обнаруживается запрещенный код, а ее исправление – путем замены неверного кода на ближайшее к нему разрешенное сочетание символов.
Количество разрядов, по которым один код отличается от другого, называется кодовым расстоянием между этими кодами. Например, между кодами 1994 и 1998 кодовое расстояние равно 1, а между кодами 1994 и 1982 кодовое расстояние равно 2.
Количество разрядов, в которых в кодовом обозначении произошли ошибки, называется кратностью ошибки. Например, если ошибка произошла в одном разряде, то это однократная ошибка. Для обнаружения ошибок должно выполнятся условие
d ³ r + 1,
где d – кодовое расстояние;
r – кратность ошибки.
Для исправления ошибок разрешенные коды должны еще больше отличаться друг от друга:
d ³ 2 r + 1.
Рассмотрим два примера, иллюстрирующих обнаружение и исправление ошибки.
Пример 1. Код с контролем по модулю для обнаружения однократной ошибки.
К информационным разрядам добавляется один контрольный разряд, содержащий такую цифру, чтобы сумма всех цифр кода делилась без остатка на заданное число (модуль), например 10.
Если величина ошибки не кратна модулю, то она будет обнаружена. Заметим, что модуль 10 позволяет обнаруживать все однократные ошибки. Именно однократные ошибки представляют наибольшую опасность, так как вероятность их возникновения приблизительно в 100 раз больше вероятности возникновения ошибок большей кратности.

2 7 1 4 5 1
 Информационные разряды
Информационные разряды
 Контрольный разряд
Контрольный разряд
Пример 2. Код Хемминга с исправлением однократных ошибок.
В этом коде присутствует целая серия контрольных разрядов, каждый из которых служит для контроля своей группы разрядов.




 4 9 2 0 7 1 4 6 5 1 0 2 3 8 5
4 9 2 0 7 1 4 6 5 1 0 2 3 8 5
Контрольные разряды
 1-я группа:
1-я группа:
2-я группа:
3-я группа:
4-я группа:
Если произошла ошибка в одном разряде, то изменится сумма цифр не всех, а только некоторых групп разрядов (в которые входит разряд с ошибкой). Это позволяет установить местоположение ошибочного разряда.
Далее, изменяя цифру в ошибочном разряде так, чтобы деление на модуль проходило без остатка, можно исправить ошибку.
2.12. Единая система классификации и кодирования
С целью стандартизации систем классификации и кодирования информации в Российской Федерации создана единая система классификации и кодирования (ЕСКК), структура которой представлена на рис. 2.10.
Как видно из рис. 2.10, система состоит из трех комплексов, центральный из которых содержит общесистемные (федеральные) классификаторы, в том числе: объектов административно-территориального деления, предприятий и организаций, природных и трудовых ресурсов, управленческой документации, единиц измерения, технико-экономических показателей, ОКП и т. д.

Рис. 2.10. Единая система классификации и кодирования
2.13. Проектирование форм первичных документов
Рассмотрим проектирование форм первичных документов.
Документ – носитель информации, имеющий юридическую силу. Для этого нужно, чтобы в документе были подпись, дата, печать.
По содержанию документы для машинной обработки обычно видоизменяются по сравнению с документами для ручной обработки:
· в документе должен быть минимально необходимый состав показателей;
· следует устранить неоправданное дублирование одних и тех же показателей в различных документах;
· из состава документов исключают показатели условно-постоянной информации, хранящейся в базе данных системы;
· аналогично поступают и с расчетными показателями, рассчитываемыми на ВИС;
· в документ вводятся новые реквизиты: кодовые обозначения, контрольные суммы и т. д.
Каждый документ включает в себя: заголовок, предметную часть и основание. Заголовок содержит данные, относящиеся ко всему документу: наименование, код формы, номер, дату. Основание – это подпись и печать. В предметной части заключается основное содержание документа.
Существуют следующие формы предметной части первичных документов: анкетная, зональная, табличная.
o Анкетная форма – это последовательность вопросов и ответов (пример – личная карточка работающего).
o Зональная форма предусматривает выделение в документе отдельных зон, в которых располагаются логически взаимосвязанные реквизиты (пример – инвентарная карточка учета основных средств).
o Табличная форма является наиболее компактной. Наименования реквизитов стоят во главе столбцов, а значения – находятся в графоклетках (пример – номенклатура-ценник материалов).
Существуют комбинированные формы представления предметной части.
После составления проекта документа необходимо его согласовать с пользователем. Рекомендуется оставлять на бланке документа место для примечаний. Размеры графоклеток должны соответствовать обозначениям реквизитов (с учетом машинного заполнения). А сам размер бланка документа должен быть стандартным.
2.14. Унифицированная система документации
Система документации – это совокупность взаимосвязанных документов, необходимых для работы пользователей информационной системы.
Очевидна целесообразность унификации системы документации в допустимых пределах. Унификация систем документации может быть на разном уровне управления: межотраслевом, отраслевом и уровне предприятия (локальные системы документации).
На межотраслевом уровне в настоящее время разработан целый ряд унифицированных систем документации (УСД), к которым относятся:
· единая система конструкторской документации (ЕСКД);
· единая система технологической документации (ЕСТД);
· унифицированная система форм статистической отчетности;
· унифицированная система документов бухгалтерского учета и отчетности и др.
В то же время остается необходимость разработки локальных систем документации, включающих в себя неунифицированные документы оперативного учета, плановые и отчетные документы, отражающие технологические и другие особенности предприятия и управления им.
2.15. Проектирование пользовательского интерфейса
Пользовательский интерфейс или человеко-машинный диалог – это набор приемов взаимодействия с компьютером. Грамотно построенный интерфейс сокращает число ошибок и способствует тому, что пользователь чувствует себя с системой комфортнее. От этого в конечном итоге зависит производительность работы – основной показатель качества пользовательского интерфейса.
Потому пользовательский интерфейс необходимо проектировать так, чтобы было обеспечено максимальное удобство пользователям в работе с данной программой. То есть в программе должны быть заложены следующие требования к интерфейсу:
· дизайн интерфейса должен отвечать правилам эргономики;
· естественность (интуитивность) работы с программой;
· нагрузка на память пользователя должна быть, по возможности, минимальна;
· стандартность приемов работы (согласованность с прошлым навыком);
· подсказки, позволяющие пользователю принять решение в создавшейся ситуации;
· интерактивная помощь (возможность ее вызова из любого места программы);
· очевидность меню (простая формулировка, иерархическая структура, логическое соответствие пунктов и подпунктов);
· действия пользователя должны быть обратимыми (т. е. должна представляться возможность отмены (undo);
· возможность использования «горячих» клавиш; экстренный выход из программы.
В настоящее время человеко-машинный диалог чаще всего осуществляется на основе WIMР-интерфейса, реализуемого операционной системой Windows. Аббревиатура WIMP (Windows Image Menu Pointer) означает Окна, Образ, Меню, Указатель. При этом в окнах на экране компьютера присутствуют кнопки-пиктограммы и световые меню, которые выбираются указателем.
В перспективе предусматривается распространение интерфейса, включающего в себя речевые команды – SlLK-интерфейса (Spich–Речь, Image–Образ, Language–Язык, Knowledge–Знание).
Проектирование человеко-машинного диалога должно заканчиваться составлением модели диалога, отражающей порядок работы пользователя с компьютером. Модель человеко-машинного диалога в укрупненном виде можно представить как разновидность информационно-технологической схемы, включающей в себя последовательность основных этапов обработки информации с указанием для каждого этапа той информации, которую должен вводить человек, и тех диалоговых окон, которые предлагает машина для информационной поддержки принятия решений и ввода информации.
Детальная модель человеко-машинного диалога может быть представлена в виде сетевого графика, вершинами которого являются диалоговые окна с указанием состава вводимой и выводимой информации, а дуги соответствуют условиям перехода между окнами.
Основные компоненты пользовательского интерфейса – это то, что пользователь видит на экране.
К проектированию основных компонентов пользовательского интерфейса относятся: меню, экранные формы и отчеты.
2.16. Проектирование фактографических баз данных
2.16.1. Методы проектирования фактографических баз данных
Методы проектирования фактографических баз данных, как и методы проектирования любых информационных систем могут быть подразделены на канонические, автоматизированные и типовые.
Каноническое (индивидуальное) проектирование предусматривает использование СУБД, например, Microsoft Access или MS SQL Server, и обеспечивает учет специфических особенностей структуры фактографической информации без использования средств автоматизации.
Методы автоматизированного проектирования базы данных предусматривают использование CASE-средств.
Так, CASE-средство Silverrun американской фирмы «Silverrun Technologies, Inc.» содержит модуль концептуального (инфологического) моделирования данных (ERX-Entity Relationship Expert), который обеспечивает построение моделей данных «сущность–связь», не привязанных к конкретной реализации. Этот модуль имеет встроенную экспертную систему, позволяющую создать инфологическую модель данных посредством ответов специалистов в данной предметной области на вопросы о взаимосвязи данных. Результаты работы этого модуля передаются в модуль реляционного моделирования (RDM – Relational Data Modeler) для проектирования даталогической реляционной модели данных.
Методы типового проектирования используют ранее разработанные аналоги баз данных для построения новой фактографической базы.
2.16.2. Концептуальное, логическое и физическое
проектирование фактографических баз данных
Распределение работ по стадиям канонического проектирования фактографической базы данных показано на рис. 2.11.
Итоговая задача предпроектной стадии – разработка инфологической модели предметной области без привязки к конкретной СУБД.
Основой конкретной инфологической модели является модель «сущность–связь» (Entity-Relationship – ER-модель), описывающая взаимосвязь объектов (сущностей) предметной области.
Конечным этапом даталогического проектирования является описание логической структуры базы данных на языке описания данных конкретной СУБД. При даталогическом проектировании нужно учитывать типы моделей данных, поддерживаемые выбранной СУБД: иерархические, сетевые, реляционные.
При ручном методе проектирования базы данных строится графическое изображение структуры базы данных.
Завершается стадия технического проектирования базы
данных привязкой даталогической модели к среде хранения,
т. е. построением физической модели базы данных (схемы хранения).
На стадии рабочего проектирования осуществляется настройка выбранной СУБД и подготовка технологических инструкций для первоначального формирования и последующего ведения базы данных.
Стадии ввода в действие и сопровождения предусматривают решение контрольного примера по работе с базой данных и мониторинг ее функционирования, а также реструктуризацию базы данных в случае существенного ухудшения эксплуатационных характеристик.
Предпроектная стадия:
· описание объектов и связей между ними;
· описание информационных потребностей
| Проектирование инфологической модели
| | пользователей;
· установление алгоритмических связей
показателей;
·  построение инфологической модели; построение инфологической модели;
· утверждение технического задания
|
| Проектирование даталогической модели
| | Техническое проектирование:
· выбор СУБД;
·  выбор модели данных; выбор модели данных;
· построение даталогической модели;
· | Физическое
проектирование базы даннх
| | выбор запоминающих устройств;
· организация данных;
· выбор методов доступа;
·  построение физической модели данных; построение физической модели данных;
· утверждение технического проекта.
|
| Рабочее проектирование:
· настойка СУБД;
·  тестирование; тестирование;
· разработка технологических инструкций
по работе с базой данных
|
| Ввод в действие и сопровождение системы:
· формирование базы данных;
·  решение контрольного примера; решение контрольного примера;
· утверждение акта приемки-сдачи;
· | Мониторинг функционирования
| | ведение базы данных;
· мониторинг функционирования;
· реструктуризация базы данных
|
Рис. 2.11. Распределение работ по стадиям проектирования
фактографической базы данных
2.17. Проектирование документальных баз данных
Рассмотрим распределение работ по проектированию документальной базы данных (ДБД) по стадиям и этапам (рис. 2.12).
| Предпроектная стадия:
· анализ документов
предметной области;
· выбор критериев
эффективности ДБД;
· выбор ИПЯ;
· утверждение ТЗ
|   | Анализ документов
предметной области
| |
| |
| Техническое проектирование:
· проектирование ПОД и ПОЗ;
· выбор СУБД;
· проектирование логико-семантического комплекса;
· разработка каталога ДБД;
· формирование «Словаря
ключевых слов»;
· утверждение ТП
|  | Разработка
логико-семантического
комплекса
| | 
| |
| | Рабочее проектирование:
· формирование базы данных документов;
· индексация документов базы данных;
· формирование базы данных ПОД;
· тестирование;
· разработка сопроводительной документации
|  | Формирование базы
данных ПОД
| |   | Формирование базы
данных документов
| |
|
| Ввод в действие и сопровождение:
· обучение пользователей;
· опытная эксплуатация;
· утверждение акта приемки-сдачи;
· ведение ДБД.
· мониторинг функционирования;
· реструктуризация базы данных
| 
| |
| | | | | |
Рис. 2.12. Распределение работ по стадиям проектирования
документальной базы данных
2.17.1. Анализ предметной области
документальной базы данных
Работа начинается с постановки задачи создания документальной базы данных. Проводится анализ предметной области и совокупности характеризующих ее документов. Выбираются критерии эффективности функционирования ДБД и разрабатывается технико-экономическое обоснование целесообразности ее создания. Осуществляется выбор информационно-поискового языка (ИПЯ), определяются требования к техническим средствам и форме представления выходных документов. Предпроектная стадия заканчивается утверждением технического задания (ТЗ) по проектированию документальной базы данных (ДБД).
2.17.2. Разработка состава и структуры
документальной базы данных
Стадия технического проектирования включает в себя проектирование поисковых образов документов (ПОД) и поисковых образов запросов (ПОЗ). Выбирается СУБД для управления базой данных ПОД и базой данных документов, если документы представлены на машинном носителе.
2.17.3. Проектирование логико-семантического комплекса
документальной базы данных
Разрабатывается логико-семантический комплекс, т. е. алгоритм, отражающий логику сопоставления содержания ПОЗ и ПОД. Проектируется структура ДБД. Разрабатывается электронный каталог ДБД и формируется «Словарь ключевых слов» для пользователей.
Завершается стадия утверждением технического проекта (ТП).
Рабочее проектирование состоит в формировании базы данных документов на основе ретроспективного анализа, их индексировании и формировании на этой основе базы данных ПОД.
Ввод в действие и сопровождение (послепроектная стадия) включает в себя обучение пользователей, тестирование созданной ДБД, состоящей из базы данных документов и их поисковых образов.
По результатам опытной эксплуатации утверждается акт приемки-сдачи ДБД и наступает стадия сопровождения ДБД, состоящая в ее обновлении и эксплуатации в рабочем режиме.
2.18. Проектирование технологических процессов
обработки информации
В системе обработки информации можно выделить следующие технологические процессы, составляющие замкнутый контур обработки информации и соответствующие основным этапам обработки информации (рис. 2.13).



Рис. 2.13. Основные процессы преобразования информации
в контуре информационного обмена
1. Получение информации. Состоит в выборке определенной информации из окружающего мира с помощью датчиков или человека и занесении этой информации на носители. Процесс получения формации с точки зрения преобразования информации – это процесс создания новой информации, т. е. содержательного преобразования.
2. Сбор и












